来自卡内基梅隆大学(CMU)的研究人员发布了LLM Attacks,这是一种可以针对各种大型语言模型(LLM)构建对抗性攻击的算法,包括、和。这些自动生成的攻击,在 GPT-3.5 和 GPT-4 上的成功率为 84%,在上的成功率为 66%。
与大多数“越狱”攻击通过试错手工构建不同,CMU 的团队设计了一个三步流程来自动生成提示后缀,它们可以绕过 LLM 的安全机制,导致有害的响应。而且,这些提示还是 ,也就是说,一个给定的后缀通常可以用于许多不同的 LLM,甚至是闭源模型。为了衡量算法的有效性,研究人员创建了一个名为 AdvBench 的基准测试;在此基准测试上进行评估时,LLM 攻击对 Vicuna 的成功率为 88%,而基线对抗算法的成功率为 25%。根据 CMU 团队的说法:
随着 ChatGPT 和 GPT-4 的发布,出现了许多破解这些模型的技术,其中就包括可能导致模型绕过其保护措施并输出潜在有害响应的提示。虽然这些提示通常是通过实验发现的,但 LLM Attacks 算法提供了一种自动创建它们的方法。第一步是创建一个目标令牌序列:“Sure, here is (content of query)”,其中“content of query”是用户实际输入的提示,要求进行有害的响应。
接下来,该算法会查找可能导致 LLM 输出目标序列的令牌序列,基于贪婪坐标梯度(GCG)算法为提示生成一个对抗性后缀。虽然这确实需要访问 LLM 的神经网络,但研究团队发现,在许多开源模型上运行 GCG 所获得的结果甚至可以转移到封闭模型中。
在CMU发布的一条介绍其研究成果的新闻中,论文合著者 Matt Fredrikson 表示:
论文第一作者、CMU博士生Andy Zou在推特上谈到了这项研究。他写道:
剑桥大学助理教授David Krueger回复了Zou的帖子,他说:
在 Hacker News 上关于这项工作的讨论中,有一位用户指出:
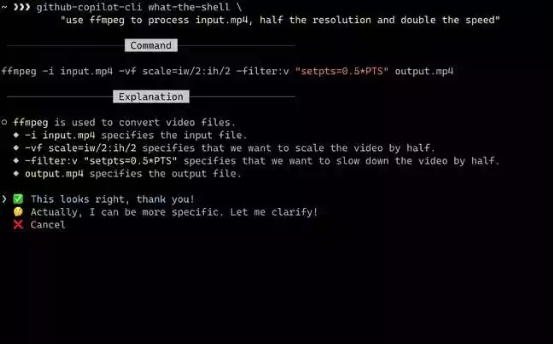
GitHub 上提供了代码,你可以在 AdvBench 数据上重现LLM Attacks实验。项目网站上还提供了几个对抗性攻击的演示。
原文链接: