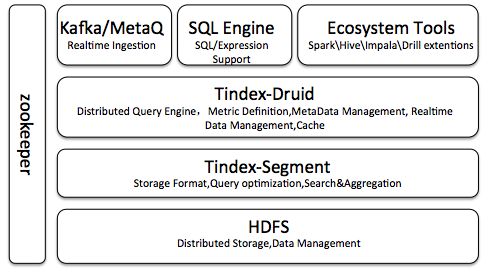
编者按 :本文节选自华章科技大数据技术丛书 《Apache Kylin 权威指南(第 2 版)》一书中的部分章节。
Top_N 度量优化
在生活中我们总能看到“世界 500 强公司” “销量最好的十款汽车”等标题的新闻报道,Top_N 分析是数据分析场景中常见的需求。在大数据时代,由于明细数据集越来越大,这种需求越来越明显。在没有预计算的情况下,得到一个分布式大数据集的 Top_N 结果需要很长时间,导致点对点查询的效率很低。
Kylin v1.5 以后的版本中引入了 Top_N 度量,意在进行 Cube 构建的时候预计算好需要的 Top_N,在查询阶段就可以迅速地获取并返回 Top_N 记录。这样,查询性能就远远高于没有 Top_N 预计算结果的 Cube,方便分析师对这类数据进行查询。
让我们用 Kylin 中通过 sample.sh 生成的项目“learn_kylin” 对 Top_N 进行说明。我们将重点使用其中的事实表“kylin_sales”。
这张样例表 “default.kylin_sales” 模拟了在线集市的交易数据,内含多个维度和度量列。这里仅用其中的四列即可:“PART_DT” “LSTG_SITE_ID” “SELLER_ID”和“PRICE”。表 3-1 所示为这些列的内容和基数简介,显而易见 “SELLER_ID” 是一个高基列。
表 3-1 样例表 “default.kylin_sales”的情况
| 列名 | 描述 | 基数 |
|---|---|---|
| 730:两年 | ||
| LSTG_SITE_ID | 交易站点ID,如美国站用00代表 | |
| 卖家ID | 大约100万 | |
| 销售额 |
假设电商公司需要查询特定时段内,特定站点交易额最高的 100 位卖家。查询语句如下:
SELECT SELLER_ID, SUM(PRICE) FROM KYLIN_SALESPART_DT >= date'2012-02-18' AND PART_DT < date'2013-03-18'AND LSTG_SITE_ID in (0)group by SELLER_IDorder by SUM(PRICE) DESC limit 100方法 1 :在不设置 Top_N 度量的情况下,为了支持这个查询,在创建 Cube 时设计如下:定义“PART_DT”“LSTG_SITE_ID”“SELLER_ID”作为维度,同时定义 “SUM(PRICE) ”作为度量。Cube 构建完成之后,Base Cuboid 如表 3-2 所示。
表 3-2 Cube 的 Base Cuboid 结构
| Base Cuboid的RowKey | SUM(PRICE) |
|---|---|
| 20120218_00_seller0000001 | |
| 20120218_00_seller0000002 | |
| 20120218_00_seller0000003 | |
| 20120218_00_seller1000000 | |
| 20120218_01_seller0000001 |
假设这些维度是彼此独立的,则 Base Cuboid 中行数为各维度基数的乘积:730 * 50 * 1 million = 36.5 billion = 365 亿。其他包含“SELLER_ID”字段的 Cuboid 也至少有百万行。由此可知,由“SELLER_ID”作为维度会使得 Cube 的膨胀率很高,如果维度更多或基数更高,则情况更糟。但真正的挑战不止如此。
我们可能还会发现上面那个 SQL 查询并不能正常执行,或者需要花费特别长的时间,原因是这个查询拥有太大的在线计算量。假设你想查 30 天内 site_00 销售额排前 100 名的卖家,则查询引擎会从存储引擎中读取约 3000 万行记录,然后按销售额进行在线排序计算(排序无法用到预计算结果),最终返回排前 100 名的卖家。由于其中的关键步骤没有进行预计算,因此虽然最终结果只有 100 行,但计算耗时非常长,且内存和其中的控制器都在查询时被严重消耗了。
反思以上过程,业务关注的只是销售额最大的那些卖家,而我们存储了所有的(100 万)卖家,且在存储时是根据卖家 ID 而不是业务需要的销售额进行排序的,因此在线计算量非常大,因而此处有很大的优化空间。
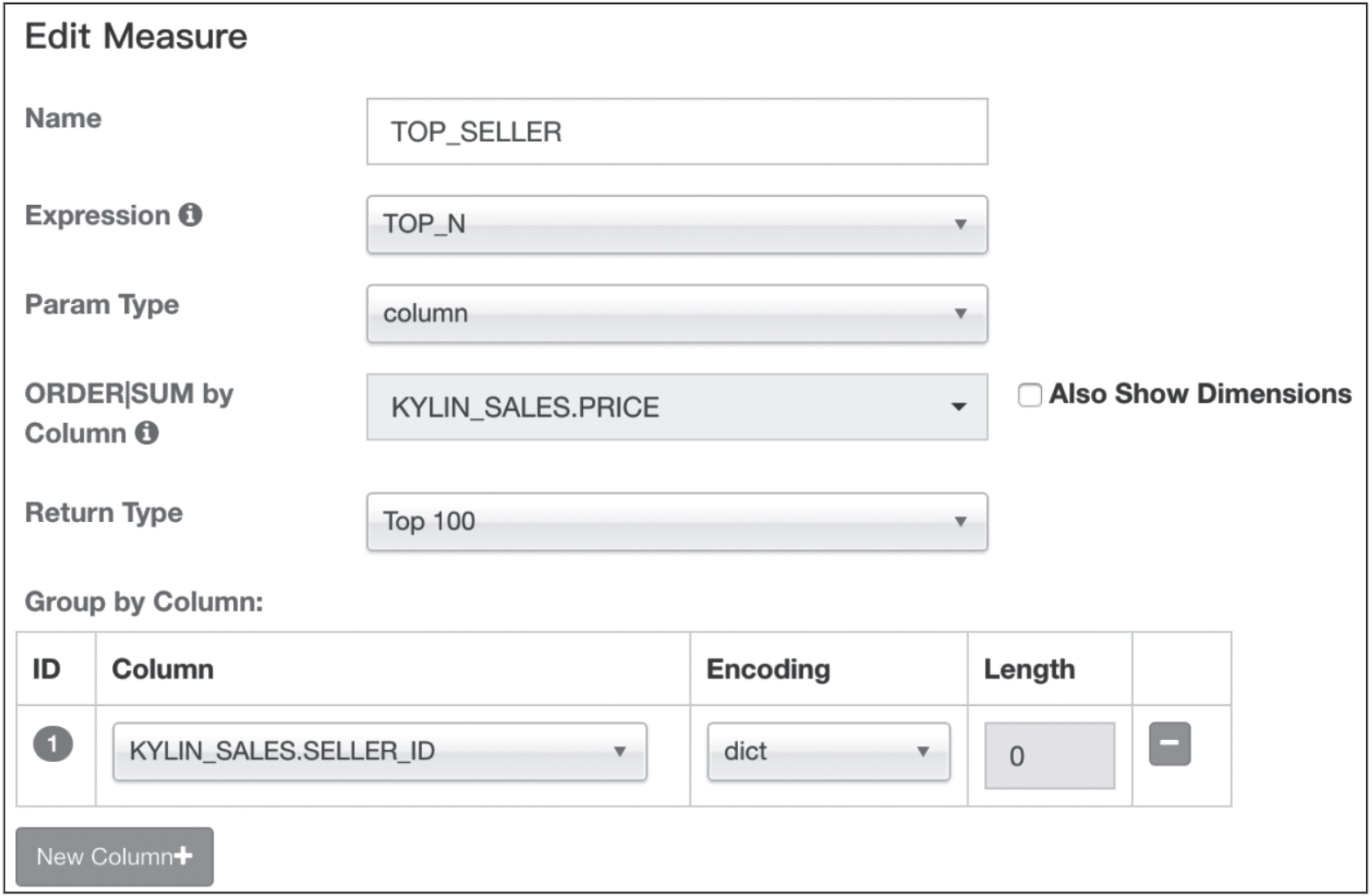
方法 2 :为了得到同一查询结果。如果在创建 Cube 时,对需要的 Top_N 进行了预计算,则查询会更加高效。如果在创建 Cube 时设计如下:不定义“SELLER_ID”为维度,仅定义“PART_DT”“LSTG_SITE_ID”为维度,同时定义一个 Top_N 度量,如图 1 所示。
图 1 TOP\_N 度量的设置示例
新 Cube 的 Base Cuboid 如表 3-3 所示,Top_N 度量的单元格中存储了按 seller_id 进行聚合且按 sum(price) 倒序排列的 seller_id 和 sum(price)的组合。
表 3-3 新 Cube 的 Base Cuboid 结构
| base cuboid的RowKey | Top_N Measure |
|---|---|
| 20120218_00 | seller0010091:1092.21, seller0005002:1090.35,…,seller0001789:891.37 |
| 20120218_01 | seller0003012:xx.xxseller0004001:xx.xx,…,seller000699: xx.xx |
| 20120218_02 | |
| 20120218_50 | |
| 20120219_01 | seller0010091:1012.74, seller0005002:1032.63…,seller0001981:883.57 |
现在 Base Cuboid 中只有 730 * 50 = 36500 行。在度量的单元格中,预计算的 Top_N 结果以倒序的方式存储在一个容器中,而序列尾端的记录已经被过滤掉。
现在,对于上面那个 Top_100 seller 的查询语句,只需要从内存中读取 30 行,Kylin 将会从 Top_N Measure 的容器中抽出“SELLER_ID”和“SUM(PRICE)”,然后将其返回客户端(并且是已经完成排序的)。现在查询结果就能以亚秒级返回了。
一般来说,Kylin 在 Top_N 的单元格中会存储 100 倍的 Top_N 定义的返回类型的记录数,如对于 Top100,就存储 10000 条 seller00xxxx:xx.xx 记录。这样一来,对于 Base Cuboid 的 Top_N 查询总是精确的,不精确的情况会出现在对于其他 Cuboid 的查询上。举例来说,对于 Cuboid[PART_DT],Kylin 会将所有日期相同而站点不同的 TOP_N 单元格进行合并,这个合并后的结果会是近似的,尤其是在各个站点的前几名卖家相差较多的情况下。比如,如果 site_00 中排第 100 名的卖家在其他站点中都排在第 10000 名以后,那么它的 Top_N 记录在其他站点都会被舍去,Kylin 在合并 TOP_N Measure 时发现其他站点里没有这个卖家的值,于是会赋予这个卖家在其他站点中的 sum(price)一个估计值,这个估计值既可能比实际值高,也可能比实际值低,最后它在 Cuboid[PART_DT]中的 Top_N 单元格中存储的是一个近似值。
图书简介 :src="https://static001.infoq.cn/resource/image/f2/84/f22bf661636663e27a8b1fdbc5e15184.png"/>
相关阅读 :
Apache Kylin权威指南(一):背景历史和使命
Apache Kylin权威指南(二):工作原理
Apache Kylin权威指南(三):技术架构
Apache Kylin权威指南(四):核心概念
Apache Kylin权威指南(五):Getting Started
Apache Kylin权威指南(六):Cuboid剪枝优化
Apache Kylin权威指南(七):剪枝优化工具
Apache Kylin权威指南(八):Rowkey 优化