背景
在线广告是互联网行业常见的商业变现方式。从工程角度看,广告索引的结构和实现方式直接决定了整个系统的服务性能。本文以美团的搜索广告系统为蓝本,与读者一起探讨广告系统的工程奥秘。
领域问题
广告索引需具备以下基本特性:
层次投放模型
一般地,广告系统可抽象为如下投放模型,并实现检索、过滤等处理逻辑。
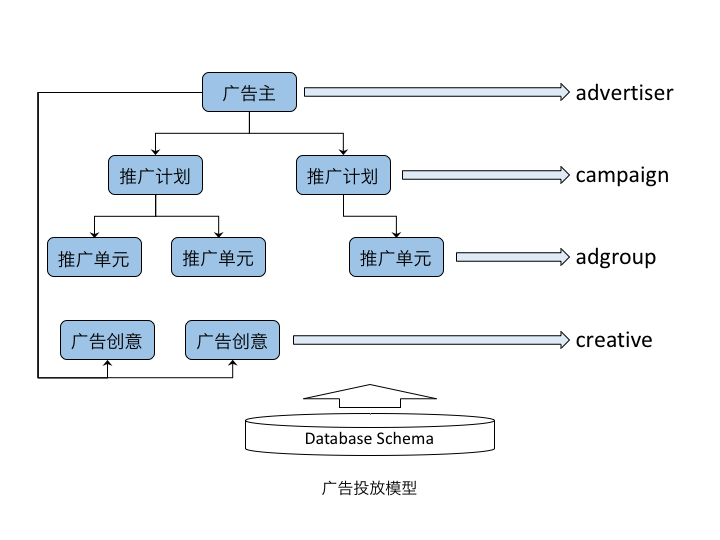
广告投放模型
该层次结构的上下层之间是一对多的关系。一个广告主通常创建若干个推广计划,每个计划对应一个较长周期的 KPI,比如一个月的预算和投放地域。一个推广计划中的多个推广单元分别用于更精细的投放控制,比如一次点击的最高出价、每日预算、定向条件等。广告创意是广告曝光使用的素材,根据业务特点,它可以从属于广告主或推广计划层级。
实时更新机制
层次结构可以更准确、更及时地反应广告主的投放控制需求。投放模型的每一层都会定义若干字段,用于实现各类投放控制。广告系统的大部分字段需要支持实时更新,比如审核状态、预算上下线状态等。例如,当一个推广单元由可投放状态变为暂停状态时,若该变更没有在索引中及时生效,就会造成大量的无效投放。
业界调研
目前,生产化的开源索引系统大部分为通用搜索引擎设计,基本无法同时满足上述条件。
因此,广告业界要么基于开源方案进行定制,要么从头开发自己的闭源系统。在经过再三考虑成本收益后,我们决定自行设计广告系统的索引系统。
索引设计
工程实践重点关注稳定性、扩展性、高性能等指标。
设计分解
设计阶段可分解为以下子需求。
实时索引
广告场景的更新流,涉及索引字段和各类属性的实时更新。特别是与上下线状态相关的属性字段,需要在若干毫秒内完成更新,对实时性有较高要求。
用于召回条件的索引字段,其更新可以滞后一些,如在几秒钟之内完成更新。采用分而治之的策略,可极大降低系统复杂度。
* 属性字段的更新:直接修改正排表的字段值,可以保证毫秒级完成。* 索引字段的更新:涉及更新流实时计算、倒排索引等的处理过程,只需保证秒级完成。此外,通过定期切换全量索引并追加增量索引,由索引快照确保数据的正确性。
层次结构
投放模型的主要实体是广告主(Advertiser)、推广计划(Campaign)、广告组(Adgroup)、创意(Creative)等。其中:
* 广告主和推广计划:定义用于控制广告投放的各类状态字段。* 广告组:描述广告相关属性,例如竞价关键词、最高出价等。* 创意:与广告的呈现、点击等相关的字段,如标题、创意地址、点击地址等。一般地,广告检索、排序等均基于广告组粒度,广告的倒排索引也是建立在广告组层面。借鉴关系数据库的概念,可以把广告组作为正排主表(即一个 Adgroup 是一个 doc),并对其建立倒排索引;把广告主、推广计划等作为辅表。主表与辅表之间通过外键关联。
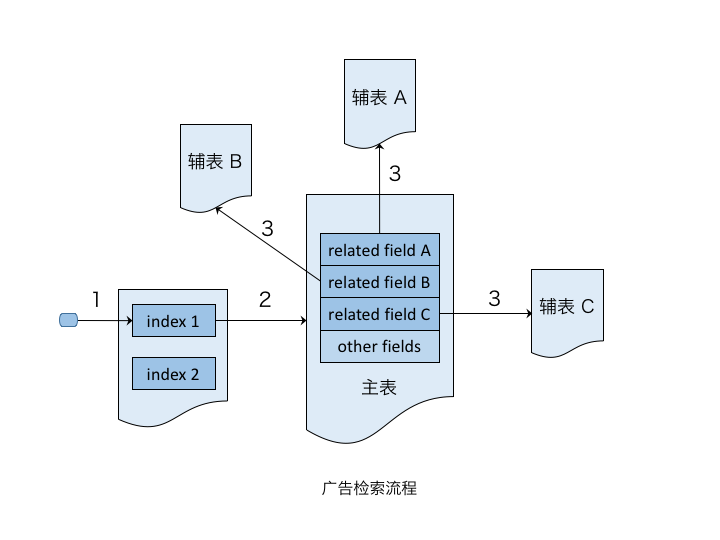
广告检索流程
检索流程中实现对各类字段值的同步过滤。
可靠高效
广告索引结构相对稳定且与具体业务场景耦合较弱,为避免 Java 虚拟机由于动态内存管理和垃圾回收机制带来的性能抖动,最终采用 C++11 作为开发语言。虽然 Java 可使用堆外内存,但是堆外堆内的数据拷贝对高并发访问仍是较大开销。项目严格遵循《Google C++ Style》,大幅降低了编程门槛。
在“读多写少”的业务场景,需要优先保证“读”的性能。检索是内存查找过程,属于计算密集型服务,为保证 CPU 的高并发,一般设计为无锁结构。可采用“一写多读”和延迟删除等技术,确保系统高效稳定运转。此外,巧妙利用数组结构,也进一步优化了读取性能。
灵活扩展
正排表、主辅表间的关系等是相对稳定的,而表内的字段类型需要支持扩展,比如用户自定义数据类型。甚至,倒排表类型也需要支持扩展,例如地理位置索引、关键词索引、携带负载信息的倒排索引等。通过继承接口,实现更多的定制化功能。
逻辑结构
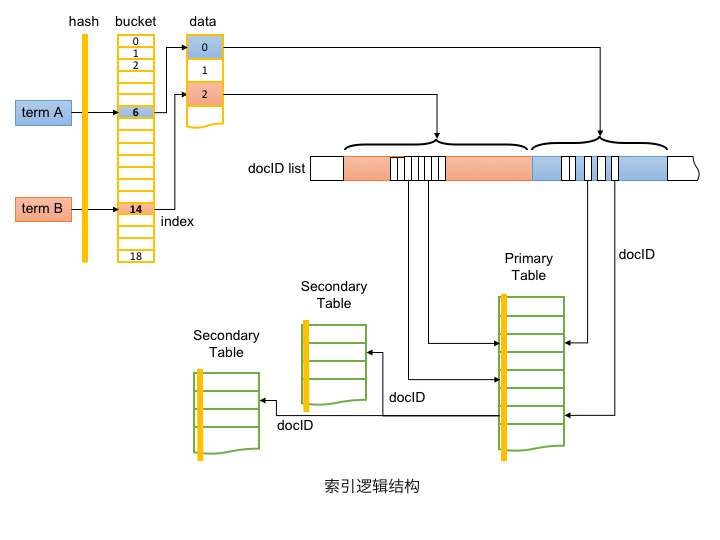
广告检索流程
从功能角度,索引由 Table 和 Index 两部分组成。如上图所示,Index 实现由 Term 到主表 docID 的转换;Table 实现正排数据的存储,并通过 docID 实现主表与辅表的关联。
分层架构
索引库分为三层:
索引实现
本节将自底向上,从存储层开始,逐一描述各层的设计细节和挑战点。
存储层
存储层负责内存分配以及数据的持久化,可使用 mmap 实现到虚拟内存空间的映射,由操作系统实现内存与文件的同步。此外,mmap 也便于外部工具访问或校验数据的正确性。
将存储层抽象为分配器(Allocator)。针对不同的内存使用场景,如对内存连续性的要求、内存是否需要回收等,可定制实现不同的分配器。
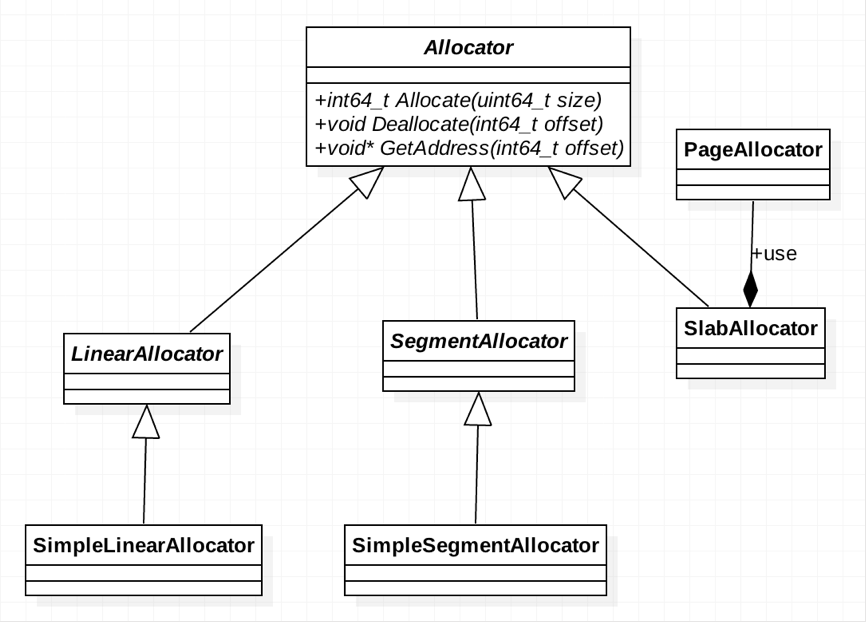
内存分配器
以下均为基于 mmap 的各类分配器,这里的“内存”是指调用进程的虚拟地址空间。实际的代码逻辑还涉及复杂的 Metadata 管理,下文并未提及。
简单的分配策略
集约的分配策略
频繁的增加、删除、修改等数据操作将导致大量的外部碎片。采用压缩操作,可以使占用的内存更紧凑,但带来的对象移动成本却很难在性能和复杂度之间找到平衡点。在工程实践中,借鉴 Linux 物理内存的分配策略,自主实现了更适于业务场景的多个分配器。
在此简要阐述伙伴分配器的处理过程,为有效管理空闲块,每一级 order 持有一个空闲块的 FreeList。设定最大级别 order=4,即从 order=0 开始,由低到高,每级 order 块内页数分别为 1、2、4、8、16 等。分配时先找满足条件的最小块;若找不到则在上一级查找更大的块,并将该块分为两个“伙伴”,其中一个分配使用,另一个置于低一级的 FreeList。
下图呈现了分配一个页大小的内存块前后的状态变化,分配前,分配器由 order=0 开始查找 FreeList,直到 order=4 才找到空闲块。
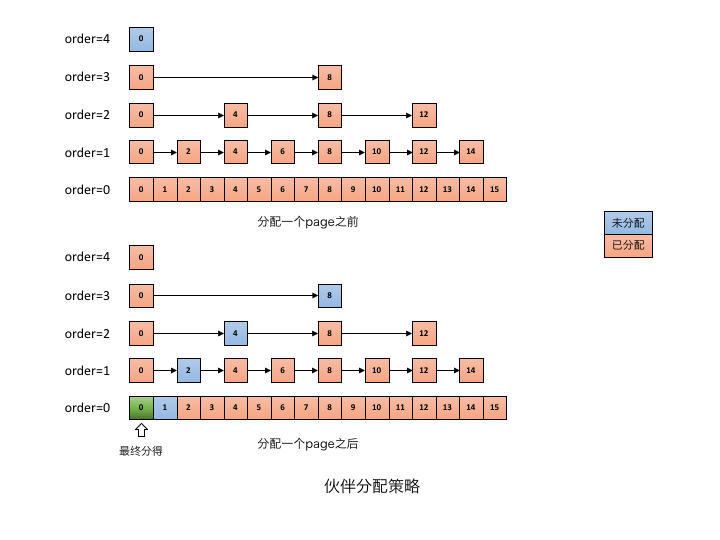
伙伴分配器策略
将该空闲块分为页数为 8 的 2 个伙伴,使用前一半,并将后一半挂载到 order=3 的 FreeList;逐级重复此过程,直到返回所需的内存块,并将页数为 1 的空闲块挂在到 order=0 的 FreeList。
当块释放时,会及时查看其伙伴是否空闲,并尽可能将两个空闲伙伴合并为更大的空闲块。这是分配过程的逆过程,不再赘述。
虽然 PageAllocator 有效地避免了外部碎片,却无法解决内部碎片的问题。为解决这类小对象的分配问题,实现了对象缓存分配器(SlabAllocator)。
对象的内存分配过程,即从对应的 PartialFreeList 获取含有空闲对象的 slab,并从该 slab 分配对象。反之,释放过程为分配的逆过程。
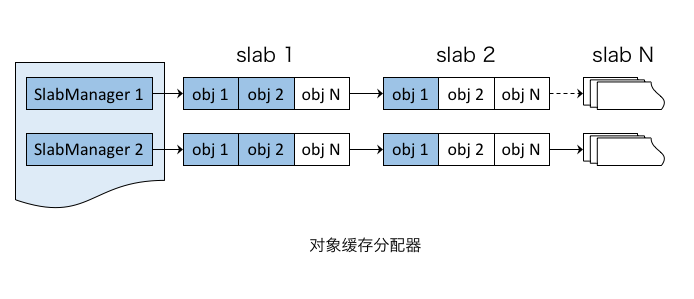
对象缓存分配器
综上,实时索引存储结合了 PageAllocator 和 SlabAllocator,有效地解决了内存管理的外部碎片和内部碎片问题,可确保系统高效稳定地长期运行。
能力层
能力层实现了正排表、倒排表等基础的存储能力,并支持索引能力的灵活扩展。
正向索引
也称为正排索引(Forward Index),即通过主键(Key)检索到文档(Doc)内容,以下简称正排表或 Table。不同于搜索引擎的正排表数据结构,Table 也可以单独用于 NoSQL 场景,类似于 Kyoto Cabinet 的哈希表。
Table 不仅提供按主键的增加、删除、修改、查询等操作,也配合倒排表实现检索、过滤、读取等功能。作为核心数据结构,Table 必须支持频繁的字段读取和各类型的正排过滤,需要高效和紧凑的实现。
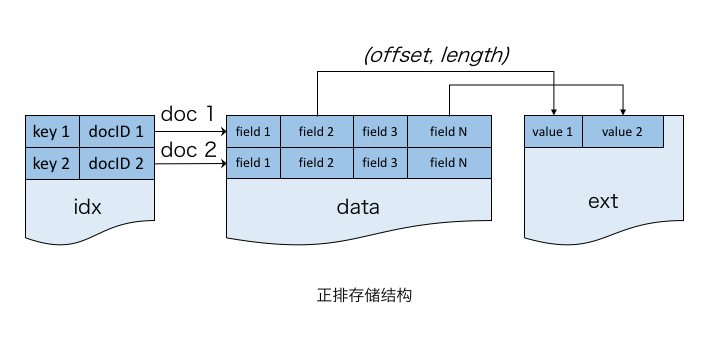
正排存储结构
为支持按 docID 的随机访问,把 Table 设计为一个大数组结构(data 区)。每个 doc 是数组的一个元素且长度固定。变长字段存储在扩展区(ext 区),仅在 doc 中存储其在扩展区的偏移量和长度。与大部分搜索引擎的列存储不同,将>
此外,针对 NoSQL 场景,可通过 HashMap 实现主键到 docID 的映射(idx 文件),这样就可支持主键到文档的随机访问。由于倒排索引的 docID 列表可以直接访问正排表,因此倒排检索并不会使用该 idx。
反向索引
也称作倒排索引(Inverted Index),即通过关键词(Keyword)检索到文档内容。为支持复杂的业务场景,如遍历索引表时的算法粗排逻辑,在此抽象了索引器接口 Indexer。

索引器接口定义
具体的 Indexer 仅需实现各接口方法,并将该类型注册到 IndexerFactory,可通过工厂的 NewIndexer 方法获取 Indexer 实例,类图如下:
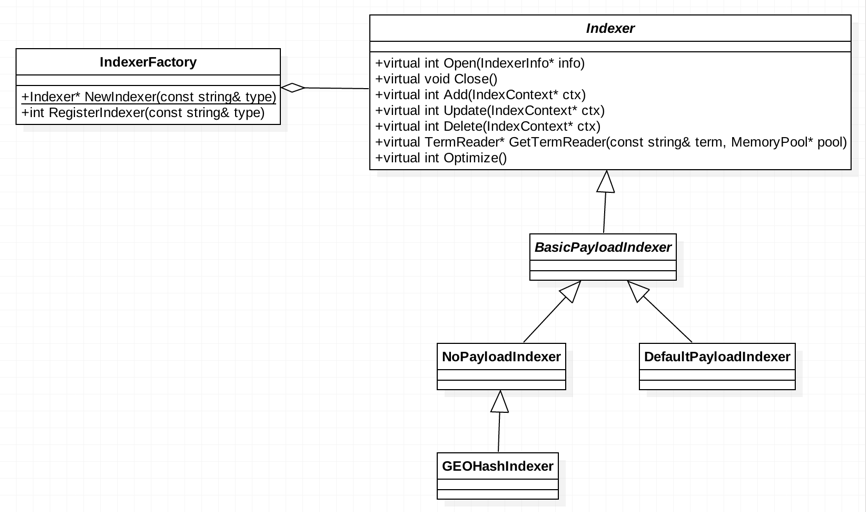
索引器接口类图
当前实现了三种常用的索引器:
上述索引器的设计思路类似,仅阐述其共性的两个特征:
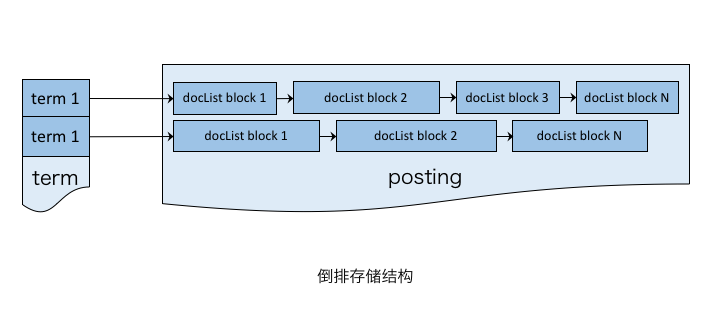
倒排存储结构
出于业务考虑,没有采用 Lucene 的 Skip list 结构,因为广告场景的 doc 数量没有搜索引擎多,且通常为单个倒排列表的操作。此外,若后续 doc 数量增长过快且索引变更频繁,可考虑对倒排列表的元素构建 B+树结构,实现倒排元素的快速定位和修改。
接口层
接口层通过 API 与外界交互,并屏蔽内部的处理细节,其核心功能是提供检索和更新服务。
配置文件
配置文件用于描述整套索引的 Schema,包括 Metadata、Table、Index 的定义,格式和内容如下:

索引配置文件
可见,Index 是构建在 Table 中的,但不是必选项;Table 中各个字段的定义是 Schema 的核心。当 Schema 变化时,如增加字段、增加索引等,需要重新构建索引。篇幅有限,此处不展开定义的细节。
检索接口
检索由查找和过滤组成,前者产出查找到的 docID 集合,后者逐个对 doc 做各类基础过滤和业务过滤。

检索接口定义
一般仅需调用 Search 就可实现全部功能;DoSearch 和 DoFilter 可用于实现更复杂的业务逻辑。
以下为检索的语法描述:
/{table}/{indexer|keyfield}?query=xxxxxx&filter=xxxxx
第一部分为路径,用于指定表和索引。第二部分为参数,多个参数由 &分隔,与 URI 参数格式一致,支持 query、filter、Payload_filter、index_filter 等。
由 query 参数定义对倒排索引的检索规则。目前仅支持单类型索引的检索,可通过 index_filter 实现组合索引的检索。可支持 AND、OR、NOT 等布尔运算,如下所示:
query=(A&B|C|D)!E
查询语法树基于 Bison 生成代码。针对业务场景常用的多个 term 求 docID 并集操作,通过修改 Bison 文法规则,消除了用于存储相邻两个 term 的 doc 合并结果的临时存储,直接将前一个 term 的 doc 并入当前结果集。该优化极大地减少了临时对象开销。
由 filter 参数定义各类正排表字段值过滤,多个键值对由“;”分割,支持单值字段的关系运算和多值字段的集合运算。
由 Payload_filter 参数定义 Payload 索引的过滤,目前仅支持单值字段的关系运算,多个键值对由“;”分割。
详细的过滤语法如下:
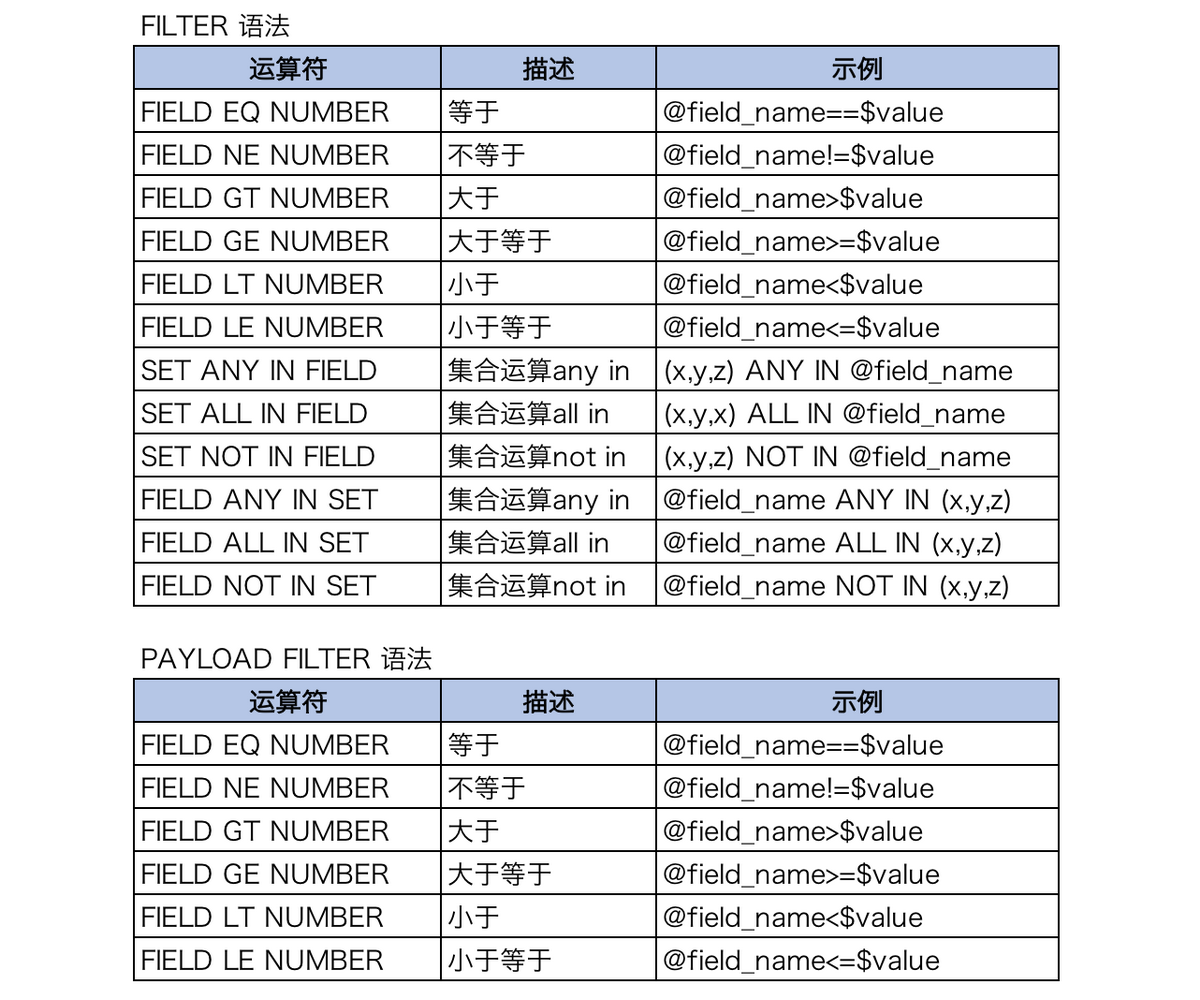
过滤语法格式
此外,由 index_filter 参数定义的索引过滤将直接操作倒排链。由于构造检索数据结构比正排过滤更复杂,此参数仅适用于召回的 docList 特别长但通过索引过滤的 docList 很短的场景。
结果集
结果集 ResultSet 的实现,参考了 java.sql.ResultSet 接口。通过 cursor 遍历结果集,采用 inline 函数频繁调用的开销。
实现为 C++模板类,主要接口定义如下:

结果集接口定义
更新接口
更新包括对 doc 的增加、修改、删除等操作。参数类型 Document,表示一条 doc 记录,内容为待更新的 doc 的字段内容,key 为字段名,value 为对应的字段值。操作成功返回 0,失败返回非 0,可通过 GetErrorString 接口获取错误信息。

更新接口定义
