丰巢第一次在生产环境实际使用 TiDB,是在 2018 年,其场景是每天产生一亿条以上数据的推送平台,当时我们还发了一篇文章,被 PingCAP 官方收录:TiDB at 丰巢:尝鲜分布式数据库。这次,因为实际的项目需要,我们选择了 QPS 和数据一致性要求更高的支付平台,作为第二个迁移到 TiDB 上的项目。由于丰巢的所有支付,都会通过该平台产生,所以其稳定性和性能,都是重中之重了,而这次的迁移之旅,也就特别的漫长和曲折。
1. 支付平台现状及问题
在迁移 TiDB 之前,丰巢支付平台全部运行于 MySQL 之上,其基本情况如下:
2. TiDB 的优势
为了寻求更好的解决方案,让支付平台更加稳健,我们再次把目光投向了 TiDB,尝试做为支付平台的核心解决方案。相比于 Mysql,其优势如下:
3. 迁移之路
3.1 标准步骤方案
在支付平台迁移之初,我们就提出了 TiDB 迁移的标准化方案,支付平台在迁移的过程中,除了部分步骤是需要反复执行之外,大体上都是按照标准化方案来走的。
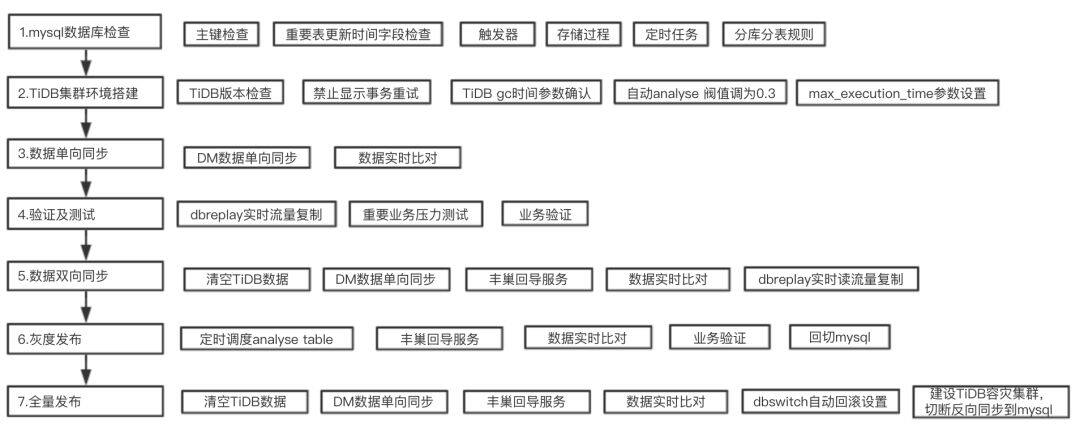
如上图所示,我们没有采用 先切读流量到 TiDB 集群和双写 的方案,而是直接切换到 TiDB 之上。这主要是基于以下的几点原因:
长期使用建立的信心:我们使用 TiDB 已经有半年了,对其稳定性有相当的信心
加快迁移速度:减少业务系统的改造,双写是需要业务系统改造代码的
一致性验证前置: 在灰度发布之前我们需要使用专门的业务压力测试工具进行一致性和压力验证
外部安全性保障:数据比对贯穿于整个迁移的过程中,发现异常随时告警
3.2 数据同步方案
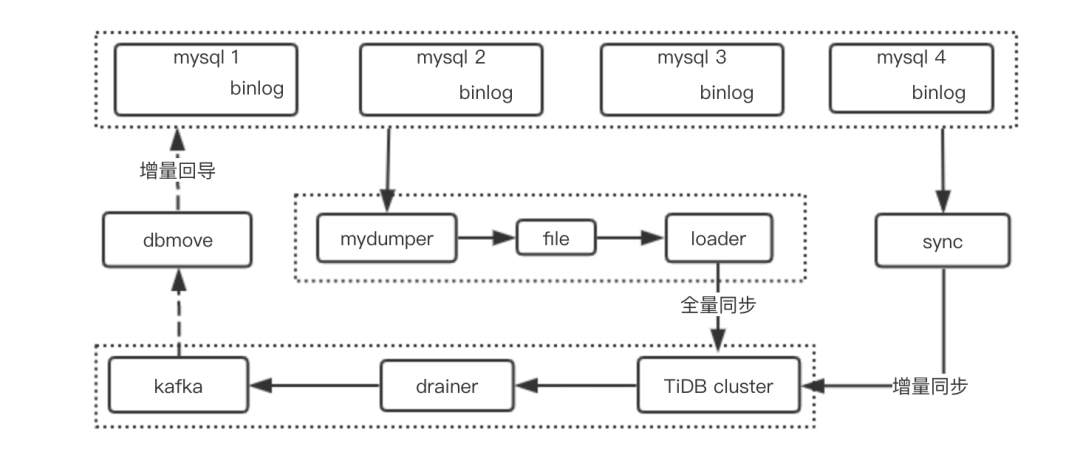
数据库迁移从来就不是容易的事情,为了让支付平台的数据,无缝的从 Mysql 迁移到 TiDB,我们制定了如下数据同步策略和框架:
由上图可知,我们的数据同步包括了三种同步机制:
1.全量同步到 TiDB 集群
借助开源工具 mydumper 和 pingcap 公司的工具 loader 来实现,为了不影响 4 个 master,mydumper 是从 4 个 slave 进行数据的拉取。因为支付平台的数据总量超过 100 亿,所以这个同步的过程是非常漫长的,要花费几十个小时,由于当时没有使用 DM 这样自动化的同步管理平台,这个过程是痛苦且漫长的。以后有这种类似 mysql 到 TiDB 的同步需求,我们都会使用 DM 来完成。
2.实时增量同步
使用 pingcap 公司的 sync 来实时读取 mysql 的 binlog,增量同步数据到 TiDB 集群。
3.数据实时回导到 mysql
为了让数据实时回导,我们研发了两个工具,来确保完全可靠:
3.3 流量回放方案
在一开始制定的迁移方案中,本来是没有流量录制和回放这个工具的。但是因为第一次迁移失败,就促使我们开发了这样的一个工具: DBReplay。其目的在于生产环境流量录制和回放,这是至关重要的一个工具。使用 DBReplay,我们可以发现如下问题:
DBReplay 的整体架构图如下:

它具备下面的 Feature:
以上列举的问题,都是在使用 DBReplay 流量回放工具,回放暴露出来的问题,前 3 个问题后面会详细的分析。
在实际的迁移过程中,会存在一些特殊的情况,超出了我们的掌控外围之外:例如,业务上新增了表和字段,我们没有办法靠人去对齐这些事情,dbreplay 最大的价值就是能够覆盖这些业务逻辑的变化。在前面讲述标准化迁移方案里面,正因为有了 DBReplay 等工具的存在,我们才能放心的,不经过灰度直接全量切换到 TiDB。
3.4 灰度发布方案
我们在制定灰度发布方案的时候,一开始在切流量的问题上有一定的讨论:
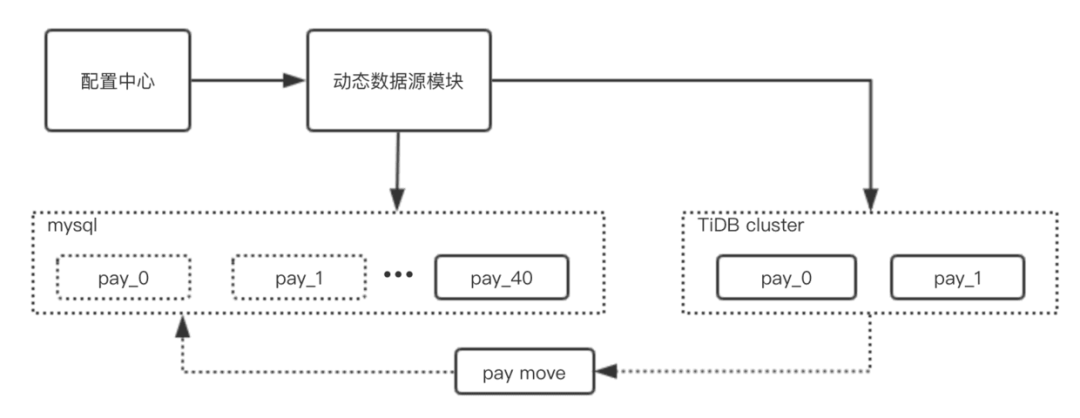
如上图所示,支付平台在进行适配灰度发布的过程中,需要具备以下几点的能力:
可以通过配置中心快速的切换 pay_0 到 pay_40 的数据源
通过 dbmove 反向同步,灰度发布到 TiDB 的数据库可以实时的切换回 mysql
需要支付平台业务代码适配灰度发布
在支付平台切换 TiDB 的过程中,共灰度发布了四次:
pay_0:第一次灰度,只灰度验证了业务最简单的 0 库,里面只有比较少量的业务数据。
pay_0,pay_1:关于 0 库和 1 库会灰度两次,因为支付平台的 0 库和其它 40 个库存储的数据由所不同。
pay_0,pay_1,pay_2,pay_3,pay_4,pay_5:第三次灰度的目的,是想在已经灰度验证完业务的基础上,给 TiDB 集群增加一些流量,尽量使得问题可以提前暴露出来。
pay_0,pay_1:这次灰度是在第二次全量切换前的一次验证操作。
3.5 快速回滚方案
支付平台的回滚方案是建立在 TiDB 到 MYSQL 数据同步服务正常的基础之上的,回滚方案按照自动化程度分为两种:人工回滚和自动回滚,其中自动回滚需要借助自研工具 DBSwitch 来完成。 DBSwitch 这个工具的产生也是源于上次切换的失败,虽然上次切换 TiDB 的过程中,我们做了很多的保障措施,但是在实际问题发生的过程中,因为需要人去判断和操作,所以我们便做了 DBSwitch 这个工具,让系统去判断 TiDB 集群是否出现问题了,是否需要把数据库切换回 MYSQL
独立于支付平台之外
通过定时的调用支付平台的接口来判断 TiDB 集群是否已经不可用
为了敢于放心切换,dbswitch 会判断 dbmove 中未同步消息的数量
通过更改配置中心的数据库开关来实现数据库的动态切换
为保障连接池和线程池都能快速的得到释放,dbswitch 会对支付平台进行重启操作
4. 迁移的坑
迁移 TiDB 的过程中,不可避免的会遇到一些坑,主要的大坑记录如下:
4.1 全量数据迁移后 TiDB 集群停止响应
这个问题是 TiDB 切换过程中遇到最大的一个问题,事后分析主要原因有两个:
TiKV 的一个已经解决的 bug,我司当时 TiDB 的版本是 2.1.9,当 transfer leader 时遇到了 conf change 时,会出现短暂的慢查询现象(连接会被 TiDB 占住一段时间):PR 链接。
当 region 在 transfer leader 时,会先判断 region 是否在做 conf change,如果已经做完并判断 conf change 的时间间隔,都满足条件后才允许进行 transfer leader 的操作。TODO: fix the transfer leader issue in Raft. 这句注释说明了 pingcap 公司未来会在 raft 协议层面去解决这个 bug,目前的方法只是临时的解决方案。
nginx 在做 tcp proxy 时,会偶尔出现连接卡死的现象,只有到达超时时间,连接被 kill 后,此连接的业务才会恢复。我司之前使用的是第三方的 nginx_tcp_proxy_module 的模块。后来把 nginx 的版本升级为 1.17.1 并使用 nginx 官方的 stream 模块,此问题也解决了。
4.2 SQL 执行突然变慢
在使用 dbreplay 进行流量回放的过程中,有一天早上所有的语句执行时间全部变慢了,分析发现是没有及时的对于经常使用的相关表做 analyse,目前 TiDB 在 analyse table 时,还是比较保守,只有三个系统参数:tidb_auto_analyze_ratio、tidb_auto_analyze_start_time、tidb_auto_analyze_end_time, TiDB 目前没有定时任务可以让触发 analyse table 的操作。详见代码:statistics/update.go
在这里,建议各位使用 TiDB 的同学在生产环境中一定要有自己的 analyse table 机制。丰巢的做法是写了一个定时服务,每天定时调度支付平台 3 次,此服务支持分布式部署,可以接入多套 TiDB 集群,只要按照配置规则,即可完成指定集群指定表的 analyse 操作。
4.3 事务的执行结果与预期不一致
这个是支付业务在 TiDB 集群上并发冲突测试时发现的,这个也是 TiDB 的一个老生常谈的问题,主要原因是 TiDB 开启了显示事务的自动重试,大家可以通过查看系统变量:tidb_disable_txn_auto_retry 的值来确定 。如果为 on,则表示 TiDB 集群关闭了显示的事务重试机制,目前 TiDB 3.0 版本对于这个值的默认值已经设置为 on 了。关于禁止显示事务重试的代码在 TiDB 的 session/session.go 中。
4.4 支付业务的定时任务执行失败
这个是使用 dbreplay 回放出来的问题。原因是,支付平台会定期的 delete 某个表中的数据,因为 TiDB 中对于事务操作中的数据量有限制,delete 数据过多,导致失败。
