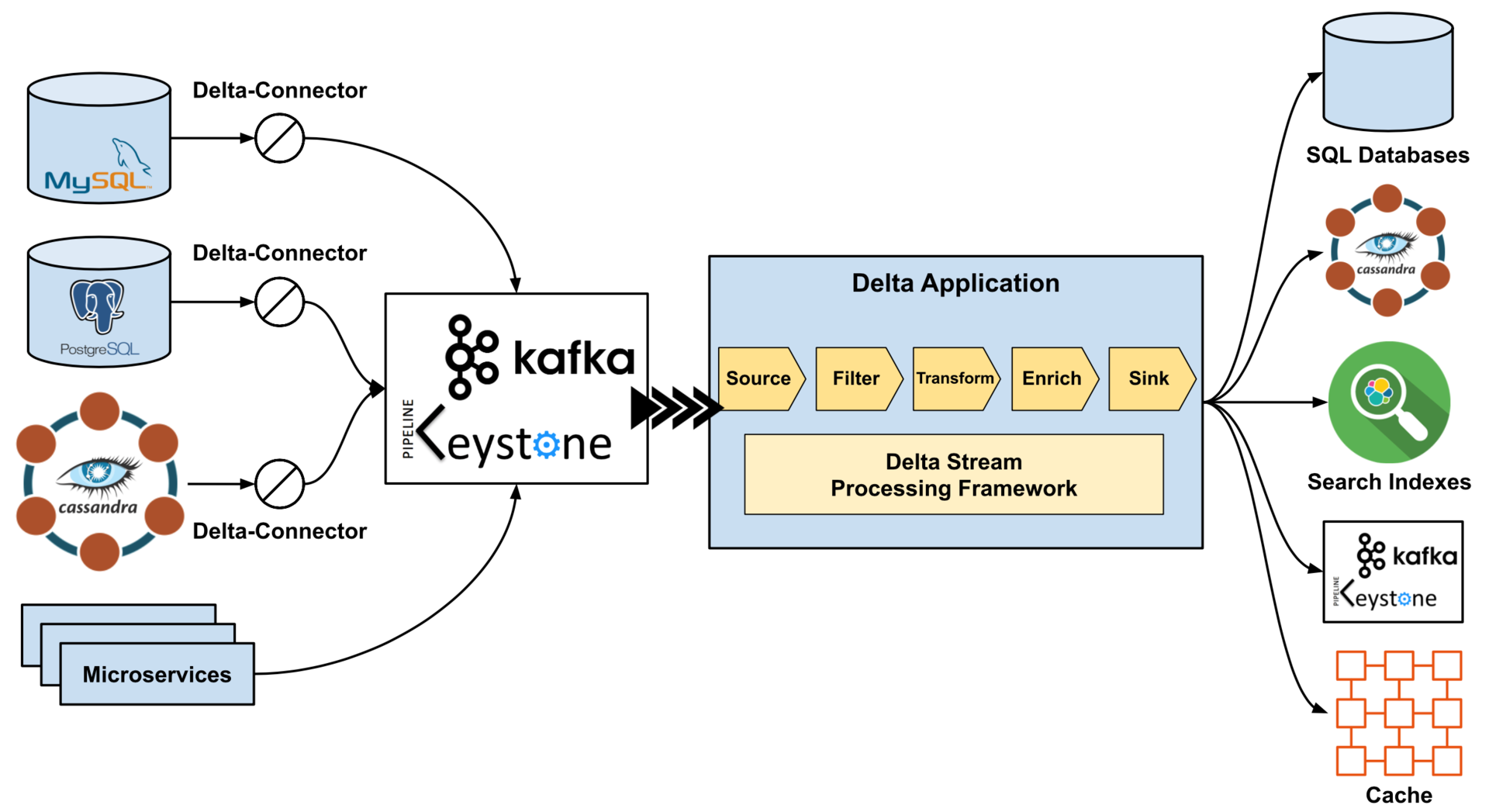
本文将介绍如何从数据湖以及 JDBC 连接数据库中的数据源增量加载数据,并且还会展示如何通过作业书签使 AWS Glue ETL 作业仅读取新添加的数据,以及如何通过在之前的作业运行结束时重置作业书签,让 AWS Glue ETL 作业处理晚到达的数据。本文还将回顾作业书签与复杂的 AWS Glue ETL 脚本和工作负载配合使用的最佳实践。最后,本文将介绍如何使用经过性能优化的自定义 AWS Glue Parquet 写入器,可以在运行时计算架构,避免额外的数据传输。AWS Glue Parquet 写入器还通过添加或删除列支持数据集的架构演变。