作者 | 作业帮大数据团队(孙建业、白振冬)
历史背景
历史采集链路比较陈旧,随着公司业务变化,对数据采集要求变高。历史采集能力主要暴露出三个方面的问题。

目标和挑战
23 年我们完成了日志采集入湖,整体运行效果很好。为解决上述问题。我们决定将 Mysql 采集由入 Hive 改为 Iceberg。在整个过程中我们还需要平衡以下问题。
方案设计
方案对比

方案一:Flink Upsert 方式直接写 Iceberg 表
方案二:较方案一增加定时同步分区快照数据
方案三:写入改为增量,利用 Spark 做 Merge 写入历史 ODS
设计细节
Iceberg 表设计
Iceberg 表存储的是 Change Log 数据。为了保证采集流程做到表级别隔离,避免互相影响导致核心表就绪时间晚,采用每组(适配单集群分库分表场景) MySQL 表对应一个 Iceberg 表。将 Iceberg 表抽象为灵活且一致的 Schema,既可以保障字段变化的扩展性,也降低了字段类型映射等平台的开发成本。Iceberg 查询场景为全列 Scan,也不用顾虑复杂类型查询无法下推的影响。
基于 Flink CDC 采集设计
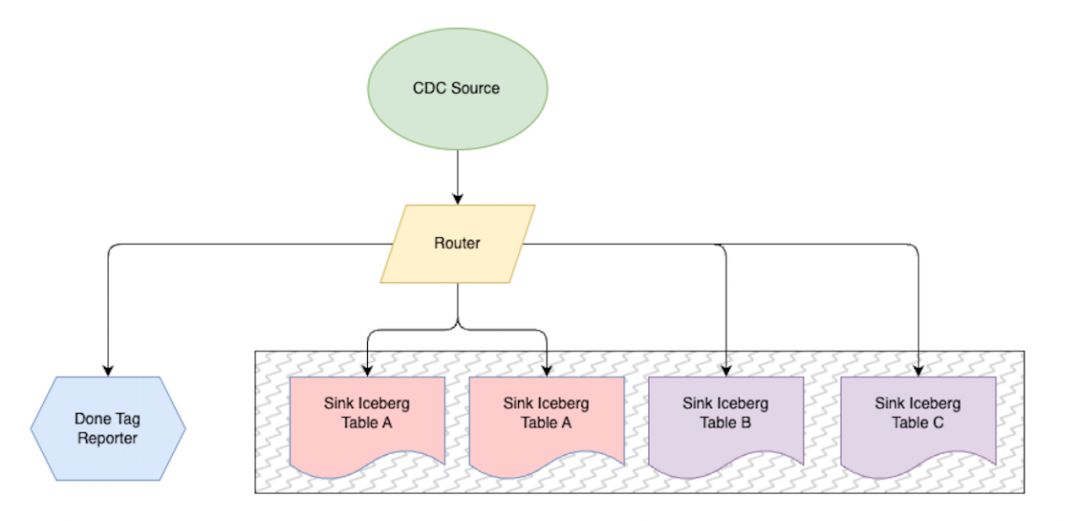
在实际运行过程中还遇到了一些问题。具体情况如下
Spark Merge 任务设计
之前设计主要以 Jar 形式开发全量和增量 Binlog Merge 任务,较 SQL 而言存在明显弊端。例如血缘解析需要额外开发,无法天然享受到计算引擎升级和优化带来的收益,开发效率低。参考了一些湖的设计思路,同时统计了增量 Binlog 数据特点,最新数据更新概率更高。在 SQL 逻辑表达时采用了全量 anti join 减去增量变化的数据,再 union row number 后的增量数据形成最新分区 ODS,较全量 union -> sort -> row number 方式计算效率提升大概 50%。
不同表在数据量、更新频率、单行大小等方面存在的差异较多,为简化任务资源设置,减少人力运维成本,借助 Spark AQE 能力沉淀了一套适合我们场景的集群环境,在保障任务稳定的同时消耗资源也非常少。在实际运行中还遇到一些其他问题。例如
对数 & 迁移
为了保障数据准确性,兼顾迁移速度。在对数上采用 sum hash 全部列的方式,然后在通过新老表主键 join,判断最终 sum 值是否一致。既可以计算出数据 diff 率,也方便抽样数据发现问题。在不同特点的数据上采用不同的对数方案,主要以增量对数为主,全量对数补充,当两者都无法满足需要时采用和业务 MySQL 对数的方式;
收益和效果
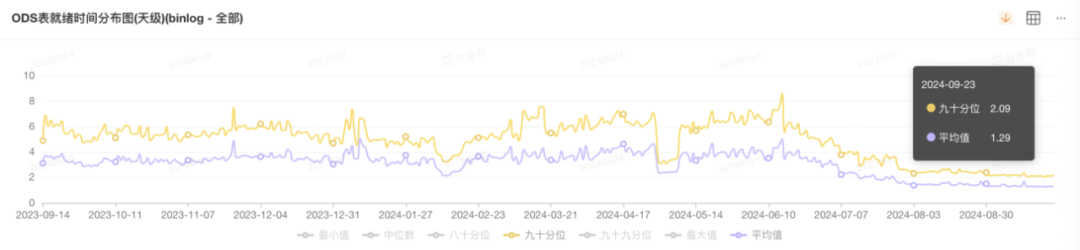
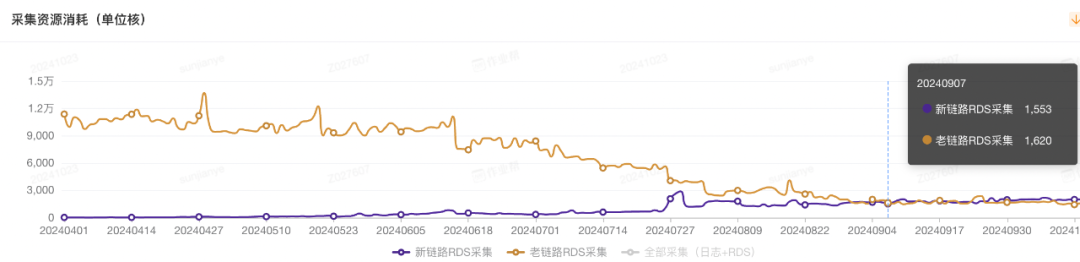
今日好文推荐
数据碎片化、基础设施落后,看金奖团队如何为农业生产转型提供新解法
美国大选倒计时:软件崩溃、密码泄漏,投票系统研发人员比候选人更“焦虑”?
“前端”架构真的有必要存在吗?
C/C++ 大限将至?美政府给出最强硬要求:2026 年前关键软件必须开始全面去 C
会议推荐
就在 12 月 13 日 -14 日,AICon 将汇聚 70+ 位 AI 及技术领域的专家,深入探讨大模型与推理、AI Agent、多模态、具身智能等前沿话题。此外,还有丰富的圆桌论坛、以及展区活动,满足你对大模型实践的好奇与想象。现在正值 8 折倒计时,名额有限,快扫码咨询了解详情,别错过这次绝佳的学习与交流机会!