编者按:
来自伯克利的犀利断言: Serverless 计算将会成为云时代默认的计算范式,将会取代 Serverful (传统云)计算模式,因此也意味着服务器-客户端模式的终结。
你准备好了吗?
引言
2009 年,伯克利以独特的视角发布了一篇文献,定义了云计算,十年过去了,这篇文章被引用无数,其中的观点更是当下最好的见证:
2019 年,伯克利又以新的视角发布了一篇文献:将云中的编程变得简单:伯克利视角下的Serverless 计算。观点同样让人眼前一亮:
因为 Serverless 和传统的云计算有着本质的区别:
如果各位看官和我一样,对于伯克利视角下的 Serverless 好奇的话,不妨跟随我接下来以问答的方式来解读一下这篇文献:
Serverless 计算的最佳理解是?
在任何的 Serverless 平台,用户只需要使用高级语言撰写使用云功能,然后以事件来触发运行即可,如将图片上传到云存储中、将图像缩略图插入到数据库表中,而所有的传统的操作:实例选择、实例扩展、部署、容错、监控、日志、安全补丁等等,均由 Serverless 计算的来掌控。
Serverless 计算和传统的云计算(serverful)有何区别?
相对于 Serverless 计算,传统意义上的云计算已经成为了 Serverful 计算了,以下列表从开发者和系统管理员的角度分别对比了他们二者之间的区别:
| 特性 | AWS Serverless 云计算 | AWS Serverful 云计算 | |
|---|---|---|---|
| 程序员 | 何时运行程序 | 由云用户根据事件自行选择 | 除非明确停止,否则会一直运行。 |
| 编程语言 | JavaScript、Python、Java、Go等有限的语言 | 任何语言 | |
| 程序状态 | 保存在存储(无状态) | 任何地方(有状态或无状态) | |
| 最大内存大小 | 0.125~3GiB(云用户自行选择) | 0.5~1952GiB(云用户自行选择) | |
| 最大本地存储 | 0~3600 GiB (云用户自行选择) | ||
| 最长运行时间 | 900秒 | 随意 | |
| 最小计费单元 | 0.1秒 | 60秒 | |
| 每计费单元价格 | $0.0000002 | $0.0000867 - $0.4080000 | |
| 操作系统和库 | 云供应商选择 | 云用户自行选择 | |
| 系统管理员 | 服务器实例 | 云供应商选择 | 云用户自行选择 |
| 扩展 | 云供应商负责提供 | 云用户自己负责 | |
| 部署 | 云供应商负责提供 | 云用户自己负责 | |
| 容错 | 云供应商负责提供 | 云用户自己负责 | |
| 监控 | 云供应商负责提供 | 云用户自己负责 | |
| 日志 | 云供应商负责提供 | 云用户自己负责 |
基于云环境的描述下,Serverful 计算犹如传统底层的编程语言,如汇编程序;而 Serverless 计算犹如高级的编程语言,如 Python。前者开发者需要考虑每一个细节,到 CPU 寄存器这样一个级别,而后者开发者只需要考虑要实现的功能即可。
Serverless 之所以成为可能的基础条件有哪些?
伯克利对 Serverless 的大胆预言是什么?
Serverless 将会在接下来的十年,迅速的被采用,将会得到飞速的发展。
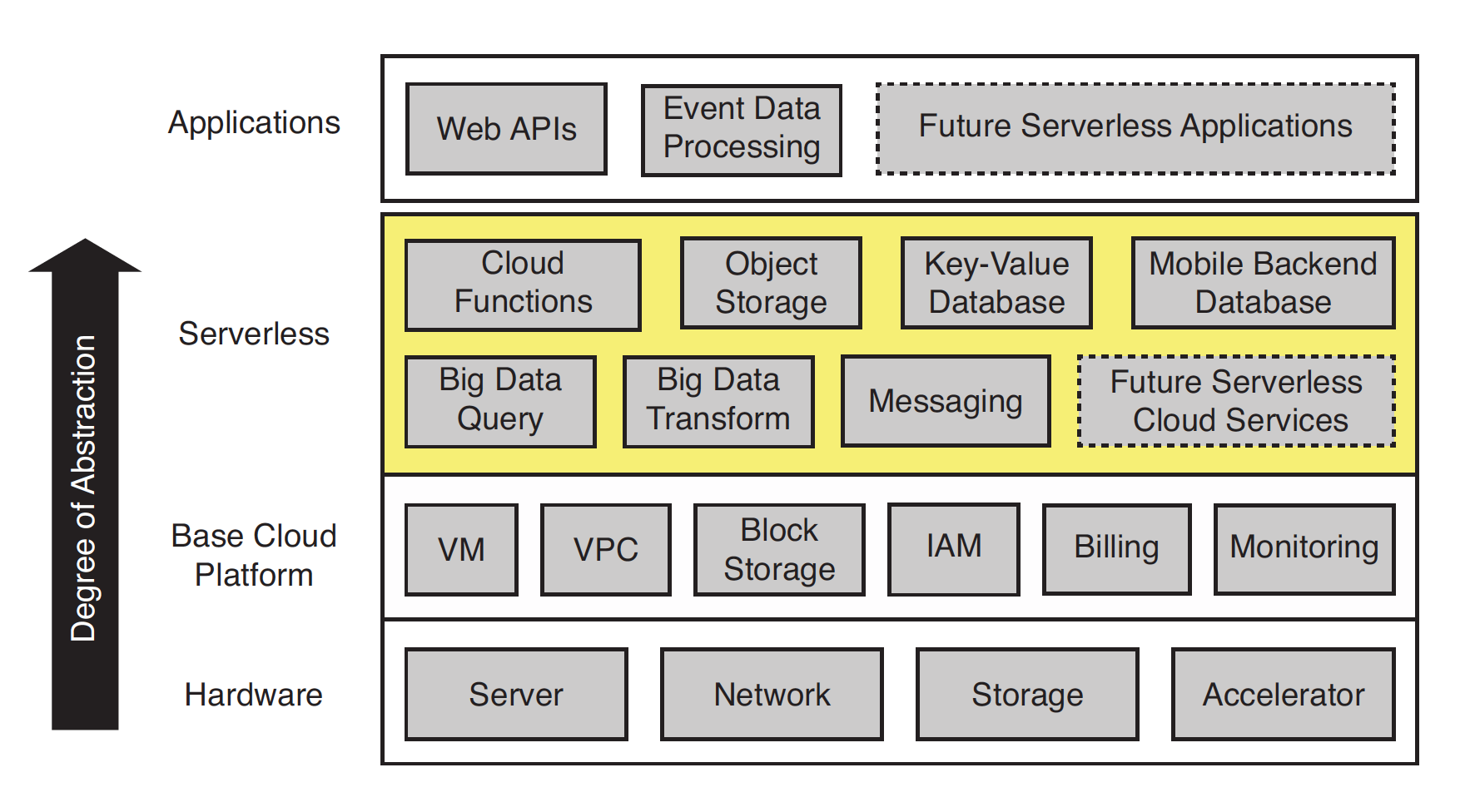
Serverless 计算的软件栈架构概览
Serverless 介于基础云平台和应用程序之间,旨在简化基于云的编程开发,Cloud Functions (通常称之为 FaaS)提供通用的计算,辅以专门的后端即服务(BaaS)等生态系统,如对象存储、Key-Value 数据库等。
Serverless 目前应用的场景如何?
来自 2018 年的一个调查显示:
| 百分比 | 用户场景 |
|---|---|
| web 和 API 服务 | |
| 数据处理,如批处理的ETL | |
| 整个第三方的服务 | |
| 内部 tooling | |
| 聊天机器人,如 Alexa Skills(Alexa AI 助手 SDK) | |
| 物联网 |
对五类典型应用的深度分析:
| 应用程序 | 描述 | 挑战 | 解决办法 | 花销比较 |
|---|---|---|---|---|
| 实时视频压缩(ExCamera) | 扔到云中的视频解码 | 对象存储太慢,无法支持细粒度的通信;功能太粗糙,无法完成任务。 | 功能对功能以避免对象存储;以功能调度而不是任务。 | 比基于虚拟机快60倍,但是钱只花了1/6。 |
| 大数据处理(100TB排序) | 由于对象存储延迟和IOPS限制,扩展成为问题 | 使用低延迟存储,高IOPS | 比虚拟机快1%,节省15%的费用 | |
| 线性代数计算(Numpy-wren) | 大规模线性代数计算 | 对象存储的低延迟、难以实现客户端的广播问题。 | 使用低延时高吞吐的对象存储, | 比原来慢了3个数量级,CPU的消耗降低1.26到2.5倍。 |
| 机器学习pipeline(Cirrus) | 大规模的机器学习 | 缺乏快速的存储,难以实现广播、聚合问题。 | 使用低延迟存储,高IOPS | 比虚拟机快3~5倍,比原来贵7倍 |
| 数据库(Serverless SQLite) | 应用程序的主要状态(OLTP) | 缺乏共享内存,对象存储具有高延迟,缺乏对入站连接的支持。 | 如果写入需求低,共享文件系统可以工作。 | TPC-C基准,要比原来的快3倍,读取比例匹配但写入不匹配。 |
对 Serverless 计算的期待?
Serverless 计算目前有被人们吐槽的地方?
在分析了五大典型(实时视频解码、MapReduce、大规模线性代数计算、机器学习训练、数据库)应用案例之后,得出如下几个结论:
是什么吸引着大家去追求 Serverless 计算方式?
对于云用户来说:
对于云提供商来说:
谬误和陷阱
本章是向Hennessy and Patterson二位的风格致敬。鉴于本文只是读论文的解读,所以不会翻译所有的内容,这里仅抛砖引玉,讲述两个非常有趣的答复:
谬误:CloudFunctions 无法处理需要可预测性能的极低延迟应用程序。
Serverful 计算,即服务器实例对于低延迟应用程序的处理,是它们始终处于启动状态,因此它们可以在收到请求时快速回复请求。 那么,照葫芦画瓢,如果 CloudFunctions 的启动延迟对于给定的应用程序来说不够好,可以使用类似的策略:通过定期运行它们来 CloudFunctions 进行预热,从而确保在任何给定时间都能够及时的响应,进而满足传入的请求。
陷阱:Serverless 计算会导致无法预料的成本
这种纯粹意义上按代码运行付费的模式,其实是大家对于这样新的计费模式的不适应罢了,尤其是大型公司的预算考虑,相信随着时间的推移,一旦人们了解了自己的业务以及有了一些历史数据之后,就会适应这样的计算模式的,一如对于如电力这样的计费模式。
笔者能力所限,加上论文论断式的风格,最后强烈建议各位看官请移步伯克利网站下载论文,进行进一步的深度阅读!尤其是引用的材料。
论文链接: