作者韩同阳斗鱼资深大数据工程师、OLAP 平台负责人
斗鱼是一家弹幕式直播分享网站,为用户提供视频直播和赛事直播服务。斗鱼以游戏直播为主,也涵盖了娱乐、综艺、体育、户外等多种直播内容。随着斗鱼直播、视频等业务的高速发展,用户增长和营收两大主营业务线对精细化运营的需求越发地迫切,各个细分业务场景对用户的差异化分析诉求也越发的强烈,例如增长业务线需要在各个活动(赛事、专题、拉新、招募等)中针对不同人群进行差异化投放,营收业务线需要根据差异化投放的效果及时调整投放策略。
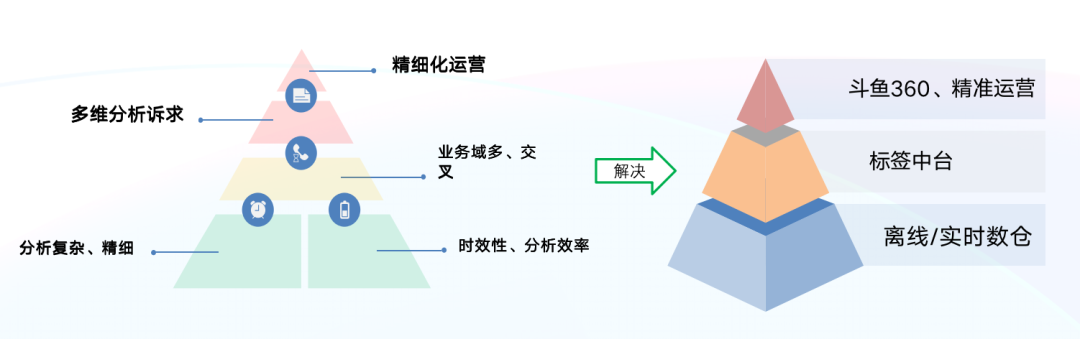
根据业务场景的诉求和精细化运营的要求,我们从金字塔自下而上来看,需求大致可以分为以下几点:
为更好解决上述需求,我们的初步目标是:
在目标驱动下,斗鱼在原有架构的基础上进行升级改造、 引入 Apache Doris 构建了实时数仓体系,并在该基础上成功构建了标签平台以及多维分析平台 ,在此期间积累了一些建设及实践经验通过本文分享给大家。
原有实时数仓架构
斗鱼从 2018 年开始探索实时数仓的建设,并尝试在某些垂直业务领域应用,但受制于人力的配置及流计算组件发展的成熟度,直到 2020 年第一版实时数据架构才构建完成,架构图如下图所示:
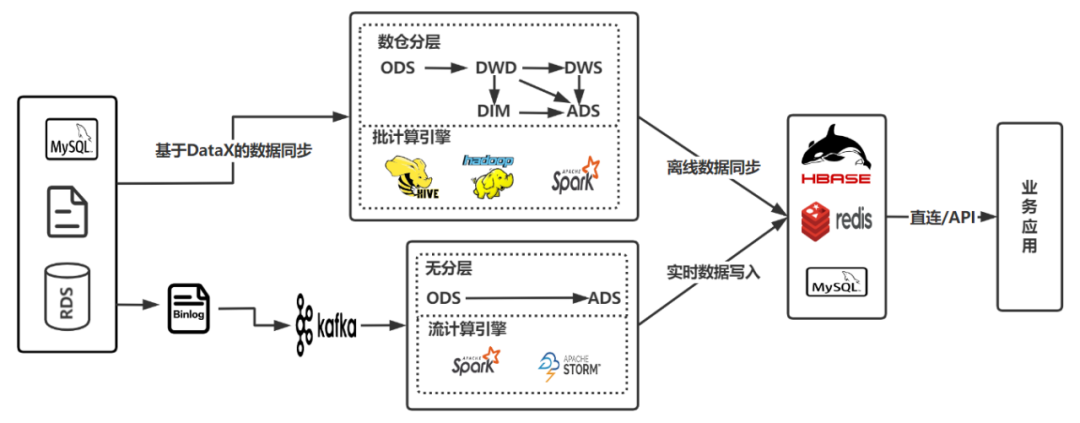
原有实时数仓架构是一个典型的 Lambda 架构,上方链路为离线数仓架构,下方链路为实时数据仓架构。鉴于当时离线数仓体系已经非常成熟,使用 Lambda 架构足够支撑实时分析需求,但随着业务的高速发展和数据需求的不断提升, 原有架构凸显出几个问题 :
新实时数仓架构
技术选型
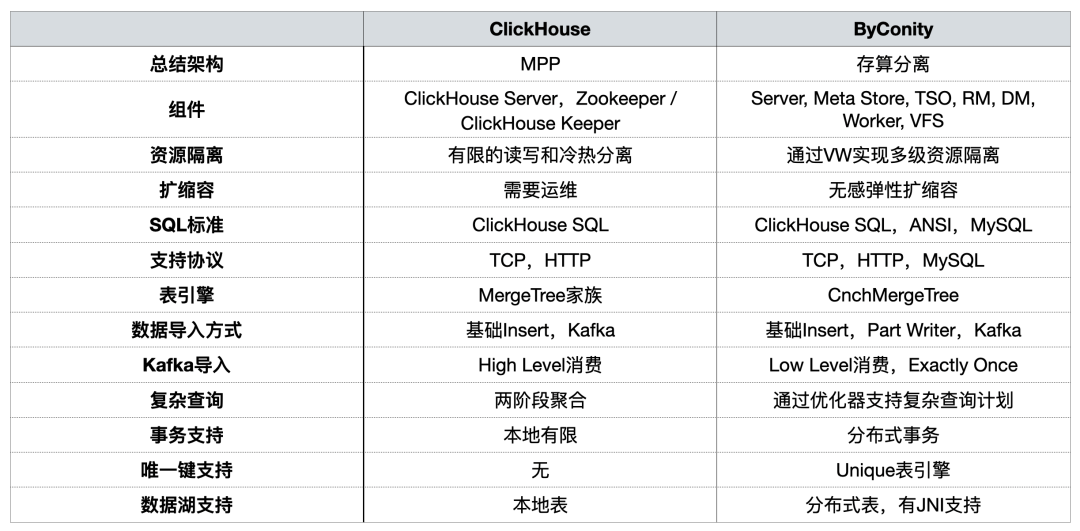
带着以上的问题,我们希望引入一款成熟的、在业内有大规模落地经验的 OLAP 引擎来帮助我们解决原有架构的痛点。我们希望该 OLAP 引擎不仅要具备传统 OLAP 的优势(即>立足于此,我们在技术选型时对比了市面上的几款 OLAP 引擎,如下图所示:
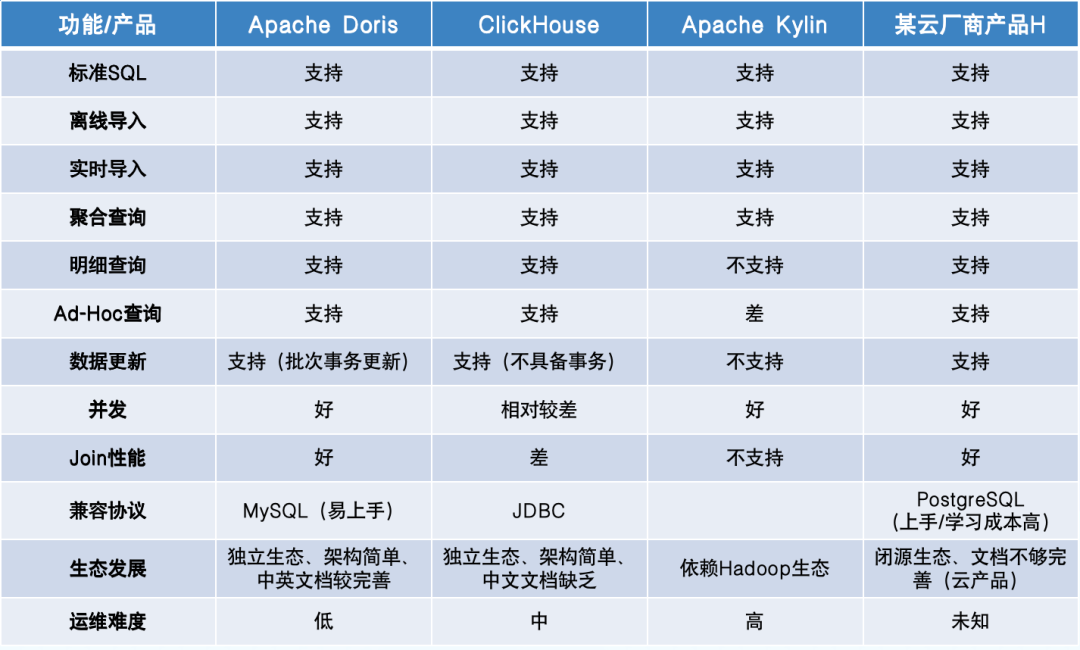
根据对选型的要求, 我们发现 Apache Doris 可以很好地满足当前业务场景及诉求,同时也兼顾了低成本的要求,因此决定引入 Doris 进行升级尝试 。
架构设计
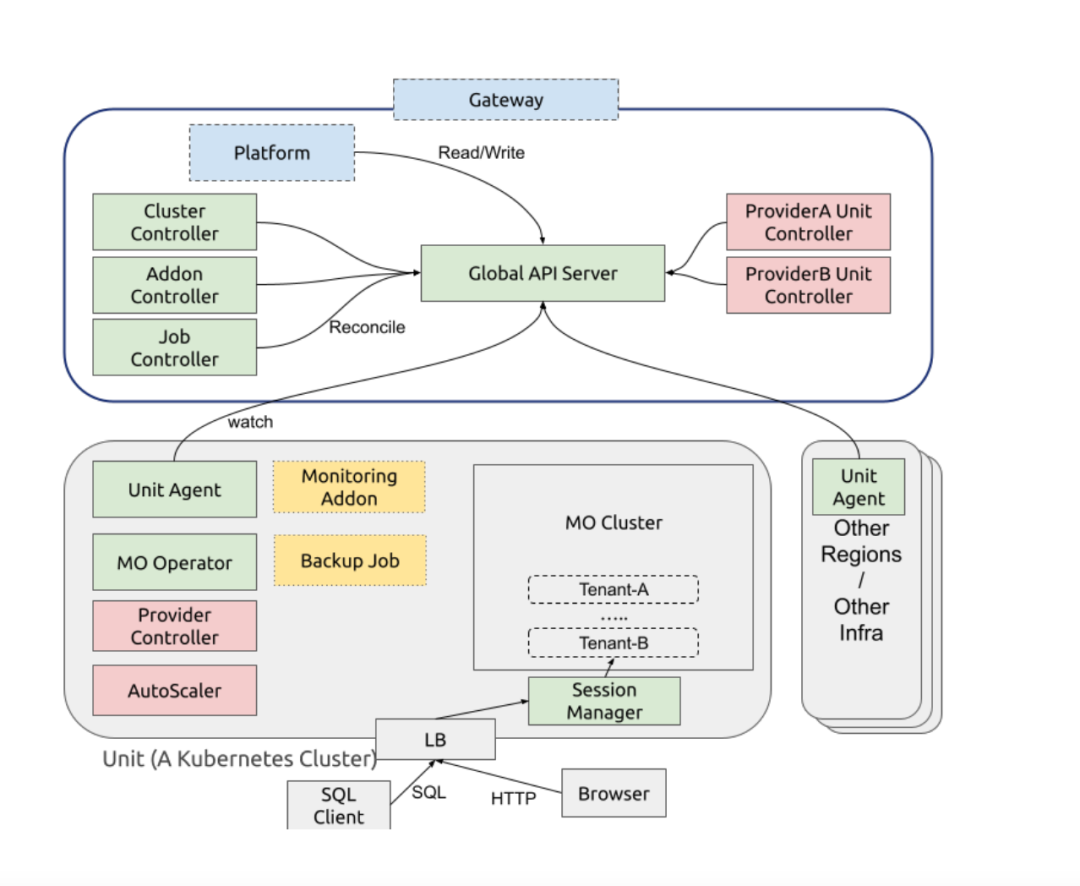
我们在 2022 年引入了 Apache Doris ,并基于 Apache Doris 构建了一套比较相对完整的实时数仓架构,如下图所示。
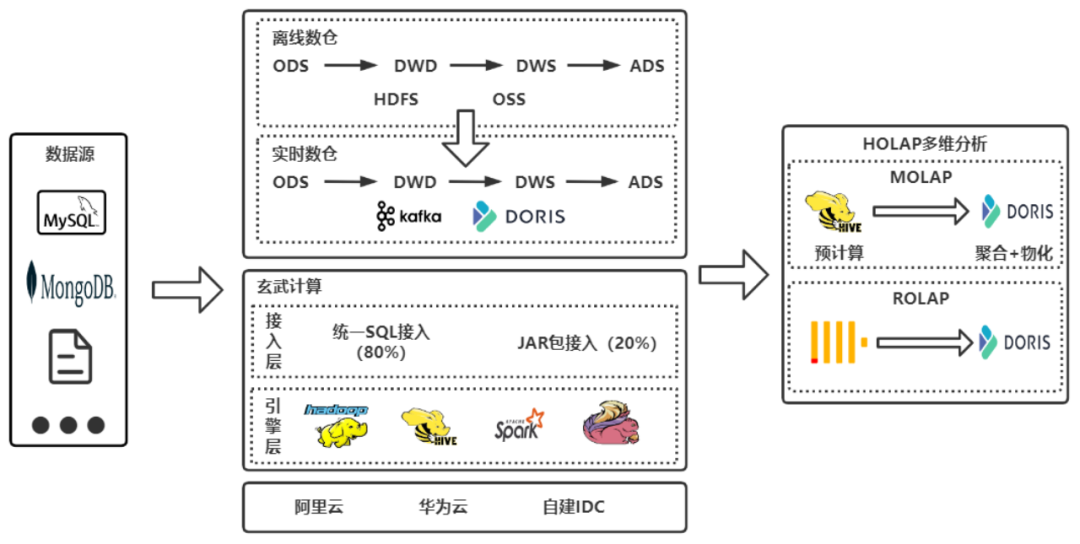
总的来说,引入 Doris 后为整体架构带来几大变化:
Overwrite 语义实现
Apache Doris 支持原子替换表和分区,我们在计算平台(玄武平台)整合 Doris Spark Connector 时进行了定制,且在 Connector 配置参数上进行扩展、增加了“Overwrite”模式。
当 Spark 作业提交后会调用 Doris 的接口,获取表的 Schema 信息和分区信息。
架构收益
通过架构升级及二次开发,我们获得了 3 个明显的收益:
Doris 在标签中台的应用
标签中台(也称用户画像平台)是斗鱼进行精准运营的重要平台之一,承担了各业务线人群圈选、规则匹配、A/B 实验、活动投放等需求。接下来看下 Doris 在标签中台是如何应用的。
原标签中台架构
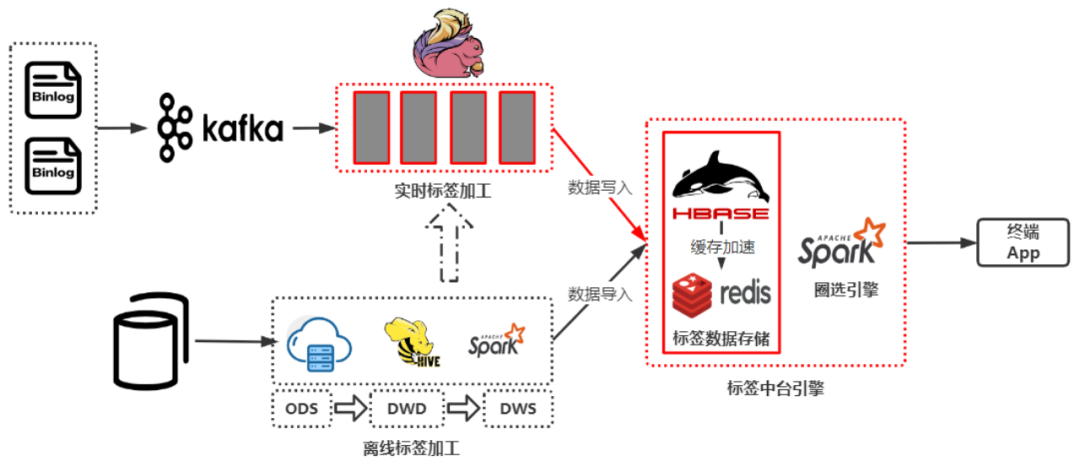
上图为斗鱼原来的标签中台架构,离线标签在数仓中加工完成后合入宽表,将最终数据写入 HBase 中,实时标签使用 Flink 加工,加工完直接写入到 HBase 中。
终端 APP 在使用标签中台时,主要解决两种业务需求:
在应对这两种场需求中,原标签中台架构出现了两个问题:
新标签中台架构
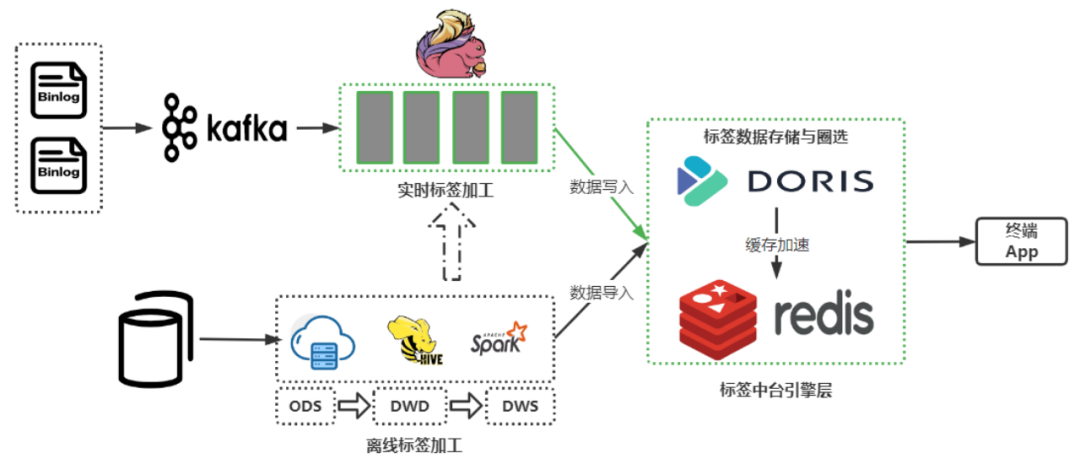
引入 Apache Doris 之后,我们对标签中台架构的进行了改进,主要改进集中在实时链路和标签数据存储这两个部分:
1. 离线/实时标签混合圈人
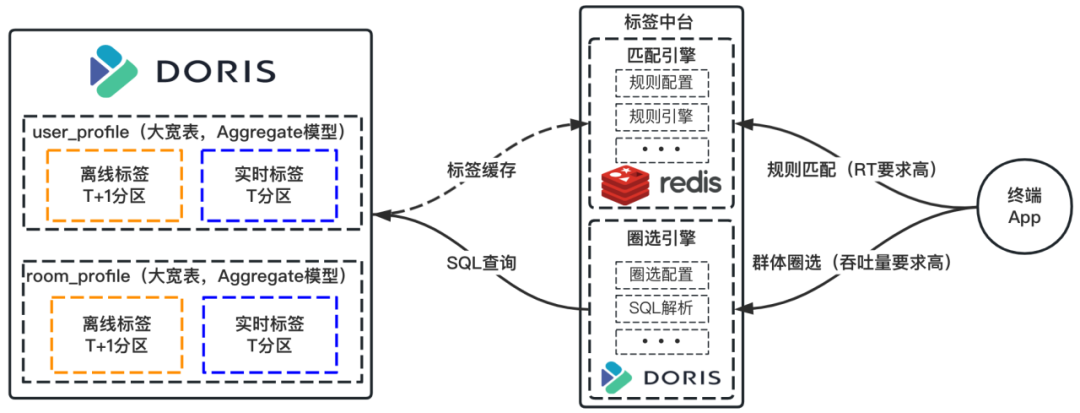
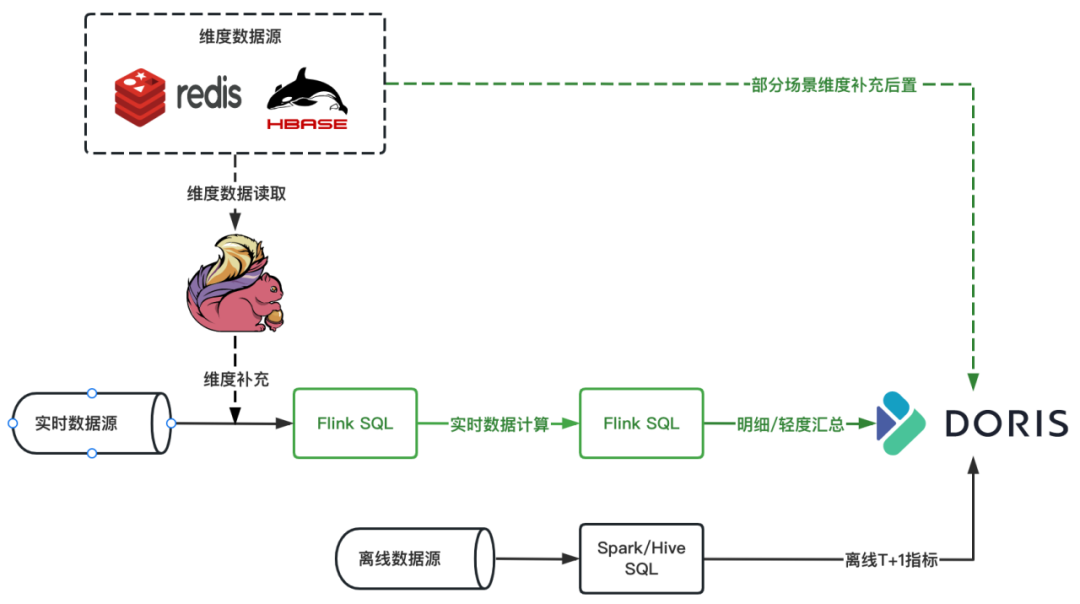
2. 长周期实时标签计算原链路
使用前:
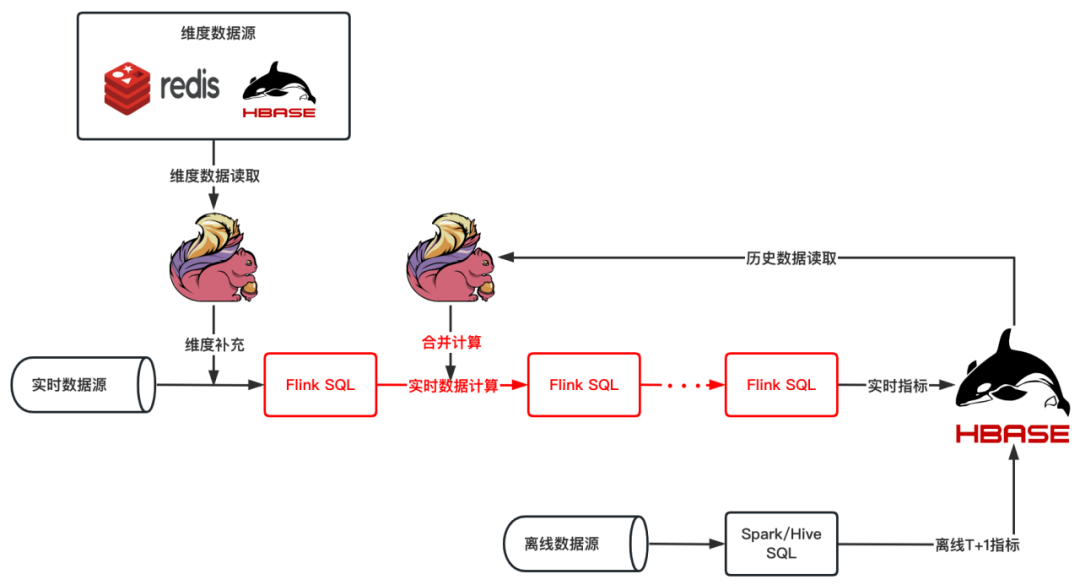
从原来的计算链路中可知,计算长周期的实时标签时会涉及到维度补充、历史数据 Merge,在经过几步加工最终将数据写入到 HBase 中。
在实际使用中发现,在这个过程中 Merge 离线聚合的数据会使链路变得很复杂,往往一个实时标签需要多个任务参与才能完成计算;另外聚合逻辑复杂的实时标签一般需要多次聚合计算,任意一个中间聚合资源分配不够或者不合理,都有可能出现反压或资源浪费的问题,从而使整个任务调试起来特别困难,同时链路过长运维管理也很麻烦,稳定性也比较低。
使用后:
我们在长周期指标计算实时链路中加入了 Apache Doris,在Flink 中只做维度补充和轻度加工汇总,只关注短的实时数据流,对于需要 Merge 的离线数据,Merge 的计算逻辑转移到 Doris 中进行计算,另外 Doris 中的轻度汇总/明细数据有助于问题排查,同时任务稳定性也能提升。
使用收益
目前标签中台底层有近 4 亿+条用户标签,每个用户标签 300+,已有 1W+ 用户规则人群,每天定时更新的人群数量达到 5K+。标签中台引入 Apache Doris 之后, 单个人群平均圈选时间实现了分钟级到秒级的跨越 ,实时标签任务稳定性有所提高,实时标签任务的产出时间相较于之前约有 40% 的提升 ,资源使用成本大大降低。
Doris 在多维数据分析平台的应用
除以上所述应用及收益之外,Apache Doris 也助力内部多维数据分析平台——斗鱼 360 取得了较大的发展,受益于 Apache Doris 的 Rollup、物化视图以及向量化执行引擎,使原来需要预计算的场景可以直接导入明细数据到 Doris 中,简化了业务数据开发流程,提升了分析效率;Doris 兼容 MySQL 协议,并具有独立简单的分布式架构,使得业务开发人员入门使用也更容易,缩短了业务开发周期,有效降低了开发成本;同时我们原来基于 ClickHouse 的查询目前也全部切换到了 Doris 中进行。
目前我们用于多维分析场景的 Doris 集群共有两个,节点规模约 120 个,存储数据量达 90~100 TB,每天增量写入到 Doris 的数据约 900GB,其中查询 QPS 在 120 左右,Apache Doris 应对起来毫不费力,轻松自如。
未来展望
未来随着 Apache Doris 在斗鱼更广泛业务场景的落地,我们将在可视化运维、问题快速定位排查等方面进行更多实践和深耕。我们关注到, Apache Doris 1.2.0 版本已经对 Multi Catalog 功能进行了支持,我们也计划对其进行探索、解锁更多使用场景,同时也期待即将发布 Apache Doris 2.x 版本的行列混存功能,更好的支持>