她琴棋书画全能,还进入清华计算机系实验室,被赞智商太超群、能力过强悍
 十三
来源:
量子位
十三
来源:
量子位
清华唐杰收了个AI女徒弟
最特殊,没有之一。
她叫 华智冰 ,没有参加过任何升学考试,没有拿过任何竞赛名次。
却被 清华大学 计算机科学与技术系知识工程实验室, “破格录取” 。

而且就这么一位学生,还得举三个单位(研究所、企业)之力, 联合培养 。
就连实验室主任 唐杰 ,一开始也是再三犹豫,“是否能hold得住这个学生”。
为什么?到底什么来头?
只因智商 太超群 、能力 过强悍 。
华智冰刚诞生,便可 绘画 、 作诗 。
在经过一段时间的训练后,竟还可以 做曲 !
或许你已经有所发觉。
华智冰,她 并不是人 :
没错,她那张逼真的脸,也是合成的。
“超级学霸”华智冰
要想深入了解华智冰,先要知道她从 哪里来 。
华智冰是这样自我介绍的:
这就不难理解她名字的由来了,是从三方名字中各取了一个字。
华智冰自诞生以来,便对 写诗 、 作画 有着浓厚的兴趣。
先来感受一下出自华智冰之手的作品。

一幅中国水墨画勾勒出的风景,别有一番“山水悠远,墨韵舒爽”的风味。
此情此景之下,就着“智源大会2021”这一主题所创作出来的七言律诗,在不失本意的基础上,也有慷慨激越之意。
而华智冰的画风不仅限于此,山水田园油画也是拿捏得很到位,亦可即兴创作春意盎然的现代诗歌。
除了写诗、作画, 作曲 也是华智冰的拿手强项。
虽说能力至此,但学霸毕竟是学霸, 好学 的本质和人类还真没有差别。
用华智冰自己的话来说就是:
(讲真,有被打击到……)
这也就是她来到清华大学,来到唐杰老师实验室继续深造的主要原因。
除此之外,华智冰也想了解自己的身世——“我是怎么诞生的”、“我能理解我自己吗”。
于是,在唐老师的“讲解”之下,华智冰开始学习人工智能发展脉络:
△华智冰学习人工智能的发展脉络
而华智冰要学习还远不止于此,作为一名具有超强学习能力的学生,她的 课程安排 和其他学生有着较大的区别:
至于先学什么,只是一个选择问题而已。
华智冰的导师唐杰对此是这样评价的:
至于何时 “毕业” ,唐杰希望是在华智冰22岁的时候,而且在这一过程中,最难的不是学习知识,“而是 认知过程 ”。
那么问题来了,华智冰为什么能够拥有如此强悍的学习和创作能力?
全球最大预训练模型加持
与以往的虚拟人不同,华智冰的核心差异点,便是智谱AI的 数据和知识的双轮驱动 引擎。
其中,数据轮要能归纳,“举十返一”;知识轮要能根据知识进行逻辑推理,做到“举一反三”。具体来说,双轮驱动的数据部分,就是“悟道2.0”。
一个超大规模预训练模型,而在知识部分,则是智谱AI搭建的一个性能稳定,规模巨大的知识图谱。
这样,华智冰背后的引擎,就具有了一定的认知和推理能力,也有了学习计算机专业知识的基础。
华智冰还拥有小冰公司在虚拟人技术上,20多年的研究积累,包括计算机视觉、自然语言处理、计算机语音、人工智能创造的情感交互框架、检索模型、生成模型、共感模型等。
这就让她已经站在了普通虚拟人的“肩膀”之上。
但更重要的是,华智冰还拥有一项“bug级”技能加点—— 悟道2.0 ,全球最大预训练模型。

悟道2.0的特点如下:
与其说悟道2.0是一个语言模型,更确切的说法应当是一位 “全能型选手” 。
正如华智冰所具备的实力一样,悟道2.0在问答、绘画、作诗、视频等任务中正在逼近 图灵测试 。

而且还是得到了官方认可的那种:

再究其背后,还有三个夯实的 基石 ,保障了悟道2.0的强悍性能。
首先,是算法基石——。

在过去的大规模预训练模型中,MoE可以说是一个必要的条件。
它是⼀个在神经⽹络中引⼊若⼲专家⽹络的技术,能直接推动预训练模型经从亿级参数到万亿级参数的跨越。
但缺点也是非常明显,需要与昂贵的硬件强关联、强绑定。
而作为⾸个支持PyTorch框架的MoE系统,FastMoE便打破了分布式训练的瓶颈,还并针对神威架构进行了优化,可在国产超算上完成训练。
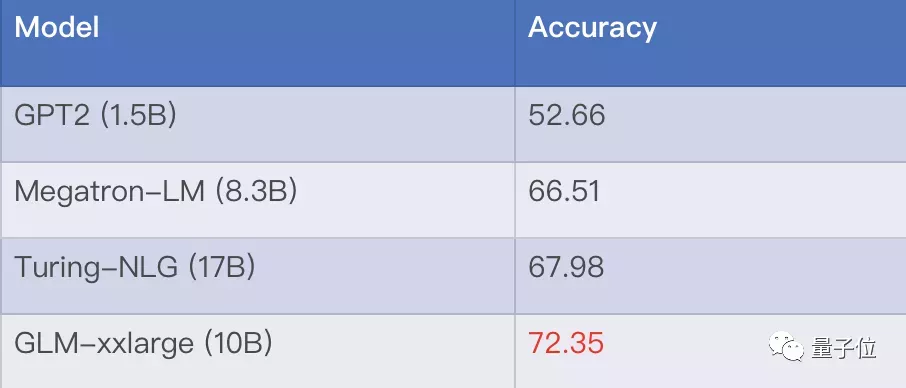
其次,是自研的最大英文通用预训练模型——。
据了解,新一代的GLM模型以 100亿 的参数量, 匹敌微软170亿参数的Turing-NLG模型,能在LAMABADA填空测试中表现更优。
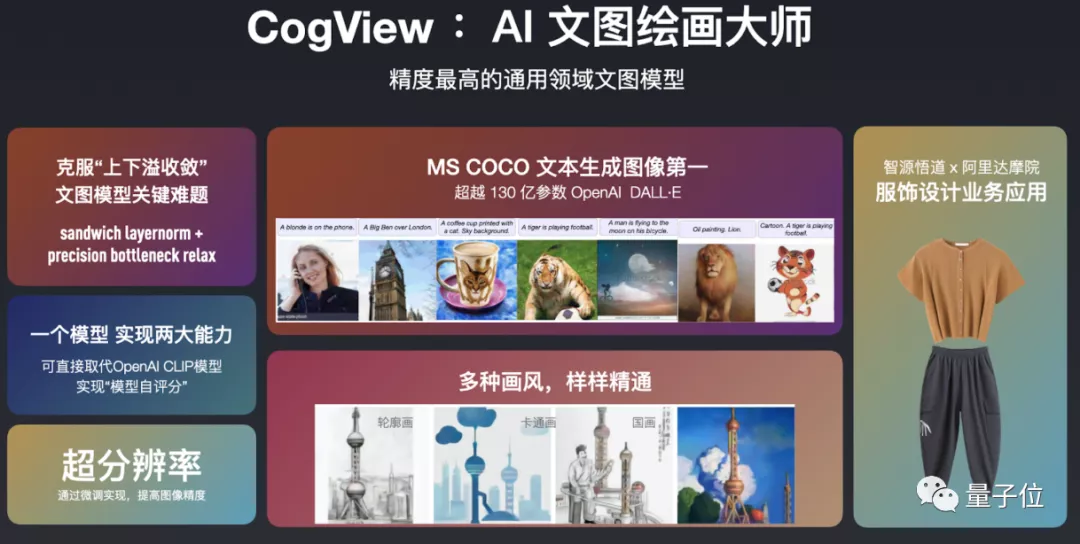
最后,还有世界最大中文多模态生成模型——。
它的参数量达到了 40亿 ,可直接从中文文字生成图像。
并且在MS COCO文本生成图像任务权威指标FID上,CogView还打败OpenAI今年年初发布的130亿参数的DALL·E,获得 世界第一 。
有 数据驱动 夯实的基本功,还有强悍 知识驱动 的加持,这便是华智冰超于以往虚拟人的关键点。
悟道的野心还不止如此。
除了自身的能力,它还能为广大开发者、技术公司,以及传统企业提强大而通用的智能服务底层系统,仅通过模型微调实现领域模型的构建,避免不必要的重复模型训练。
通过这种智能赋能的方式,“悟道2.0”之上将会出现一个超大规模的智能模型应用生态。在智谱AI负责的应用平台上,已经出现了不少有趣的应用(见文末链接)。
比如,在故事生成专区里,有开发者做的应用可以创作时下最为流行的逻辑推理游戏—— 剧本杀 的脚本。
剧本杀故事本身所具有的强逻辑性、环环相扣的特点,多数玩家应当是深有体会。
这些应用已经上线了,大家可以体验一下!
以为这就完了?
不不不。
还能 写论文和策论 !
只要给定标题、分论点和关键词,即可生成一段逻辑严谨的文字片段。
归总一句话,这个关键点能够推动的,便是让机器能像人一样“思考”。
“炼大模型就像建一个粒子加速器”
由此延伸,随之浮出的一个问题便是:
从谷歌的BERT,到OpenAI 的 GPT-3、Dall·E,以及越来越多的大模型涌现。
一个模型的定义,不再仅局限于“算力+算法”,还要整合尽可能多的数据。
整理成式就是, 模型=数据+算力+算法。
通过设计先进的算法,整合尽可能多的数据,汇聚大量算力,集约化地训练大模型,供大量企业使用。
但与此同时,伴随而来的争议也十分明显:
太烧钱!
一般企业是承受不了的。而烧钱之后所能达到的效果,也是差强人意。
那要不要做?值不值得做?成为世界上一些国家、大型企业所面临的难题。
清华大学人工智能研究院院长、中国科学院院士 张钹 教授,则肯定表示—— 要做!
这也是悟道系列在内所有大模型的科学价值。
不过,张钹院士也强调,不要抱有太大希望,也建议不要一拥而上。
而作为当前全球最大的预训练模型悟道2.0,已经在探索大模型的 产业价值 。
智谱AI首席科学家、清华大学教授唐杰表示,如果分成不同阶段,悟道1.0的定位是 追赶 世界顶尖水平,那么悟道2.0就是单点突破,从单个特性超过它。
至于是什么契机创造这么一个虚拟大学生—— 华智冰 ,唐杰坦言主要有两方面原因。
第一,很简单。华智冰充当一个载体,来验证悟道2.0的有效性。
第二个原因,则是虚拟形象技术本身。
试想一下,未来10到20年,人类社会也许会有几十亿的虚拟人与我们共存。
AI也逐渐从现在的算法慢慢变成一个主体,而虚拟人形象正好是这样一个主体的依托。
正如人的大脑意识和身体躯壳一般。
现在,华智冰也许是未来社会虚拟人的一个缩影。
通过持续学习和演化,最后成为一个有着丰富知识和与人类有很强交互能力的机器人。
然而,调皮的网友却关心起了“人之常情”的问题来:
研究人员回应道:
悟道2.0应用体验链接:
版权所有,未经授权不得以任何形式转载及使用,违者必究。