背景
当前,Thrift 是字节内部主要使用的 RPC 序列化协议,在 CloudWeGo/Kitex 项目中优化和使用后,性能相比使用 支持泛型编解码 的协议如 JSON 有较大优势。但是在和业务团队进行深入合作优化的过程中,我们发现一些特殊业务场景并不能享受 静态化代码生成 所带来的高性能:
不难发现,这些业务场景都具有 难以统一定义静态 的特点。即使可以通过分布式 sidecar 技术规避这个问题,也往往因为业务需要动态更新而放弃传统代码生成方式,诉诸某些自研或开源的 Thrift 泛型编解码库进行泛化 RPC 调用。
我们经过性能分析发现,目前这些库相比代码生成方式有巨大的性能下降。以字节某 BFF 服务为例,仅仅 Thrift 泛化调用产生的 CPU 开销占比就将近 40%,这几乎是正常 Thrift RPC 服务的 4 到 8 倍。因此,我们自研了一套能动态处理 RPC 数据(不需要代码生成)同时保证高性能的 Go 基础库 —— dynamicgo。
设计与实现
首先要搞清楚当前这些泛化调用库性能为什么差呢?其核心原因是: 采用了某种低效泛型容器来承载中间处理过程中的数据 (典型如 thrift-iterator 中的 map[string]interface{})。众所周知,Go 的堆内存管理代价是极高的 (GC +heap bitmap),而采用 interface 不可避免会带来大量的内存分配。但实际上相当多的业务场景并不真正需要这些中间表示。比如 http-thrift API 网关中的纯协议转换场景,其本质诉求只是将 JSON(或其它协议)数据依据用户 IDL 转换为 Thrift 编码(反之亦然),完全可以基于输入的数据流逐字进行翻译。
同样,我们也统计了抖音某 BFF 服务中泛化调用的具体代码,发现真正需要进行读(Get)和写(Set)操作的字段占整个数据包字段不到 5%,这种场景下完全可以对不需要的字段进行跳过(Skip)处理而不是反序列化。而 dynamicgo 的核心设计思想是: 基于 原始字节流 和 动态类型描述 原地(in-place) 进行数据处理与转换 。为此,我们针对不同的场景设计了不同的 API 去实现这个目标。
动态反射
对于 thrift 反射代理的使用场景,归纳起来有如下使用需求:
这里我们参考了 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构——Value,提供一套完整的反射 API。
//IDL类型描述typeTypeDescriptorinterface{Type()Type//数据类型Name()string//类型名称Key()*TypeDescriptor//formapkeyElem()*TypeDescriptor//forsliceormapelementStruct()*StructDescriptor//forstruct//纯TLV数据单元typeNodestruct{tType//数据类型vunsafe.Pointer//buffer起始位置lint//数据单元长度//Node+类型描述descriptortypeValuestruct{Descthrift.TypeDescriptor这样,只要保证 TypeDescriptor 包含的类型信息足够丰富,以及对应的 thrift 原始字节流处理逻辑足够健壮,甚至可以实现 数据裁剪、聚合 等各种复杂的业务场景。
协议转换
协议转换的过程可以通过有限状态机(FSM)来表达。以 JSON->Thrift 流程为例,其转换过程大致为:
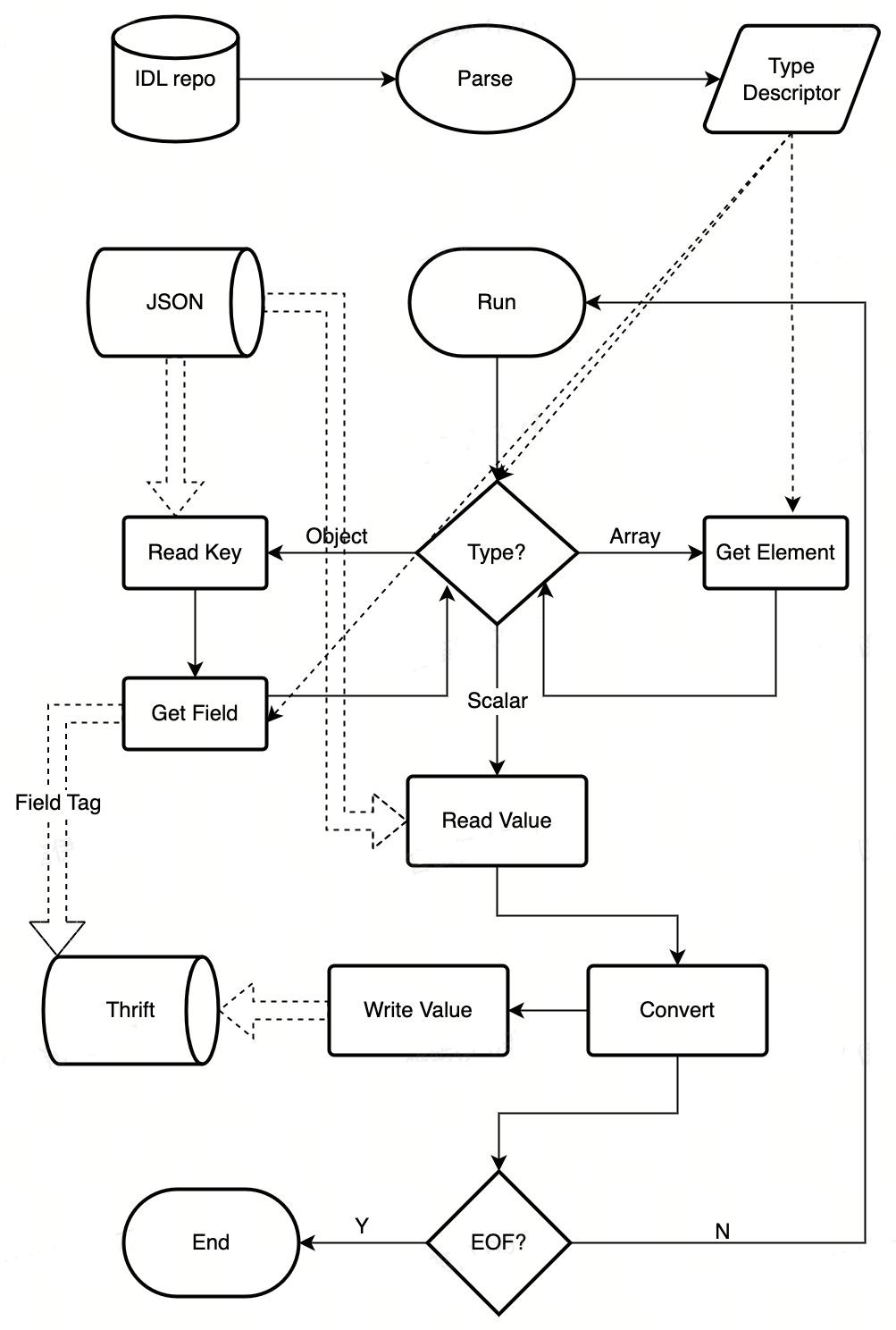 图1 JSON2Thrift 数据转换流程
图1 JSON2Thrift 数据转换流程
整个过程可以完全做到 in-place 进行,仅需为输出字节流分配一次内存即可。
数据编排
与前面两个场景稍微有所不同,数据编排场景下可能涉及 数据位置的改变 (异构转换),并且往往会 访问大量数据节点 (最坏复杂度 O(N) )。在与抖音隐私合规团队的合作研发中我们就发现了类似问题。它们的一个重要业务场景:要横向遍历某一个 array 的子节点,查找是否有违规数据并进行整行擦除。这种场景下,直接基于原始字节流进行查找和插入可能会带来大量重复的 skip 定位、数据拷贝开销 ,最终导致性能劣化。
因此我们需要一种高效的反序列化(带有指针)结构表示来处理数据。根据以往经验,我们想到了 (Document Object Model) ,这种结构被广泛运用在 JSON 的泛型解析场景中(如 rappidJSON、sonic/ast),并且性能相比 map+interface 泛型要好很多。
要用 DOM 来描述一个 Thrift 结构体,首先需要一个能准确 描述数据节点之间的关系的定位方式 —— Path。其类型应该包括 list index、map key 以及 struct field id 等。
typePathTypeuint8PathFieldIdPathType=1+iota//STRUCT下字段IDPathFieldName//STRUCT下字段名称PathIndex//SET/LIST下的序列号PathStrKey//MAP下的stringkeyPathIntkey//MAP下的integerkeyPathObjKey//MAP下的objectkeytypePathNodestruct{Path//相对父节点路径Node//原始数据单元Next[]PathNode//存储子节点在 Path 的基础上,我们 组合 对应的 数据单元 ,然后再通过一个 Next 数组动态存储子节点 ,便可以组装成一个类似于的泛型结构。
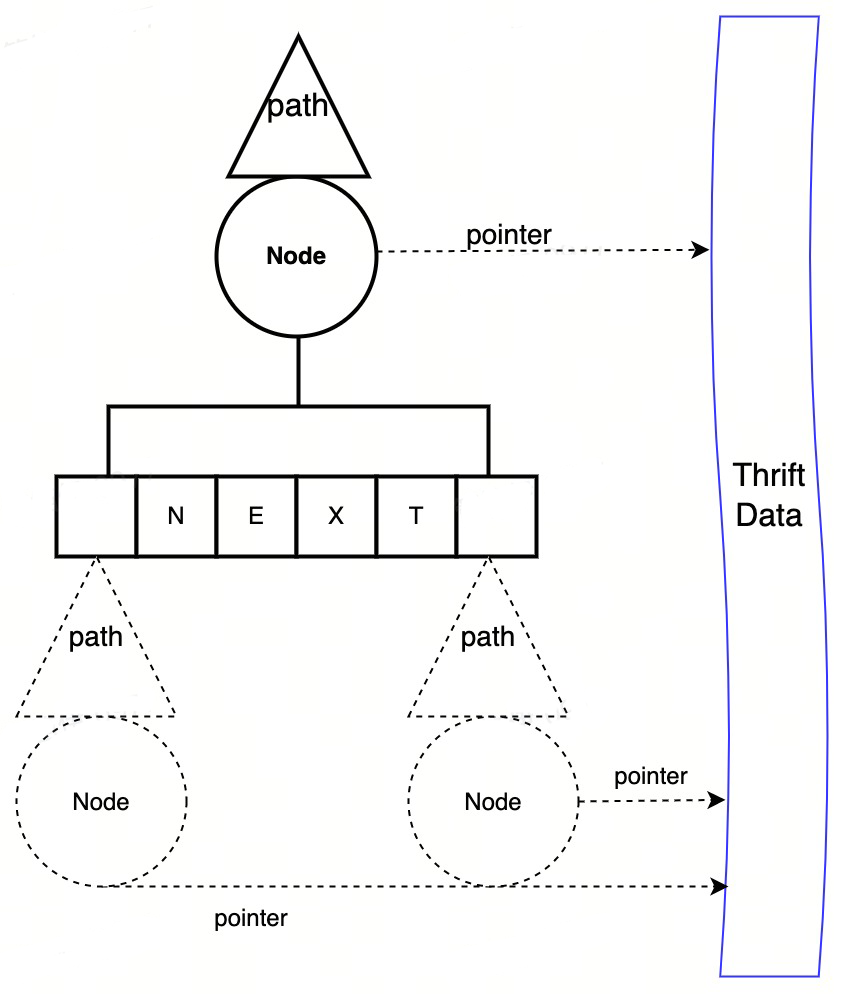 图2 thrift DOM 数据结构
图2 thrift DOM 数据结构
这种泛型结构比 map+interface 要好在哪呢?首先,底层的数据单元 Node 都是对原始 thrift>转换 interface 带来的二进制编解码开销;其次,我们的设计保证所有树节点 PathNode 的内存结构是完全一样,并且由于父子关系的底层核心容器是 slice, 我们又可以更进一步 采用内存池技术 ,将整个 DOM 树的子节点内存分配与释放都进行池化从而避免调用 go 堆内存管理。测试结果表明,在理想场景下(后续反序列化的 DOM 树节点数量小于等于之前反序列化节点数量的最大值——这由于内存池本身的缓冲效应基本可以保证),内存分配次数可为 0,性能提升 200%!(见【性能测试-全量序列化/反序列化】部分)。
性能测试
这里我们分别定义简单(Small)、复杂(Medium) 两个基准结构体分别在比较 不同数据量级 下的性能,同时添加简单部分(SmallPartial)、复杂部分(MediumPartial) 两个对应子集,用于【反射-裁剪】场景的性能比较:
其次,我们依据上述业务场景划分为 反射、协议转换、全量序列化/反序列化 三套 API,并以代码生成库kitex/FastAPI、泛化调用库kitex/generic、JSON 库sonic为基准进行性能测试。其它测试环境均保持一致:
反射
1. 代码
dynamicgo/testdata/baseline_tg_test.go
2. 用例
3. 结果
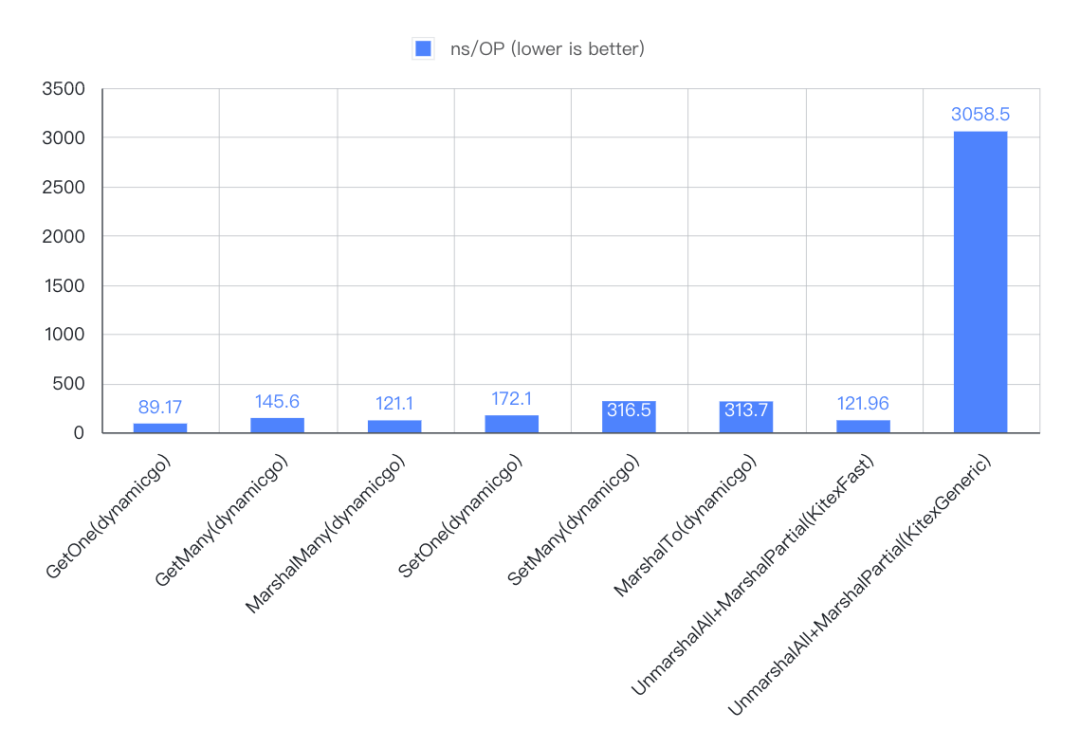
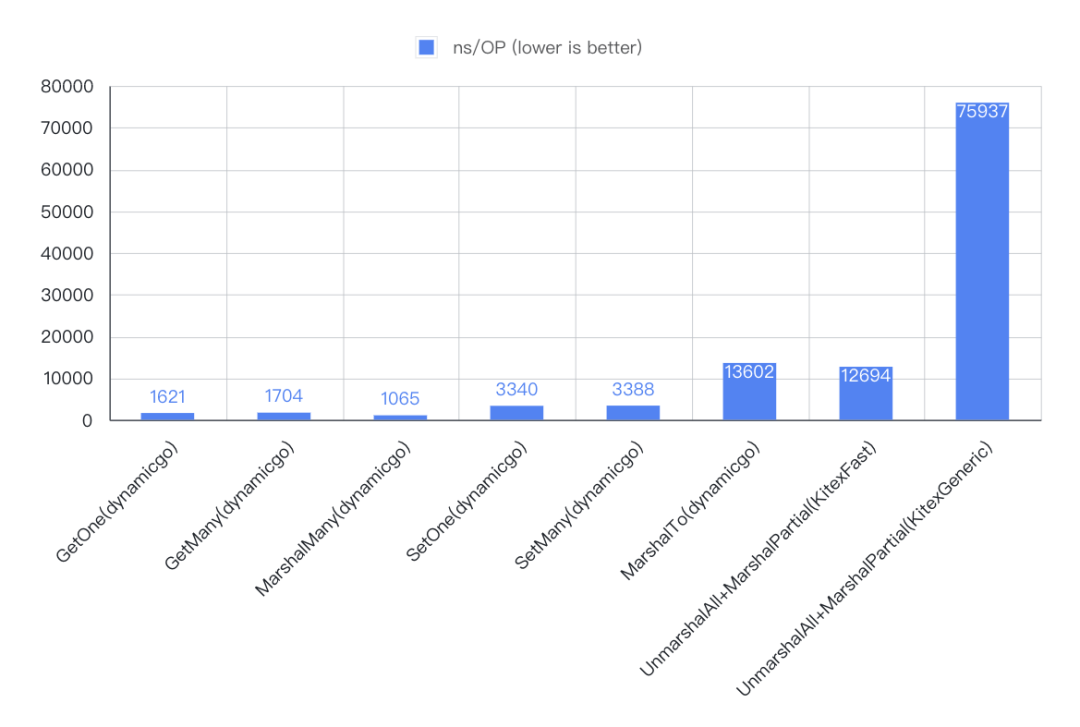
4. 结论
协议转换
1. 代码
2. 用例
3. 结果
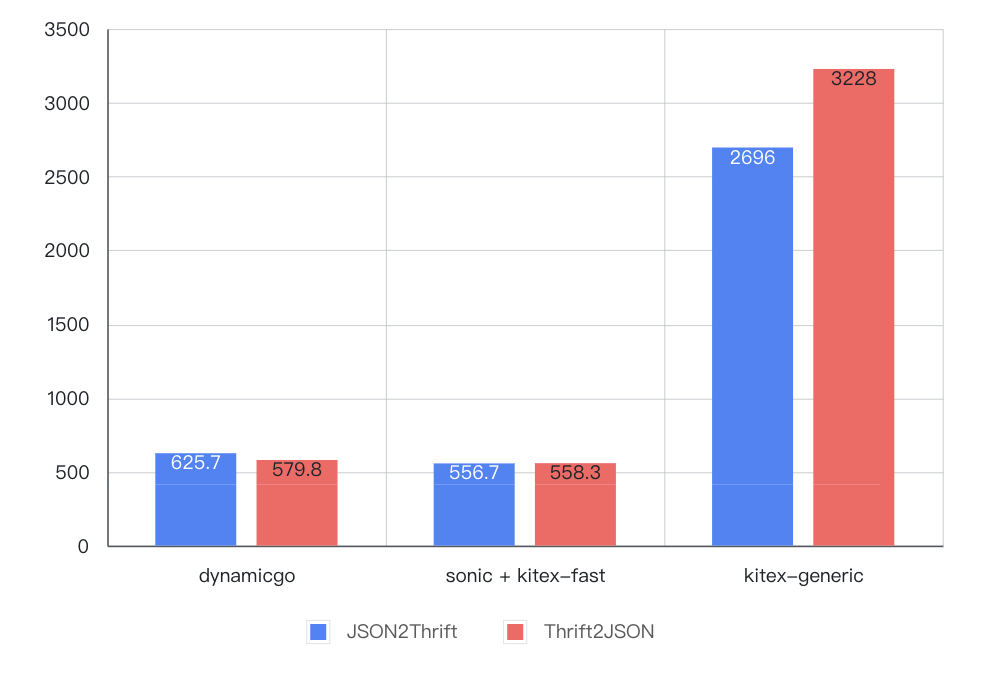
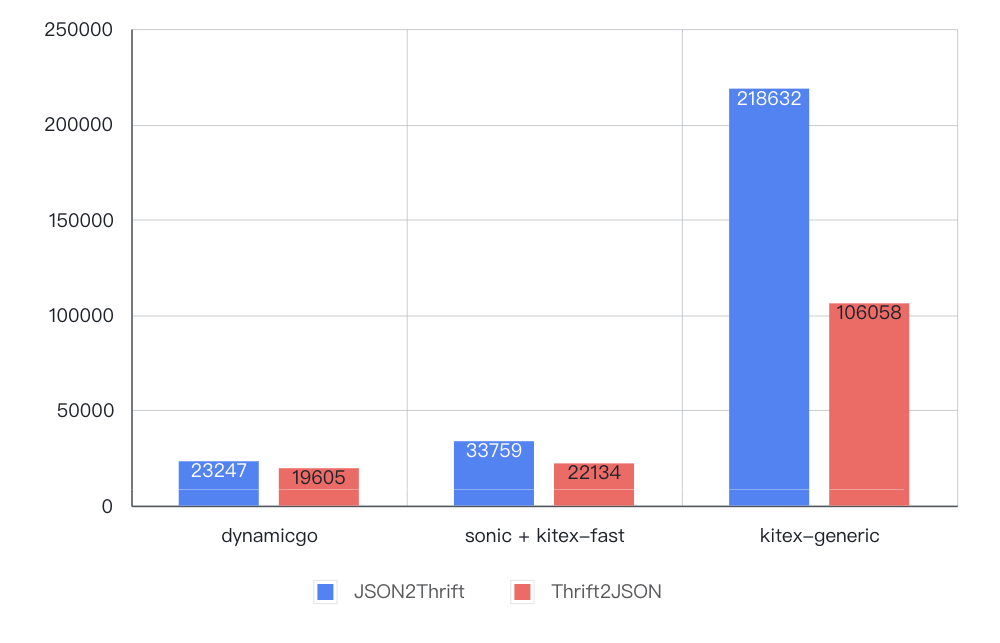
4. 结论
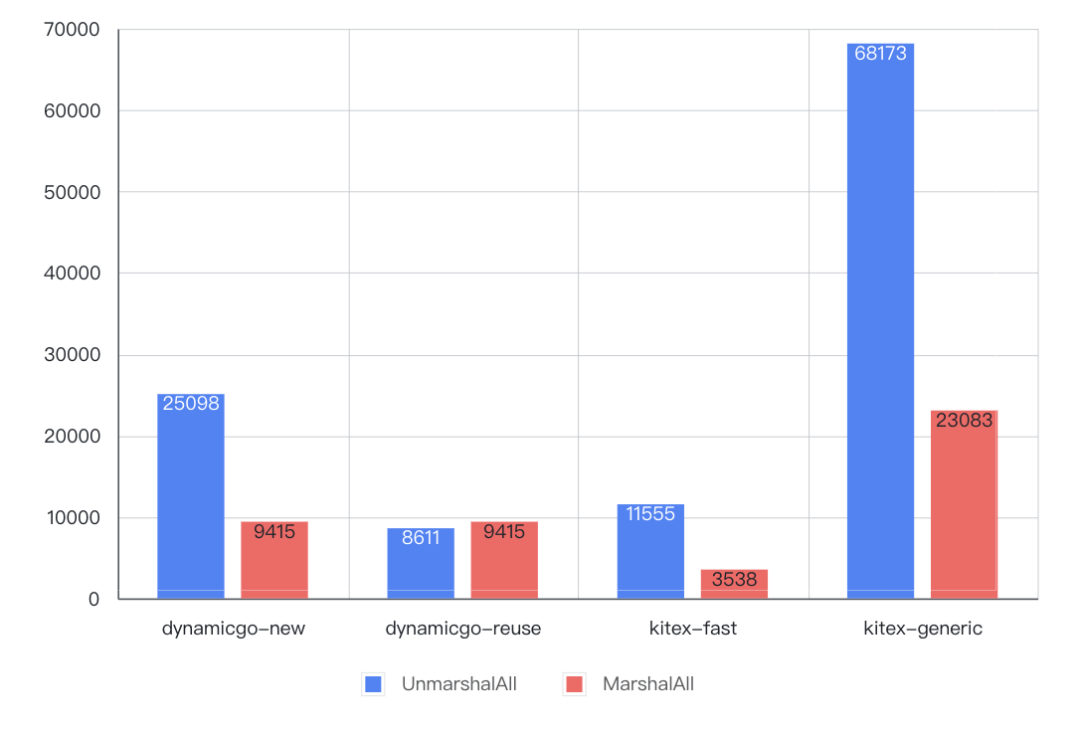
全量序列化/反序列化
1. 代码
dynamicgo/testdata/baseline_tg_test.go#BenchmarkThriftGetAll
2. 用例
3. 结果
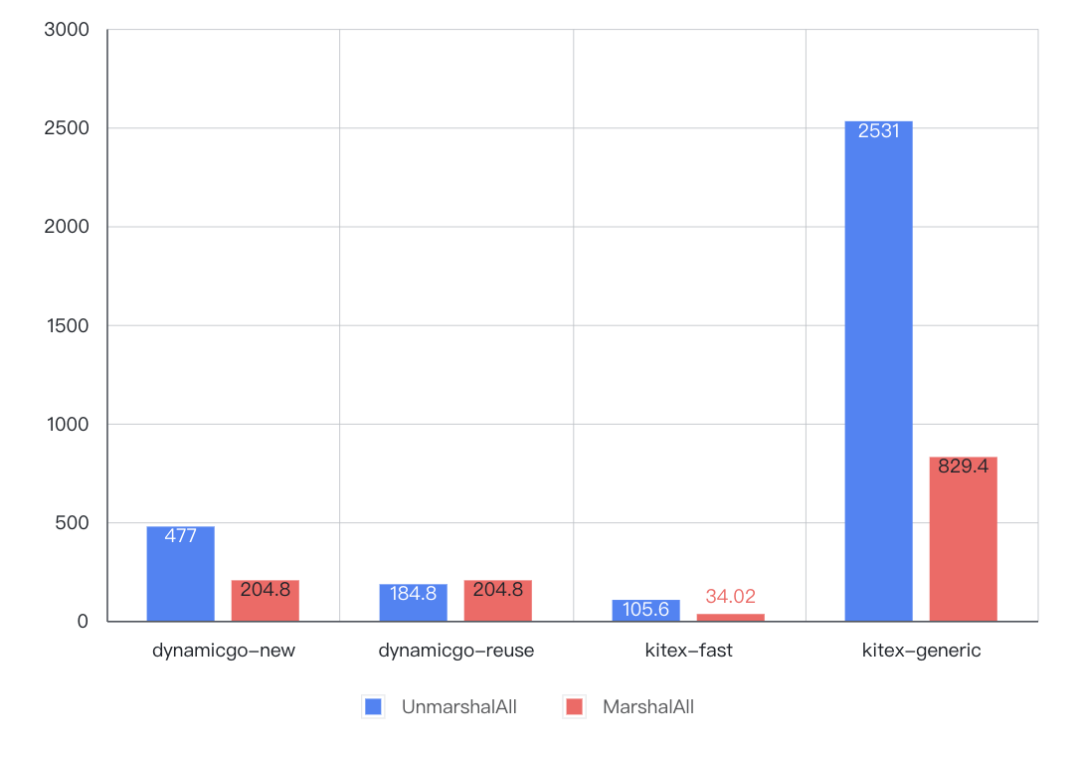
4. 结论
应用与展望
当前,dynamicgo 已经应用到许多重要业务场景中,包括:
并且逐步上线并取得收益。目前 dynamic 还在迭代中,接下来的工作包括:
也欢迎感兴趣的个人或团队参与进来,共同开发!
项目地址
GitHub: 官网: www.cloudwego.io