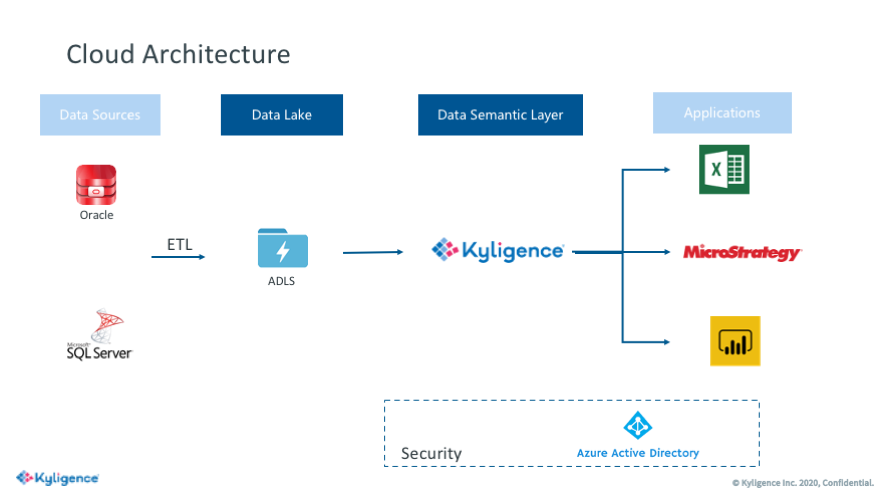
Apache Hadoop 于 2006 年第一次在 IT 领域亮相,承诺为组织提供以往商用硬件从来没能达到的强大数据存储能力。这一承诺不仅一举解决了数据集大小的问题,同时也让我们得以应对更多数据类型——包括物联网设备、传感器、服务器以及企业越来越关注的社交媒体生成数据。这种数据量、处理速度以及类型变化的总和,形成了我们当下最为熟悉的新概念——大数据。
在 Hadoop 的普及当中,schema-on-read 起到了至关重要的作用。企业发现,他们不再需要担心表内数据以及表间相互连接的繁琐定义流程——以往这类工作往往需要耗费数月之久,而且在此期间所有数据仓库都无法接受正常查询。在 Hadoop 带来的美丽新世界中,企业能够尽可能多地存储数据,从基于 Hadoop 的存储库(被称为数据湖)中获取数据,并考虑如何进行后续分析。
自此开始,数据湖广泛出现在企业运营环境当中。这些数据湖由商业大数据版本支持——一般通过单一平台提供独立的开源计算引擎。该平台能够为数据湖提供不同的数据分析方式。最重要的是,这一切都属于开源项目,可供企业免费试用!听起来前景一片大好啊,怎么会出问题?
问题出在 schema-on-read 身上
就像生活中的很多事物一样,Hadoop 受到广泛好评的核心优势,也逐渐成为其致命的弱点。首先,随着 schema-on-write 模式限制的解除,数以 TB 计的结构化与非结构化数据快速流入数据湖。由于 Hadoop 的数据治理框架与功能还没有完全成熟,因此企业发现其越来越难以确定数据湖内容以及数据之间的继承关系。此外,这些数据也没有做好接受消费的准备。企业开始对数据湖中的数据失去信心,最终数据湖变成了数据沼泽,这也意味着 Hadoop 当初提出的“构建即可消费”的架构读取理念遭遇失败。
Hadoop 复杂性与零散的计算引擎

第二,Hadoop 各发行版提供众多开源计算引擎,包括 Apache Hive、Apache Spark 以及 Apache Kafka 等等。但事实证明,这种丰富性本身也不完全是好事。一套典型的商用 Hadoop 平台当中可能包含多达 26 种此类引擎。这些计算引擎的操作非常复杂,需要由具备专门技能的人员将其“粘合”在一起。可以想见,市场上没那么多符合要求的人选。
关注点错误:数据湖还是应用
第三点,也是最重要的一点,数据湖项目开始失败,这是因为企业原本希望利用数据湖将所有企业数据存储在同一中心位置,以供全部开发人员随意使用。换言之,大家也可以将其视为一种超级数据仓库。但实际情况是,数据会对应用程序产生直接影响。因此,Hadoop 集群通常会成为企业数据流水线中的网关,其负责数据的过滤、处理与转换,而后将数据导出至其它数据库及数据市场以便传递至下游——这意味着预期应用方式与实际运营体系发生了冲突。因此,数据湖最终成为另外一组庞大的差异性计算引擎,其运行在不同工作负载之上,且所有负载都共享同一套存储系统。这令管理工作变得无比艰难,虽然生态系统中的资源隔离与管理工具确实在不断改进,但仍有很长的道路要走。而这一切复杂性,仅仅只是为了实现数据报告功能。
在大多数情况下,企业不希望把关注重点从关键任务应用程序那边,转移至数据湖这种本应充当廉价数据存储库与数据转移通道的方案身上。例如,Apache Hive 与 Apache Spark 是 Hadoop 数据湖领域使用最广泛的两款计算引擎。这两款引擎都拥有强大的分析能力——要么负责处理类 SQL 查询(Hive),要么执行类 SQL 数据转换并构建预测模型(Spark)。但很明显,这些数据湖并没有充分关注应用程序究竟是如何使用数据的。
战略进展
因此,如果您所在的组织关注 Hadoop 生态系统的最新进展,并且发现自己很难证明数据湖的实际价值,那么您应该首先关注运营应用程序,而后再反过来审视自己的数据。
通过对具有数据及智能元素的应用程序进行现代化升级,您终将能够利用数据预测应用程序中可能发生的未来趋势,并根据经验主动做出应对决策,最终获得卓越的业务成果。下面来看应用程序现代化战略中的五大基本要素:
从本质层面来看,如今的使用场景已经与当初的数据湖使用方式完全不同。通过新方式,能够利用数据湖资源的应用程序将更快为业务线提供真实可见的商业价值。
这种方法除了通过应用程序现代化帮助企业建立竞争优势之外,还能帮助大家继续保留原有数据湖投资组合。
最后,感兴趣的朋友也可以点击此处获取本份白皮书副本,其中详尽阐述了应用程序落后于数字化转趋势的五种迹象以及其它细节信息。
原文链接:
What Happened to Hadoop? What Should You Do Now?