微软研究院最近开源了Visual ChatGPT,一个聊天机器人系统,可以根据人类的文本提示生成和处理图像。该系统将OpenAI的ChatGPT与 22 种不同的视觉基础模型(VFM)相结合,可以支持多模态交互。
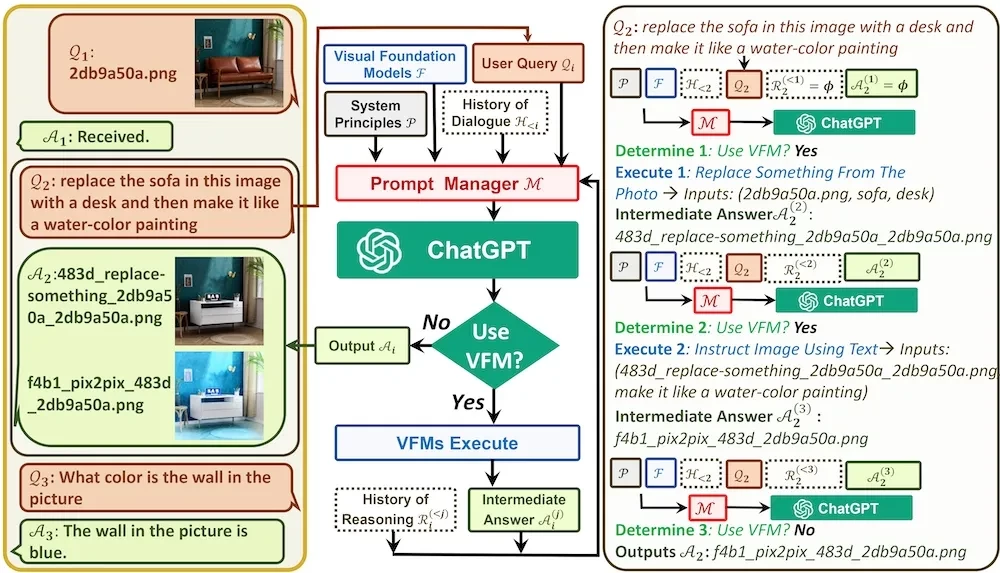
arXiv 上的一篇论文对该系统进行了描述。用户可以通过输入文本或上传图片与聊天机器人互动。机器人还可以根据文本提示生成图像,或者通过处理聊天历史记录中的图像来生成图像。该聊天机器人的一个关键模块是提示词管理器(Prompt Manager),它将用户输入的原始文本组织成一个“思维链”提示词,帮助 ChatGPT 确定是否需要调用 VFM 工具来执行图像任务。据微软团队称,Visual ChatGPT 是:
ChatGPT 和其他大语言模型(LLM)已经显示出了强大的自然语言处理能力,但它们被训练成只处理一种输入模式:文本。微软并没有训练另一个新的模型来处理多模态输入,而是设计了一个 Prompt Manager 来生成输入给 ChatGPT 的文本,进而生成可以调用 VFM(如 CLIP 或Stable Diffusion)来执行计算机视觉任务的输出。
Visual ChatGPT 架构
提示词管理器基于 LangChain 代理,而 VFM 被定义为 LangChain 代理工具。为了确定是否需要调用工具,代理会结合用户提示词和对话历史记录(其中包含了图像文件名),然后应用提示词的前缀和后缀。前缀包括以下文本:
前缀中的附加文本会引导 ChatGPT 问自己“是否需要使用工具”,如果需要使用工具,它应该输出工具的名称以及所需的输入,例如要生成的图像文件名或图像的文本描述。代理将迭代地调用 VFM 工具,将生成的图像发送到聊天会话中,直到不再需要使用工具。此时,最后生成的文本输出将被发送到聊天会话中。
在 Hacker News 的一个帖子中,一位用户指出 VFM 使用的内存比语言模型少得多,他想知道为什么。另一位用户回复说:
Visual ChatGPT源代码可在 GitHub 上获得。
原文链接:
Microsoft Open-Sources Multimodal Chatbot Visual ChatGPT
相关阅读:
一部手机就可运行,精通 Python 等 20 种语言!谷歌终于能与 OpenAI 打擂台了,全新 PaLM 2 比肩 GPT-4
AIGC 在保险行业有哪些应用落地的可能性?
AI 时代的“身份证”要来了?ChatGPT 之父推出加密钱包 World App,并称区块链可以区分人与 AI