ZooKeeper 最早起源于雅虎研究院的一个研究小组。当时,雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的 Pig 项目),雅虎的工程师希望给这个项目也取一个动物的名字。当时研究院的首席科学家 RaghuRamakrishnan 开玩笑说:“再这样下去,我们这儿就变成动物园了!”是不是很有趣,顺势大家就表示既然已经是动物园了,它就叫动物园管理员吧!各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 ZooKeeper 正好要用来进行分布式环境的协调一一于是,ZooKeeper 的名字也就由此诞生了!
ZooKeeper 概述
ZooKeeper 是一种用于分布式应用程序的分布式开源协调服务。它公开了一组简单的原语,分布式应用程序可以构建这些原语,以实现更高级别的服务,以实现同步,配置维护以及组和命名。它被设计为易于编程,并使用在熟悉的文件系统目录树结构之后设计的数据模型。它在 Java 中运行,并且具有 Java 和 C 的绑定。
众所周知,协调服务很难做到。他们特别容易出现诸如竞争条件和死锁等错误。ZooKeeper 背后的动机是减轻分布式应用程序从头开始实施协调服务的责任。
集群模型
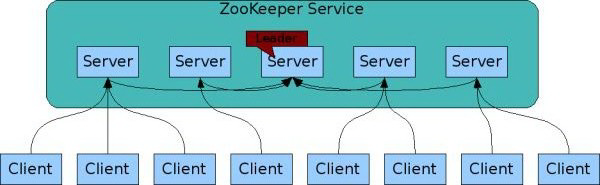
Leader 服务器是整个 ZooKeeper 集群工作机制中的核心,其主要工作有以下两个:
从角色名字上可以看出,Follewer 服务器是 ZooKeeper 集群状态的跟随者,其主要工作有以下三个:
Observer 充当了一个观察者的角色,在工作原理上基本和 Follower 一致,唯一的区别在于,它不参与任何形式的投票。
数据结构
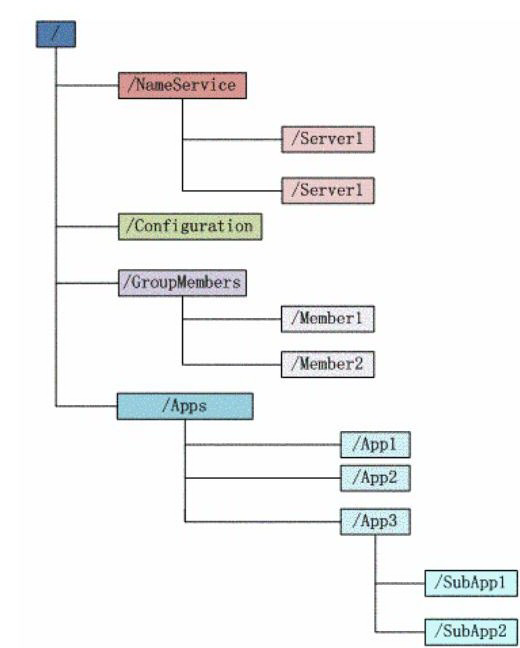
树形结构
首先我们来看上述数据节点示意图,从而对 ZooKeeper 上的数据节点有一个大体上的认识,在 ZooKeeper 中,每一个节点都被称为一个 ZNode,所有 ZNode 按层次化机构进行组织,形成一棵树。ZNode 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠(/)进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。
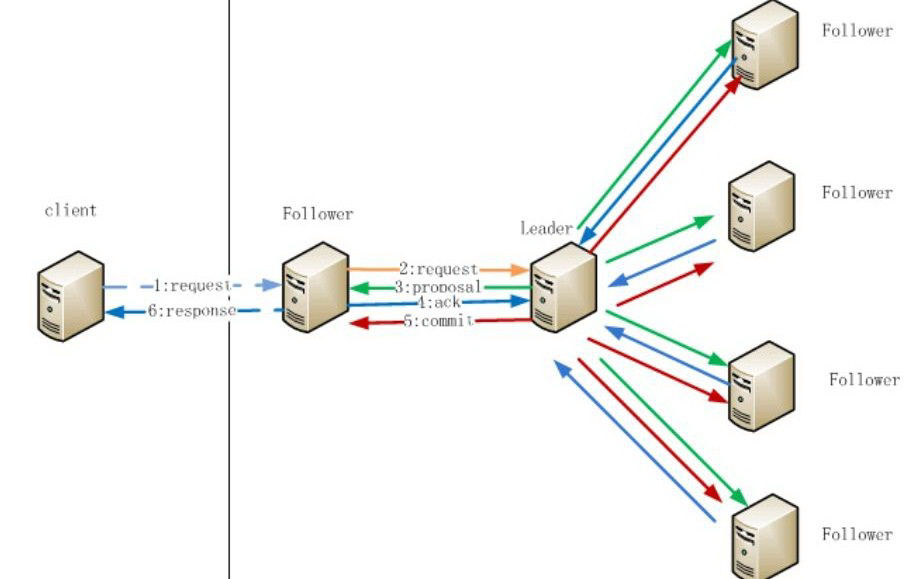
节点操作流程
设计目标
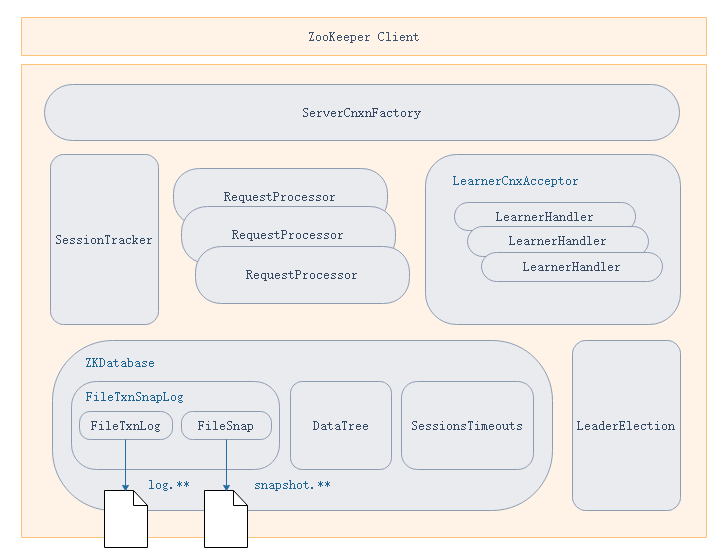
整体架构
原文链接 :