好久没写东西,分享一下最近思考的比较多的东西,就当是工作记录了。
从一个很重要的问题出发:如果在今天,我们从新设计一个>
在进入到具体的技术设计之前,我先分享一下我理解的当今(以及未来)的开发者对于数据库的期待:
针对上面这些趋势和痛点,映射到技术上:
带着这些假设,过去这一年,大概做的工作总结一句话就是把: TiDB 大卸八块,然后利用云的基础设施,将它从新拼装起来变成一个数据库服务。最近低调的发布了 TiDB Serverless Tier 就是这个新引擎的第一次亮相。下面聊聊一些技术和工程上的思考。
做服务而不是做软件
今天做数据库,如果你不提供云服务,出门都不太好意思和人打招呼(很快就会是 Serverless)。有很多人(尤其是数据库内核开发者)会低估做一个云服务的复杂性,经典的论调:‘不就是在云上的自动化部署吗?’ 或者 ‘支持一下 Kubernetes Operator?’…其实并不是,甚至目标都应该反过来:**我们要做的并不是一个数据库软件,而是一个数据库服务,当我们用更长的眼光去看的时候就会发现,后者是包含前者的。**这个认知的转变是做好数据库云服务第一步,也是最重要的一步。
我们过去开发程序,不同的模块看到的环境是同构且确定的,例如:开发一个单机上运行的软件,不同的模块虽然可以有逻辑上的边界,但是链接到一起之后,运行起来看到的还是这台计算机的一亩三分地,Everything is a trade-off。即使近几年的分布式系统的兴起,但对于经典的分布式软件来说,大致还是单机软件设计思路的延伸,只是通过 RPC 将多台计算机连接在一起,但是仍然环境是相对确定的,尽管很多软件对于底层的环境变化做了一些适配:例如分布式数据库的动态扩容,数据重均衡 Re-balance 等,但是本质并未变化,只是能够操控和调度的资源变多了。但是在云上,这些假设都发生了变化:
假设的变化带来的技术上的变化:云上的数据库,首先应该是 多个自治的微服务组成的网络 。这里的微服务并非一定是在不同的机器上,在物理上可能在一台机器上,但是需要能在远程访问,另外这些服务应该是无状态的(无副作用),方便快速的弹性扩展,这个带来对于开发者的转变就是:放弃对于同步语义的坚持,这个世界是异步化且不可靠的。我很高兴我的偶像 Amazon 的 CTO Werner Vogels 在今年 ReInvent Keynote 上也强调了这一点。放弃掉对于同步和单机的幻想,得到了什么?我们看一些例子:
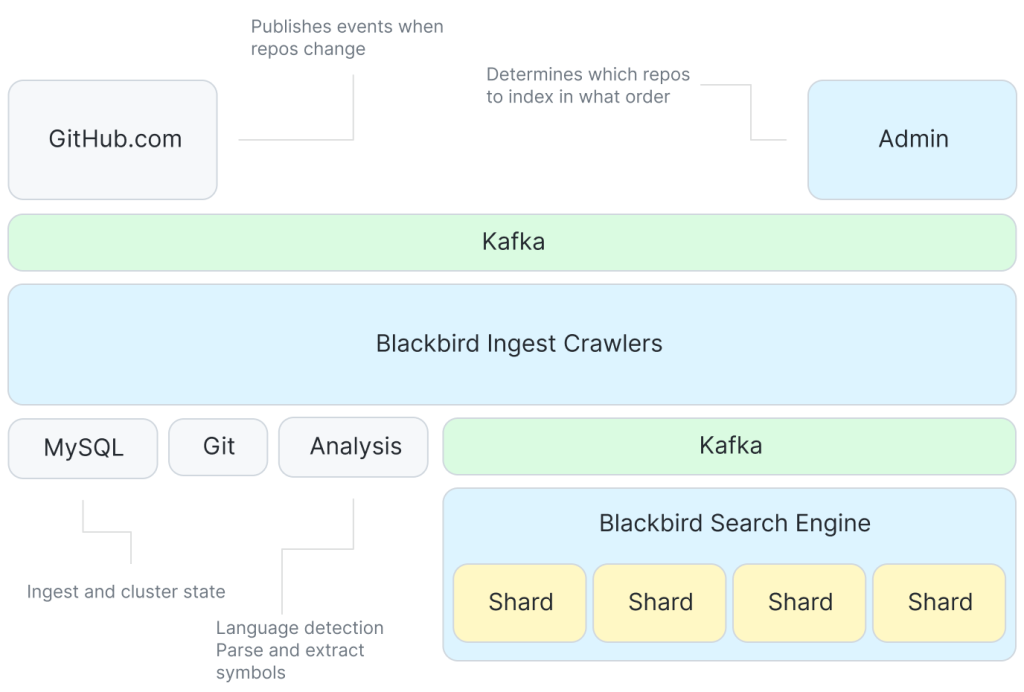
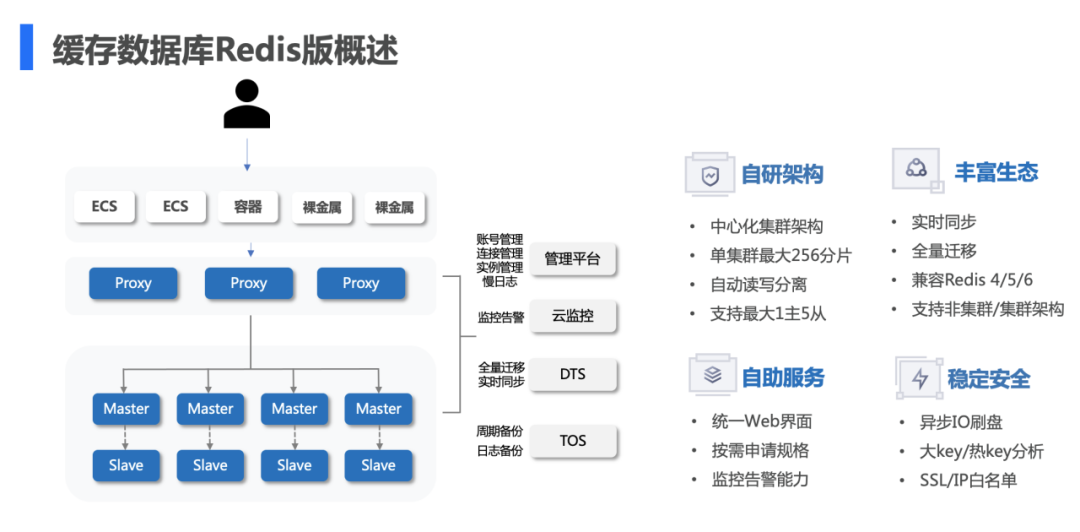
第一,最近几年被聊烂的存算分离