众安在线财产保险股份有限公司是中国首家互联网保险公司,由蚂蚁金服、中国平安和腾讯于 2013 年联合发起设立。众安专注于应用新技术重塑保险价值链,围绕健康、数字生活、消费金融、汽车四大生态,以科技服务新生代,为其提供个性化、定制化、智能化的新保险。业务和关联公司的业务包括:众安保险、众安医疗、众安小贷、众安科技、众安经纪、众安国际、众安银行等。截至 2023 年中,众安服务超过 5 亿用户,累计出具约 574 亿张保单。
然而,随着业务在金融、保险和商城领域的不断扩展,众安保险面临用户数据管理的挑战。用户信息来源于公众号、小程序和 APP 等多个渠道,这些数据不仅碎片化,而且多样化。同时,运营渠道也涵盖了自营、联营和外部投放等多种途径,导致数据进一步分散。这种数据孤岛现象使得众安保险难以形成完整的用户融合体系,从而无法实现对用户的精准识别和实时营销。
CDP 建设目标及方案
为了解决这一问题,众安保险建设了 CDP 平台。该平台的核心职责是整合所有用户数据,构建全面的用户标签和客群体系,并利用其强大的数据分析能力为自动化营销提供数据支持。

CDP 平台的建设目标主要包括以下几点:
基于上述建设目标,众安保险目前已形成了完整的 CDP 解决方案,该方案包括以下几个关键步骤:

CDP 平台架构的演进历程
在初步了解了 CDP 平台的建设初衷和解决方案之后,我们将深入挖掘其演进历程,探索它如何逐步蜕变为众安保险统一、高效且不可或缺的核心基础设施。本文将重点分享 CDP 平台的建设过程及其在实际生产中的应用实践。
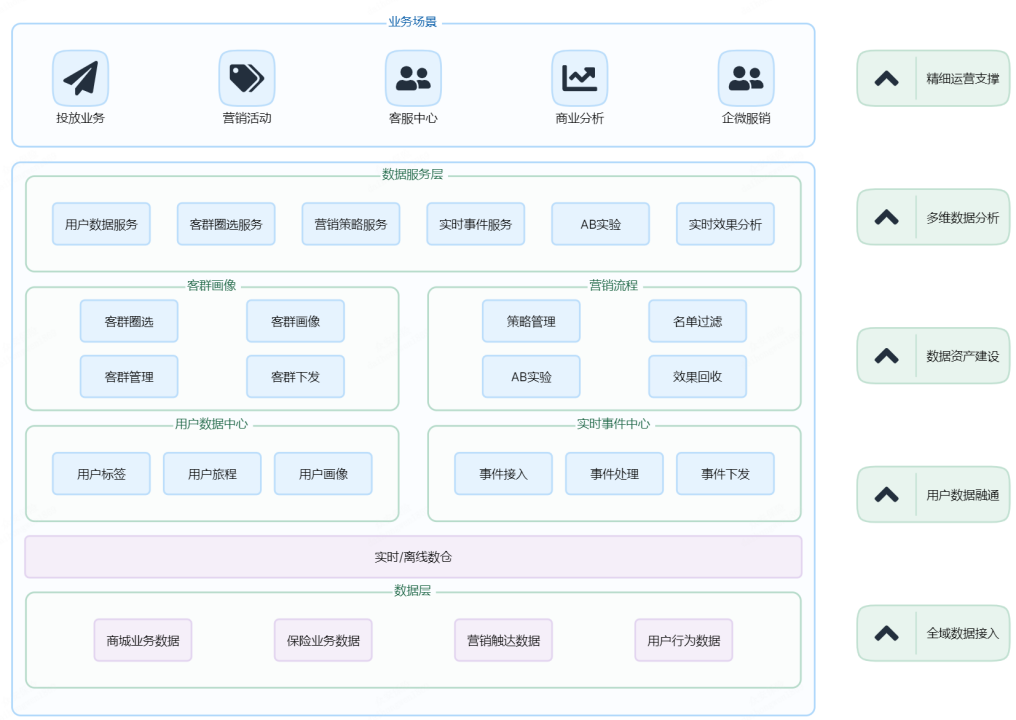
CDP 产品架构如上图所示。全域数据接入之后,这些数据就可以搭建用户数据中心、实时事件中心、客群画像以及营销流程。用户数据中心是客群画像的基石,并与客群画像、实时事件中心一同支撑营销流程的数据需求。数据服务层则包括用户数据服务、客群圈选、营销策略、实时事件、 AB 实验和实时效果分析回收在内的全方位数据服务,满足各业务场景的数据需求。
架构 1.0:多个技术栈,形成数据孤岛
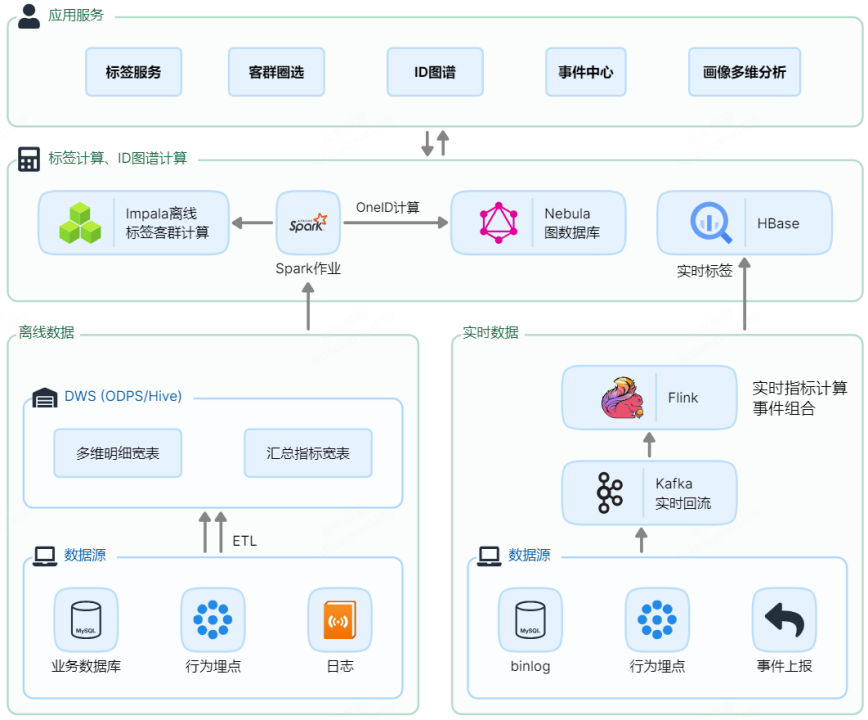
CDP 平台架构 1.0 如上图所示,离线数据和实时数据的处理流程如下:
然而,从架构图中可以明显看出,标签计算和 ID 图谱计算这一层涉及了非常多的技术栈,包含 Impala、Spark、Nebula 以及 Hbase。这些过多的组件导致了离线标签、实时标签以及图数据存储的不统一、各场景数据分散存储,形成了数据孤岛。
在这种情况下,当需进行整体视图计算或为上层提供服务时,就需要打通所有的数据,这无疑增加了大量数据传输和数据重复存储的成本。此外,由于各类数据存储方案的差异,还需要使用较大的 CDH 集群和 Nebula 图数据库集群,进一步提高了集群资源与维护成本。
架构 2.0:统一技术栈,打破数据孤岛
为了解决数据存储的不一致性和高昂成本问题,我们决定进行架构升级,并选择 Apache Doris 作为核心组件。我们的升级目标是希望通过引入 Doris 来统一技术栈,实现实时和离线数据存储和计算的整合,从而打破数据孤岛,大幅度降低数据存储和资源维护的成本。在实际的应用中,Doris 完美地满足了我们的需求,使得整体架构变得更精简高效。
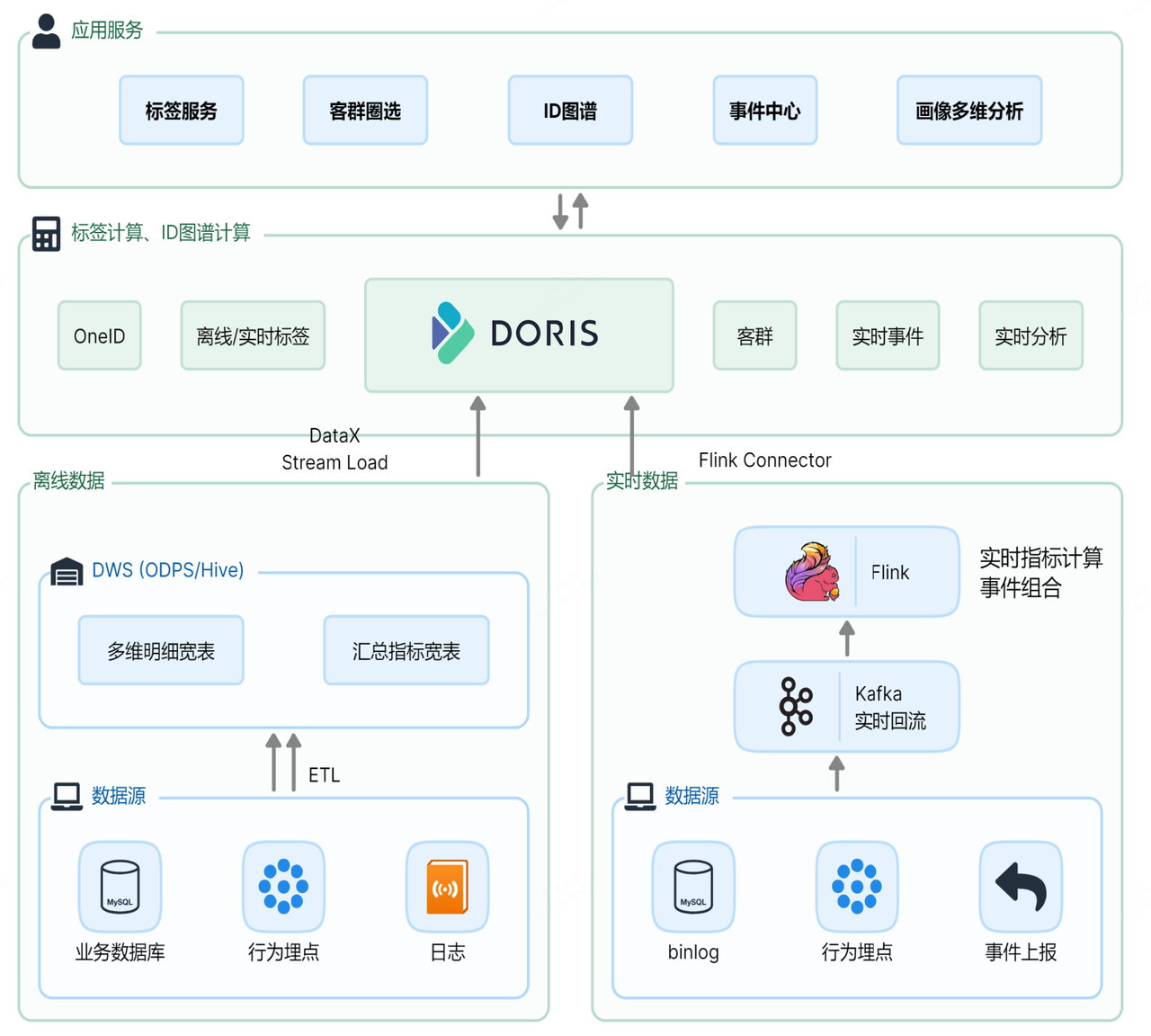
对于离线数据,我们采用了 Doris 的 Stream Load 功能,轻松地从离线数仓中将数据抽取到 Doris 中。而对于实时数据,则通过 Flink Connector 与 Stream Load 的结合,将实时事件和实时标签无缝导入到 Doris 中。基于 Doris 强大的向量化计算引擎,我们不仅实现了 One ID 计算、离线/实时标签的存储和计算、客群圈选、实时事件存储,还支持了实时分析等多样化需求,真正实现了技术栈的统一。
引入 Doris 后,我们还收获了以下显著的收益:
Doris for CDP 在业务场景中的实践
全域数据采集
为满足不同场景的数据集成需求,CDP 平台主要分为三个板块:
1. 构建 ID 图谱
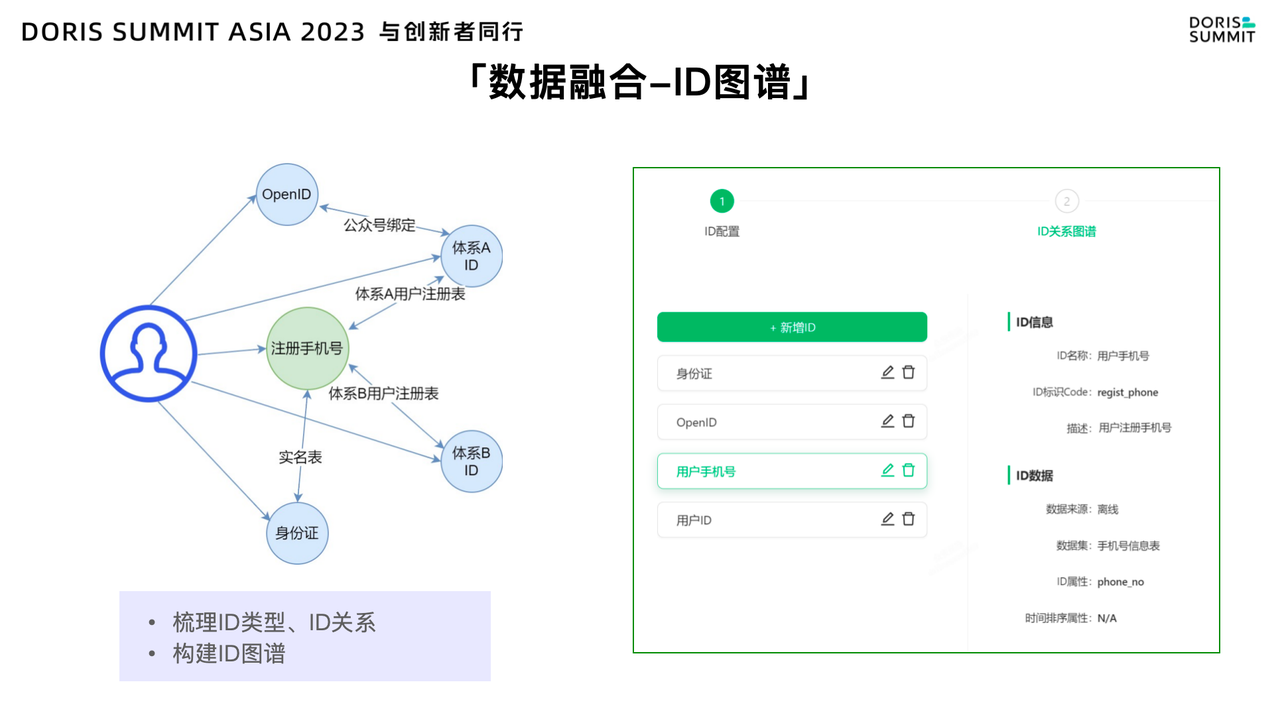
我们在现有系统中配置了 ID 图谱的点关系,这些关系以用户为中心,形成了复杂的网络结构。举例说明:假设某用户在体系 A 拥有用户 ID,并且绑定的公众号,这样就形成了 Open ID 绑定关系。随着用户的使用,他可能注册了手机号,那么手机号跟体系 A 用户 ID 之间便建立了绑定关系。如果用户在体系 A 也进行了实名,那么身份证和注册手机号也会建立绑定关系。
随着时间的推移,该用户可能进入到体系 B 中,并注册体系 B 账户。这时,与该用户相关的体系 A 用户 ID、手机号、身份证和体系 B 账户之间都会形成关联。在如上图右侧系统里,我们可以配置用户 ID、OpenID、手机号、身份证这些点的属性、物理表及关联关系,形成 ID 图谱。那么结合 ID 图谱,就可以基于 Doris 进行 OneID 的构建。
2. 构建 OneID
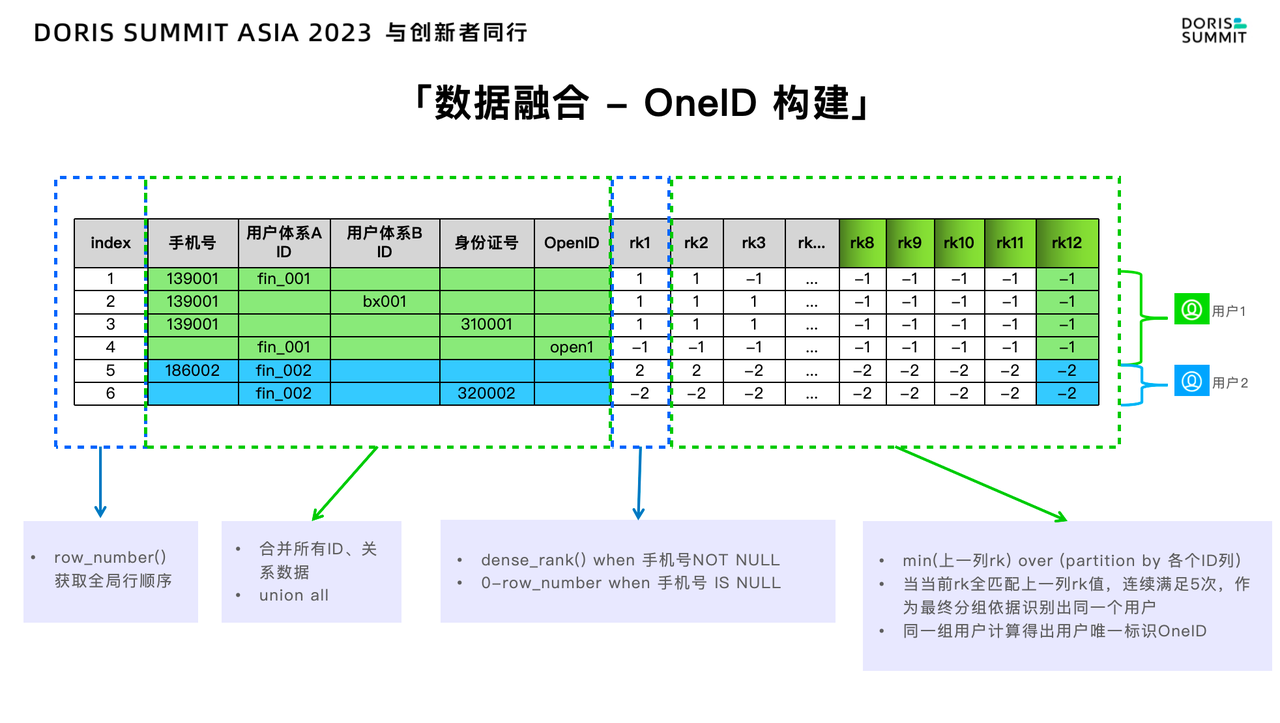
基于用户各个业务线之间点和边的关系,我们会将用户在不同业务线中的信息全部抽取出来,放入一张大表里面进行 Union All 操作。这张表包含了手机号、体系 A 用户 ID、体系 B 用户 ID、身份证号和 Open ID 关键信息。OneID 的构建流程如下:
结合上图以及构建流程,可以得出结论: 1 - 4 行是用户 1,5 - 6 行是用户 2。
标签体系
我们的标签体系由实时标签和离线标签两部分组成,
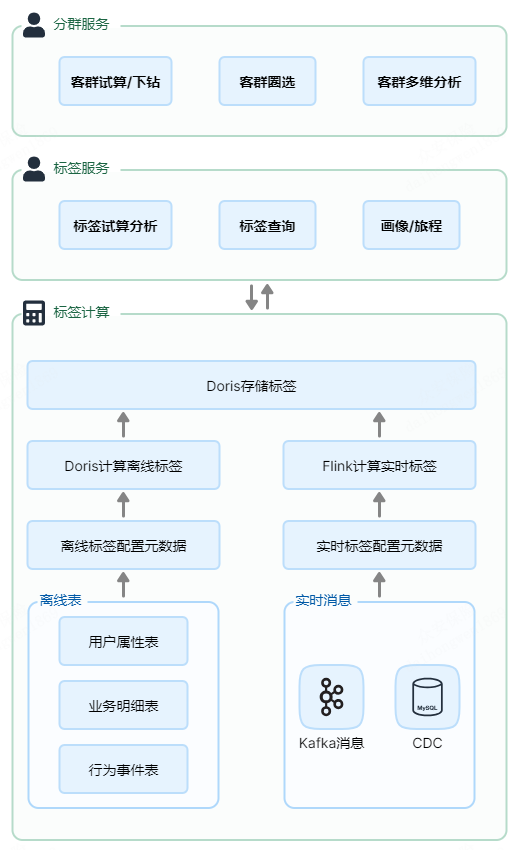
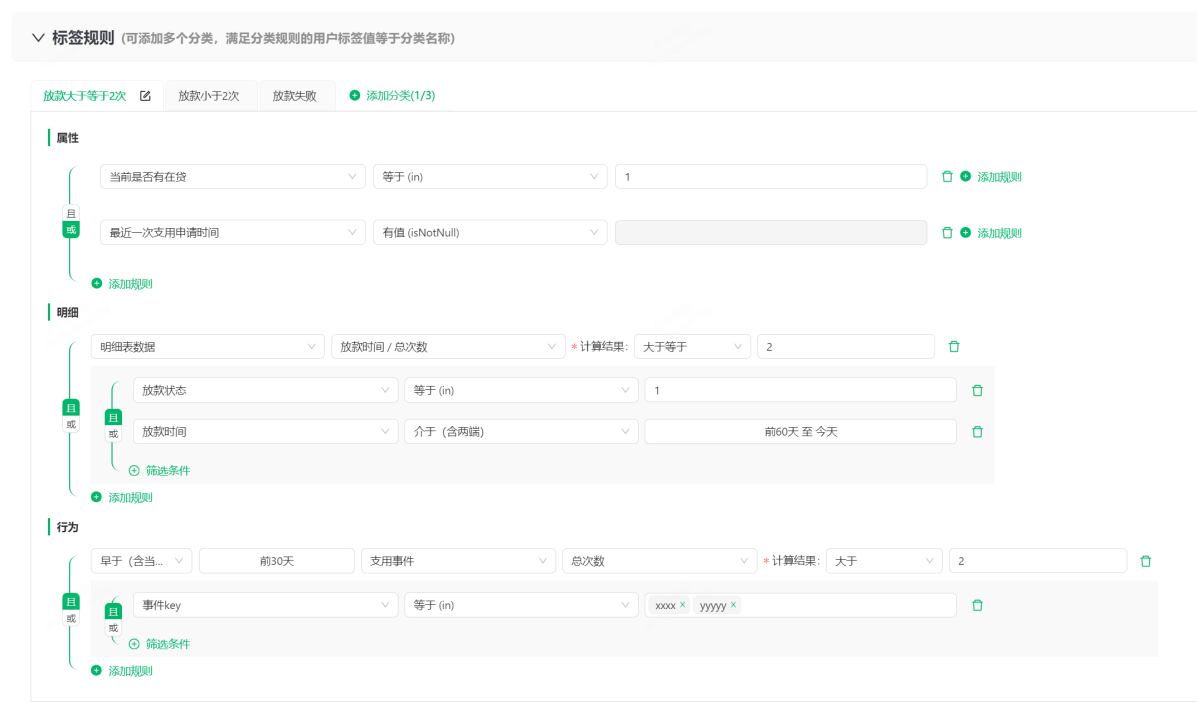
在标签体系中,有一些简单的配置规则:
Apache Doris 在标签体系中的应用主要包含以下四个方面:
1.离线标签处理: 由于拥有 2000+ 较大量级的标签一级用户,当遇到高峰期并发宽表写入时,全量更新所有列可能会出现内存不足的问题。为避免该问题,我们利用 Doris 的 Insert Into Select 功能,在 session 变量中打开部分列更新开关,只更新目标表中需要修改的列,这样可显著减少内存消耗,以提升全量导入的稳定性。
set enable_unique_key_partial_update=true;insert into tb_label_result(one_id, labelxx) select one_id, label_value as labelxx2.实时标签处理: 在实时标签写入时,不同的实时标签字段更新时间不一样,而部分列更新能力可以满足此更新需求。只需打开 Partial Column,并将其设置为 True,就可以实现实时标签的部分列更新。
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,balance,last_access_time" -T /tmp/test.csv复制代码3.标签点查:随着线上业务量的不断增长,我们面临着处理超过 5000 QPS 标签请求的挑战。为满足这一需求,我们采用多种策略来确保高效的点查性能。首先,通过利用 PrepareStatement 技术,预编译和执行 SQL 查询,从而提高查询效率。其次,精细调整了 Backend(BE)参数和表参数,以优化数据存储和查询性能。同时,我们打开了行存,进一步提升系统在高并发场景下的处理能力。
disable_storage_row_cache = falsestorage_page_cache_limit=40%
复制代码enable_unique_key_merge_on_write = truestore_row_column = truelight_schema_change = true
复制代码4.标签计算:为了满足用户对于标签配置的灵活需求,系统允许在 DSL 生成的语义中进行多表 Join 操作,而这就可能会涉及十几张表的 Join 操作。为了确保标签计算性能最优,我们充分运用 Doris Colocation Group 策略,对所有分桶列的类型、数量和副本进行统一,并优先满足 Colocation Join 和本地的 Hash Join。在线上环境中,也可以打开Colocate With开关,指定一个 Group,确保全局表的分片与副本策略一致。
客群圈选
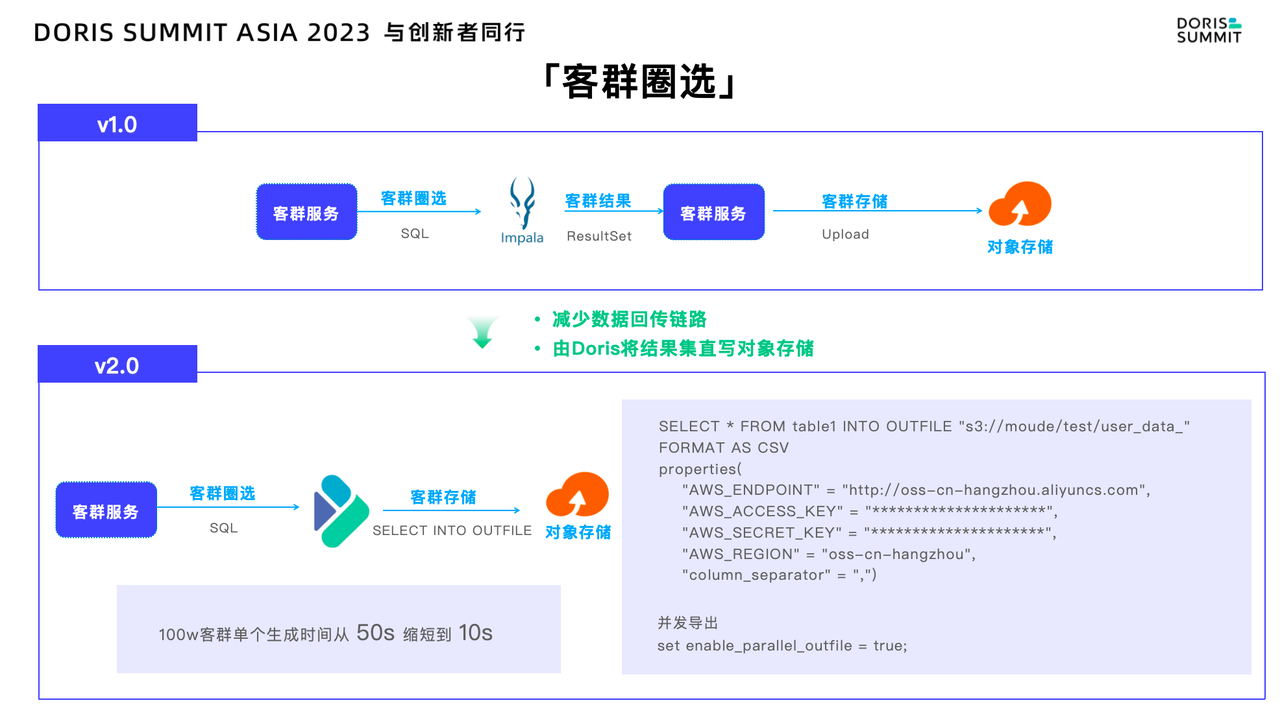
在架构 1.0 中,客群服务先生成动态 SQL,然后将其传输到 Impala 中进行客群圈选。完成圈选后,结果集需被重新读取回客群服务,并由其上传到对象存储中。这一连串的操作使得数据处理链路相对冗长,影响了整体效率。而在架构 2.0 中,我们可以在 Doris 中使用基于 Select 语句的结果集,并通过 Select Into Outfile 功能,将数据无缝导入到 S3 协议的对象存储中,这种方式极大缩短了数据处理链路。
在实际的业务中,线上约有 100 万个客群,单个客群生成所需时间从 50 秒缩短至 10 秒,极大提升了客群圈选效率。若需要进一步提高性能,可以选择打开并发导出开关,进一步提高数据导出性能。
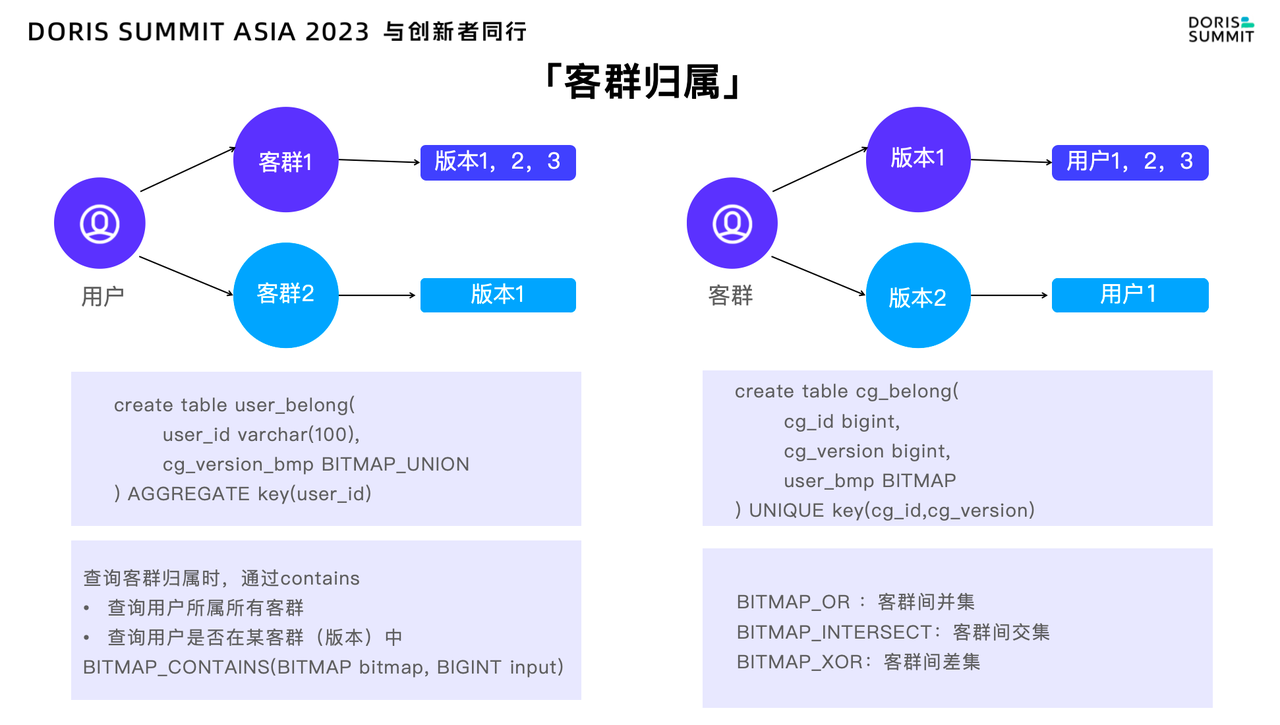
客群归属
在我们的业务系统中,客群归属扮演着至关重要的角色,特别是在实时智能营销和千人千面的识别场景中。我们经常需要判断某个用户是否隶属于特定的客群,或者确定其属于哪些客群。这种全局性的判断有助于我们深入理解多个客群之间的用户重叠关系。
为了满足这一需求,我们可以借助 Bitmap 来实现。在 Bitmap 中,使用 Bitmap Contains 可以快速识别某个用户是否存在于特定客群中,也可以通过 BitmapOR、Bitmap Intersect 或 Bitmap XOR 来实现客群全量、多版本之间的交并叉分析,从而提供更为精准和高效的营销策略。
总结与展望
在架构 1.0 中采用了复杂的技术组合,以实现标签、客群以及 OneID 的计算。这一架构组件众多,导致数据处理链路冗长、造成数据孤岛,且有着较高的管理和维护成本。通过引入 Apache Doris ,替换了 Spark + Impala + Hbase + Nebula,成功实现存储与计算的统一,简化了数据处理的流程,不仅降低了系统的复杂性,更提升了数据处理的效率,满足了更丰富的数据处理需求。随着业务的发展,实时营销场景对实时性的要求日益提升。未来,我们计划在 3.0 版本中,实现离线标签和实时标签的混合圈选功能,并依托 Doris 进行 OneID 实时计算。这将使我们能够更快速、准确地识别增量的用户,并在多用户体系中实现精准的用户识别,以满足不断变化的业务需求,推动实时智能营销和个性化识别场景的持续创新与发展。