一、背景
监控上收到了大量慢查的告警,业务也反馈查询很慢,随即打开电脑确认慢查的原因。
二、现象描述
通过平台的慢查分析之后,我们发现慢查有以下特征:
三、问题分析
通对慢查的大致分析,SQL 本身没有发现问题。那么是不是主机或者网络等有问题呢?
经过对网络和主机磁盘的 IO 等的分析,负载均正常,没有丢包的现象。
回到数据库本身,慢查还在,确认下慢查到底是慢在哪里。
当慢查在执行的时候,大部分的都是表现在 Sending>
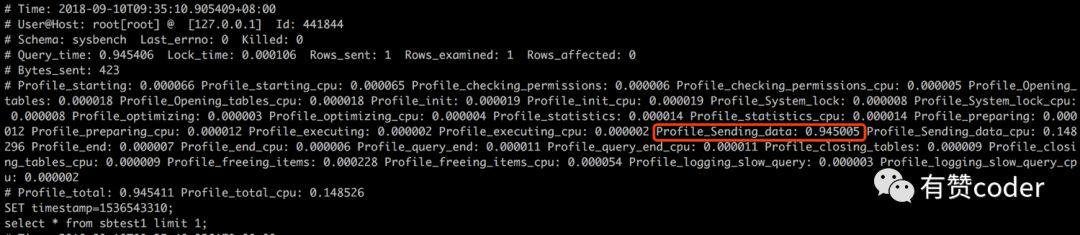
从图中,我们可以看到
sending>
那么
sending>
Sending>
那为啥只取 limit 1,而且没有 where 条件的 SQL 执行扫描一行数据会这么慢呢?
打开监控,看看有没有啥指标异常。
我们注意到数据库的
History list length
这个指标一直在升高,达到了几万。慢查的执行时间是随着
History list length
升高而变的更慢。当
History list length
一直居高不下的时候,说明了有大量的 UNDO 没有被 purge。由于当前数据库的隔壁级别是 RR,开始比较早的事务,如果还没提交,就需要通过 UNDO 去构建对应版本历史时,保证数据库的可重复读(跟 MVCC 有关)。
既然
History list length
那么高,可能是有历史事务出现异常没有提交,也有可能是一致性快照的备份。可以通过 information_schema.innodb_trx 表去确认对应的事务信息。经过查询,的确发现一个事务执行了 4 个小时左右,没有提交,且不是备份用户。手动将该线程执行 kill 操作,慢查消失。
3.1 聊一下 MVCC
MySQL支持多版本,可以在普通的时不加锁。利用多版本读取指定版本的行记录,降低加锁的次数,能极大提高数据库的并发读写能力。
在事务的某个时刻记录下 MySQL 所有的活跃事务列表,保存到里面。在之后的查询中,通过比较记录的事务 ID 和里面的事务列表,判断记录是否可见。
3.1.1 Innodb 行记录
在 Innodb 的行结构中,还存在三个系统列,分别是
DATA_ROW_ID
、
DATA_TRX_ID
、
DATA_ROLL_PTR
。
3.1.2 read view
是在 SQL 语句执行之前申请的,其中 RC 隔离级别是每个 SELECT 都会申请,RR 隔离级别的是事务开始之后的第一个 SQL 申请,之后事务内的其他 SQL 都使用该。
中有三个变量需要重点关注:
3.1.3 判断记录可见
3.1.4>UNDO 日志是 MVCC 的重要组成部分,当一条数据被修改时,UNDO 日志里面保存了记录的历史版本。当事务需要查询记录的历史版本时,可以通过 UNDO 日志构建特定版本的数据。
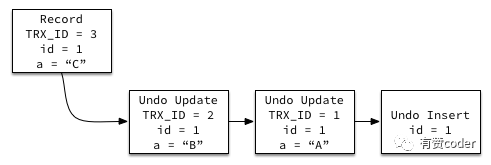
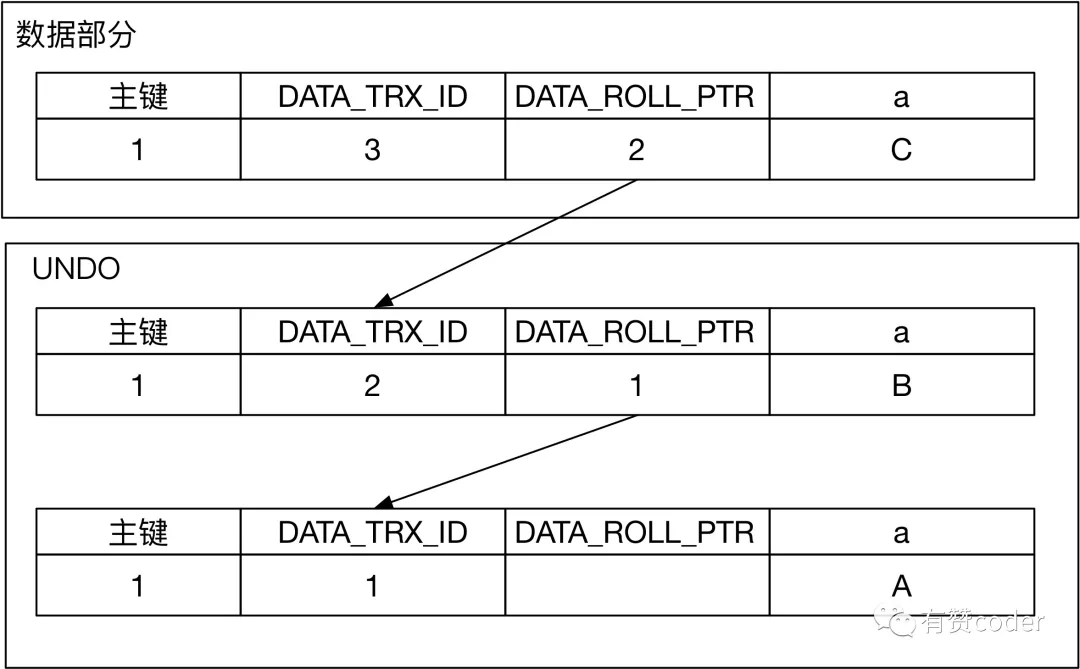
每条行记录上面都有一个指针
DATA_ROLL_PTR
,指向最近的 UNDO 记录。同时每条 UNDO 记录包含一个指向前一个 UNDO 记录的指针,这样就构成了一条记录的所有 UNDO 历史的链表。当 UNDO 的记录还存在,那么对应的记录的历史版本就能被构建出来。
当记录对应的版本通过
DATA_TRX_ID
比对发现不可见时,通过系统列
DATA_ROLL_PTR
,找到对应的回滚段记录,继续通过上述判断记录可见的规则,进行判断,如果记录依旧不可见,继续通过回滚段查找之前的版本,直到找到对应可见的版本。
3.2 慢查问题复现
经过和业务方沟通,得知该表每天都有定时任务,会删除历史数据。大致了解到整个过程后,我们搭建模拟环境进行测试。
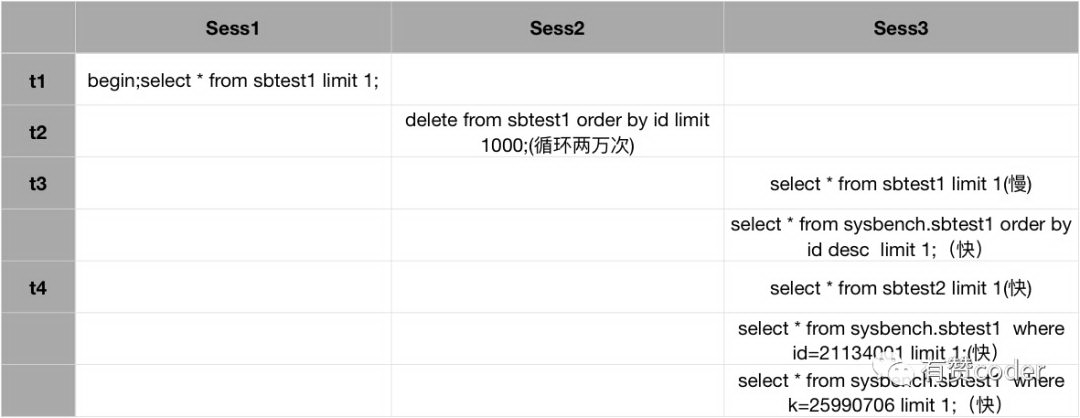
测试分为三个 session,其中 Sess1 执行长事务,没有提交。Sess2 对表的历史数据做清理,清理了 2000 万的数据。此时在 Sess3 执行查询,快慢情况如上图所示。
select * from sbtest1 limit 1
跟预期表现一样,为很慢。但是
select * from sbtest1 order by id desc limit 1
执行很快,这是为什么呢?
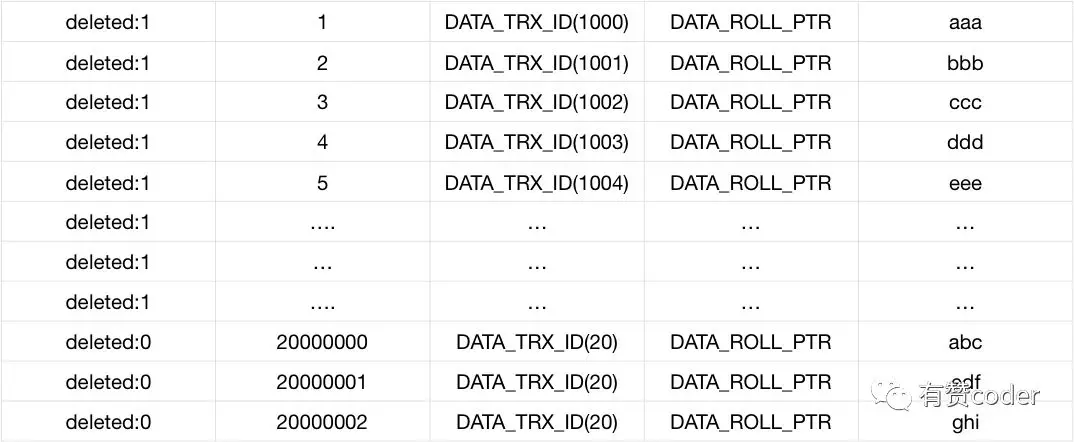
上图为主键的记录格式,在每条主键记录的前面有个删除标志位,然后是主键 ID,事务 ID,回滚段指针,最后是行记录。
当记录被执行删除的时候,MySQL 只是将记录标记为已删除,同时更新
DATA_TRX_ID
为自己删除会话的事务 ID,并没有将记录真正删除。当被删除的记录不再被其他事务需要的时候,会被
purge 线程
删除。
purge 线程
负责清理这些真正被删除的记录以及不再需要的 UNDO 日志。
回到慢查本身,我们来看看慢查的执行过程。
SQL 为
select * from sbtest1 limit1
。
由于被删除的记录有 2000 万,Innodb 需要扫描 2000 万的记录,才能找到符合条件的第一条记录,然后返回到 MySQL 的 Server 层。
当 SQL 为
select * from sbtest1 order by id desc limit1
。
由于删除的是老数据,当从 ID 最大的方向开始扫描时,通过 MVCC 判断可见,然后判断记录是否被标记为删除的时候,记录没有被删除,因此就可以快速返回到 Server 层,SQL 执行效率就会很高。