3.3.1>我们在 CNN/DAILY MAIL ( Hermann et al., 2015 ) 和 SQUAD ( Raj- purkar et al., 2016 ) 上评估了我们的模型。我们在之前的 2.1.3 节中已经描述过数据集的构建方式以及它们在神经阅读理解发展中的重要性。现在我们简要回顾一下这些数据集和统计数据。
CNN /DAILYMAIL 是使用 CNN 和 Daily Mail 里面的文章及其要点摘要进行构建的。一个要点被转换成一个问题,一个实体被一个占位符替换,答案就是这个实体。文本已经通过谷歌 NLP pipeline 运行。Tokenized,小写化以及命名实体识别和指代消歧已经被运行过了。对于每个包含至少一个命名实体的 coreference 链,链中的所有项都用 @entityn 标记替换,以表示不同的索引 n ( Table 2.1 (a) )。平均而言,CNN 和 DAILY MAIL 在文章中都包含了 26.2 个不同的实体。训练、开发和测试示例是从不同时期的新闻文章中收集的。评估使用准确度 ( 预测正确实体的实例的百分比 ) 这个指标。
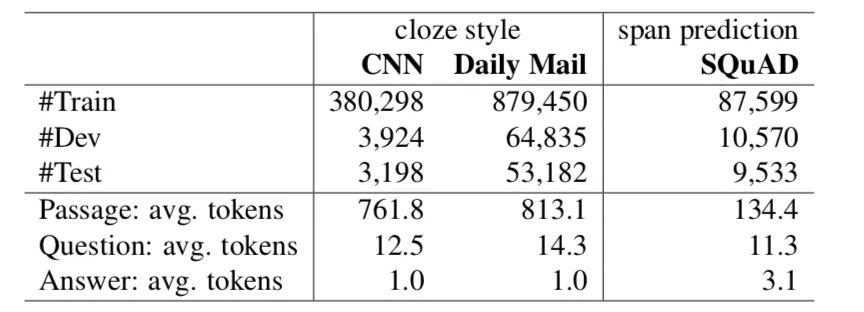
Table 3.2:>
SQUAD 数据集是根据维基百科上的文章收集的。抽取了 536 篇高质量的维基百科文章作为样本,众包工人根据每一段创建问题 ( 删除长度小于 500 个字符的段落 ),并且要求答案必须在每一段中突出显示 ( 表 2.1 (c) )。训练/开发/测试数据的由文章随机划分获得 ( 80% vs. 10% vs. 10% )。为了评估人类的表现并使评估更可靠,他们为每个问题收集了一些额外的答案 ( 开发集中的每个问题平均有 3.3 个答案 )。如 2.2.2 节所述,我们使用精确匹配和宏观平均 F1 分数进行评估。请注意,SQUAD 2.0 ( Rajpurkar et al., 2018 ) 是最近提出的,它在原始数据集中添加了 53,775 个无法回答的问题,我们将在第 4.2 节中讨论它。在本论文的大部分内容中,除非另有说明,否则“SQUAD”指的是“SQUAD1.1”。
表 3.2 给出了更详细的数据集统计。如图所示,由于数据集的构造方式,CNN/DAILY MAIL 的数据集比 SQUAD 大得多 ( 几乎大一个数量级 )。CNN/DAILY MAIL 中使用的段落也要长得多,CNN 和 DAILY MAIL 分别是 761.8 和 813.1 token,而 SQUAD 是 134.4 token。最后,SQUAD 的答案平均只有 3.1 个令牌,这反映了小队的问题大部分都是陈述型,大部分的答案都是常见的名词或命名实体。
3.3.2 Implementation Details
除了不同体系结构的模型设计,实现细节对这些神经阅读理解系统的最终性能也起着至关重要的作用。在接下来的文章中,我们将重点介绍一些我们还没有涉及到的重要方面,最后给出我们在这两个数据集中使用的模型规范。
Stacked BiLSTMs。一个简单的方法是增加用于问题和篇章编码的双向 LSTMs 的深度。它计算 ,然后将 作为下一层的输入 ,传递给另一层 BiLSTM,以此类推。结果表明,堆叠的 BiLSTM 比单层的 BiLSTM 效果好。在 SQUAD 实验中,我们使用了 3 层。
Dropout。在神经网络正则化中,Dropout 是一种有效且应用广泛的方法。简单地说,dropout 是指在训练过程中随机屏蔽掉一些单元。对于我们的模型,可以将 dropout 添加到每个 LSTM 层的嵌入、输入向量和隐藏向量中。最后,dropout 的变种方法 ( Gal 和 Ghahramani, 2016 ) 已经被证明在 RNNs 规范化方面比标准 dropout 更好。这个想法是应用相同的 dropout 掩盖在每一个时间步骤的输入,输出和重复层,例如,在每一个 time step 中会 drop 相同的单位。我们建议读者在实践中使用这种变体。
Handling word embedding。常用处理字嵌入的方法之一 ( 也是我们的默认选择 ) 是在训练集中保持最常见的 K ( 如 K = 500,000 ) 种 word 并将所有其他 word 映射到一个 令牌,然后使用 pre-trained 字嵌入的初始化 K 个 word。通常,当训练集足够大时,我们对所有单词 embeddings 进行微调;当训练集相对较小时 ( 例如,SQUAD ),我们通常将所有嵌入的单词都固定为静态特性。在 Chen 等人 ( 2017 ) 的研究中,我们发现对最常见的疑问词进行微调是有帮助的,因为这些关键词的表征,如 what, how, which 可能对阅读理解至关重要系统。( Dhingra et al., 2017a ) 等研究表明,对预训练的词嵌入和对集合外单词的应对方式会对阅读理解任务的性能有很大的影响。
Model specifications。对于所有需要语言学标注的实验 ( lemma,part-of-speech tags,named entity tags, dependency parses ),我们使用 Stanford CoreNLP toolkit ( Manning et al., 2014 ) 进行预处理。为了训练所有的神经模型,我们按照它的篇章长度对所有的示例进行排序,并为每次 ( weights 的 ) update 随机抽取大小为 32 的小批样本。
对于 CNN/DAILY MAIL 的结果,我们使用在 Wikipedia 和 Gi- gaword 上训练过的小写的、100 维的预训练好的 GLOVE 词嵌入 ( Pennington et al., 2014 ) 进行初始化。Attention 和输出 ( 层 ) 的参数使用均匀分布初始化,LSTM 权值由高斯分布 N ( 0,0.1 ) 初始化。我们使用一个隐藏大小为 h = 128 的 1 层 BiLSTM 用于 CNN, h = 256 用于 DAILY MAIL。采用 vanilla stochastic gradient descent ( SGD ) 进行优化,固定学习率为 0.1。当梯度范数超过 10 时,我们还将概率为 0.2 的 dropout 应用于嵌入层和梯度裁剪。
对于 SQUAD 的结果,我们使用隐藏单元 h = 128 的的 3 层 BiLSTMs 对段落和问题进行编码。我们使用 ADAMAX 进行优化,如 ( Kingma 和 Ba, 2014 ) 所述。约 0.3 的 Dropout 应用于 word 嵌入和 LSTMs 的所有隐藏单元。我们使用从 840B Web 抓取数据中训练的 300 维 GLOVE 词嵌入进行初始化,只微调了 1000 个最常见的问题词。
其他的实现细节可以在以下的两个 github 的仓库中找到:
our experiments in Chen et al. ( 2016 ).
our experiments in Chen et al. ( 2017 ).
我们也想提醒读者,我们的实验结果发表在了 2016 年和 2017 年的两篇论文中,并且在很多地方有所不同。一个关键的区别是,我们在 CNN /英国《每日邮报》的结果不包括手动特征 ,精确匹配特性 ,对齐问题嵌入 和 ,仅仅需要词嵌入 。另一个不同之处在于,我们之前没有涉及编码问题的 attention 层,而只是在两个方向上连接 LSTMs 的最后一个隐藏向量。我们相信这些补充在 CNN/DAILY MAIL 和其他完形填空任务中也很有用,但我们没有进一步研究。
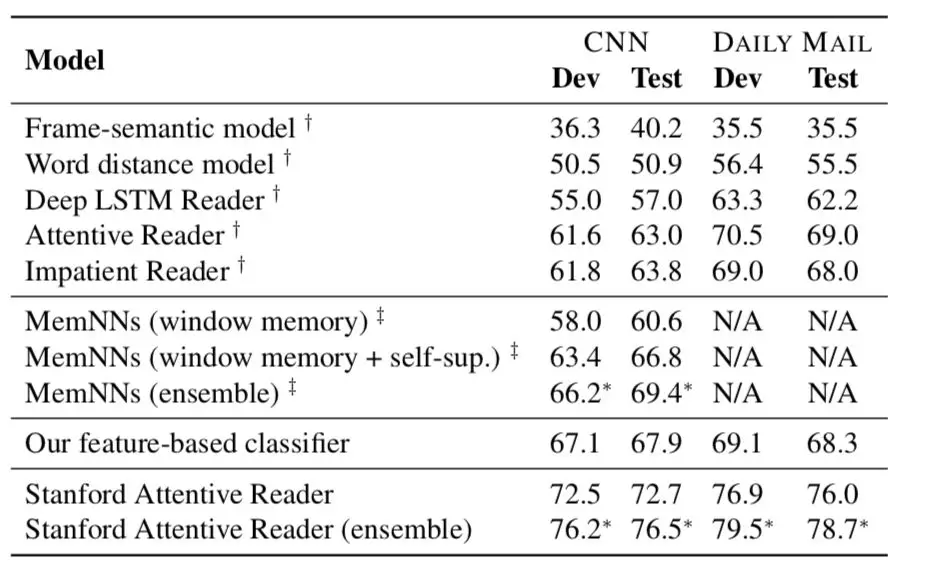
Table 3.3: Accuracy of all models on the CNN and DAILY MAIL>
3.3.3 Experimental Results
3.3.3.1 Results on CNN/DAILY MAIL
表 3.3 给出了我们在 Chen et al. ( 2016 ) 中报告的结果。我们用不同的随机种子分别运行我们的神经模型 5 次,并报告了每次运行的平均性能。我们还报告了综合结果,平均了 5 个模型的预测概率。我们还展示了我们在 3.1 节中描述的基于特征的分类器的结果。
Baselines。我们是最早研究这第一个大规模阅读理解数据集的小组之一。当时,Hermann et al. ( 2015 ) 和 Hill et al. ( 2016 ) 为这项任务提出了一些基线,包括符号方法和神经模型。基线包括:
如表 3.3 所示,我们的基于特征的分类器在 CNN 测试集上的准确率为 67.9%,在 DAILY MAIL 测试集上的准确率为 68.3%,显著优于 Hermann et al. ( 2015 ) 所报道的任何符号方法。我们认为它们的框架语义模型不适合这些任务,因为解析器的覆盖率很低,并且不能代表一个简单的 NLP 系统可以实现什么。事实上,框架语义模型甚至明显低于单词距离模型。令我们惊讶的是,我们的基于特征的分类器甚至比 Hermann et al. ( 2015 ) 和 Hill et al. ( 2016 ) 中所有的神经网络系统都表现得更好。此外,我们的单模型神经网络大大超过了之前的结果(超过 5%),将最先进的精度分别提高到 72.7%和 76.0%。5 个模型的组合始终带来进一步的 2-4%的收益。
3.3.3.2 Results on SQUAD
表 3.4 给出了我们对开发和测试集的评估结果。自创建以来,SQUAD 一直是一个非常有竞争力的基准,我们只列出了一些代表性的模式和单模式的表现。众所周知,集成模型可以进一步提高性能的几个点。我们还包括了逻辑回归基线的结果。( Rajpurkar et al., 2016 )。
我们的系统可以在测试集上达到 70.0%的精确匹配和 79.0%的 F1 成绩,超过了所有已发表的结果,并且与我们的论文中 SQUAD 排行榜上最好的性能相匹配 ( Chen et al., 2017 )。此外,我们认为我们的模型在概念上比大多数现有系统更简单。与 logistic 回归基线 F1 = 51.0 相比,该模型已经接近 30%的绝对改进,对于神经模型来说是一个巨大的胜利。
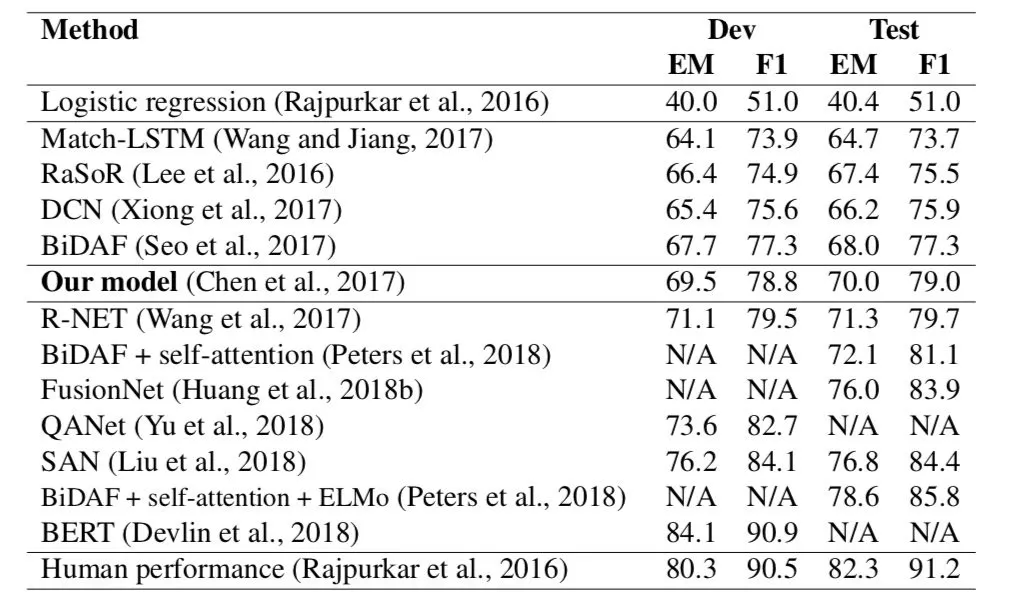
Table 3.4: Evaluation results on the SQUAD>
此后,SQUAD 受到了极大的关注,在这个数据集上取得了很大的进步,如表 3.4 所示。最近的进展包括用于初始化的预训练语言模型、更细粒度的注意机制、数据增强技术技巧,甚至更好的训练目标。我们将在第 3.4 节中讨论它们。
3.3.3.3 Ablation studies
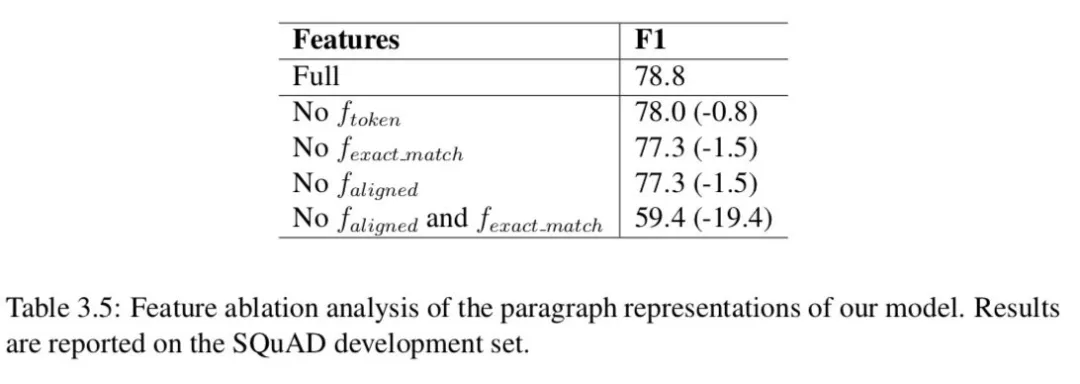
Chen 等 ( 2017 ) 对通道表征成分进行消融分析。如表 3.5 所示,所有组件都对最终系统的性能有贡献。我们发现,没有对齐的问题嵌入 ( 只有 word 嵌入和一些手动特性 ),我们的系统仍然能够实现 F1 超过 77%。精确匹配特征的有效性还表明,该数据集上的文章和问题之间存在大量的单词重叠。更有趣的是,如果我们同时去掉伪匹配和非精确匹配,性能会显著下降,因此我们得出结论,这两个特征在特征表示方面发挥着相似但互补的作用,比如问句和短文词之间的硬对齐和软对齐。
3.3.4 Analysis:What Have the Models Learned?
在 Chen et al. ( 2016 ) 中,我们试图更好地理解这些模型实际学到了什么,以及解决这些问题需要多大的语言理解深度。我们通过对 CNN 数据集开发集中的 100 个随机抽样示例进行仔细的手工分析来实现这一点。
我们大致将其分为以下几类 ( 如果一个例子满足一个以上的类别,我们将其分为前面的类别 ):
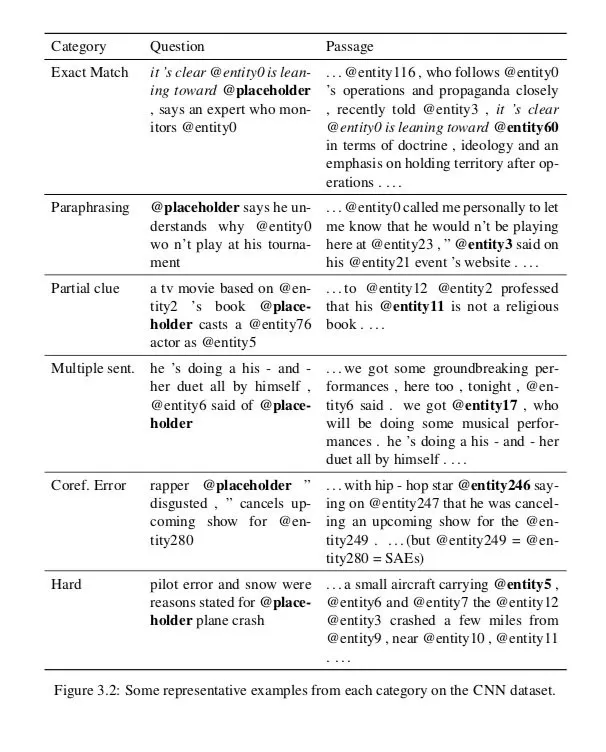
Exact match 占位符周围最近的单词也可以在围绕实体标记的段落中找到;答案不言自明。
Sentence-level paraphrasing 问题在篇章中作为一句话的结尾或者是一句话的转述,所以答案一定可以从那句话中找出来
Partial clue 在许多情况下,即使我们不能在问题文本和一些句子之间找到一个完全的语义匹配,我们仍然能够通过部分线索来推断答案,比如一些单词/概念重叠。
Multiple sentences 多句话必须被处理才能推测正确答案
Coreference errors 数据集中不可避免地存在许多指代错误。这一类别包括对出现在问题中的答案实体或关键实体具有关键共参考错误的示例。基本上,我们把这个类别视为“不可回答的”。
Ambiguous or hard 这个类别包括那些我们认为人类肯定不能获取正确答案的例子
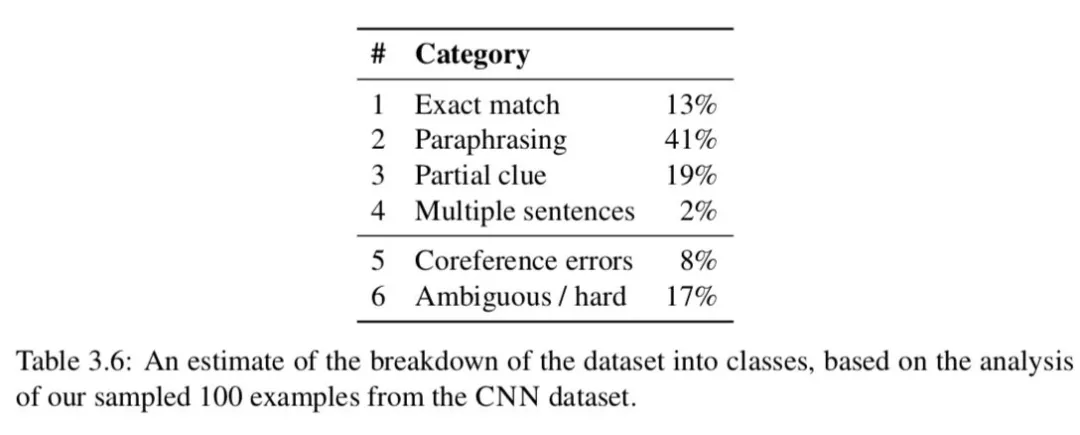
表 3.6 给出了每个类别的百分比估计值,图 3.2 给出了每个类别的一个代表性示例。我们观察到改写 ( paraphrasing ) 占 41%的例子和 19%的例子属于 partial clue ( 部分线索 ) 类别。加上最简单的 Exact match 精确匹配类别,我们假设大部分示例 ( 这个子集中 73% ) 能够通过识别最相关的 ( 单个 ) 句子并根据它推断出答案。此外,只有两个例子需要多个句子进行推理。这比我们预期的要低,这表明数据集需要的推理比之前认为的要少。令我们惊讶的是,根据我们的手工分析,“共参错误”和“模糊/困难”的情况占这个样本集的 25%,这对于准确率远远高于 75%的训练模型来说肯定是一个障碍 ( 当然,模型有时可能会做出幸运的猜测 )。事实上,我们的集成神经网络模型在开发集上已经能够达到 76.5%,我们认为在这个数据集上进一步改进的前景是很小的。
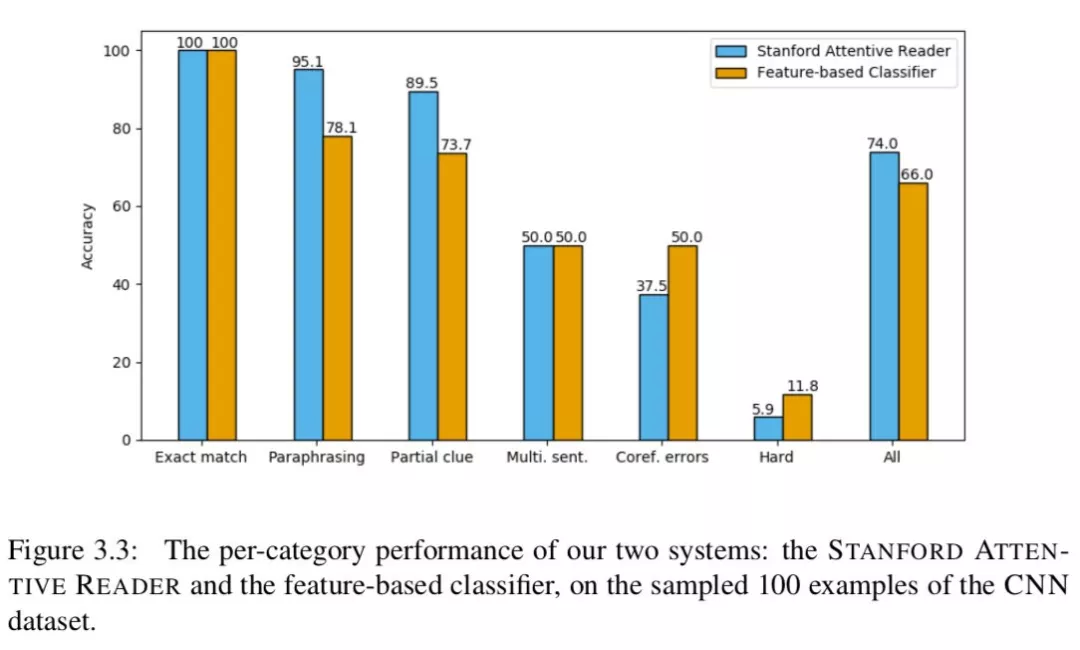
在上述分类的基础上,我们进一步研究神经网络和基于特征的分类器的分类性能。如图 3.3 所示,我们得到以下观察结果:
① 精确匹配的情况非常简单,两个系统的 tems 都得到 100%的正确。
② 对于模糊/硬连接和实体连接错误的情况,符合我们的预期,这两个系统的性能都很差。
③ 两种系统主要不同之处在于释义的情况,以及部分“部分线索”的情况。这清楚地显示了神经网络能够更好地学习语义匹配,包括释义或两个句子之间的词汇变化。
④ 我们认为神经网络模型在所有的单句和明确的情况下都已经达到了近乎最优的性能。
综上所述,我们发现与传统的基于特征的模型相比,神经网络在识别词汇匹配和释义方面无疑更强大;虽然目前还不清楚他们是否也搞定了需要更复杂的文本推理的例子,因为目前在这方面的数据集仍然非常有限。
3.4 Further Advances
在本节中,我们总结了神经阅读理解的最新进展。我们将它们分为以下四类:单词表示、注意机制、LSTMs 的变体以及其他(如训练目标、数据扩充)。最后对其重要性进行了总结和讨论。
3.4.1 Word Representations
第一类是对疑问词和短文词的更好的单词表示,因此神经模型是建立在更好的基础上的。译者注:原文有笔误,大意是神经模型是建立在 word representations 的基础上的。从文本中学习更好的分布式单词表示或者为特定任务发现更好的词嵌入集合依然是一个活跃的研究话题。例如,Mikolov 等人 ( 2017 ) 发现在我们的模型中将 GLOVE 与训练向量使用最新的 FASTTEXT 向量 ( Bojanowski 等人 2017 ) 可以早 SQUAD 上面取得 1 个百分点的提升。不仅如此,有两个关键的想法已经被证明 ( 非常 ) 有用:
Character embeddings
第一个想法是使用字符级嵌入来表示单词,这对于罕见的或词汇表外的单词尤其有用。现有的研究大多采用了一种能够有效利用 n-gram 字符表面模式的卷积神经网络 ( CNN )。更具体地说,设 C 为字符的词汇表,每个单词类型 x 都可以表示为字符序列 。我们首先将 C 中的每个字符映射到一个 维度的向量,所以单词 x 可以表示成 ${\rm c}{|x|}$。
接下来,我们对宽度为 的滤波器应用卷积层,表示 ${\rm c}{i:i+j}{\rm c}{i+1},\dots,{\rm c}{i+j}$ 的级联。因此,对于 i = 1,…,|x| - w + 1,我们可以应用这个滤波器 w,然后我们添加一个偏置 b,应用非线性 tanh 如下:
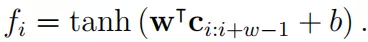
最后,我们可以在 上应用一个最大池操作, ,得到一个标量特征:
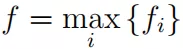
这个特性本质上选择一个字符 n-gram,其中 n-gram 对应过滤器的宽度 w。我们可以重复上面的过程,方法是重复个不同的过滤器 。因此,我们可以获得每个单词类型 的基于字符的单词表示。所有的字符嵌入,过滤器权重 {w} 和偏差 {b} 都是在训练中学习的。更多细节可以在 Kim ( 2014 ) 中找到。实际上,字符嵌入 的维数通常取一个小值 ( 例如 20 ),宽度 w 通常取 3 - 5,而 100 是的一个典型值。
Contextualized word embeddings
另一个重要的概念是上下文的单词嵌入。与传统的单词嵌入 ( 每个单词类型都映射到一个向量 ) 不同,上下文化的单词嵌入将每个单词作为整个输入语句的函数分配给一个向量。这些词的嵌入可以更好地模拟单词使用的复杂特性 ( 例如,语法和语义 ),以及这些用法如何在不同的语言环境中变化 ( 例如,一词多义 )。
ELMO 在 Peters et al. ( 2018 ) 中详细介绍了一个具体的实现:它们的上下文单词嵌入是一个深层双向语言模型的内部状态的学习函数,该模型是在一个大型文本语料库上预先训练的。基本上,给定一个单词序列 它们运行 l 层正向 LSTM,序列概率模型为:

这些上下文的单词嵌入通常与传统的单词类型嵌入和字符嵌入一起使用。事实证明,这种在非常大的文本语料库上 ( 例如 1B 词库标记 ( Chelba et al., 2014 ) ) 预训练的上下文词嵌入是非常有效的。Peters et al. ( 2018 ) 证明,在现有的竞争模型中添加 ELMo embeddings ( L = 2 个 biLSTM 图层,包含 4096 个单元和 512 个维度投影 ) 可以直接将 F1 成绩从 81.1 提高到 85.8,绝对提高 4.7 分。
在 ELMO 之前,McCann 等人 ( 2017 ) 提出了 COVE,该方法在神经机器翻译框架中学习上下文化的单词嵌入,得到的编码器可以作为单词嵌入的补充。他们也展示了 4.3 分的绝对进步。
最近,Radford et al. ( 2018 ) 和 Devlin et al. ( 2018 ) 发现这些上下文词潜入不仅可以用在一个特定任务的神经结构中作为一个词表示的特征 ( 阅读理解模式的上下文 ),而且我们可以调整深层语言模型直接并进行最小修改来执行下游任务。这在我写这篇论文的时候确实是一个非常惊人的结果,我们将在第 4.4.2 节对此进行更多的讨论,在未来还有很多问题需要回答。此外,Devlin et al. ( 2018 ) 提出了一种训练双向语言模型的聪明方法:他们在输入层随机屏蔽一些单词,而不是总是往一个方向叠加 LSTMs 并预测下一个单词,将双向层叠加,并在顶层预测这些被屏蔽的单词。他们发现这种训练策略在经验上非常有用。
3.4.2 Attention Mechanisms
针对神经阅读理解模型,已经提出了许多注意力机制的变种,它们的目的是在不同层次、不同粒度或分层的方式上捕捉问题和文章之间的语义相似性。在 ( Huang et al., 2018b ) 处可以找到这个方向的典型复合例子。据我们所知,目前还没有一个结论说存在一个变种是十分突出的。我们的 STANFORD ATTENTIVE READER 采用了最简单的注意力形式 ( 图 3.4 是不同层的 attention 的概览图 )。除此以外,我们认为有两个想法可以在通常意义上进一步提升这些系统的性能。
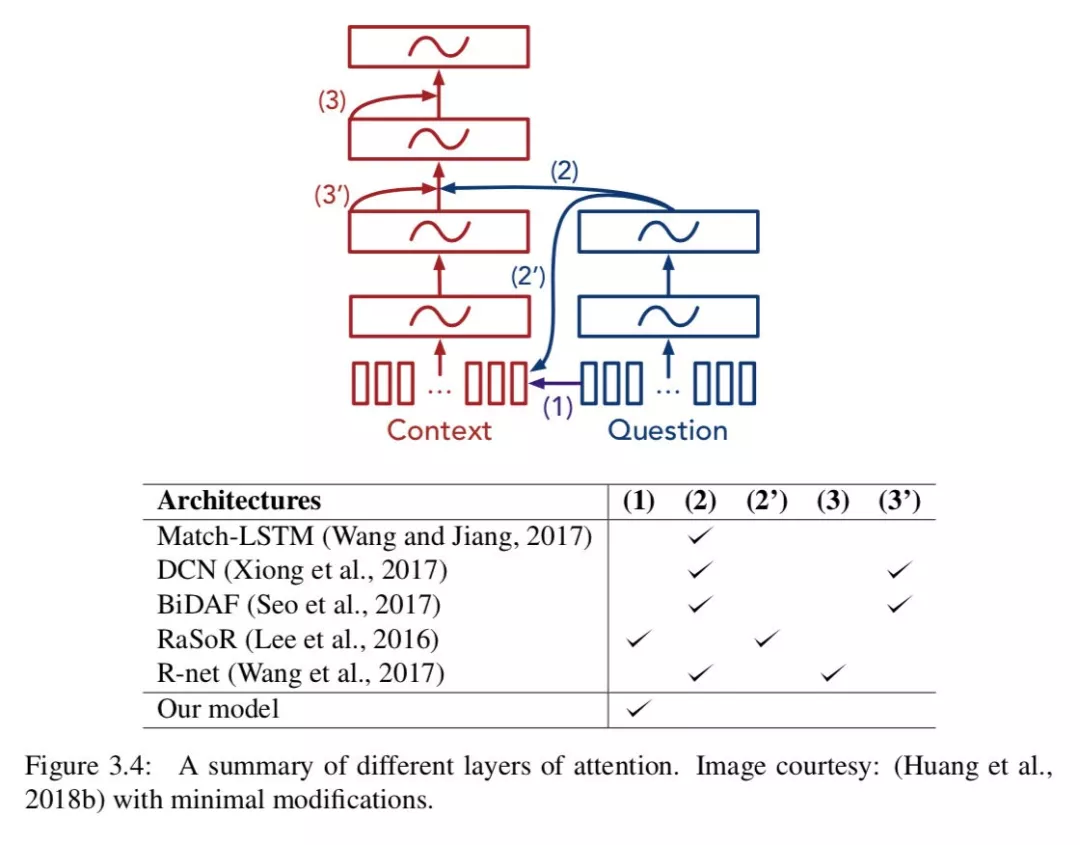
Bidirectional attention
Seo 等 ( 2017 ) 首次提出了双向注意力机制的概念。除了我们已经拥有的 ( 特性 ),关键的区别是他们有问题到段落的注意力,这表示了着哪些段落单词与每个问题单词最相似。在实践中,这可以实现为:对于问题中的每个单词,我们可以计算出所有短文单词的注意图,类似于我们在方程 3.22 和 3.23 中所做的,但方向相反:
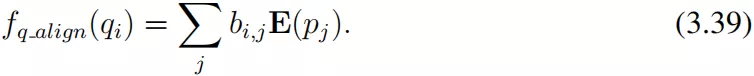
之后,我们可以简单的将 输入到问题编码器的输入层。
Seo 等人 ( 2017 ) 的注意机制比较复杂,但我们认为是相似的。我们还认为,在这个方向上的注意力功能没有那么有用,Seo 等人 ( 2017 ) 也证明了这一点。这是因为问题通常很短 ( 平均 10- 20 个单词 ),使用一个 LSTM 进行问题编码 ( 无需额外的注意力 ) 通常就足够了。
Self-attention over passage
第二种观点是对段落词的自我关注,最早出现在 Wang 等人 ( 2017 ) 的文章中。直观的感觉是,文章中的单词可以与其他文章中的单词对齐,希望它可以解决相互参照的问题,并从文章中的多个地方收集 ( 同一实体的 ) 信息。
Wang 等 ( 2017 ) 首先计算了这篇文章的隐藏向量:${\rm p}_1,{\rm p}{l_p}{\rm p}_1,{\rm p}{l_p}$ 施加一个注意函数:
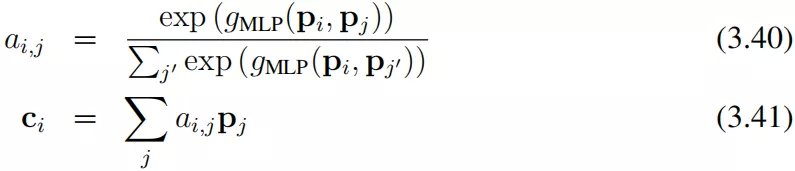
之后 和 被连接起来,并且输入到另一个 bilstm 中:
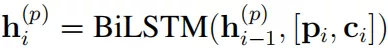
并且可以被用作最终的篇章表示。
3.4.3 Alternative to LSTMs
目前我们讨论的所有模型都是基于递归神经网络 ( RNNs ) 的。众所周知,增加神经网络的深度可以提高模型的容量,并带来性能的提高 ( He et al., 2016 )。我们之前还讨论了 3 或 4 层的深层 BiLSTM,这通常比单层 BiLSTM 性能更好 ( 第 3.3.2 节 )。然而,随着 LSTM 模型深度的进一步提高,我们面临着两个挑战:① 由于梯度消失问题,优化变得更加困难;② 可扩展性成为一个问题,因为随着层数的增加,训练/推理时间呈线性增长。众所周知,由于 LSTMs 的顺序性,它很难并行化,因此伸缩性 ( scale ) 很差。
一方面,有一些工作尝试在层与层之间添加高速连接 ( Srivastava et al., 2015 ) 或残差连接 ( He et al., 2016 ),从而简化优化过程,能够训练更多层的 LSTMs。另一方面,人们开始寻找 LSTMs 的替代品,在消除重复结构的同时,性能仍然类似甚至更好。
这方面最值得注意的工作是谷歌研究人员提出的 TRANSFORMER 模型 ( Vaswani et al., 2017 )。TRANSFORMER 只构建在 word 嵌入和简单的位置编码之上,这些位置编码具有堆叠的自我关注层和位置明智的完全连接层。通过残差连接,该模型能够在多个层次上快速训练。它首先在 L = 6 层的机器翻译任务 ( 每层由一个自我注意和一个完全连接的前馈网络组成 ) 上表现出优越的性能,然后被 Yu 等人 ( 2018 ) 改编用于阅读理解。
该模型名为 QANET ( Yu et al., 2018 ),它堆叠了多个卷积层,以自我关注和完全连接层为中心,作为问题和段落编码的构建块,以及在最终预测之前堆叠的几个层。该模型显示了当时最先进的性能 ( 表 3.4 ),同时显示了显著的加速。
Lei 等人 ( 2018 ) 的另一项研究工作提出了一种轻量级的递归单元,称为简单递归单元 ( SIMPLE unit,SRU ),它简化了 LSTM 公式,同时支持 cuda 级优化以实现高并行化。研究结果表明,简化递归模型通过层堆积保持了较强的建模能力。他们还证明了用 SRU 单元替换我们模型中的 LSTMs 可以提高 F1 成绩 2 分,同时训练和推理速度更快。
3.4.4 Others
训练目标:通过改进训练目标也有可能取得进一步进展。对于完形填空或多项选择题,通常直接使用交叉熵或最大边际损失。然而,对于跨度预测问题,Xiong 等 ( 2018 ) 认为预测答案两个端点的交叉熵损失与最终的评价指标存在差异,这涉及到 gold answer 与 ground truth 之间的单词重叠。例如:
范围“Worriors”也是一个正确的答案,但是从跨熵训练的角度来看,它并不比跨度“历史”更好。熊等人 ( 2018 ) 提出了一种混合训练目标,将位置交叉熵损失和训练后的单词重叠量与强化学习相结合。基本上,他们使用经过交叉 entroy loss 训练的 和 来采样答案的开始和结束位置,然后使用 F1 分数作为奖励函数。
对于阅读理解问题的自由形式回答,近年来在训练更好的 SEQ2SEQ 模型方面取得了许多进展,尤其是在神经 ma- chine 翻译环境下,如句子水平训练 ( Ranzato et al., 2016 ) 和最小风险训练 ( Shen et al., 2016 )。然而,我们在阅读理解问题上还没有看到很多这样的应用。
数据增加。数据增强是一种非常成功的 image 识别方法,但在 NLP 问题中研究较少。Yu 等 ( 2018 ) 提出了一种为阅读理解模型创建更多训练数据的简单技术。技术称为 backtranslation——基本上就是他们利用两个最先进的神经机器翻译模型:一个模型从英语到法语和其他模型从法语,英语,和解释文章中的每一句话贯穿两个模型 ( 如果需要一些修改答案 )。在 F1 值上,他们通过在 SQUAD 上这样做获得了 2 分。Devlin 等 ( 2018 ) 也发现,SQUAD 与 TRIVIAQA 联合训练 ( Joshi 等,2017 ) 可以适度提高 SQUAD 上的性能。译者注,用这种方式,理论上可以共享大多数语言的数据集
3.4.5 Summary
到目前为止,我们已经讨论了不同方面的最新进展,总而言之,这些进展有助于当前阅读理解基准 ( 尤其是 SQUAD ) 的最新进展。哪些组件比其他组件更重要?我们需要把这些都加起来吗?这些最新的进展是否可以推广到其他阅读理解任务?它们如何与不同的语言理解能力相关联?我们认为这些问题中的大多数还没有一个明确的答案,仍然需要大量的调查。
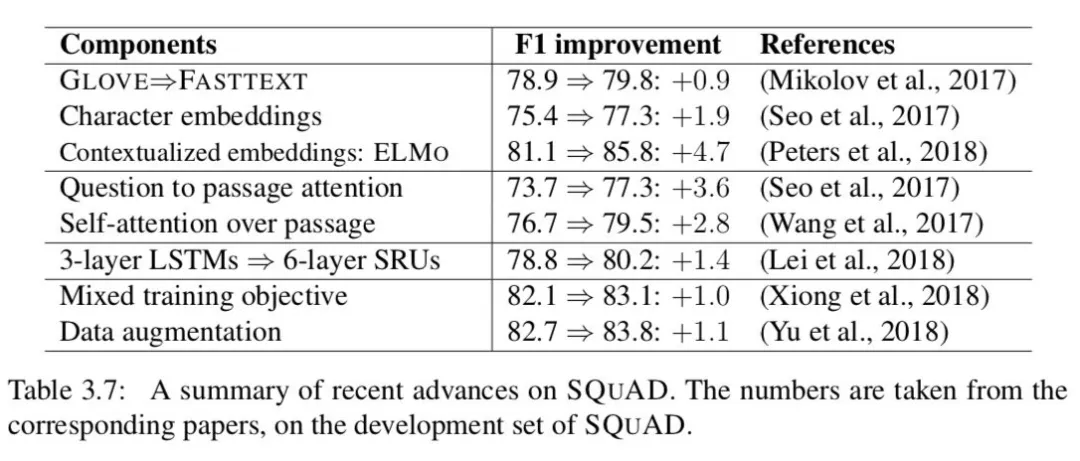
我们在表 3.7 中编制了对 SQUAD 不同组件的改进。我们想提醒读者,这些数字并不是直接可比较的,因为它们是建立在不同的模型架构和不同的实现之上的。我们希望这个表格至少反映了一些关于这些组件在 SQUAD 数据集中重要性的想法。正如所看到的,所有这些组件或多或少都会对最终的性能做出贡献。最重要的创新可能是使用上下文的单词嵌入 ( 例如 ELMO ),而注意力函数的制定也很重要。研究这些进步是否可以推广到未来的其他阅读理解任务,将是非常重要的。
4. The Future of Reading Comprehension
在前一章中,我们描述了神经阅读理解模型如何在当前的阅读理解基准测试中取得成功,以及它们的关键见解。尽管其发展迅速,但要达到真正的人的阅读理解水平还有很长的路要走。在这一章,我们将讨论未来的工作和开放的问题。
我们首先在第 4.1 节中检查了现有模型的错误情况,并得出结论,尽管它们的平均准确率很高,但在“简单”或“琐碎”的情况下,它们仍然会失败。
正如我们前面所讨论的,最近阅读理解的成功归功于大规模数据集的创建和神经阅读理解模型的开发。在未来,我们相信这两个组成部分仍然同样重要。我们将在 4.2 节和 4.3 节分别讨论数据集和模型的未来工作。现有的数据集和模型中还缺少什么?我们该怎么做呢?
最后,我们在第 4.4 节中回顾了这一领域的几个重要研究问题。
4.1 Is SQuAD Solved Yet?
尽管我们已经在 SQUAD 数据机上达到了超人的性能,这能说明我们的阅读理解模型已经能够解决所有的 SQUAD 例子或者其他同等难度的例子么?
图 4.1 展示了我们在 3.2 节中描述的 STANFORD ATTENTIVE READER 模型的一些失败案例。正如我们所看到的,该模型完美地预测了所有这些例子的答案类型:它预测了问题的一个数字,即……吗?人口是多少……吗?哪支球队赢得了超级碗 50 强?然而,该模型无法理解文本中表达的微妙之处,也无法区分候选答案。细节如下:
① The number 2,400 modifies professors, lecturers, and instructors while 7,200 modifies undergraduates. However, the system failed to identify that and we believe that linguistic structures ( e.g., syntactic parsing ) can help resolve this case.
② Both teams Denver Broncos and Carolina Panthers are modified by the word champion, but the system failed to infer that “X defeated Y” so “X won”.
③ The system predicted 100,000 probably because it is closer to the word population. However, to answer the question correctly, the system has to identify that 3.7 million is the population of Los Angles, and 1.3 million is the population of San Diego and compare the two numbers and infer that 1.3 million is the answer because it is second largest. This is a difficult example and probably beyond the scope of all the existing systems.
我们还仔细研究了迄今为止最佳阵容模型的预测,7 个 BERT 模型的集合 ( Devlin et al., 2018 )。如图 4.2 所示,我们可以看到这个强大的模型仍然会犯一些人类几乎不会犯的简单错误。可以推测,这些模型一直在进行非常复杂的文本匹配,但它们仍然难以理解实体和文本中所表达的事件之间的内在结构。
最后,Jia 和 Liang ( 2017 ) 发现,如果我们在文章末尾添加一个让人分心的句子 ( 见图 4.3 中的例子 ),目前阅读理解系统的平均性能将会从 75.4%大幅下降到 36.4%。这些让人分心的时态与问题有词汇重叠,但实际上并不与正确答案相矛盾,也不会误导人类的理解。如果允许分散注意力的句子添加不符合语法的单词序列,那么效果会更糟。这些结果表明:
综上所述,我们认为,目前的模型虽然在 SQUAD 数据集上已经获得了很高的精度,但目前的模型只关注文本的表层信息,在理解的 ( 稍微 ) 更深层次上仍然存在简单的错误。另一方面,高准确度也表明,大多数球队的例子是相当容易的,需要很少的理解。有一些困难的例子需要在 SQUAD 中进行复杂的推理 ( 例如,图 4.1 中的(c) ),但是由于它们的稀缺性,它们的准确性并没有真正反映在平均度量中。此外,高精度只有在训练和发展来自同一分布时才成立,当它们不同时仍然是一个严重的问题。在接下来的两部分中,我们将讨论创建更具挑战性的数据集和构建更有效模型的可能性。
4.2 Future Work:Datasets
我们主要关注的是 CNN/DAILY MAIL 和 SQUAD,并证明了以下两点:
1、神经模型在这两种数据集上都能够实现比人类更好的效果或者达到目前的上限;
2、虽然这些数据集非常有用,但大多数例子都很简单,还不需要太多推理。
这些数据集中还缺少哪些需要的属性?接下来我们应该处理什么样的数据集?如何收集更好的数据集?
我们认为像 SQUAD 这样的数据集主要有以下的局限性:
为了解决这些局限性,最近出现了一些新的数据集。他们和 SQUAD 有类似的地方,但以不同的方式构建。表 4.1 给出了一些代表性数据集的概述。正如我们所看到的,这些数据集具有相似的数量级 ( 范围从 33k 到 529k 的训练示例 ),并且在最先进的性能和人类性能之间仍然存在差距 ( 尽管有些差距比其他差距更大 )。下面,我们将详细描述这些数据集,并讨论它们如何解决上述限制及其优缺点:
TriviaQA ( Joshi 等,2017 )。这个数据集的关键思想是在构建相应的段落之前收集问题/答案对。更具体地说,他们从琐事和测验联盟网站上收集了 95k 对问答对,并收集了包含答案的虚拟证据,这些答案要么来自网络搜索结果,要么来自与问题中提到的实体对应的维基百科页面。结果,他们总共收集了 650k ( 短文,问题,答案 ) 的三倍。该范式有效地解决了问题依赖于文章的问题,并且更容易廉价地构建大型数据集。值得注意的是,该数据集中使用的段落大多是长文档 ( 平均文档长度为 2895 个单词,是 SQUAD 的 20 倍 ),并且对现有模型的可拓展性也提出了挑战。然而,它有一个类似于 CNN/DAILY MAIL 数据集的问题——由于数据集是启发式地整理的,因此不能保证文章真正提供了问题的答案,这影响了训练数据的质量。
RACE ( Lai 等,2017 )。人的标准化测试是评价汉语阅读理解能力的一种有效方法。RACE 是一个多选题数据集,收集了 12-18 岁中国中学生和高中生的英语考试数据。所有的问题和答案选项都是由专家创建的。因此,该数据集比大多数现有数据集更加困难,据估计,26%的问题需要多句推理。最先进的性能只是 59% ( 每个问题有 4 个候选答案 )。
NarrativeQA ( Kocˇisky et al., 2018 )。这是一个具有挑战性的数据集,它要求工作人员根据维基百科上一本书或一部电影的情节摘要提出问题。答案是自由形式的人类生成的文本,特别是,在交互界面上,标注者被鼓励使用自己的语言,并且不允许复制。情节总结通常比新闻文章或维基百科的段落包含更多的人物和事件,而且更复杂。数据集包含两个设置:一个是基于摘要回答问题 ( 平均 659 个令牌 ),这更接近于 SQUAD;另一个是基于完整的书籍或电影脚本回答问题 ( 平均 62528 个 token )。第二个设置尤其困难,因为它要求 IR 组件在长文档中定位相关信息。这个数据集的一个问题是,由于其自由形式的答案形式,人类的一致性很低,因此很难评估。
SQUAD2.0 ( Rajpurkar 等,2018 )。SQUAD2.0 提出在原有 SQUAD 数据集中增加 53,775 个反面例子。这些问题不能从文章中得到答案,但是看起来和积极的问题很相似 ( 相关的,文章中有一个可信的答案 )。为好地处理数据集,系统不仅需要回答问题,还需要确定段落中什么时候不支持回答,并避免回答。这是实际应用中的一个重要方面,但在以前的数据集中被忽略了。
HotpotQA ( Yang et al., 2018 )。该数据集旨在构造需要多个支持文档才能回答的问题。为了达到这个目的,众包工作者被要求根据维基百科的两个相关段落提问 ( 一篇文章的第一段到另一篇文章有一个超链接 )。它还提供了一种新的仿真陈述比较问题,系统需要在一些共享属性上比较两个实体。该数据集由两个评估设置组成——一个称为干扰设置,其中每个问题都提供 10 个段落,包括用于构建问题的两个段落和从 Wikipedia 检索到的 8 个干扰段落;第二个设置是使用完整的 Wikipedia 来回答这个问题。
与 SQUAD 相比,这些数据集要么需要更复杂的跨时态或文档推理,要么需要处理更长的文档,要么需要生成自由形式的答案而不是提取单个跨度,要么需要预测文章中何时没有答案。它们带来了新的挑战,许多挑战仍然超出了现有模型的范围。我们相信这些数据集将在未来进一步激发一系列的建模创新。当我们的模型达到下一个性能级别后,我们将需要开始构建更加困难的数据集来解决。
4.3 Future Work:Models
接下来,我们转向未来工作模型的研究方向。我们首先描述了阅读理解模型的期望。现有的大部分工作只注重准确性,给定一个标准 train/dev/test 数据集分割,主要目标是得到最好的测试准确性分数。但是,我们认为还有其他重要的方面被忽视了,我们需要工作在未来,包括速度和可扩展性、鲁棒性和可解释性。最后,我们讨论了在目前的模型中还缺少哪些重要的元素,以解决更多的阅读理解难题。
4.3.1 Desiderata
除了准确性 ( 在标准数据集上获得更好的性能分数 ),以下的需求对未来的工作也非常重要:
Speed and Scalability。如何构建更快的模型 ( 用于训练和推理 ),以及如何扩展到更长的文档,这些都是需要研究的重要方向。建立更快的训练模型可以降低实验的周转时间,还可以使我们在更大的数据集上进行训练。在实际应用中部署模型时,为推理构建更快的模型非常有用。此外,用 RNN 编码一个很长的文档 ( 例如 TRIVIAQA ) 甚至是一本书 ( 例如 NARRATIVEQA ) 都是不现实的,这仍然是一个严峻的挑战。例如,TRIVIAQA 的平均文档长度为 2,895 个 token,为了可伸缩性,作者将文档缩减为前 800 个 token。NARRATIVEQA 的平均文档长度为 62,528 个 token,作者必须首先使用 IR 系统从故事中检索少量相关段落。
现有的对这些问题的解决方法如下:
Robustness。我们在 4.1 节中讨论了现有的模型对于对抗性例子来说是非常脆弱的,这将成为我们在现实世界中部署这些模型时所面临的一个严重问题。此外,目前的大多数工作都遵循标准范例:对一个数据集的分割进行培训和评估。众所周知,如果我们在一个数据集上训练我们的模型,并在另一个数据集上进行评估,由于它们的文本来源和构造方法不同,性能将显著下降。对于今后的工作,我们需要考虑:
Interpretability。最后一个重要的方面是可解释性,在目前的系统中,可解释性一直是被忽略的。我们未来的系统不仅应该能够提供最终的答案,而且还应该提供预测背后的理由,这样用户就可以决定是否可以信任输出并利用它们。神经网络尤其臭名昭著的一个事实是,端到端训练范式使这些模型像一个黑匣子,很难解释它们的预测。如果我们想将这些系统应用到医疗或法律领域,这一点尤其重要。
可解释性可以有不同的定义。在我们的背景下,我们认为有几种方法可以解决这个问题:
4.3.2 Structures and Modules
在这个章节,我们会讨论如果我们想要解决更多困难的阅读理解问题的话,目前模型中缺失的元素。
首先,当前的模型要么建立在序列模型的基础上,要么对称地处理所有单词对 ( 例如 TRANSFORMER ),并且忽略了语言的固有结构。一方面,这迫使我们的模型从头开始学习所有相关的语言信息,这使得我们的模型的学习更加困难。另一方面,NLP 社区多年来投入了大量精力研究语言表示任务 ( 例如语法解析、指代 ) 并且构建许多语言资源和工具。语言按照单词序列上的层次结构和嵌套结构对意义进行编码。在我们的阅读理解模型中更明确地编码语言结构是否仍然有用?
Figure 4.4 表明了 CORENLP 在 SQUAD 中输出的几个例子。我们相信在合格结构信息会是有意义的:
因此,我们认为这些语言知识/结构仍然是对现有模型的有益补充。剩下的我们需要回答的问题是:① 将这些结构合并到序列模型中的最佳方法是什么?② 我们是想将结构建模为潜在变量,还是依赖现成的语言工具?对于后一种情况,当前的工具是否足够好,使模型能够获得更多的好处 ( 而不是遭受噪声 )?我们能进一步提高这些代表任务的性能吗?
我们认为,大多数现有模型仍然缺少的另一个方面是模块 ( modules )。阅读理解的任务本质上是非常复杂的,不同类型的例子需要不同类型的推理能力。如果我们想通过一个巨大的神经网络来学习所有的东西,这仍然是一个巨大的挑战 ( 这让人想起为什么提出注意力机制,因为我们不想把一个句子或一段话的意思压缩成一个向量! ) 我们相信,如果我们想达到更深层次的阅读理解,我们未来的模型将更加结构化,模块化,解决一个综合任务可以分解成许多子问题,我们可以单独解决每一个规模较小的子问题 ( 例如,每个推理类型 ) 并组合它们。
modules 的思想以前已经在神经模块网络 ( NMN ) 中实现过 ( Andreas et al., 2016 )。它们首先对问题进行依赖解析,然后根据解析结构将回答问题分解为几个“模块”。他们在视觉问答 ( VQA ) 任务中使用的一个例子是:一个问题“鸟是什么颜色的?”可以分解为两个模块。一个模块用于检测给定图像中的鸟,另一个模块用于检测发现区域(鸟)的颜色。我们相信这种方法有望回答诸如加州第二大城市的人口是多少之类的问题。( 图 4.1 © )。然而,迄今为止,NMN 只在视觉问答或小知识库问题上进行了研究,由于语言变异和问题类型的灵活性,将其应用于阅读理解问题可能更具挑战性。
4.4 Research Questions
在最后一个小节中,我们讨论一些这个领域的中心研究问题,这些依然是 open 的,并且等待在未来被回答。
4.4.1 How to Measure Progress?
第一个问题是:How can we measure the progress of this field?
评估指标无疑是衡量我们阅读理解水平进步的清晰指标。这是否意味着我们在阅读理解上取得了真正的进步?我们如何判断一个基准上的一些进展是否可以推广到其他基准上?如果模型 A 在一个数据集上比模型 B 工作得更好,而模型 B 在另一个数据集上工作得更好呢?如何判断这些计算机系统与真正的人类阅读理解水平之间的差距?
一方面,我们认为参加人的标准化考试可以作为评价机器阅读理解系统性能的一个好策略。这些问题通常是精心策划和设计的,以测试人类阅读理解能力的不同水平。在构建自然语言理解系统时,使计算机系统与人类测量系统保持一致是一种正确的方法。
另一方面,我们认为在未来,我们需要将许多阅读理解数据集集成为一个测试套件进行评估,而不是只在一个数据集上进行测试。这将帮助我们更好地区分什么是阅读理解的真正进步,什么可能只是对一个特定数据集的过度拟合。
更重要的是,我们需要更好地理解我们现有的数据集:描述它们的质量和回答问题所需的技能。这将是构建更具挑战性的数据集和分析模型行为的重要一步。Sugawara 等人 ( 2017 ) 在分析 Chen et al. ( 2016 ) 的 CNN/DAILY MAIL 例子的基础上,尝试将阅读理解技能分为两个不同的部分:前提技能和可读性。前提技能测量不同类型的推理和回答问题所需的知识,并定义了 13 个技能:对象跟踪、数学推理、指代解析、逻辑推理、类比、因果关系、时空关系、省略、搭桥、精化、元知识、示意性从句关系和标点符号。可读性度量“文本处理的易用性”,并使用了广泛的语言特性/人类可读性度量。作者的结论是,这两个集合是弱相关的,从易于阅读的上下文中设计难的问题是可能的。这些研究表明,我们可以分别基于这些属性构建数据集和开发模型。
此外,Sugawara 等人 ( 2018 ) 设计了一些简单的过滤启发式算法,并将许多现有数据集中的例子划分为一个硬子集和一个简单子集,这是基于:① 是否可以只用头几个单词来回答问题;② 答案是否包含在文章中最相似的句子中。他们发现,与整个数据集相比,硬子集的基线性能显著下降。此外,Kaushik 和 Lipton ( 2018 ) 使用仅传递或仅提问的信息分析了现有模型的性能,发现这些模型有时可以工作得惊人地好,因此在一些现有数据集中存在注释构件。
综上所述,我们认为,如果我们想在今后的阅读理解中取得平稳的进步,我们必须首先回答这些关于例题难度的基本问题。了解数据集需要什么,我们当前的系统能做什么和不能做什么,这将帮助我们识别我们面临的挑战,并衡量进展。
4.4.2 Representations vs. Architecture:Which is More Important?
第二个重要的问题是理解表示和架构在对阅读理解模型性能影响上的角色。自 SQUAD 建立以来,最近出现了一种增加神经结构复杂性的趋势。特别是,人们提出了越来越复杂的注意力机制来捕捉文章和问题之间的相似性 ( 第 3.4.2 节 )。然而,最近的研究 ( Radford et al., 2018;Devlin et al ., 2018 ) 提出,如果我们能在大型文本语料库上预训练深度语言模型,一个拼接问题和篇章的简单模型,并且不需要在这两者 ( 问题和篇章 ) 之间建立任何直接互动,都可以在 SQUAD 和 RACE 这辆的阅读理解数据集上表现十分良好。( 见表 3.4 和表 4.1 )。
如图 4.5 所示,第一个类的模型 ( 左 ) 基于顶层的在未标记文本上预训练的词嵌入 ( 每个单词类型有一个向量表示 ) 构建,而所有其余的参数 ( 包括所有的权重来计算各种注意力功能 ) 需要从有限的训练数据学习。第二类模型 ( 右 ) 使模型体系结构非常简单,它只将问题和篇章建模为单个序列。对整个模型进行预训练,保留所有参数。只增加了几个新的参数 ( 如预测 SQUAD 起始和结束位置的参数 ),其他参数将在阅读理解任务的训练集上进行微调。
我们认为这两类模型表明了两个极端。一方面,它确实展示了非监督表示的不可思议的力量。由于我们有一个从大量文本中预先训练的强大的语言模型,该模型已经编码了大量关于语言的属性,而一个连接篇章和问题的简单模型足以学习两者之间的依赖关系。另一方面,当只给出单词嵌入时,似乎对文章和问题之间的交互进行建模 ( 或者为模型提供更多的先验知识 ) 会有所帮助。在未来,我们怀疑我们需要将两者结合起来,像 BERT 这样的模型太粗糙,无法处理需要复杂推理的例子。
4.4.3 How Many Training Examples Are Needed?
第三个问题是实际需要多少个训练实例?我们已经多次讨论过神经阅读理解的成功是由大规模的数据集驱动的。我们一直在积极研究的所有数据集都包含至少 50,000 个示例。我们能否始终保持数据的丰富性,并进一步提高系统的性能?是否有可能训练一个只有几百个注释例子的神经阅读理解模型?
我们认为目前还没有一个明确的答案。一方面,有明确的证据表明,拥有更多的数据会有所帮助。Bajgar et al. ( 2016 ) 证明,使用相同的模型,膨胀通过古登堡计划 ( project Gutenberg ) 从书籍中构建的完形填空 ( cloze-style ) 的训练数据可以在 CHILDREN BOOK TEST ( CBT ) 数据集合 ( Hill et al., 2016 )。我们之前讨论过使用数据增强技术 ( Yu et al.2018 ) 或使用 TRIVIAQA 增强训练数据可以帮助提高在 SQUAD 上的性能 ( # training examples = 87,599 )。
另一方面,预训练 ( 语言 ) 模型 ( Radford 等,2018;Devlin et al., 2018 ) 可以帮助我们减少对大规模数据集的依赖。在这些模型中,大部分参数已经在大量的未标记数据上进行了预训练,并且只会在训练过程中进行微调。
在未来,我们应该鼓励更多在非监督学习和迁移学习上的研究。利用非标注数据 ( 例如 text ) 或者别的廉价的资源或者监督 ( 例如 CNN/DAILY MAIL 这样的数据集 ) 会将我们从收集昂贵的标注数据中解放出来。我们也应该寻找更好和更加便宜的方式来收集监督数据。
译者 注
关于这篇论文的中文翻译在这里:
同时我强烈推荐 phD Grind:
这篇文章,也是讲述了斯坦福大学的博士生的学习心路历程。推荐理由引用其中的一段话:有些人可以通过博士的学习生涯学习到一种思维方式,有的人没有通过博士的学习生涯,但是通过别的方式同样达到了这样的高度。
NLP 领域逐渐进入人们的视野,从 word2vec 到 BERT 再到后来提出的一些模型,都是在 dig 预训练这个环节。
在未来,有时间的情况话,我会对文中提到的一些有代表性的论文进行解读。部分论文会进行复现。
才疏学浅,有不足之处,还望指出。谢谢。可以直接提出 issue 或者通过邮件联系:4ljy@163.com。
本文翻译已经咨询过原作者。
本文仅供学习交流所用,一切权利由原作者及单位保留,译者不承担法律责任。
论文原文地址:
~danqic/papers/thesis.pdf
陈丹琦博士个人主页:
~danqic/
译者介绍 :
Duke Lee。前美团点评 NLP 算法工程师。曾负责自然语言处理平台。
本文来自>
原文链接 :