Hadoop 技术栈,一直是企业自建大数据平台的首选。随着企业数据量的指数级增长,云计算时代的到来,企业对存储的弹性、运维及 TCO 都提出了更高要求。曾经自建 Hadoop 大数据平台的企业正逐步将大数据平台迁移至云上。本文中,“一面数据”分享了其大数据平台迁移的架构设计及实践,文末有份超详细的云平台运维避坑实践。
背景
一面数据创立于 2014 年,是一家领先的数据智能解决方案提供商,通过解读来自电商平台和社交媒体渠道的海量数据,提供实时、全面的数据洞察。长期服务全球快消巨头(宝洁、联合利华、玛氏等),获得行业广泛认可。公司与阿里、京东、字节合作共建多个项目,旗下知乎数据专栏“数据冰山”拥有超 30 万粉丝。一面所属艾盛集团(Ascential)在伦敦证券交易所上市,在 120 多个国家为客户提供本地化专业服务。
公司在 2016 年线下机房部署了 CDH 集群,到 2021 年已存储和处理 PB 级的数据。公司自创立以来一直保持每年翻一番的高增长,而比业务量增长更快的是 Hadoop 集群的数据量。
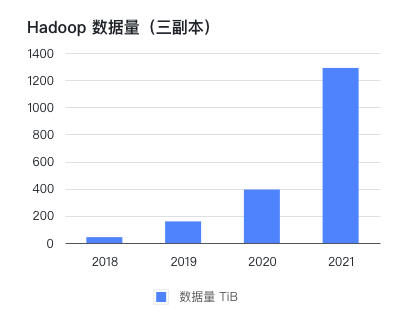
在这几年间,按 1 到 2 年规划的硬件,往往因数据增长超出预期而在半年后不得不再次扩容。 每次扩容周期可达到一个月,除了花费大量精力跟进行政和技术流程,业务端也不得不安排较多人日控制数据量。
为了降低运维难度,发展可持续扩张的大数据处理方案,我们从 2021 年 10 月份开始探索取代现有 Hadoop 集群的方案。
当时提出了这些需求:
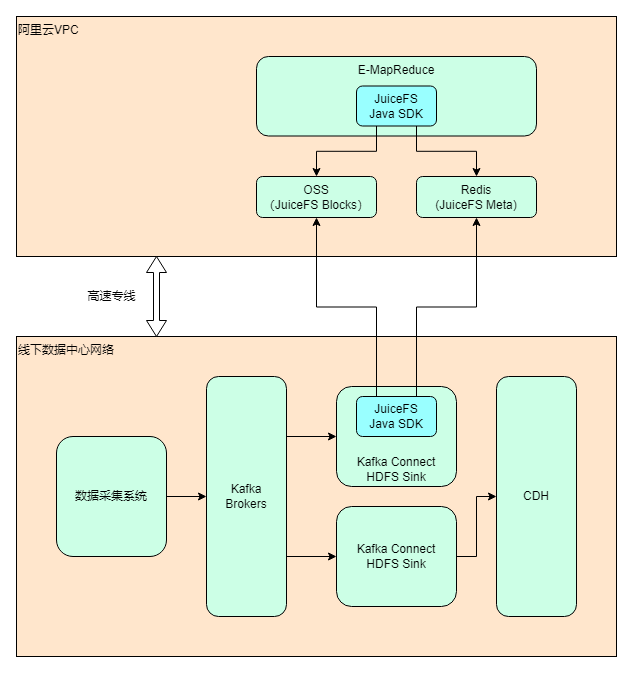
最终选择的方案是 使用阿里云 EMR + JuiceFS + 阿里云 OSS 来搭建存算分离的大数据平台 ,将云下数据中心的业务逐步迁移上云。截至目前(2022 年 7 月)整体迁移进度约 40%,计划在 2022 年内完成全部业务的搬迁,届时云上 EMR 的数据量预计会超过单副本 1 PB.
技术选型
首先是决定使用哪家云厂商。由于业务需求,AWS、Azure 和阿里云都有在用,综合考虑后认为阿里云最适合,有这些因素:
阿里云的 EMR 本身也有使用 JindoFS 的存算分离方案,但基于以下考虑,我们最终选择了 JuiceFS:
关于 JuiceFS
直接截取官方文档的介绍:
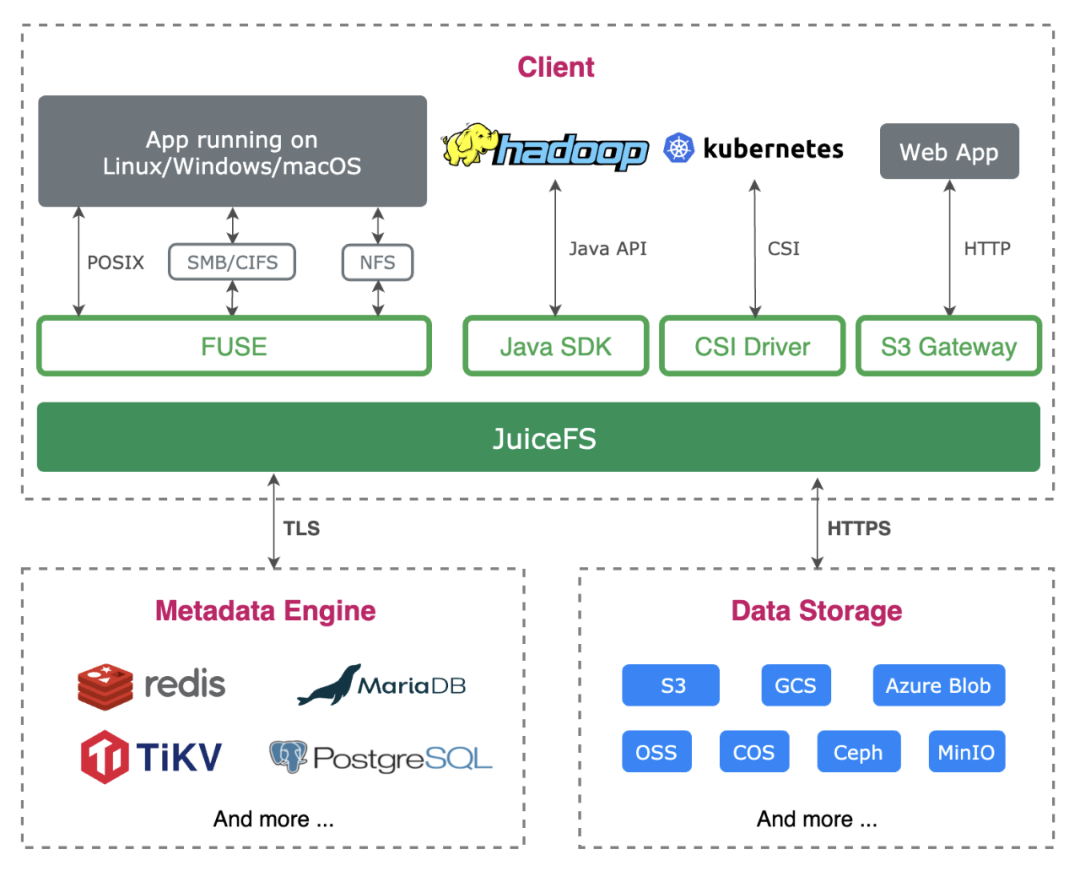
JuiceFS 是一款面向云原生设计的高性能共享文件系统,在 Apache 2.0 开源协议下发布。提供完备的POSIX兼容性,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。
JuiceFS 采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计。使用 JuiceFS 存储数据,数据本身会被持久化在对象存储(例如,Amazon S3),相对应的元数据可以按需持久化在 Redis、MySQL、TiKV、SQLite 等多种数据库中。
除了 POSIX 之外,JuiceFS 完整兼容 HDFS SDK,与对象存储结合使用可以完美替换 HDFS,实现存储和计算分离。
实施过程
我们在 2021 年 10 月开始探索 Hadoop 的上云方案;11 月做了大量调研和讨论,基本确定方案内容;12 月和 2022 年 1 月春节前做了 PoC 测试,在春节后 3 月份开始搭建正式环境并安排迁移。为了避免导致业务中断,整个迁移过程以相对较慢的节奏分阶段执行,截至目前(2022 年 7 月)进度约 40%,计划在 2022 年内完成整体的搬迁。迁移完后,云上的 EMR 集群数据量预计会超过单副本 1 PB.
架构设计
做完技术选型之后,架构设计也能很快确定下来。考虑到除了 Hadoop 上云之外,仍然有大部分业务会继续保留在数据中心,所以整体实际上是个混合云的架构。
部署和配置
基于以上考虑和配置对比,我们决定选用 ecs.i2.16xlarge,每个节点 64 vCore、512GiB Memory、1.8T*8 SSD。
经过一些测试,确认 JuiceFS 可以完美应用于 Kafka Connect 的 HDFS Sink 插件(我们把配置方式也补充到了官方文档)。相比使用 HDFS Sink 写入 HDFS,写入 JuiceFS 需要增加或修改以下配置项:
fs.jfs.impl=io.juicefs.JuiceFileSystemfs.AbstractFileSystem.jfs.impl=io.juicefs.JuiceFSjuicefs.meta=redis://:password@my.redis.com:6379/请参见 JuiceFS Java SDK 的配置文档。
hadoop.conf.dir=<core-site.xml所在目录>store.url=jfs://<JuiceFS文件系统名称>/<路径>PoC 的目的是快速验证方案的可行性,有几个具体目标:
期间做了大量测试、文档调研、内外部(阿里云 + JuiceFS 团队)讨论、源码理解、工具适配等工作,最终决定继续推进。
数据同步
要迁移的数据包括两部分:Hive Metastore 元数据以及 HDFS 上的文件。由于不能中断业务,采用存量同步 + 增量同步(双写)的方式进行迁移;数据同步完后需要进行一致性校验。
存量同步
对于存量文件同步,可以使用 JuiceFS 提供的功能完整的数据同步工具sync 子命令来实现高效迁移。JuiceFS sync 命令支持单节点和多机并发同步,实际使用时发现单节点开多线程即可打满专线带宽,CPU 和内存占用低,性能表现非常不错。
Hive Metastore 的数据同步则相对麻烦些:
因此我们开发了一套脚本工具,支持表和分区粒度的数据同步,使用起来很方便。
增量同步
增量数据主要来自两个场景: Kafka Connect HDFS Sink 和 ETL 程序,我们采用了双写机制。
Kafka Connect 的 Sink 任务都复制一份即可,配置方式上文有介绍。ETL 任务统一在内部自研的低代码平台上开发,底层使用 Airflow 进行调度。通常只需要把相关的 DAG 复制一份,修改集群地址即可。实际迁移过程中,这一步遇到的问题最多,花了大量时间来解决。主要原因是 Spark、Impala、Hive 组件版本的差异导致任务出错或数据不一致,需要修改业务代码。这些问题在 PoC 和早期的迁移中没有覆盖到,算是个教训。
数据校验
数据同步完后需要进行一致性校验,分三层:
数据校验的功能也封装到了脚本里,方便快速发现数据问题。
后续计划
大致有几个方向:
一手实战经验
在整个实施过程中陆陆续续踩了一些坑,积累了一些经验,分享给大家做参考。
阿里云 EMR 和组件相关
兼容性
性能
运维
JuiceFS 相关
作者简介 :
刘畅 ,一面数据运维负责人,十五年程序老兵,计算机原理、算法、编程爱好者。
李阳良 ,一面数据大数据部门负责人,九年互联网工作经验,对后台开发、大数据技术接触比较多。
引用链接
官方文档:
POSIX:
对象存储:
数据库:
在 Hadoop 中通过 Java 客户端访问 JuiceFS:
官方文档:
sync 子命令:
issue:
pull request:
IMPALA-10230:
CatalogObjects.thrift 文件:
IMPALA-10005:
IMPALA-10695:
修改操作系统的用户:
用户映射表:
JuiceFS + HDFS 权限问题定位:
JuiceFS IO 配置:
JuiceFS 故障诊断和分析 | JuiceFS Document Center: