Peloton 最初是在 2018 年 11 月份引入的,并在2019年3月份正式开源。Peloton 是为像优步这样拥有数百万个容器和数万个节点的规模公司设计的,它提供了高级的资源管理特性,比如弹性资源共享、层级化的最大最小公平性(max-min fairness)、资源超量(resource overcommits)使用和工作负载抢占。
为何需要统一的资源调度器
集群管理是科技公司中常见的软件基础设施,它将物理主机中的计算资源聚合到一个共享资源池中,这样增强了计算能力,并允许灵活使用数据中心的硬件。在优步,集群管理为各种工作负载提供了一个抽象层。随着业务规模的不断扩大,有效地使用集群资源变得非常重要。
但是,因为有一些用于批处理、无状态或有状态用户场景的集群,所以优步的计算栈并没有得到充分利用。此外,业务的动态性意味着在节假日或其他活动的时候,拼车的需求会有很大的波动。这些边缘情况会导致优步的工程师为每个集群提供过量的硬件资源,以便于处理高峰期的工作负载。依赖于专用集群也意味着无法在它们之间共享资源。在高峰时期,可能有的集群急需资源,而其他的集群恰好有可共享的资源。
为了更好的使用资源,优步需要将这些工作负载放到一个统一的计算平台上。由此带来的高效率将会减少每次出行的基础设施的成本,最终能够依赖优步的司机和乘客从中收益。
最终,优步给出的解决方案是 Peloton,它是一个统一的调度器,设计为跨不同的工作负载管理资源,它会将不同的集群合并成一个统一的集群。Peloton 通过一个共享的平台支持优步内所有的工作负载,实现平衡资源使用、弹性共享资源的功能,并且还能帮助优步的工程师规划未来的容量需求。
计算集群工作负载
在优步,主要使用了四种计算集群工作负载,分别是无状态的任务、有状态的任务、批处理任务以及守护任务。

图 1 优步将工作负载分成了四类,每一类都有其特殊的属性和资源
统一资源调度的需求
计算集群对于优步的业务来说是至关重要的,借助它,基础设施的用户能够更容易地管理企业内部和云环境中的资源。
让各种不同的工作负载共享集群是提升集群利用率和降低整体集群成本的关键所在。如下列出了工作负载混合协作以驱动集群利用率提升的样例:
在认识到这些场景能够实现更好的运维效率、提升资源规划能力和优化资源共享之后,优步的工程团队意识到将不同的工作负载放到一个共享的计算平台中是非常有意义的。统一的资源调度平台能够管理所有类型的工作负载,并且尽可能高效地利用资源。
可用的集群调度器
在最近几年间,随着数据中心规模的不断增长和 Linux 容器技术的采用,大规模的集群管理已经成为了一项热点技术。与优步相关的四个集群管理技术包括:Google Borg、Kubernetes、Hadoop YARN和Apache Mesos/。
集群调度器的架构
在如下所示的图 2 中,基于六个功能化领域对比了这四个集群调度器的架构,这六个领域包括:任务执行、资源分配、任务抢占、任务安置、作业/任务生命周期以及应用级别的工作流(如):
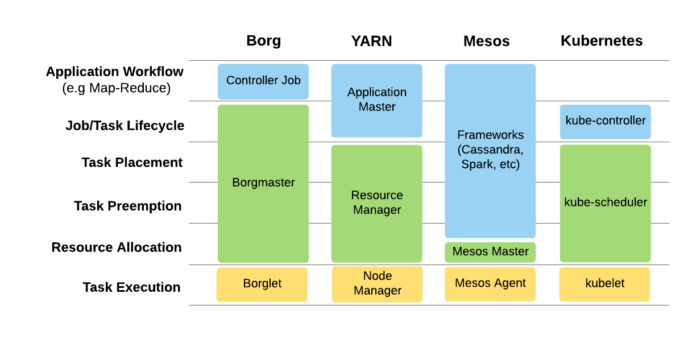
图 2 基于六个功能领域对四个主要的集群调度器进行对比
Mesos 的资源分配分成了两部分:框架级别的粗粒度分配以及作业级别的细粒度分配。Mesos 使用为框架分配资源,而对于作业级别的分配则委托给了每个框架来实现。
基于以下原因,优步最终没有选择这些技术方案:
因此,为了支持自己的工作负载,优步构建了 Peloton,这是运行在 Mesos 之上的统一资源调度器。
Peloton 概览
Peloton 构建在之上,利用了它从不同主机聚合资源并且以容器的形式搭建任务的能力。为了更高效地管理集群范围内的资源并加速全局的调度决策,Peloton 使用了层级化(hierarchical)的资源池来管理不同组织和团队之间的弹性资源。
如下的图 3 对比了 Peloton 和其他集群管理系统的架构:
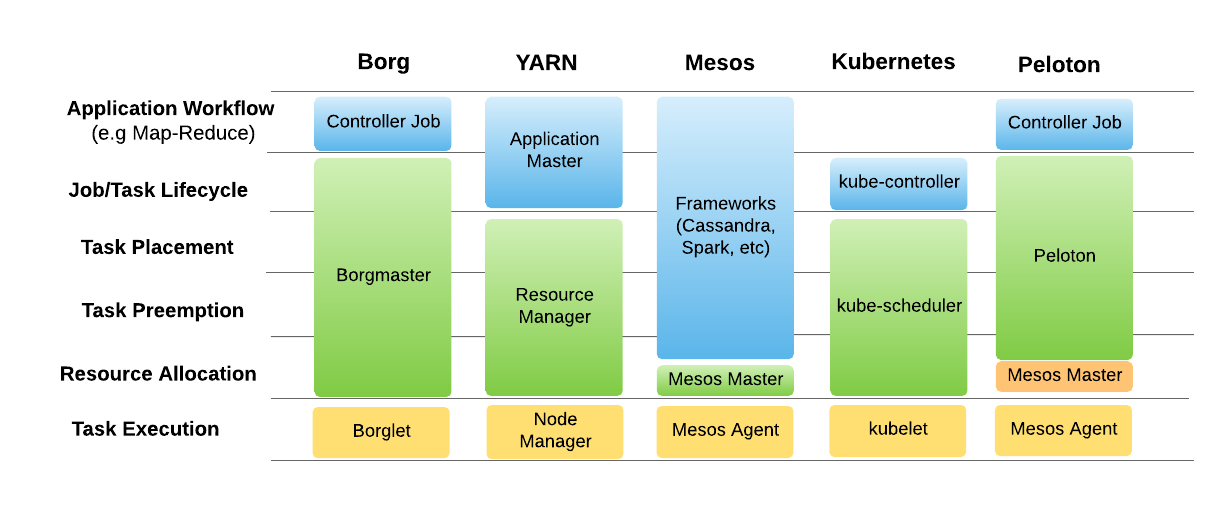
图 3 在作业生命周期、任务安置以及任务抢占方面,Peloton 能够比其他集群调度器更好地满足需求
在 Peloton 中,优步遵循了和 Borg 一样的方式,主要的区别在于使用 Mesos 作为资源聚合和任务执行层。而 Borg 使用自己的 Borglet 进行任务执行。
Peloton 的架构
为了实现高可用性和扩展性,Peloton 使用了双活架构并且具有四个单独的守护类型:任务管理器、资源管理器、安置引擎以及主机管理器。这些守护进程之间的交互进行了专门的设计,所以依赖实现了最小化,而且只会发生在一个方向。这四个守护进程都依赖Apache Zookeeper进行服务发现和领导者选举。
