
崖山迁移平台 YMP 是 YashanDB 提供的数据库迁移产品,提供异构 RDBMS 与 YashanDB 之间进行迁移评估、数据迁移、数据校验的能力。
在最新发布的 V23.3 版本中,YMP 新增增量迁移组件(以下简称“迁移组件”),具备异构数据库的在线全量迁移和增量迁移能力,且支持两者间的无缝衔接,真正实现业务无感知迁移,保障数据一致性及业务连续性。
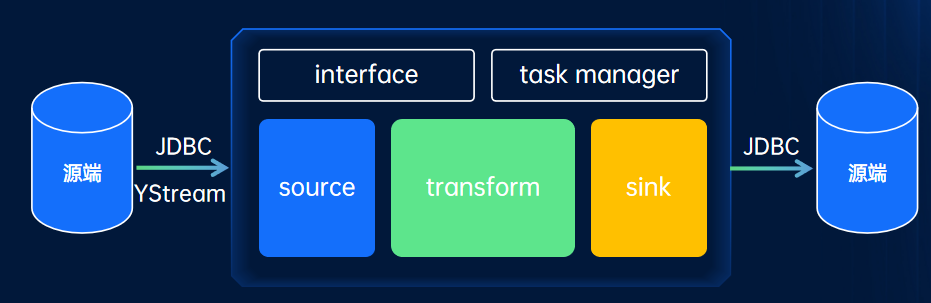
迁移组件架构上由 source,transform,sink 三个模块组成。其中 source 模块负责从源端获取数据,transform 模块负责数据转换,sink 模块负责目标端数据导入。其具备以下关键能力:
完整的数据迁移过程包括元数据迁移、全量迁移及增量迁移三个阶段,接下来将会介绍每个迁移阶段的关键能力。
元数据迁移能力
迁移组件在元数据迁移阶段具备以下几方面能力:
高性能全量迁移
全量迁移阶段,迁移组件对性能进行深度优化。
首先是多线程并行,按表并发,把每张表分配给一个线程去迁移。源端会启动多个线程进行查询,目标端也是多线程进行批量插入。每对线程之间有独立的缓冲队列,互不影响。
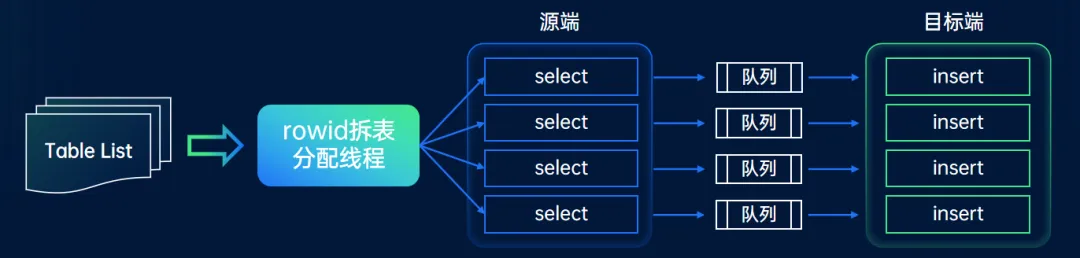
其次对大表进行拆分,均匀拆分成多个子表,分配给多个线程,进一步提高并发度。迁移组件采用 rowid 拆表算法,拆分耗时短,可以支持无主键表的拆分。
经过上述优化,全量迁移的性能可达到 200M/s,满足主流场景的性能要求。
无缝衔接全量至增量迁移
全量迁移结束后,将进入增量迁移。在此阶段需考虑全量迁移和增量迁移之前的无缝衔接。
基本要求如下:

迁移组件基于闪回查询实现全量迁移至增量迁移的无缝衔接。具体实施细节如下:
增量迁移环节主要分为两部分,一个是从源端获取数据,另一个是在目标端入库。
增量迁移:源数获取
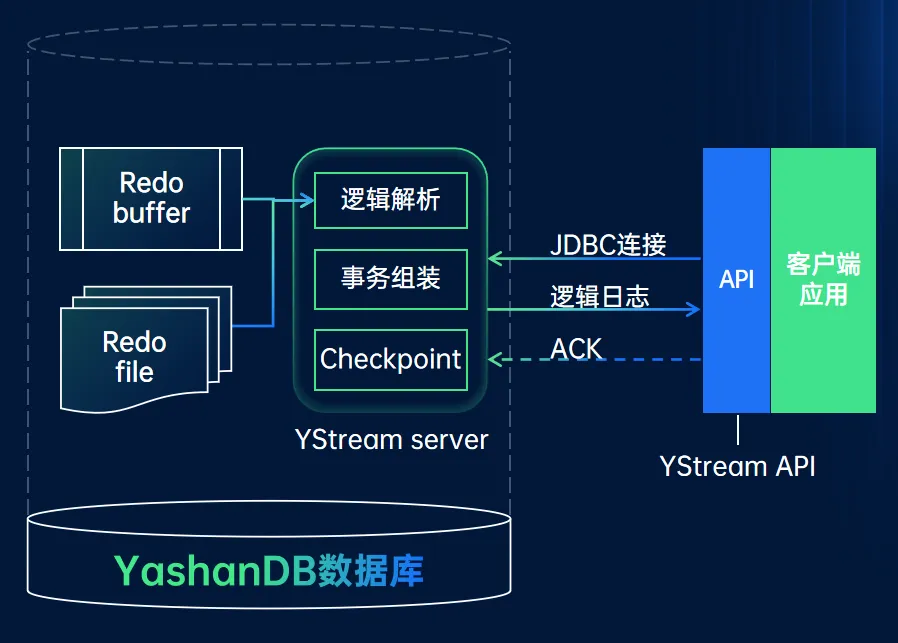
迁移组件通过逻辑日志解析接口 YStream 获取源端增量数据。
YStream 工作原理
YStream 是 YashanDB 数据库提供的一个日志解析服务,客户端可以通过 YStream 获取数据库逻辑日志,用于数据同步。YStream 具备高性能、高可靠性、易使用等特点,主备部署环境下可以将其部署在备库,以减少主库压力。
迁移组件就是通过 YStream 获取增量逻辑日志,然后组装成 SQL 语法发送到目标库执行。
YStream 性能优化
Redo 日志的读取性能以及日志解析性能是影响逻辑日志获取性能的重要因素,YStream 对此进行了深度优化。
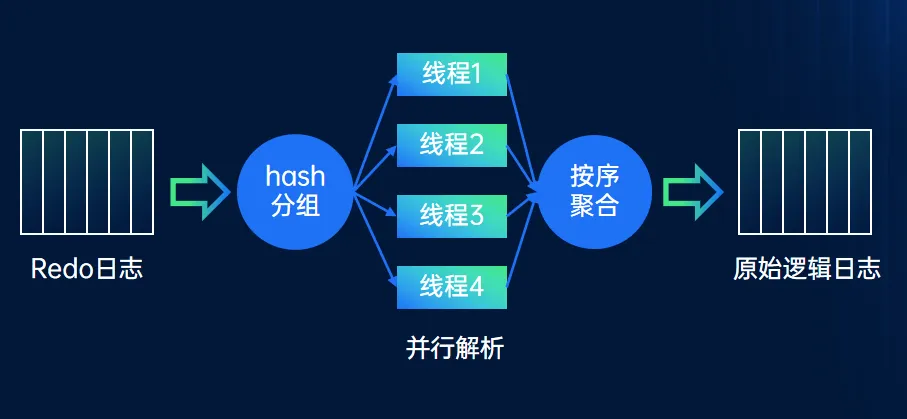
Redo IO 优化
YStream 会优先从 Redo buffer 读取日志。一方面从 buffer 读取的速度很快,延迟很低;另一方面读 Redo buffer 不产生读 IO,可以减少数据库压力。
正常情况下,数据库产生 Redo 的速度和 YStream 解析的速度一样,所以全部从 Redo buffer 读取,完全不产生 IO。如果目标端背压高,导致 YStream 解析阻塞后,可能会从 Redo 文件读取。但当下次 YStream 解析追平 Redo 产生速度后,又会接着从 buffer 读取。
并行解析
单个解析线程的性能无法满足并发业务产生的数据库 Redo 解析要求,因此 YStream 将 Redo 日志进行哈希分组,然后分配给多个线程进行独立解析。解析完毕后,再按照原始顺序进行聚合,生成原始逻辑日志进行事务组装和发送。
YStream 一致性事务发送
YStream 在发送逻辑日志时,是以事务为单位发送的,且严格按照事务的顺序发送,用户无需关心回滚事务。当一个事务的所有逻辑发送完后,才会发送下一个事务,并且仅发送已提交的事务。
每条逻辑日志都有单调递增的 position,使得客户端能够精确定位至特定的逻辑日志。在断点续传的时候,通过给服务端发送最后一次成功接收的 position,可以让 YStream 从这个点开始发送后续数据,确保数据传输不会重复也不会遗漏。因为每条 DML 均有独立的 position,YStream 可以实现在事务中间的断点续传功能。
YStream DDL 逻辑日志附带信息
增量迁移过程中,增量 DDL 通常是一个难点,一方面是 DDL 语法较多,不同数据库之间不一定兼容,另一方面是从 DDL 原始语句里无法获取足够的信息。一般的 CDC 组件,对于 DDL 逻辑日志的只会输出 DDL 原始语句,不会有更多元数据信息。

YStream 在解析增量 DDL 语句的时候,除了输出原始 SQL 语句,还会输出 DDL 类型以及表结构信息。包括表里有多少列,这次 DDL 涉及哪些列等。这样不需要解析 SQL 语句,直接从附带信息就知道表结构。
另外会附带主键等 SQL 语句无法获取的信息。比如上图中的建表语句,这条 DDL 没有指定主键约束名,执行时会自动生成一个约束名,这个约束名在 DDL 语句里看不到,但是 YStream 的逻辑日志会附带。
如果在目标端建表的时候执行原始 DDL 语句,那么会自动生成一个随机约束名,和源端约束名不一致。后面遇到一个指定约束名的 DDL,目标端就会执行失败。比如源端执行 DDL,drop 指定的约束名,而目标端没有这个名字的约束(因为目标端自动生成的约束名不一样)。而 YStream 通过更详细的附带信息能解决这类问题。
增量迁移:并行入库
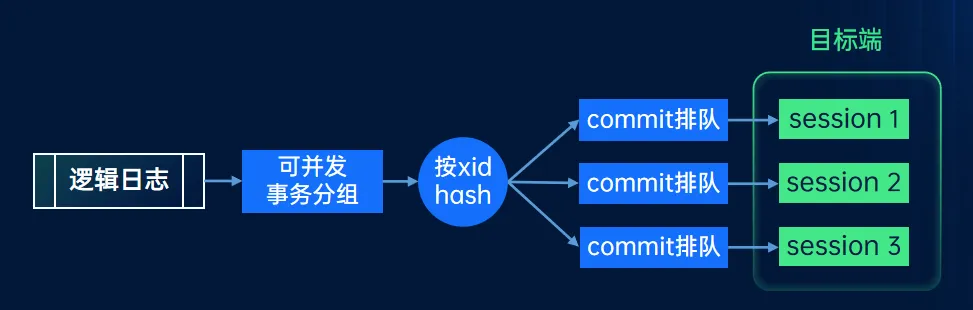
从源端获取增量数据后,如何高效的把增量数据在目标端入库,也是增量迁移的重点内容。迁移组件支持表级和事务级两种并发模式,以提供数据入库效率。
按表并发
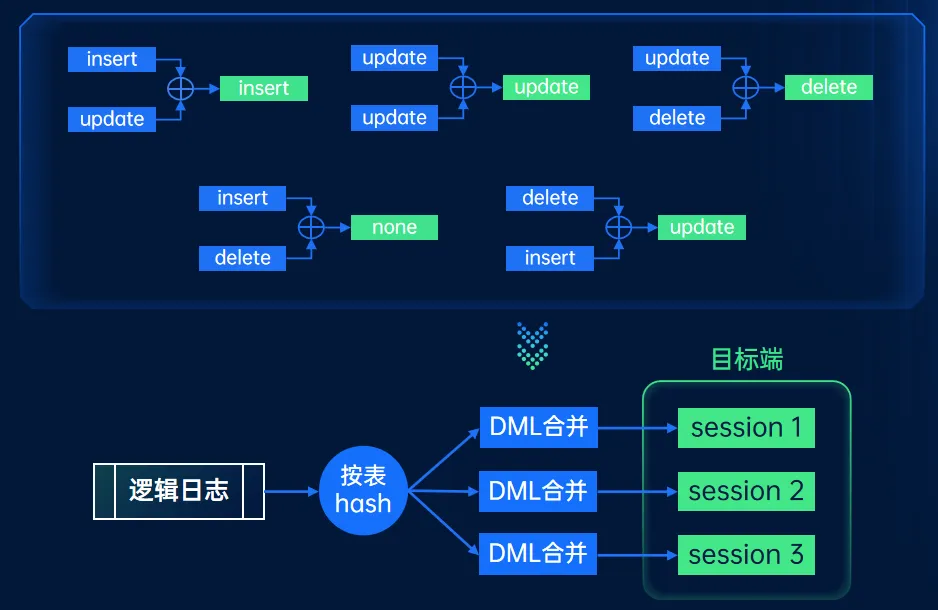
按事务并发
断点续传
断点续传是指增量迁移过程中,源端或目标端发生故障,导致事务传输中断后,可以重新从断点位置继续传输。 为了提高增量迁移的可靠性,迁移组件实现“精确一次”的断点续传功能。
在迁移开始前,迁移组件在目标端创建一张辅助表,然后在往目标端迁移的事务中,同时更新辅助表中的 position,这样事务提交后,这个 position 之前的数据就迁移成功了。
若在迁移过程中任意时刻发生故障,比如断网、数据库宕机等,只要在迁移组件重连目标库后,把辅助表里的 position 发送给 YStream,YStream 就可以从断点处发送后续数据,不会漏发,也不会重复发。
未来展望
异构数据库之间的数据迁移,是一项较为复杂的工程。在不同的数据库产品,不同的部署拓扑结构下,会有较大差异的处理逻辑。目前 YashanDB 的迁移组件实现了数据迁移的常用功能,但是还有一些能力有待完善,未来我们将从以下几个方面进行优化加强:
