

背景
字节跳动视频业务线上每天都能接收到海量的投稿视频,我们在服务端接收到这些视频时,可以发现由于上传用户的拍摄设备性能层次不齐,存在大量低清低质视频。为了提升这类低清视频的清晰度,我们可以在服务端对其使用超分辨率算法。
超分辨率( Super-Resolution ),是一种提高图像、影片分辨率的技术。分辨率是一种用于描述影像细节分辨能力的指标,即每个方向上的像素数量,分辨率越高,影像清晰度越高。

近年来随着深度神经网络的流行以及发展,相关技术被应用于该场景中,并且其效果大幅领先基于插值的传统算法。
基于神经网络的超分辨率
我们以 SRCNN(Super-resolution convolution neural network )为例,简单介绍基于神经网络的超分辨率算法。网络的输入是一个低分辨率的图像,而输出是一个高分辨率的图像。该过程主要分成三个步骤,区块特征抽取与表达( Patch extraction and representation )、非线性对应( non-linear mapping )以及重建( reconstruction )。
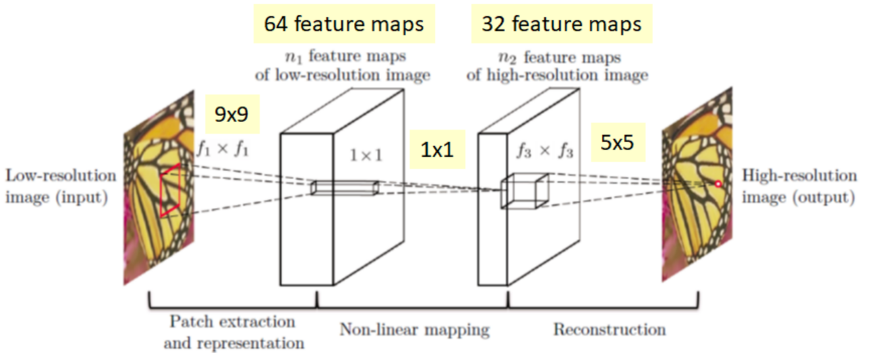
网络的训练方式一般是使用高分辨率的图片作为标签,并且使用 Bicubic 或者 Bilinear 等退化方式得到低分辨率图片作为网络输入,通常使用 L1 或者 L2 的损失函数进行监督。
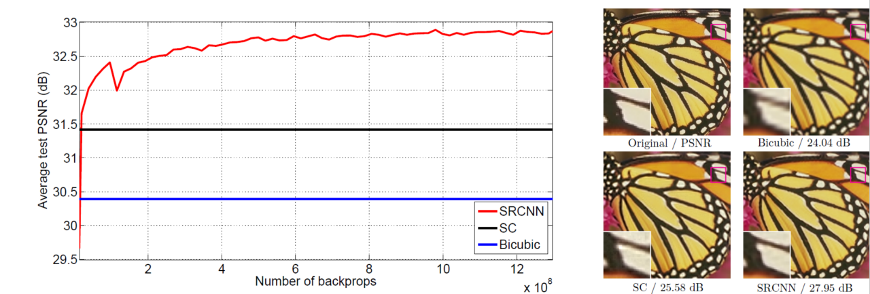
这样训练得到的网络,在客观指标 PSNR 上大幅超过例如 Bicubic 这种基于插值的 Scaling 方法,其中 PSNR 为峰值信号比,是衡量超分辨率算法的重要客观指标。
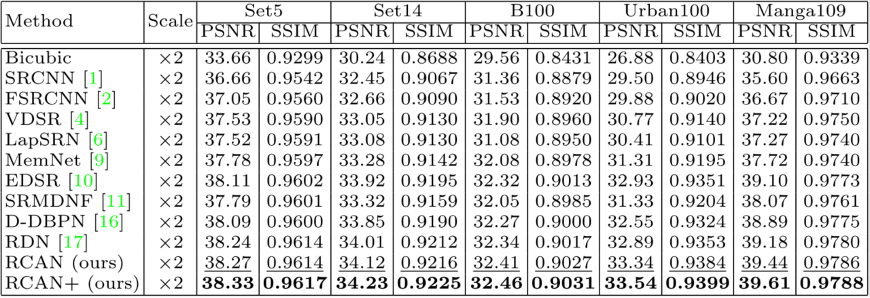
Fig 4. 更多超分辨率算法客观数据对比 [8]
在 SRCNN 之后还出现了众多其他的超分辨率网络的研究,比如 EDSR 、 RCAN 等,但网络框架以及训练方式和 SRCNN 大同小异。
超分辨率的主观效果优化
实际场景效果不佳
我们在实际使用时,往往会发现直接使用以上提到的深度学习超分辨率网络,会出现主观效果不佳的情况。比如对以下表情包的图片使用 pre-trained EDSR 网络,会发现其主观效果和 Bicubic 差不多,对输入的提升效果很有限。我们接下来从几个角度来介绍一些优化超分辨率网络主观效果的方法。
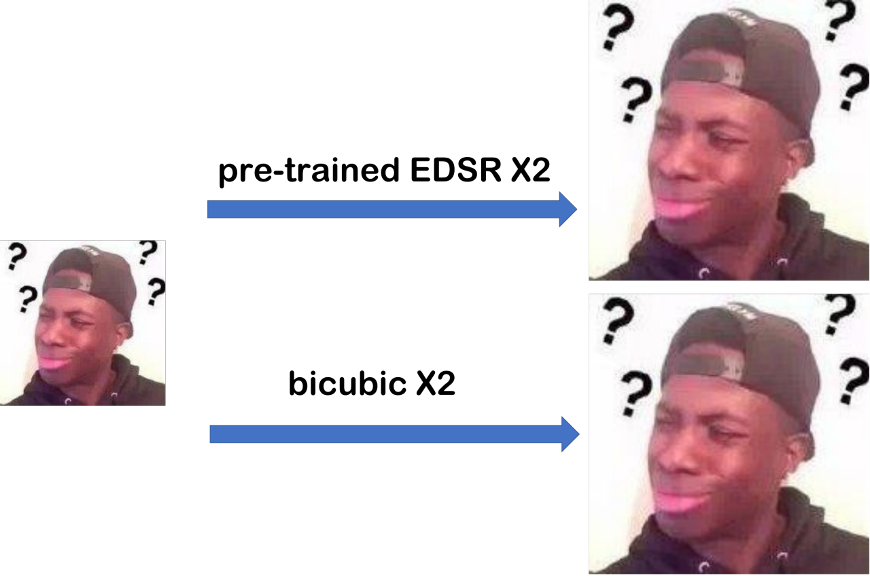
Fig 5. 网络图片 [9 ]使用 EDSR 和 Bicubic 进行上采样的效果对比
基于 GAN 的超分辨率网络
首先我们介绍第一个优化手段。超分辨率是一对多的任务,一个低分辨率图可能有无数个高清图相对应,在这种情况下用 L1 或者 L2 作为损失函数训练,就会导致网络学习的结果会指向所有高清可能的平均,主观上看来即是一片模糊。
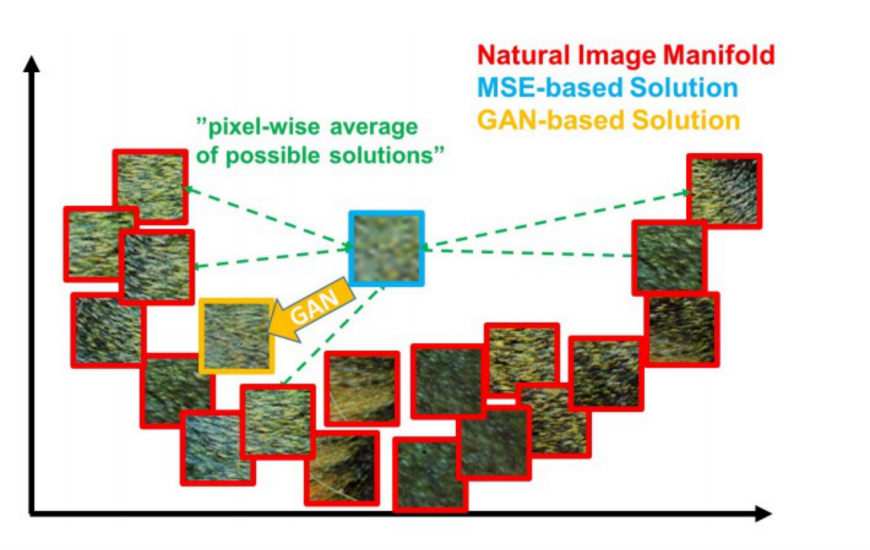
Fig 6. 基于对抗生成网络的超分辨率 [4]
为了解决这个问题,我们可以在网络训练的过程中引入 GANloss ,即使用对抗生成的方式来对超分辨率网络进行训练,通过 GANloss ,我们使得超分辨率网络生成的结果分布在真实、自然的高分辨率图的流形之上,而不是一片模糊的平均结果。
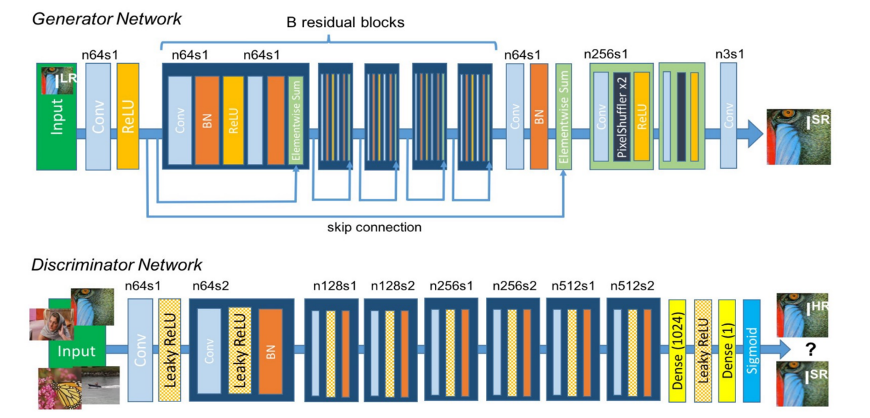
Fig 7. 基于对抗生成网络的超分辨率 [4]
图 8 显示的是在 Set14 测试图片上的部分超分辨率网络主客观表现,我们可以发现 PSNR 指标和主观效果并不一致,并且基于 GAN 的超分辨率算法 PSNR 指标甚至低于 Bicubic。

Fig 8. 基于对抗生成网络的主客观表现 [4]
基于真实下采样优化训练数据
另一个优化点是训练数据。我们以上讨论的超分辨率的训练数据对,往往是通过 Bicubic 或者其他已知下采样方式得到的。然而往往真实场景并不是,从而导致模型训练数据和实际预测数据存在比较大的差距,使得超分算法效果不够理想。
我们这里介绍一种同样基于对抗生成网络的真实下采样生成方式。如图 9 所示,对于一张高分辨率图,我们训练下采样生成器 G 和判别器 D ,使得 G 生成的低分辨率图和真实低分辨率图接近,从而得到真实下采样 G 。得到了 G 以后我们便可以利用高分辨率图大量生成满足真实下采样退化的训练数据对。
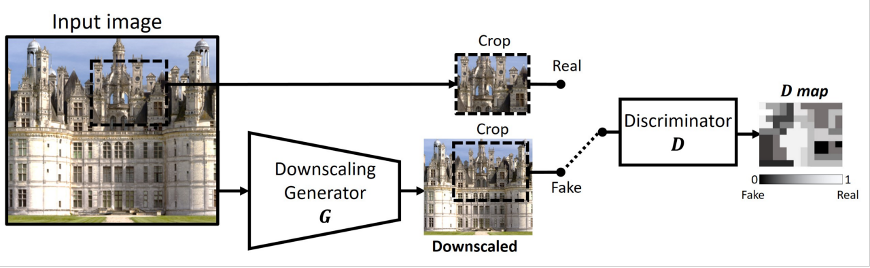
Fig 9. 基于 KernelGAN 的真实下采样生成方式 [6]
在满足真实下采样退化的数据对上进行训练,我们能获得在真实场景下表现较好的超分模型。
引入先验信息
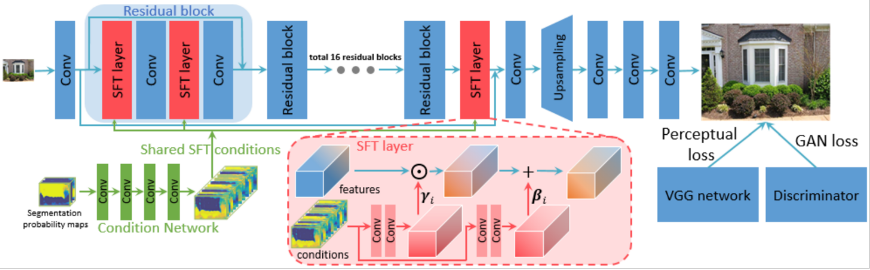
除了以上优化点,另一个比较直接的方法是,在神经网络中加入先验高层语义信息来辅助超分辨率重建。比如在 SFTGAN 中,我们引入一个先验的语义分割网络,以 SFT layer 的形式加入到重建网络中。但是实际场景中,语义信息往往过于复杂,很难用一个网络去进行分析和表达,所以结合通用分割网络的方法也难以明显提升主观效果。但如果局限在部分特殊场景下,这种引入先验知识的方式可以提升超分辨率的效果。
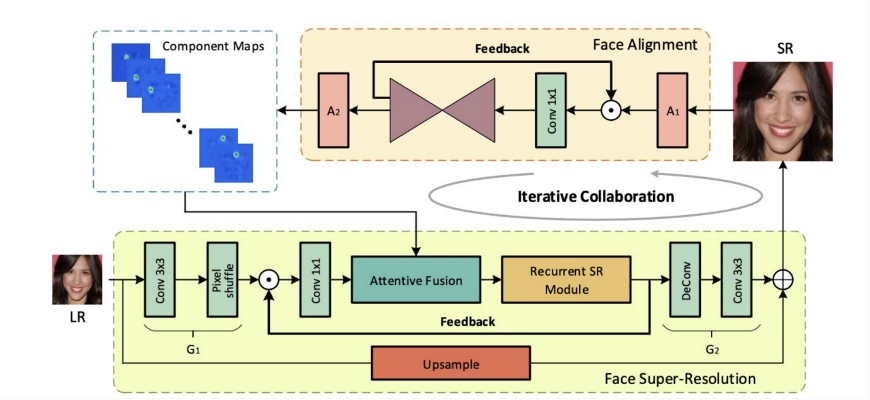
如图 11 所示,如果我们将场景限定到人脸区域,将人脸五官的先验知识融合到超分辨率重建网络之中,能够在主观以及客观上均得到较明显的提升。
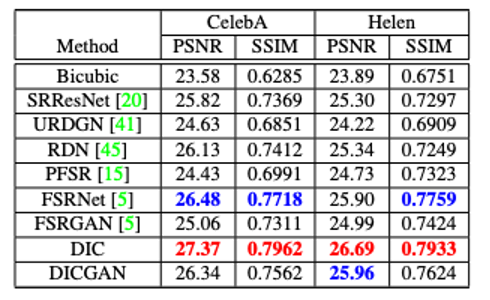

Fig 12.DICGAN 在 CelebA 和 Helen 数据集上的主客观表现 [1]
对输入的噪声进行考虑
在真实场景中,低分辨率输入往往存在除了下采样之外的其他退化,比如噪声、压缩失真、模糊等等。我们在训练超分辨率网络的过程中如果不考虑这些因素,也会使得网络的主观效果较差。因此我们在训练过程同时应该根据应用场景,引入对应的退化。我们在服务端实际使用时,需要对输入的图片进行质量分析。依靠我们所建立的服务端无参考质量评价算法,我们对输入视频在多个维度上进行质量估计,并且对其使用相应退化训练的超分模型进行处理。
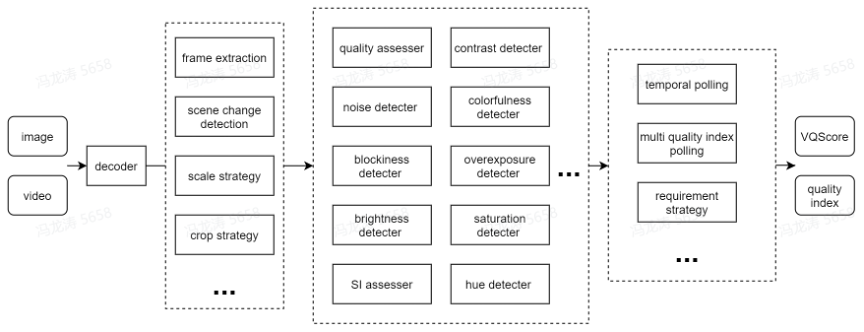
Fig 13. 自研无参考视频质量评价体系
总结
在结合以上所说的优化点后,我们再回顾图 5 中的低分辨率表情包,输入是属于人脸场景,并且存在较强的低质退化问题。我们对其使用上面所讨论的一系列的算法对其进行优化,可以发现处理结果的主观效果得到了极大的提升。
本文对基于深度学习的超分辨率算法主观效果优化,从生成式模型、引入语义信息、优化训练数据、考虑输入退化等多个维度展开了讨论。总的来说,随着视频业务不断扩张,我们每天都能接收到源源不断的投稿视频,一方面视频种类繁多,其次视频质量层次不齐,再者用户对视频清晰度的要求越来越高。在提升视频的分辨率这个问题上,我们需要结合多个算法点并且根据具体场景进行优化使用,才能为用户带来更好的体验。
Fig 13. 左图为 Bicubic 上采样结果,右图为超分优化结果
引用
[1] C. Ma, Z. Jiang, Y. Rao, J. Lu and J. Zhou. Deep Face Super-Resolution With Iterative Collaboration Between Attentive Recovery and Landmark Estimation, 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 5568-5577, 2020.
[2]C. Dong, C. C. Loy, K. He and X. Tang. Image Super-Resolution Using Deep Convolutional Networks, in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 295-307, 1 Feb. 2016.
[3] C. Ledig et al., Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 105-114, 2017.
[4] Wang X. et al. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In: Leal-Taixé L., Roth S. (eds), ECCV 2018 Workshops.
[5] X. Wang, K. Yu, C. Dong and C. Change Loy. Recovering Realistic Texture in Image Super-Resolution by Deep Spatial Feature Transform, 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 606-615, 2018.
[6] Bell-Kligler, Sefi et al. Blind Super-Resolution Kernel Estimation using an Internal-GAN. NeurIPS 2019.
[7] Lim, Bee & Son, Sanghyun & Kim, Heewon & Nah, Seungjun & Lee, Kyoung. Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW, 2017.
[8] Zhang, Yulun and Li, Kunpeng and Li, Kai and Wang, Lichen and Zhong, Bineng and Fu, Yun. ECCV, 2018.
[9]黑人问号
[10]分辨率




