从接触 TiDB 以来,就看到过 TiDB 官方文档上的提示,gc_life_time 设置过大,会因为历史版本过多,影响查询效率,但是为什么 SQL 非要去扫描历史版本呢?下面列举一些知识点一步一步来解析这个问题
1. TiDB key 的编码方式
TiDB 会对每个表分配一个全局唯一的 table_id,每一个索引都会分配一个表内唯一的 index_id,每一行分配一个 row_id(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 row_id,如果没有,那么 TiDB 会自动生成一个隐式主键_tidb_rowid)
数据编码方式:
t{table_id}_r{row_id}-->[col1,col2,col3,...]
索引编码方式:
unique index
t{table_id}_i{index_id}_{index_column_value}-->[row_id]
非 unique index
t{table_id}_i{index_id}_{index_column_value}_{row_id}-->null
举个栗子:
CREATE TABLE `test_table` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',`column1` varchar(10) DEFAULT NULL,`column2` varchar(10) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_column1` (`column1`)那么主键编码可以抽象为
t10_r1-->[1,"a","b"]
t10_r2-->[2,"c","d"]
索引
idx_column1
编码可以抽象为
t10_i1_a_1-->null
t10_i1_b_2-->null
2. MVCC 多版本信息是如何保存的?
TiDB 使用基于 Percolator 的事务模型,将一行数据抽象为 default、write 和 lock 3 个 CF(column family)存储,其中:
一个读取操作的过程如下:
TiDB 将一行记录的多个版本按照从新到老的顺序排列,这样方便我们获得满足查询条件的最新记录,TiKV 默认存储引擎是 RocksDB,RocksDB 一个 seek 操作要比 next 操作昂贵很多,如下这个例子
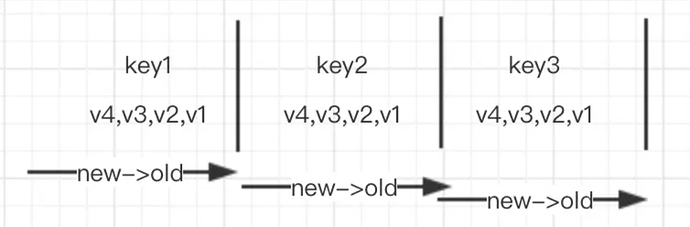
假设 key1,key2,key3 都有多次更新,生成的 mvcc 版本从老到新分别为 key1_v1,key1_v2,key1_v3,key1_v4…
几个相邻 key 的存放方式抽象为下图:
Rocksdb 没办法精确去定位每一个 key,如果扫描每一个 key 都走 seek 接口,这样代价太大。所以如图,假设一个范围查询 seek 到第一个 key,key1 之后,就开始调用 next 函数获取后面的 key2、key3 值,这样需要遍历 key1 甚至 key2 的所有历史版本。如此,就能解释为什么过多的历史版本会让查询效率急剧下降了。
我们日常工作经常碰见的几个问题:
一、SQL 执行时间不稳定 慢日志中会发现这些 SQL 语句的 total keys 比 process keys 大很多,这就是典型的历史版本过多,导致扫描了大量历史数据。解决方法
while True:delete table where {$condition} limit nif affectrows==0:这个场景的现象是 delete 语句会越来越慢。因为扫描范围{$condition}是固定不变的,delete 删除语句在 TiDB 处理方式是标记删除,删除本身实际上也是插入一条 kv 记录,只不过 value 变成了 delete,最后通过逻辑 GC 和 compaction 来删除真实数据。所以,循环执行 delete 语句,每次删除 n 条记录,下一次 delete 语句要扫描的 key 就会+n,执行时间越来越长(大家可以去做个实验,观察慢日志文件,同样的 delete 语句 total keys 会不断增加)。
首先,我们知道 TiDB 对事务大小是有限制的
由于 TiDB 的事务限制和 TiDB mvcc 的实现原理,想要删除 &归档一个特定范围的数据,目前没有太好的方法。整理一些个人心得供大家参考:
第一种方式:
尽量缩小范围删除的粒度,比如提前按分钟将数据分段,打开 tidb_batch_delete,提高并发去删除。注意使用开闭区间,分段之间不要出现冲突,TiDB 解决事务冲突的代价比较大。
set @@session.tidb_batch_delete=1;delete from table where create_time > '$start_step' and create_time <= '$end_step';如果分段内的数据超出事务大小限制,TiDB 会自动将 delete 操作拆分成多个 batch。个人亲测,这种方式删除数据的速度还是比较快的。
第二种方式:
作者介绍 :
吕磊,美团点评 DBA, TiDB User Group (TUG) 大使。
原文链接 :