ByConity 作为云原生数据仓库,从 0.2.0 版本开始逐步支持 Extract-Load-Transform (ELT),使用户免于维护多套异构数据系统。本文将介绍 ByConity 在 ELT 方面的能力规划,实现原理和使用方式等。
ETL 场景和方案
ELT 与 ETL 的区别
资源重复的挑战
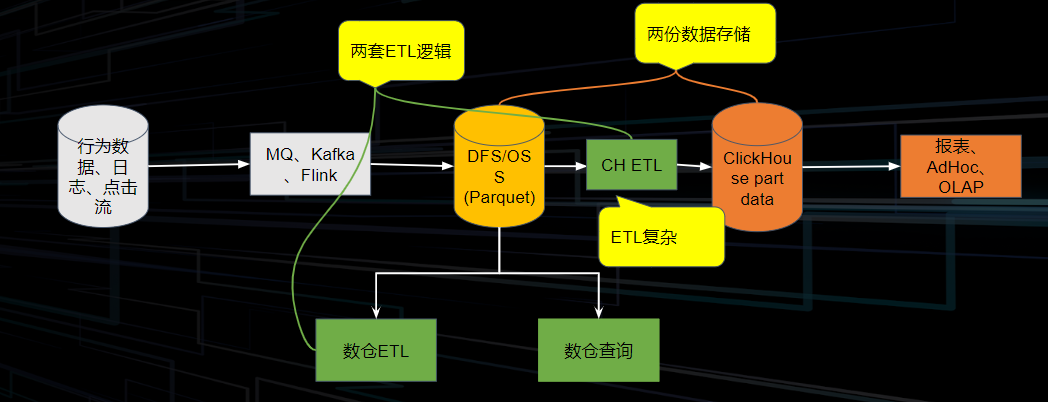
典型的数据链路如下:我们将行为数据、日志、点击流等通过 MQ/ Kafka/ Flink 将其接入存储系统当中,存储系统又可分为域内的 HDFS 和云上的 OSS& S3 这种远程储存系统,然后进行一系列的数仓的 ETL 操作,提供给 OLAP 系统完成分析查询。
但有些业务需要从上述的存储中做一个分支,因此会在数据分析的某一阶段,从整体链路中将数据导出,做一些不同于主链路的 ETL 操作,会出现两份数据存储。其次在这过程中也会出现两套不同的 ETL 逻辑。
当数据量变大,计算冗余以及存储冗余所带来的成本压力也会愈发变大,同时,存储空间的膨胀也会让弹性扩容变得不便利。
业界解决思路
在业界中,为了解决以上问题,有以下几类流派:
ELT in ByConity
整体执行流程
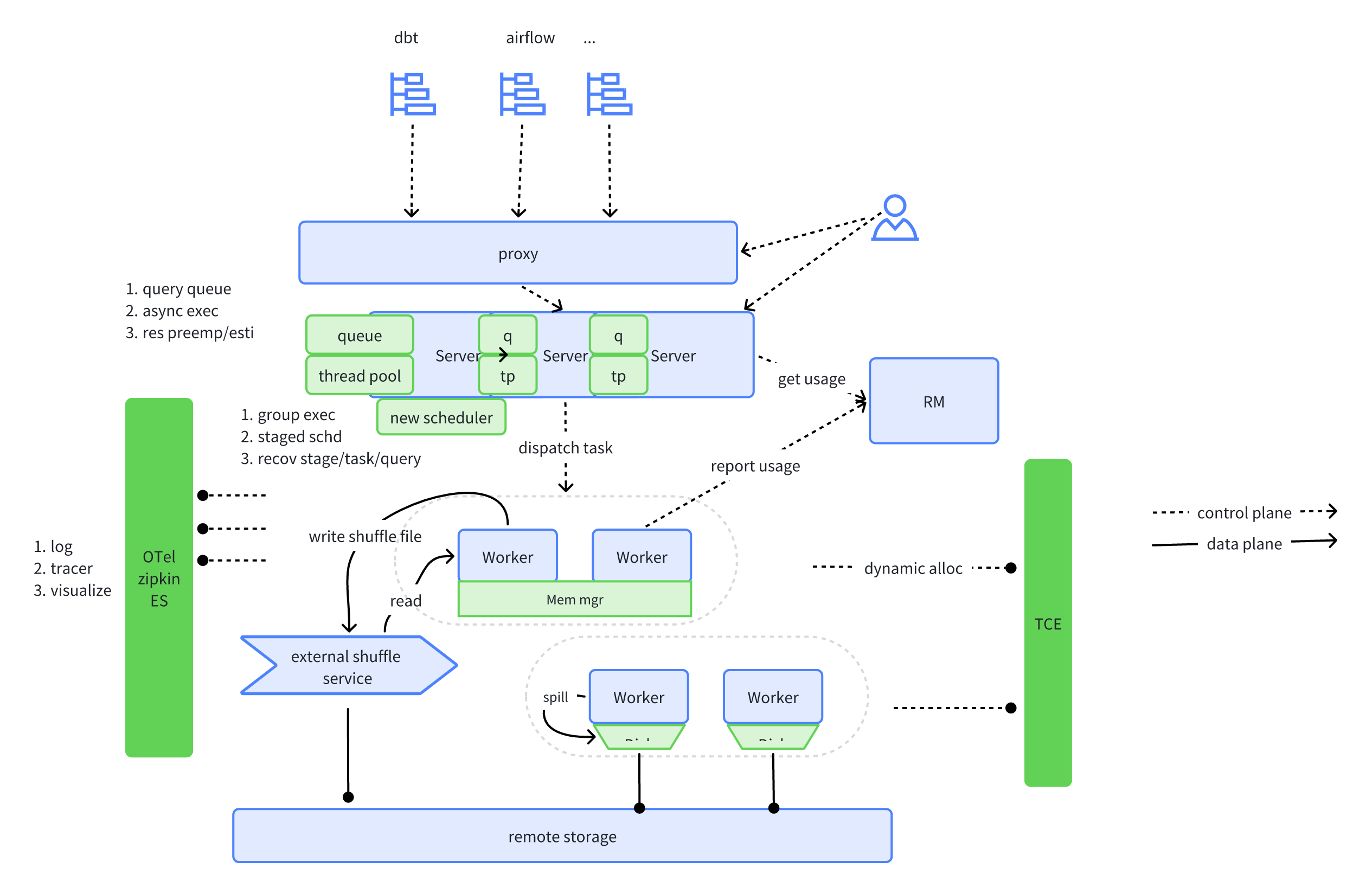
ELT 任务对系统的要求:
ByConity 针对 ELT 任务的要求,以及当前场景遇到的困难,新增了以下特性和优化改进。
分阶段执行(Stage-level Scheduling)
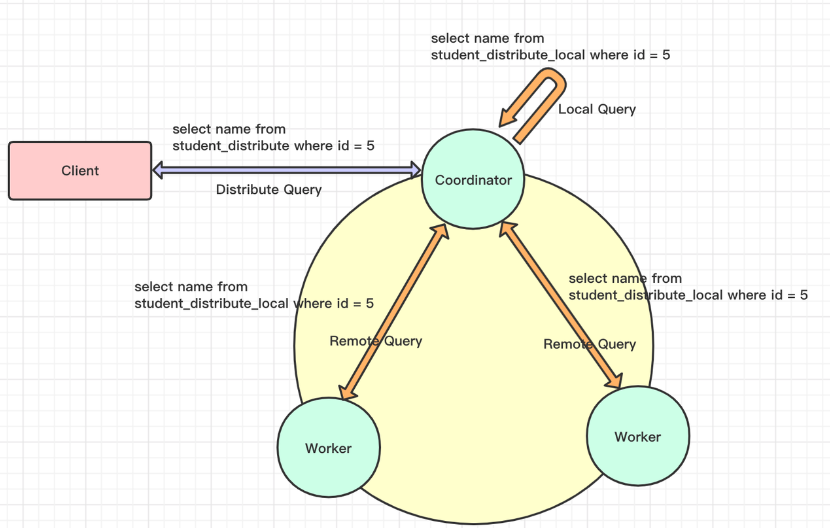
原理解析