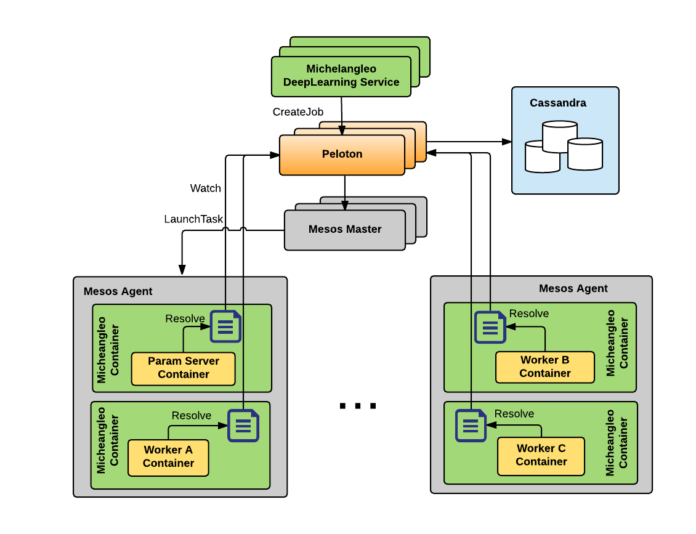
如下的图 4 展示了 Peloton 的整体架构,它构建在 Mesos、Zookeeper 和之上:
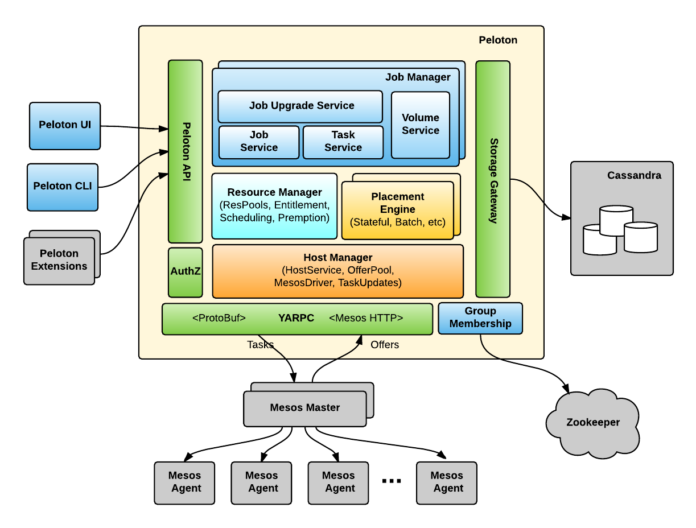
图 4 Peloton 通过多个 Mesos 集群实现了双活架构
Peloton 的架构是由如下的组件组成的:
Peloton 的四个守护进程都能保证高可用性,这是通过双活实例或领导者-跟随者(leader-follower )拓扑结构实现的。即便有的应用实例出现失败,Peloton 也能保证所有的任务都至少执行一次。
在扩展性方面,Peloton 有多个维度,包括集群中主机的数量、运行中作业和任务的数量、调度决策和启动任务的最大吞吐量。
Mesos 本身有着扩展性相关的一些限制。在 Peloton 中,Mesos 会作为所有主机的聚合器,这样允许系统管理来自多个 Mesos 集群的资源。因此,Peloton 可以通过管理多个 Mesos 集群的方式来进行扩展,而 Mesos 集群可以针对工作负载的特点确定合适的规模。在 Peloton 管理多个 Mesos 集群的时候,每个 Mesos 集群可以一组主机管理器。在如下的图 5 中,展现了通过共享的主机管理器管理多个 Mesos 集群实现扩展的样例。
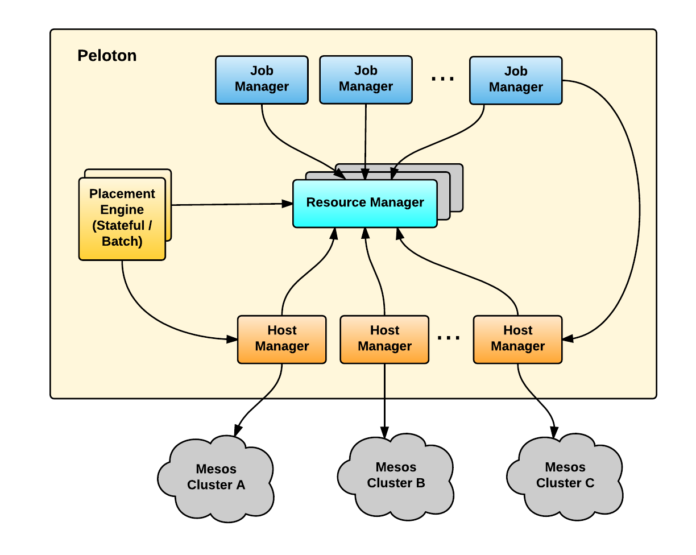
图 5 在扩展式部署中,Peloton 可以管理多个 Mesos 集群并在它们之间调度作业
Peloton 的特性
Peloton 主要的特性包括:
弹性化的资源管理
Peloton 的资源模型定义了集群中所有资源如何在不同的用户和作业之间进行分配以及不同的用户该如何弹性共享资源。在大型生产环境的数据中心中,有两种主要的资源分配机制:基于优先级的配额以及层级化的最大最小公平性。
这种模型已经被和集群管理系统所采用。在这种方式中,资源会被划分为两个基于优先级的配额:生产和非生产。生产配额的总处理能力不能超过集群的总能力。但是,在面对集群范围内的资源竞争时,非生产配额无法得到这样的保证。
在 Peloton 中,优步使用了层级化的最大最小公平性来进行资源管理,它在本质上就是弹性化的。在集群管理中,最大最小公平性是最为广泛采用的资源分配机制,这主要归功于它的通用性和性能隔离的能力。目前,很多集群调度器都提供了最大最小公平性,比如 YARN、VMware DRS 和 DRF。
如图 6 所示,通过使用这种方式,集群中所有的资源会被划分到不同的组织中,随后再划分至该组织的不同的团队。
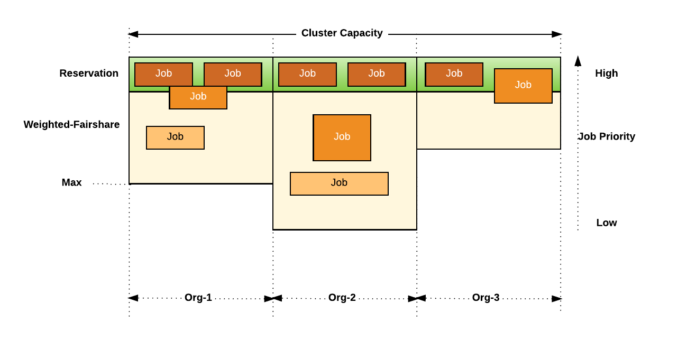
图 6 优步在 Peloton 中实现了资源管理的层级化最大最小公平性,从而能够在不同的组织间共享资源
每个组织都能得到固定数量的资源保证,在组织化的边界内,作业优先级是强制保证的。例如,如果一个组织没有高优先级的工作,那么其他优先级相对较低的工作负载的资源将会得到保证。
资源池
Peloton 中的资源池是集群中资源子集的逻辑抽象。集群中的所有资源都可以基于组织和团队划分为层级化的资源池。资源池又可以包含层级化的子资源池,从而能够在组织中进一步划分资源。
每个资源池都有不同的资源维度,比如用于 CPU、内存、磁盘空间和 GPU 的资源。
如图 7 所示,Peloton 资源池中的每个资源维度都有四个基本的资源控制:
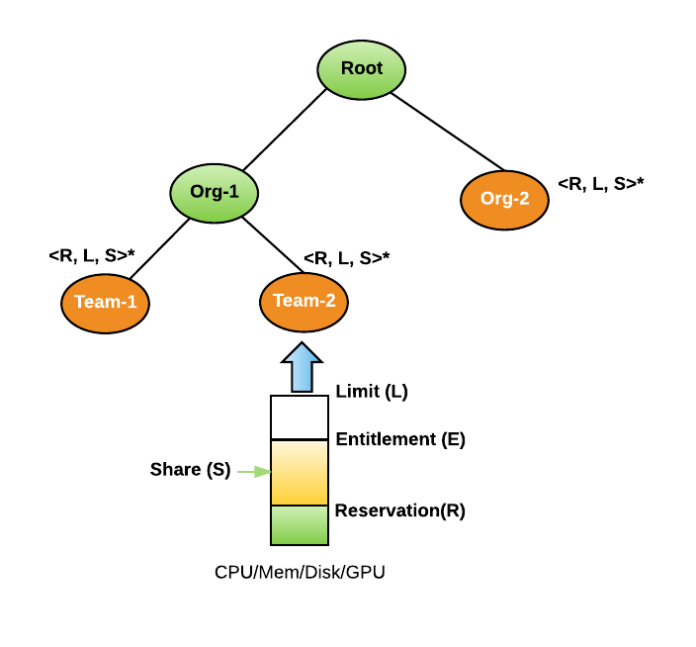
图 7 Peloton 为组织中的每个团队管理资源池,这个过程中会使用 Reservation、Limit 和 Share 进行控制
下图中展现了 Peloton 的弹性资源共享机制从某个资源池中借取资源满足优步生产环境的需求。
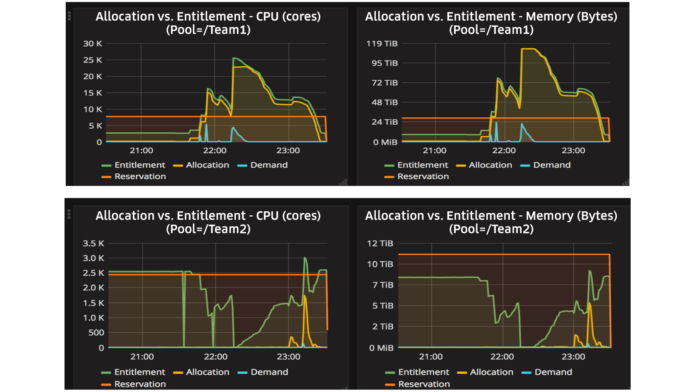
图 8 借助 Team 1 和 Team 2 的资源池之间的弹性资源共享,一个资源池可以从另一个资源池借用资源,以防其需求超过其保证的 Reservation。
资源池抢占
资源池的弹性层级化结构允许在不同的组织之间共享资源。每个组织都有专门的资源和资源池,可以在资源未得到充分利用时借给其他组织。
然而,共享资源的代价是,当出借者需要资源时,却无法检索这些资源。调度程序常常利用静态配额来实现更严格的 SLA 保证,Kubernetes 和 Aurora 就是这样。优步选择在团队之间共享资源,并通过在 Peloton 启用抢占来实现更严格的 SLA。在 Peloton 中,抢占机制允许从使用额超过其分配的资源的实体中收回资源,将它们返回给原始出借者以满足其计算需求。
使用场景
Apache Spark
Peloton 有自己的 Apache Spark 驱动程序,类似于用于 YARN、Mesos 和 Kubernetes 的驱动程序。Spark 驱动程序在 Peloton 中作为控制器作业运行,它会为相同的作业添加和删除执行器。Spark 的 shuffle 服务作为一个容器在所有主机上运行。在优步,每个月都在生产中运行数百万个 Spark 作业,使用 Peloton 作为资源调度程序,提高了与地图、市场和数据分析相关的所有工作的效率。
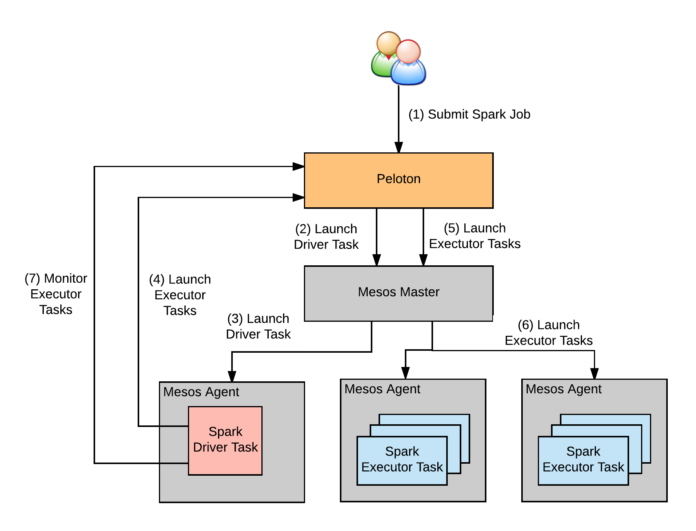
图 9 当 Peloton 运行 Apache Spark 的时候,它会使用 Spark 驱动程序来调度、排列优先级和启动执行器任务
TensorFlow
Peloton 支持分布式的TensorFlow、gang调度和,其中 Horovod 是优步的分布式 TensorFlow、Keras 和 PyTorch 框架。Peloton 允许这些框架将 CPU 和 GPU 配置在同一个集群上,并调度混合的工作负载。在这个项目中,Peloton 运行超过 4000 个 GPU 的大集群,并安排深度学习任务。
图 10 在 Peloton 使用 Horovod 运行分布式 TensorFlow 作业的示例,Peloton 可以使用 Mesos 运行所有任务,并提供了它们之间彼此发现的机制
除此之外,Peloton 还运用到了自动驾驶、地图和市场相关的工作负载中。
关于 Peloton 的最新进展和相关手册,请参考如下资料:
Peloton官方文档
Peloton开源,优步的统一资源调度器
Peloton:优步针对多样化集群工作负载的统一资源调度器
Peloton:Apache Mesos和Kubernetes上大规模Web工作负载的统一资源调度器
让Uber的所有人都能轻而易举地使用Apache Spark