引言
本文整理自 ArchSummit 微信大讲堂线上群分享内容;解释一下这次我为什么不是分享安全方面,反而分享数据方面的,ArchSummit 北京 2015 分享的实际也是数据计算方面的技巧,只不过用在了风控场景上,这次我尝试把那些操作更加往底层架构上延伸一下,更加有逻辑去考虑这个话题。
正文
第一部分存储模型之前,先抛两个问题:
1)这些存储的数据结构,主要是来优化什么操作的?
2)SSD 对于这些存储结构有什么样的影响?
一. 存储模型–读和写的取舍
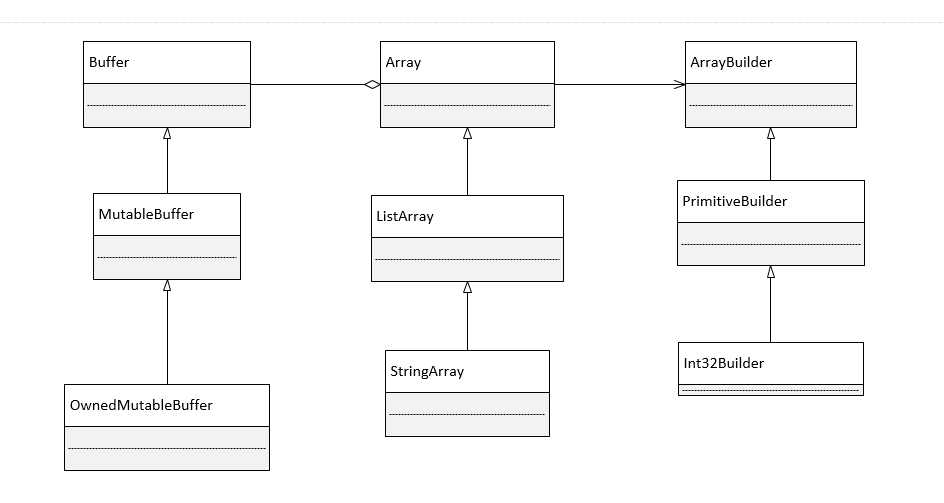
一个好的存储结构,我们希望的是更新数据快,查找特定的数据也快,最好占用空间还小,一般来说,这算得上是对存储的终极要求了。
终极要求,这东西一般都是 YY,但是,加上一定的限制条件,在特定的时期,数据大爆炸之前,单机时代,B 树这个结构,可以算得上是银弹。基本上所有的关系型数据库系统都采用这种结构。SqlServer 和 Oracle 都采用 B 树,Mysql,Db2 还有 informix 采用的 B+ 树,
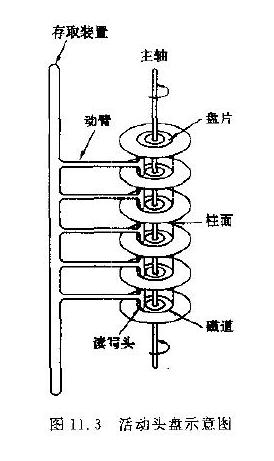
磁盘读数据和写数据的过程,1)移动磁头到对用的扇区,2)然后磁头接触磁道,写或者读数据,3)通过总线传输到内存或者寄存器。
磁头移动时间,十分之一秒的级别,读写的时间,按照普通磁盘,7200 转的,差不多在百分之一秒级不到,还有一个耗时就是总线传输时间,这个基本可以忽略,在 10 的 8 次方分之秒。
另一个背景知识是,文件系统, 读写是有最小操作单位的块,每次 I/O 操作,都是整块操作。块大小,跟文件系统的格式有关,fat32,ext3/4 等等,常见的块大小 4096 个字节,块大小可以调整,块,对应到物理的扇区。
通过上面的分析,有效的优化是降低磁头定位的次数;B 树就是综合读写两方面的需求,提出的对磁头定位操作优化的结构。隐含的数据特征是:重查询,轻新增,并发写要求不高。总的数据量优先,单挑记录会被反复更新,这刚好就是单机时代的数据特征。在做关系型数据库表设计的时候,知道这点会比较有用。
B+ 树和 B* 树是 B 树的两种变形,B+ 树降低了中间节点的数据大小,同样的块大小,可以存储更多的数据,检索上更有效率,但是,实际数据读取上有妥协。B* 树,相对于 B 数在节点的分裂,旋转,平衡方面有增强。
进入互联网时代,数据的特征有了变化,写多读少,数据具备热点时间。有效期之后的数据,就相当于传统数据库的归档。另外一个有利的变化,是内存变得很便宜,可以用足够低的成本 hold 住热点数据。这种前提下,顺序写做持久化,热点数据保持在内存中,并且在内存中进行排序,保证顺序写入的数据是有序的。
基于这样的思路,就有了 LSM-Tree 和 COLA-Tree 两种改进。区别在于 LSM 的 MemTable 保持固定大小,持久化数据的索引都有 compaction 阶段完成。COLA 的思路,是 Memtable 就按照固定的逻辑完成索引更新。COLA 里面是没有 Memtable 这个名称的。
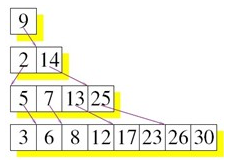
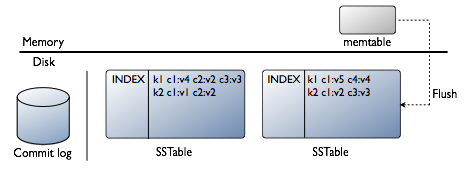
基本上现存所有的 NoSQL 都是采用 LSM-Tree 的思路,除了 TokuDB。
Cassandrda 和 LevelDB,需要特别提一下,他们两个在 Compaction 阶段的实现,是参考了 COLA 的做法的,sstable 做了分层合并。COLA 在层之间,还引入了分形树(Fractal Tree)的实现,改进索引性能,Cassandra 和 LevelDB 是没有,单层上数据检索,还是采用的 BloomFilter 和二分法。
二. 实时计算 - 精度和速度的权衡
纯粹从性能对比,COLA 跟 B 树算是公平对决,数据如下:块大小 4098 字节
查询 Cola 比 B 树慢 12 倍,插入速度是 B 树的 340 倍。
LSM 不具备可比性,更多靠 cache 命中的效率。
之前提到的问题,SSD 的影响,这么看起来,SSD 对 B 树和 Toku 的影响要比 LSM 大(只是相对的),这些算法,对于 ssd 来说,算法对性能的影响并不重要,比较重要的反而是,通过算法降低,flash 的读写次数,达到延长 ssd 使用寿命和减少损坏率。
除了需要保存检索数据,还需要对数据进行计算,流计算,实时计算的框架,已经是大数据里面到处可见,Storm,Spark Stream 等等,这些流行框架更多是调度系统,真正的计算还需要自己来实现。
在我现在的实际工作中,常见的有点难度的计有 exist 是否存在,distinct count 去重计数,top n 等等在 window 内部。
所有这些计算,对于内存都是很巨大的挑战。可行的做法,就是引入精度,接受概率。
这些做法,在数据挖掘的领域,已经是司空见惯的做法,比如关联规则挖掘的 Apriori 跟 Fp-growth 等都引入的概率的做法。
很多程序员其实也用过,一说就知道,Bloom Filter 做去重,接受一定概率的误差,换来空间的减少,提升性能。
接下来介绍几个,我在实际工作中,用得比较多的方法,实际上是几个概念。
1)Bloom Filter
2)Sketching
3)基数估计
BF 略过,大家都知道。Sketching,用于做频率估计,估算数据流中每个数据的出现次数。基本思路也跟 BF 差不多,通过互相独立的 hash 函数依次处理输入,接受一定程度的正负错判,估计值在一定概率内正确,这个概率可调整。这类方法的另一个优势是可以很容易实现分布式,能够合并。
Sketch 有几个变种,basic sketch, counter sketch 和 counter min sketch,依次各有改进。
Bf 和 counter min sketch 算是当前最优的 top n 的方法。Cms 对于重复度高的效果较好,重复度不高了,有基于 cms 基础上的改进,counter-mean-min sketch。
上面在存储模型中间没有提到,cms 还能够用在 nosql 的 range query 索引上,不追求精确度,在性能方面完爆 B 树。
基数估计也是类似的思路,用很少的空间,计算集合的势,常见的算法有 Linear counter,LogLog counter 两类,分别使用在重复情况比较明显和重复情况相对于总量来说较低
Redis 在支持 bitmap 之后,在 2.8.9 之后,直接提供了 hyperloglog 的支持,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。线性的 counter 也可以直接利用 bitmap 实现。Hash 函数的 murmur 是比较可以无脑使用的实现。
具体的算法描述,大家可以问百度,不细说了,知道有哪些可用场景就好。我们主要用在风险检测的参数计算方面。
三. 分布式持久化 -CAP 的妥协
对于分布式持久化的内容,也扯两句,我个人很喜欢 Dynamo 模型的对称结构,BigTable 的管理节点实在是不美观。也就是 zk 和 gossip+vector clock 的战争,这种选择也就决定了各自在 CAP 和 ACID 中间能够达到的水平。
四.日志为中心的基础架构设计
ArchSummit 全球架构师峰会 上我也推荐过 kafka 的作者写的文章,在推荐一次,个人觉得每一个做分布式系统设计的架构师,都应该读几遍才好。
给大家看这样一个图
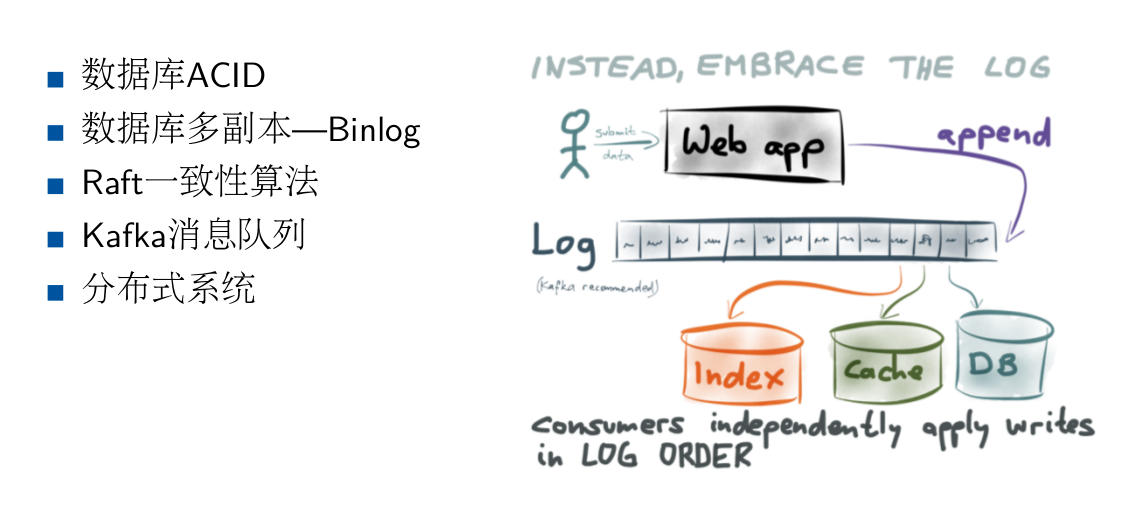
(点击放大图像)
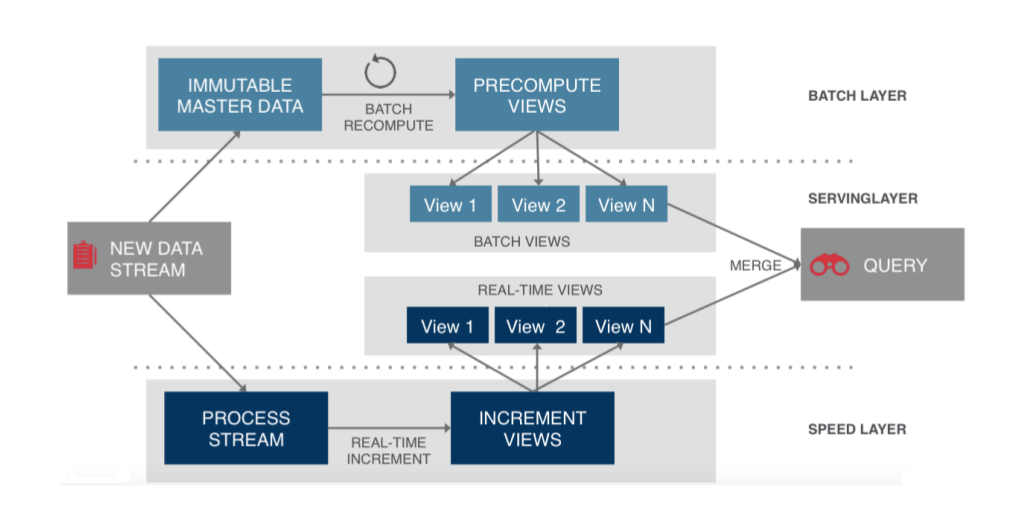
苏宁现在整体数据系统建设思路,差不多就是这样,通过日志,串行所有操作,避免冲突。基本上满足异地多活的需求。
中间过程,分实时计算,批量计算并且在服务层合并数据。
五.Q&A
您好,您在处理复杂的任务调度方面,有什么心得体会?
你们代码是自动 Review 的吗?
Q3.storm**** 和 spark 的应用场景有什么区别?
Q.4**** 日志输出是否有自研组件?所有业务线统一一个吗?主要输出哪些内容?
Q.5**** 对 SSD 而言,现有的文件系统已经不太能发挥存储设备的最大速度,未来的 SSD 文件系统会是什么样?
对于 Google 任务调度系统 Borg,您怎么看?
Q.7**** 能否详细讲解一下 sketch 算法的计算过程,这个算法在苏宁有哪些应用?
Q.9**** 随着新硬件的快速发展,大数据系统当存储和网络不再成为瓶颈时,会不会呈现出一种新的形态?
讲师介绍
季虎 ,苏宁 IT 总部安全研发技术总监,ArchSummit 北京专题讲师,目前已构建了苏宁电商和金融的风控技术体系,此前,任阿里集团安全部高级技术专家,参与了 AE,金融和集团的风控系统建设,并致力推进风控自动化和大数据风控实践。
本文根据 ArchSummit 微信大讲堂上邀请讲师,苏宁 IT 技术总监 季虎为大家线上分享内容整理而成, 长按下方二维码,回复“架构师”,获取参与方式,加入围观大牛线上分享,同步大会筹备近况……
点击这里