当前 ClickHouse 的 SQL 执行过程如下:
ClickHouse 将 Join 操作中的右表转换为子查询,带来如下几个问题都很难以解决:
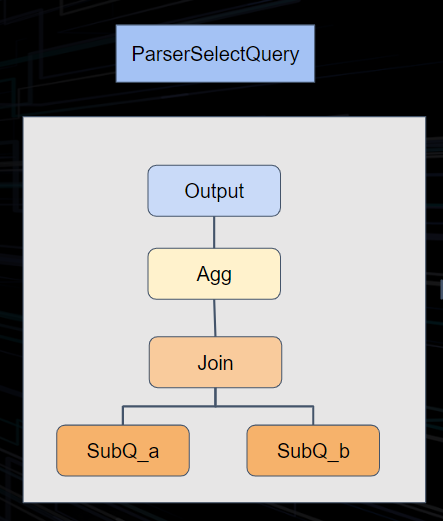
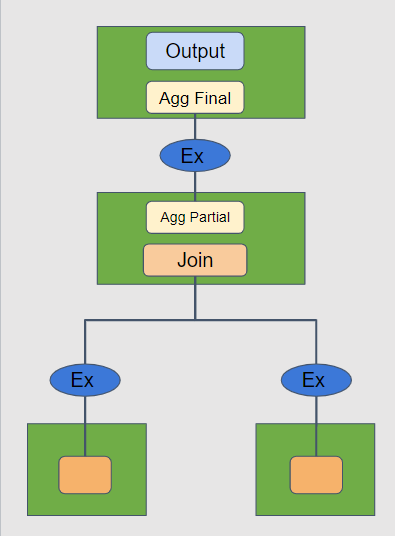
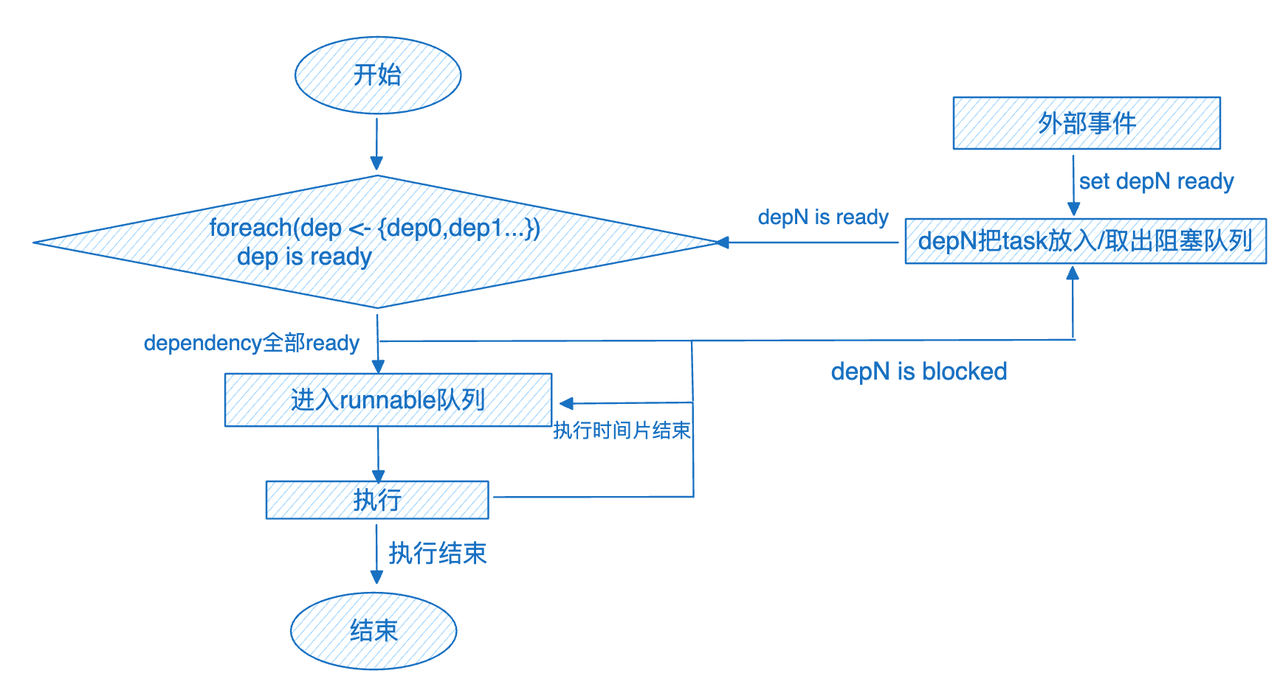
不同于 ClickHouse,我们在 ByConity 中实现了对复杂查询的执行优化。通过对执行计划的切分,将之前的两阶段执行模型转换为分阶段执行。在逻辑计划阶段,根据算子类型插入 exchange 算子。执行阶段根据 exchange 算子将整个执行计划进行 DAG 切分,并且分 stage 进行调度。stage 之间的 exchange 算子负责完成数据传输和交换。
关键节点:
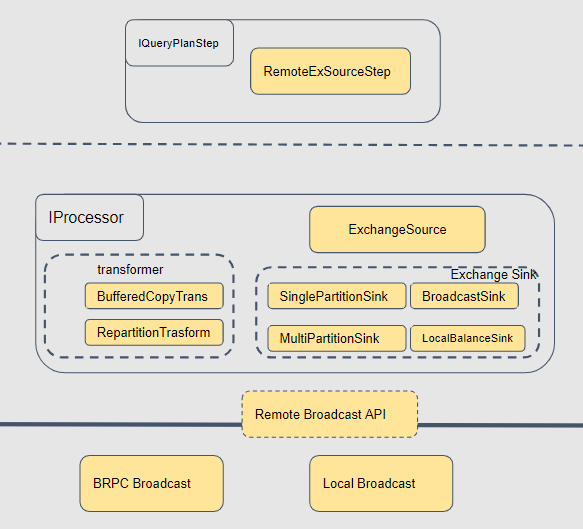
这里重点来讲一下 exchange 的视线。上图可以看到,最顶层的是 query plan。下面转换成物理计划的时候,我们会根据不同的数据分布的要求转换成不同的算子。source 层是接收数据的节点,基本都是统一的,叫做 ExchangeSource。Sink 则有不同的实现,BroadcastSink、Local、PartitionSink 等,他们是作为 map task 的一部分去运行的。如果是跨节点的数据操作,我们在底层使用统一的 brpc 流式数据传输,如果是本地,则使用内存队列来实现。针对不同的点,我们进行了非常细致的优化:
带来的收益
因为 ByConity 彻底采用了多阶段的查询执行方式,整体有很大的收益:
自适应的调度器(Adaptive Scheduler)
Adaptive Scheduler 属于我们在稳定性方面所做的特性。在 OLAP 场景中可能会发现部分数据不全或数据查询超时等,原因是每个 worker 是所有的 query 共用的,这样一旦有一个 worker 较慢就会导致整个 query 的执行受到影响。
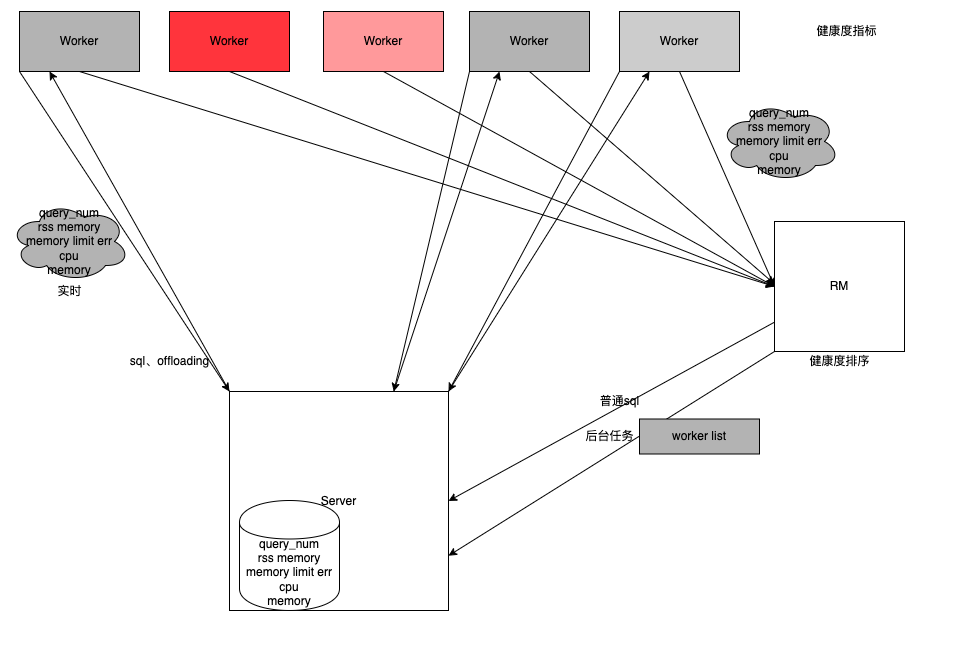
计算节点共用存在的问题:
这就导致 worker 节点之间的负载严重不均衡。负载较重的 worker 节点就会影响 query 整体的进程。因此我们做了以下的优化方案:
查询的队列机制(Query Queue)
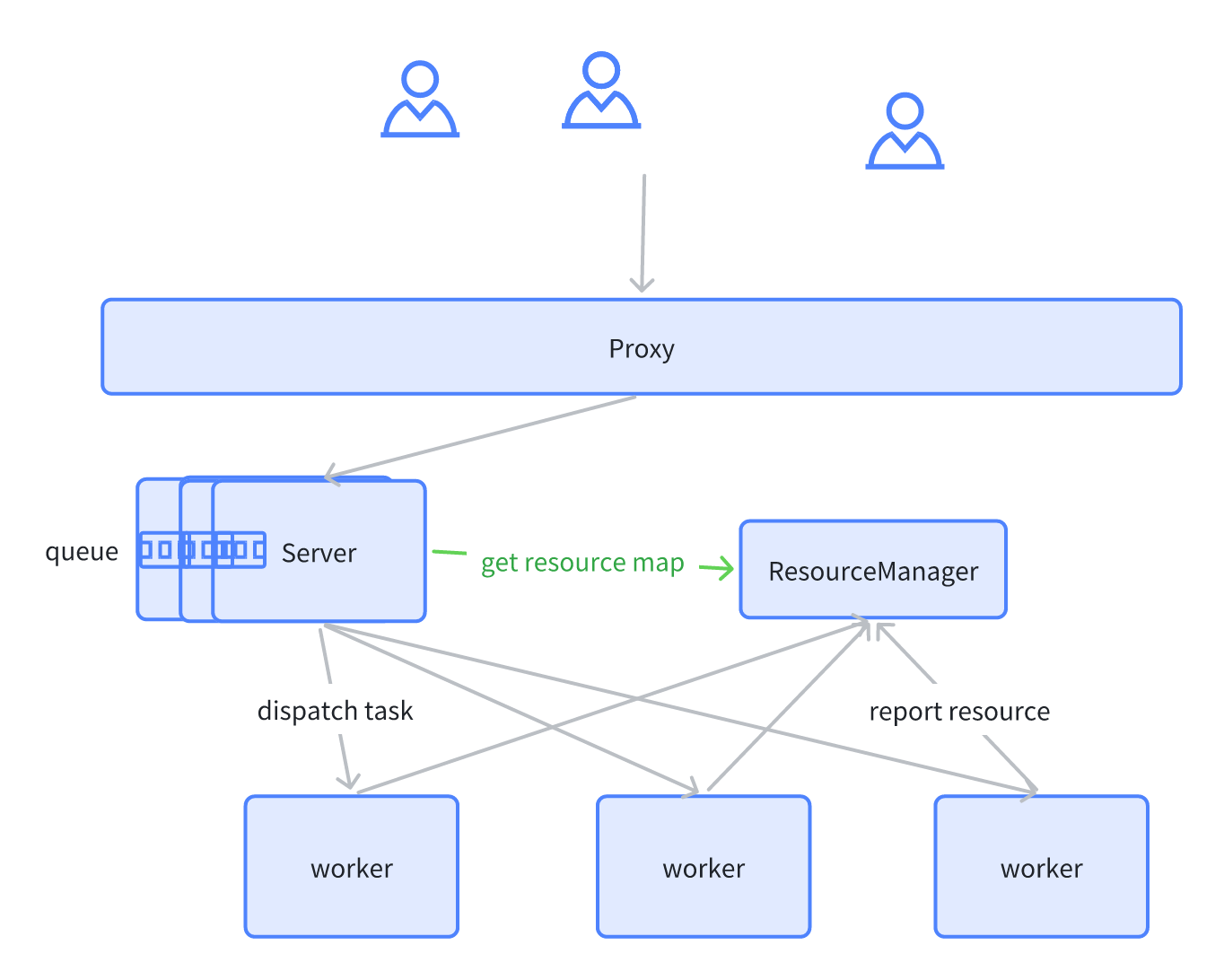
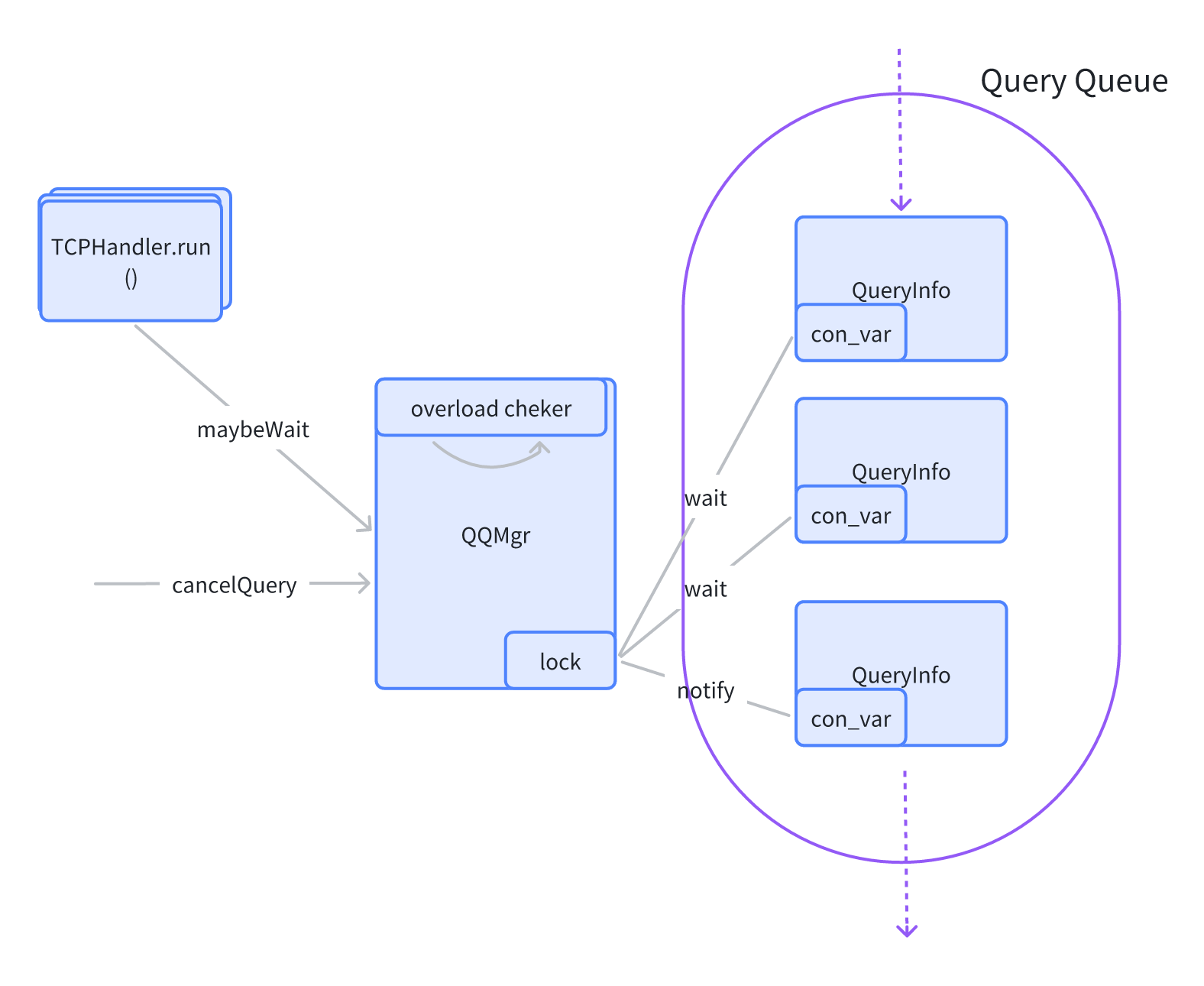
我们的集群也会出现满载情况,即所有的 worker 都是不健康的或者满载/超载的,就会用查询队列来进行优化。
我们直接在 server 端做了一个 manager。每次查询的时候 manager 会去 check 集群的资源,并且持有一个锁。如果资源不够用,则等待资源释放后去唤醒这个锁。这就避免了 Server 端不限制的下发计算任务,导致 worker 节点超载,然后崩掉的情况。
当前实现相对简单。server 是多实例,每个 server 实例中都有 queue,所持有的是一个局部视角,缺乏全局的资源视角。除此之外,每个 queue 中的查询状态没有持久化,只是简单的缓存在内存中。
后续,我们会增加 server 之间的协调,在一个全局的视角上对查询并发做限制。也会对 server 实例中 query 做持久化,增加一些 failover 的场景支持。
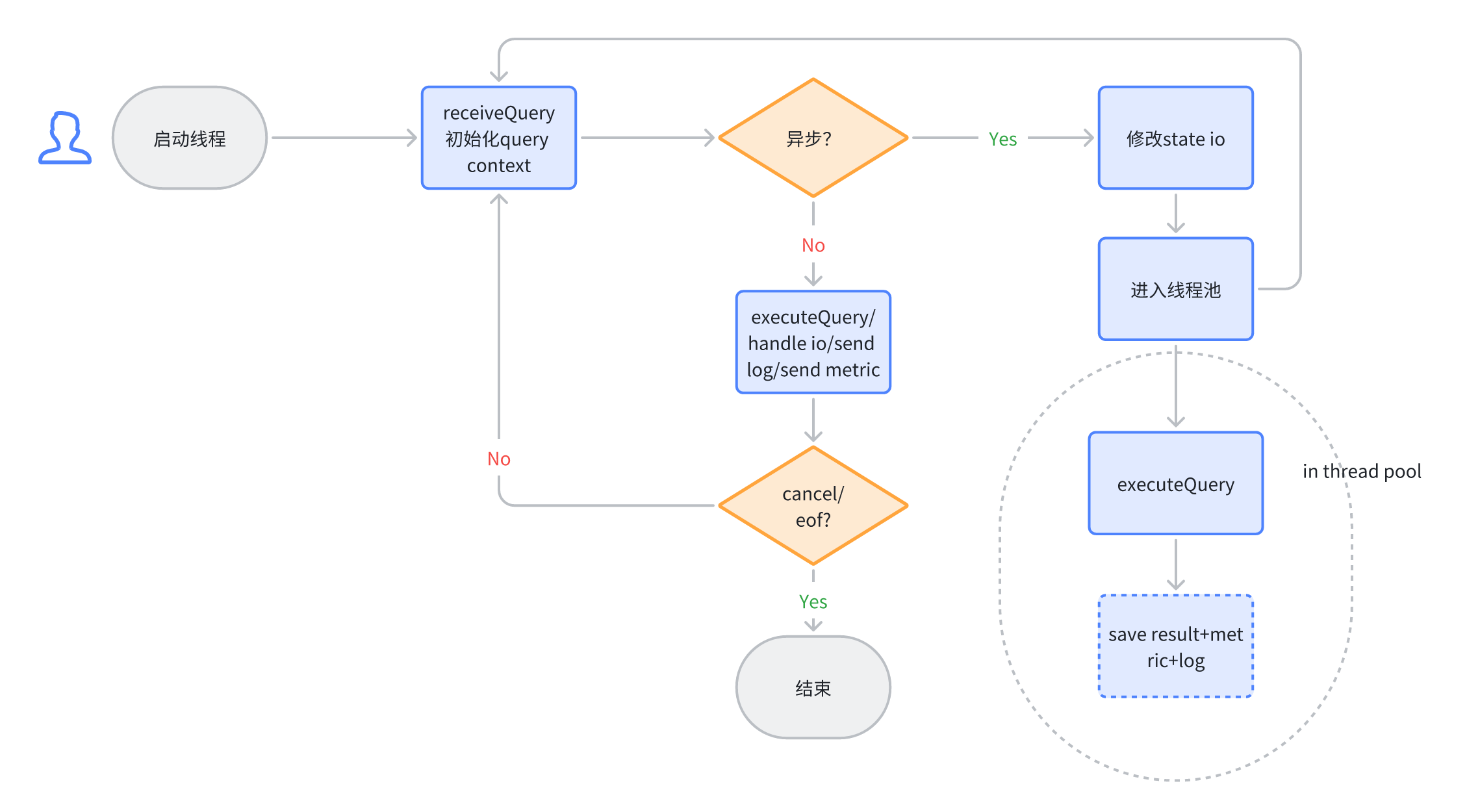
异步执行(Async Execution)
ELT 任务的一个典型特征就是:相对于即时分析,他们的运行时间会相对较长。一般 ELT 任务执行时长为分钟级,甚至到达小时级。
目前 ClickHouse 的客户端查询都采用阻塞的方式进行返回。这样就造成了客户端长期处于等待的情况,而在这个等待过程中还需要保持和服务端的连接。在不稳定的网络情况下,客户端和服务端的连接会断开,从而导致服务端的任务失败。
为了减少这种不必要的失败,以及减少客户端为了维持连接的增加的复杂度。我们开发了异步执行的功能,它的实现如下:
针对 query 的初始化还是在 session 的同步线程中进行。一旦完成初始化,则将 query 状态写入到 metastore,并向客户端返回 async query id。客户端可以用这个 id 查询 query 的状态。async query id 返回后,则表示完成此次查询的交互。这种模式下,如果语句是 select,那么后续结果则无法回传给客户端。这种情况下我们推荐用户使用 async query + select...into outfile 的组合来满足需求。
未来规划
针对 ELT 混合负载,ByConity 0.2.0 版本目前只是牛刀小试。后续的版本中我们会持续优化查询相关的能力,ELT 为核心的规划如下:
故障恢复能力
资源
相关专题推荐: 《开源云原生数仓ByConity技术与实践全解》