更新服务对接实时更新流,实现真正的广告实时索引。
更新系统
除以上描述的索引实现机制,生产系统还需要打通在线投放引擎与商家端、预算控制、反作弊等的更新流。
挑战与目标
数据更新系统的主要工作是将原始多个维度的信息进行聚合、平铺、计算后,最终输出线上检索引擎需要的维度和内容。
业务场景导致上游触发可能极不规律。为避免更新流出现的抖动,必须对实时更新的吞吐量做优化,留出充足的性能余量来应对触发的尖峰。此外,更新系统涉及多对多的维度转换,保持计算、更新触发等逻辑的可维护性是系统面临的主要挑战。
吞吐设计
虽然更新系统需要大量的计算资源,但由于需要对几十种外部数据源进行查询,因此仍属于 IO 密集型应用。优化外部数据源访问机制,是吞吐量优化的主要目标。
在此,采取经典的批量化方法,即集群内部,对于可以批量查询的一类数据源,全部收拢到一类特定的 worker 上来处理。在短时间内,worker 聚合数据源并逐次返回给各个需要数据的数据流。处理一种数据源的 worker 可以有多个,根据同类型的查询汇集到同一个 worker 批量查询后返回。在这个划分后,就可以做一系列的逻辑优化来提升吞吐量。
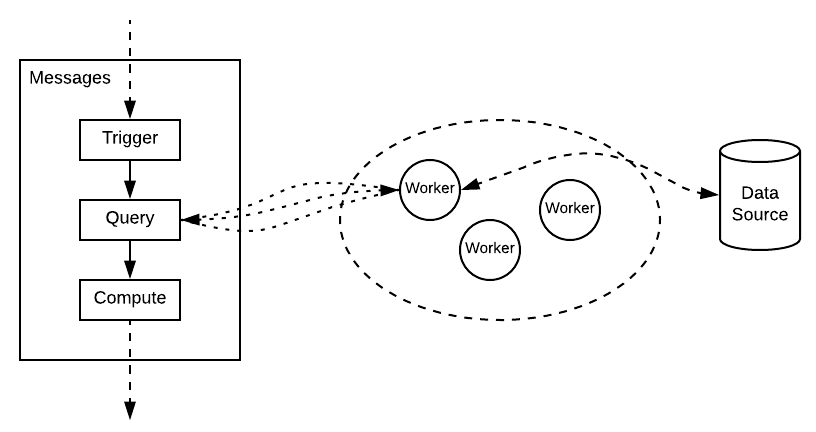
分层抽象
除生成商家端的投放模型数据,更新系统还需处理针对各种业务场景的过滤,以及广告呈现的各类专属信息。业务变更可能涉及多个数据源的逻辑调整,只有简洁清晰的分成抽象,才能应对业务迭代的复杂度。
工程实践中,将外部数据源抽象为统一的 Schema,既做到了数据源对业务逻辑透明,也可借助编译器和类型系统来实现完整的校验,将更多问题提前到编译期解决。
将数据定义为表(Table)、记录(Record)、字段(Field)、值(Value)等抽象类型,并将其定义为 Scala Path Dependent Type,方便编译器对程序内部的逻辑进行校验。
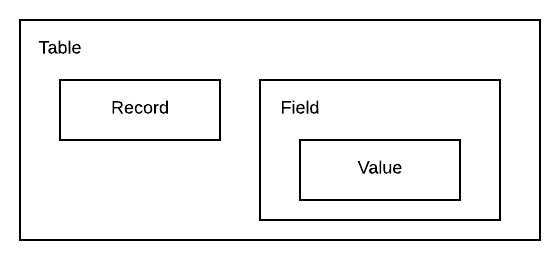
可复用设计
多对多维度的计算场景中,每个字段的处理函数(DFP)应该尽可能地简单、可复用。例如,每个输出字段(DF)的 DFP 只描述需要的源数据字段(SF)和该字段计算逻辑,并不描述所需的 SF(1)到 SF(n)之间的查询或路由关系。
此外,DFP 也不与最终输出的层级绑定。层级绑定在定义输出消息包含的字段时完成,即定义消息的时候需要定义这个消息的主键在哪一个层级上,同时绑定一系列的 DFP 到消息上。
这样,DFP 只需单纯地描述字段内容的生成逻辑。如果业务场景需要将同一个 DF 平铺到不同层级,只要在该层级的输出消息上引用同一个 DFP 即可。
触发机制
更新系统需要接收数据源的状态变动,判断是否触发更新,并需要更新哪些索引字段、最终生成更新消息。
为实现数据源变动的自动触发机制,需要描述以下信息:
生产实践
早期的搜索广告是基于自然搜索的系统架构建的,随着业务的发展,需要根据广告特点进行系统改造。新的广告索引实现了纯粹的实时更新和层次化结构,已经在美团搜索广告上线。该架构也适用于各类非搜索的业务场景。
系统架构
作为整个系统的核心,基于实时索引构建的广告检索过滤服务(RS),承担了广告检索和各类业务过滤功能。日常的业务迭代,均可通过升级索引配置完成。
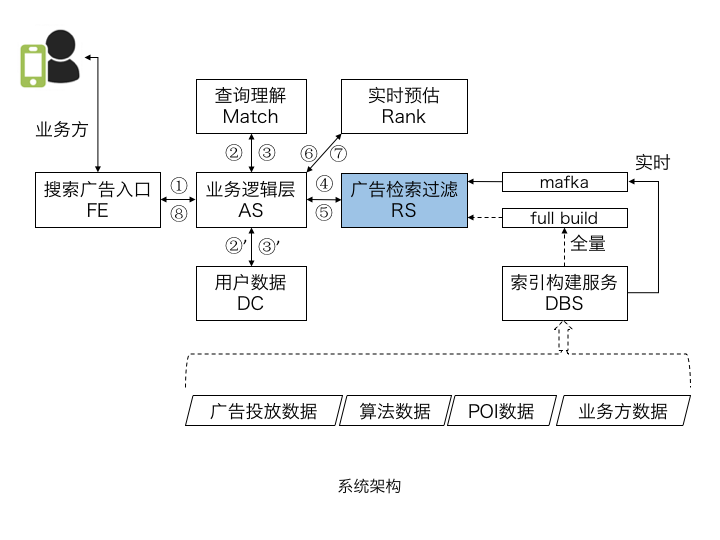
系统架构
此外,为提升系统的吞吐量,多个模块已实现服务端异步化。
性能优化
以下为监控系统的性能曲线,索引中的 doc 数量为百万级别,时延的单位是毫秒。
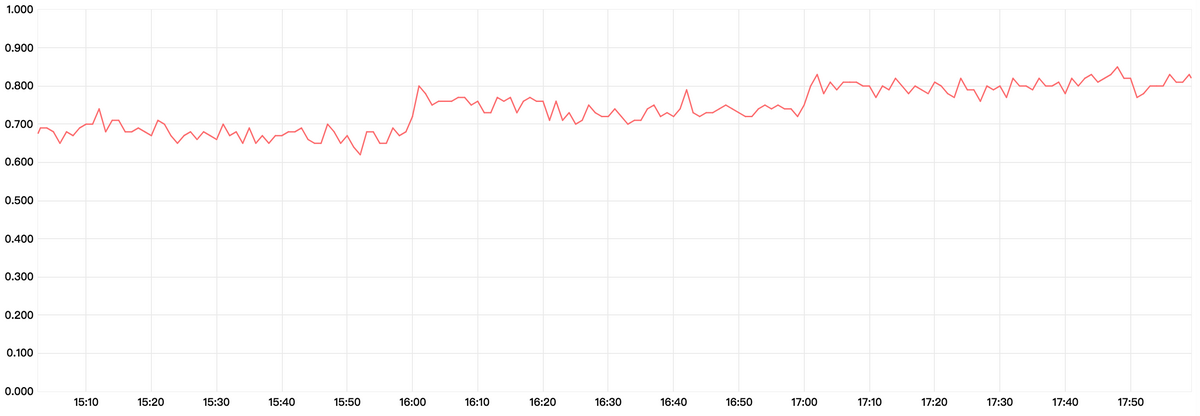
索引查询性能
后续规划
为便于实时索引与其他生产系统的结合,除进一步的性能优化和功能扩展外,我们还计划完成多项功能支持。
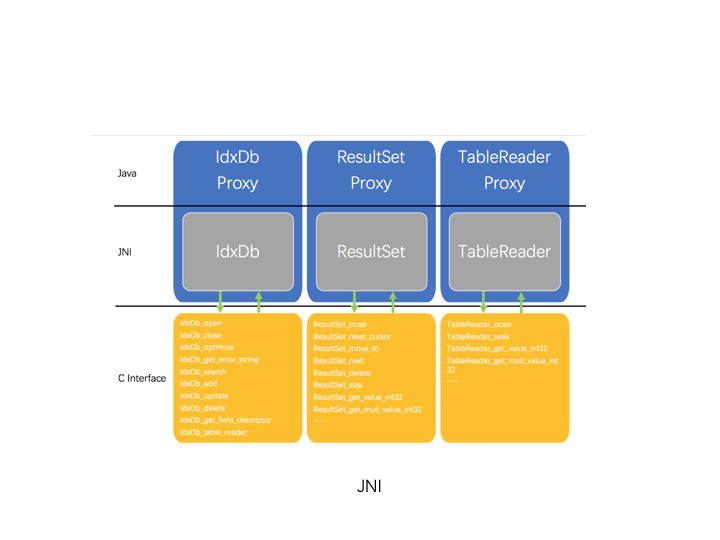
通过 JNI,将 Table 作为单独的 NoSQL,为 Java 提供本地缓存。如广告系统的实时预估模块,可使用 Table 存储模型使用的广告特征。
索引库 JNI
提供 SQL 语法,提供简单的 SQL 支持,进一步降低使用门槛。提供 JDBC,进一步简化 Java 的调用。