上面的图来自于 TiDB 的官方文档,TiDB 因为是分布式数据库,所以对于大事务会有比较多的限制,从官方文档来看,我们批量语句是违背了第三或第四条规则。但是一开始实际测试的值与官方文档的值又不一致,我们实际测试 10 万条左右是一个临界值,单表大于 10 万条则删除失败,提示:“9500 - transaction is too large”。为了搞清楚到底是 10 万还是 30 万,我们查阅了 TiDB 的源码,在 store/tikv/2pc.go 这个文件中找到了答案:
kv.TxnEntryCountLimit 的默认值就是 30 万,并且这个值虽然是在 config.go 中设置的,但是没有放开修改权限。我们又进行了一次测试,建了一个表,表的字段个数只有两个,并且都是 bigint 类型,最后证明事务中最大的处理行数就是 30 万条。我们之前的测试是因为违反了“键值对总大小不超过 100MB”这条规则。在使用批量插入和批量删除语句时,尽量将大事务变为多个小事务,上生产环境之前,还是要测试一下再实际使用。
5. 优化建议
5.1 任务调度机制
提这个建议主要是因为 analyse table 的需要,上面我们也提到了之前由于 analyse table 不及时,造成数据库的查询语句开始大量变慢的问题。为此我们还专门写了一个定时调度的服务,目前生产环境是每天执行 3 次相关表的 analyse 操作。但是写额外的服务,会存在下面几方面的问题:
对于推广 TiDB 的团队成员要求有常规编程语言的能力:很多公司落地执行 TiDB 的角色是 DBA,一般 DBA 不擅长用 Java、golang 等常用的编程语言,我们是用 Java 实现 analyse 的调度功能,很容易就选择了第三方的分布式调度框架。
不便于监控:因为这个调度服务至关重要,就要提供额外的监控服务来对它的状态和任务的执行结果进行监控,增加了复杂度。
容易遗漏:没有经验的人员在第一次使用的时候,容易把这个过程遗漏,遗漏后可能造成生产事故。
5.2 回导机制
在反向同步这个领域内,TiDB 的 drainer 是支持目标数据库为 Mysql 的,但不支持目标数据库是多个 mysql 的情况。虽然 DM 系列的组件已经很容易的便把已经分库分表的 mysql 数据库聚合到了 TiDB 上,但是没有反向实时回导的功能。这个回导机制在刚刚切换的过程中是最后的保底手段,正如 dbmove 做的事情。
6. 总结
TiDB 是一款非常棒的分布式关系数据库,它的社区活跃度、版本迭代速度、周边产品的完善程度等,都已经做的比较全面了,它在全球范围内有几百个 Contributor,我们丰巢也几次对 TiDB 贡献了源码,后面我们会在内部培养更多的 Contributor。
这次我们选择支付平台来作为迁移到 TiDB 上的业务,就是想证明在丰巢所有的 OLTP 业务范畴内,我们是可以 All in TiDB 的。它对于丰巢的意义就在于,可以长期规划丰巢的数据库的选型和资源的投入,避免数据库产品使用的分裂和无效资源的投入。
在支付平台迁移的过程中,我们对于 TiDB 的使用和迁移工具都有了一定程度的积累,对于丰巢所有跑在 Mysql 上的业务,都有信心可以快速的迁移到 TiDB 上来。希望未来能有更多关于 TiDB 的知识和大家一起分享。
原文链接: