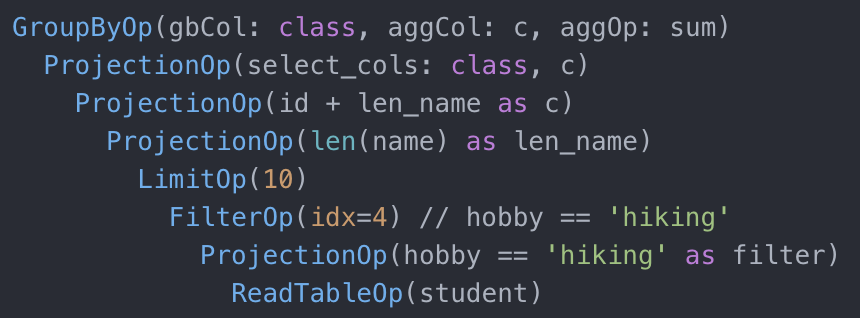
可能看完了这个执行计划的流程,读者依然会说,没毛病啊。其实不然。比如,对于 class 表,总共只用到了两个 column:id 和 name,因此我们可以在读取表的时候直接进行 projection。一是,相对于把整个表全部读取放进内存中,只读取 2 个 column 所需的内存要少很多。另外,如果考虑到使用列存形式存储数据,只读两个 column 和读取全部的 column 速度上也快很多。这里,我们引出了第一个语句重写的规则:Projections push down。通过把用到的哪些 column 往下推送直到叶节点的 table scan,可以减少扫描后数据的大小,同时也可以提升扫描速度。同样的,我们也可以对学生表的读取进行优化,学生表只用到了 id, class_id, 和 name column。更进一步的是,对于学生表,除了 projections push down,我们还能把 filter predicates 也往下推送。因为最终的结果里面只需要姓名为’ZhangSan’的学生,与其把所有的学生信息都读取进来和 class 表进行 join,我们可以先 filter 掉其他的学生,使得 join 的数据大大减少(假设叫’ZhangSan’的同学应该不会很多)。这便是我们提到的第二个重写规则:Predicates push down。通过把 filter predicates 往下推送,以减少后续操作的数据量。经过这两步的改写,新的语法树变成了如下这个形式: