本文主要介绍顺丰在数据仓库的数据实时化、数据库 CDC、Hudi on Flink 上的实践应用及产品化经验。文章主要分为以下几部分:
1 顺丰业务
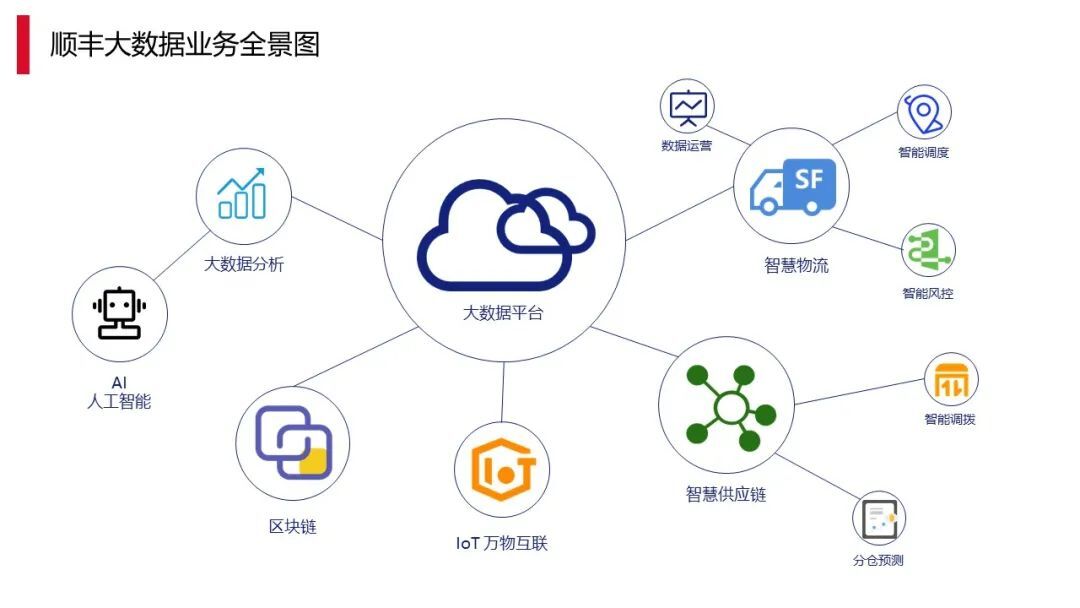
1.1 顺丰大数据的应用
先来看一下顺丰大数据业务的全景图。
下面这块就是 IOT 实践中的一部分:
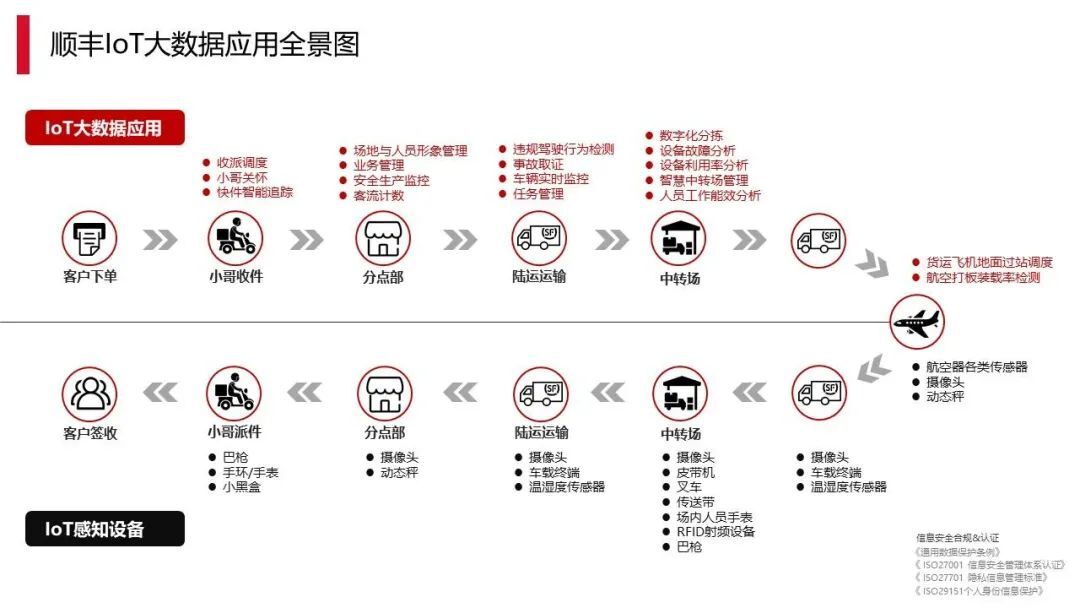
从上面可以看出物流本身的环节是非常多的,下单、小哥收件、分拣、陆运中转等整个过程,红色解释部分是指我们会做的一些 IoT 与大数据结合的应用,这里其实大部分都是基于 Flink 来完成的。
1.2 顺丰大数据技术矩阵
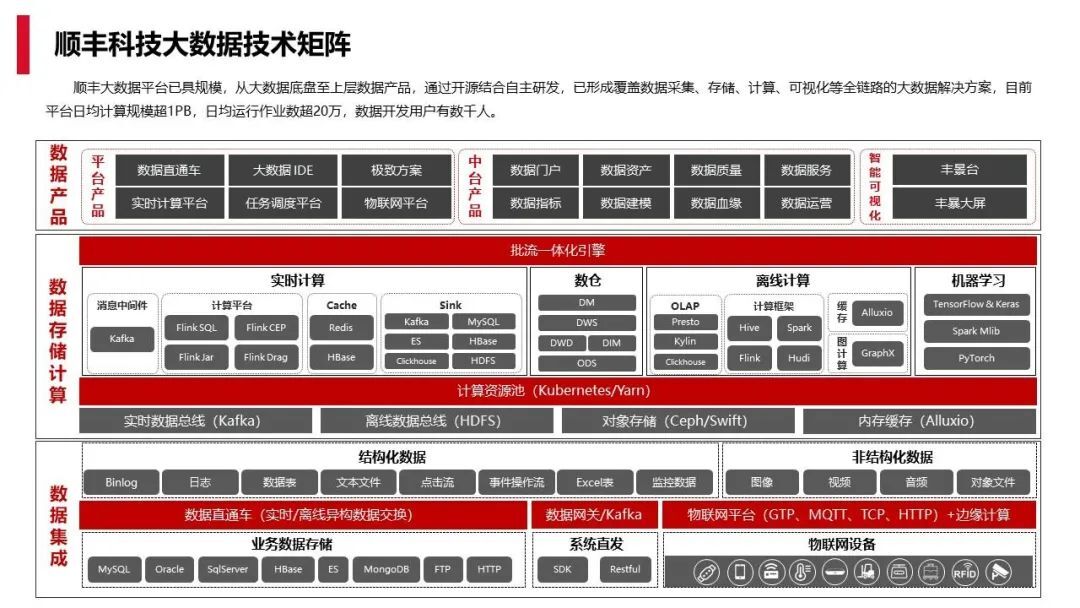
下面这张图是顺丰目前大数据整体的架构概览:
1.3 顺丰科技数据采集组成
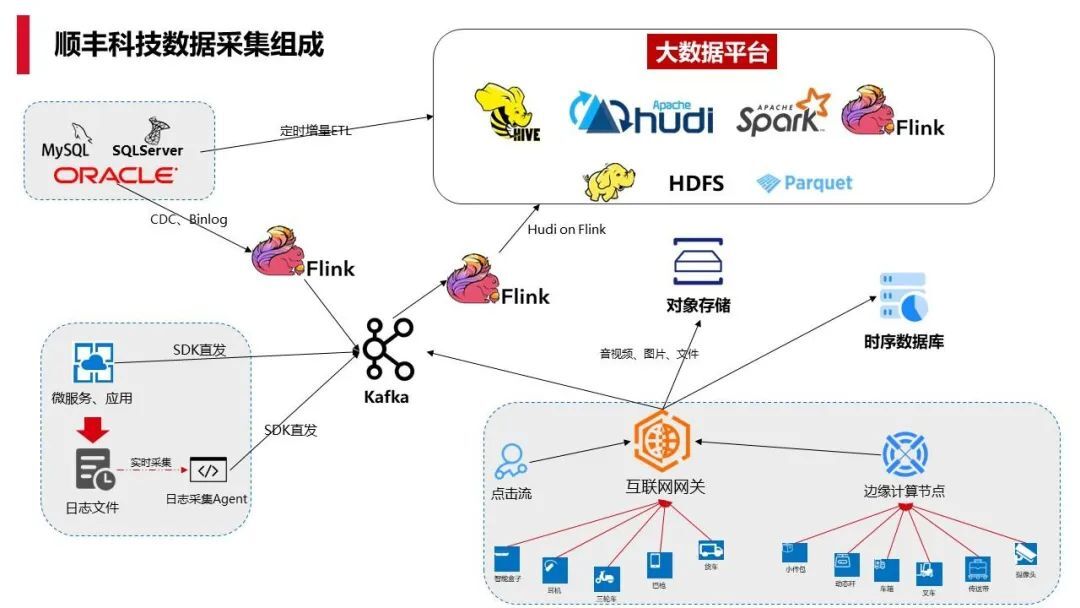
上图就是我们大数据整体数据采集的概览,数据采集当前包括微服务的应用,部分数据直发到 Kafka,还有些会落成日志,然后我们自己做了一个日志采集工具,类似于 Flume,更加的轻量化,达到不丢、不重、以及远程的更新、限速。另外我们也会将 Kafka 中的数据通过 Flink 放到 HDFS,以 Hudi 的形式去做。下面会详细介绍。
1.4 顺丰数据应用架构
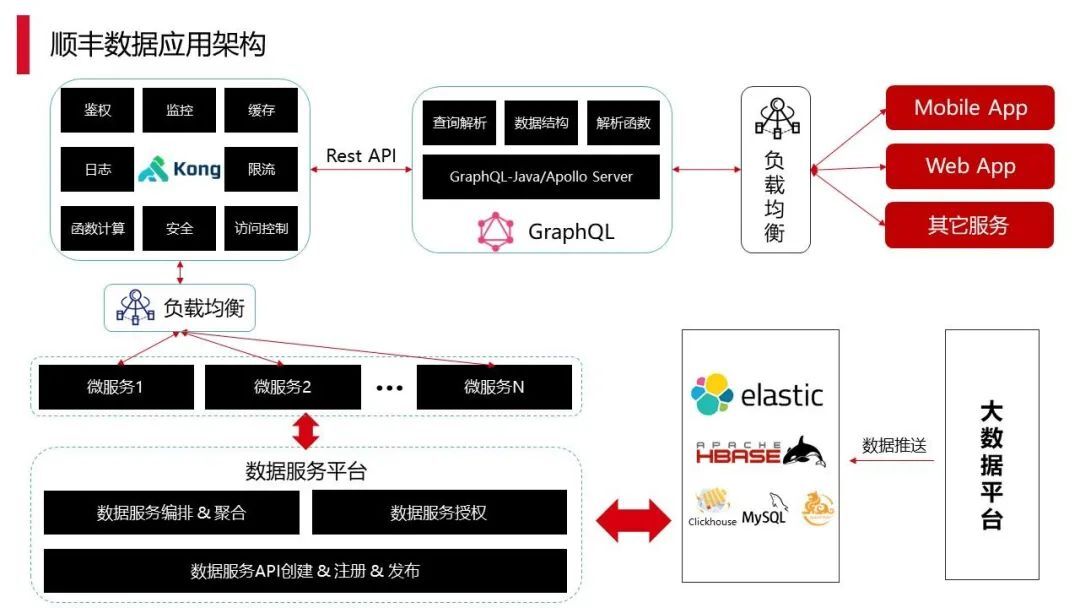
上图是一个简单的应用架构,刚才所说的大数据平台数据我们会按需推送到 OLAP 分析引擎、数据库,这部分数据推送过去之后,到达数据服务平台。该数据服务平台主要是考虑到用户或研发对接数据库更便捷,以往在使用时,内部用户首先需要了解大数据组件的使用,而现在通过我们的数据服务产品以配置化的方式配置查询条件、聚合条件即可,最终把结果生成一个 restful 接口,业务系统可直接调用。比如研发用户需要做搜索,只需要关注入参、出参,中间的过程不需要了解,这样的话就能够最大化的把技术门槛降下来,使用时也会更高效简便。
中间部分我们是基于 Kong 做的网关,在 Kong 里面可以加很多种通用的能力,包括监控、限流、缓存等都可以在里面完成。
右边的 Graphql,是 Facebook 开源的一个组件。前端用户经常会出现需求的变更,后台接口需要相应地进行调整,这种情况就可以使用 Graphql 来支持。这里其实是有两个东西:apollo、graphql_Java,两条线,apollo 适用于前端的研发用户,用 node_js 来完成控制层的内容;graphql_Java 适用于后端的用户,主要提供一些接口。
2 Hudi on Flink
2.1 Hudi 介绍
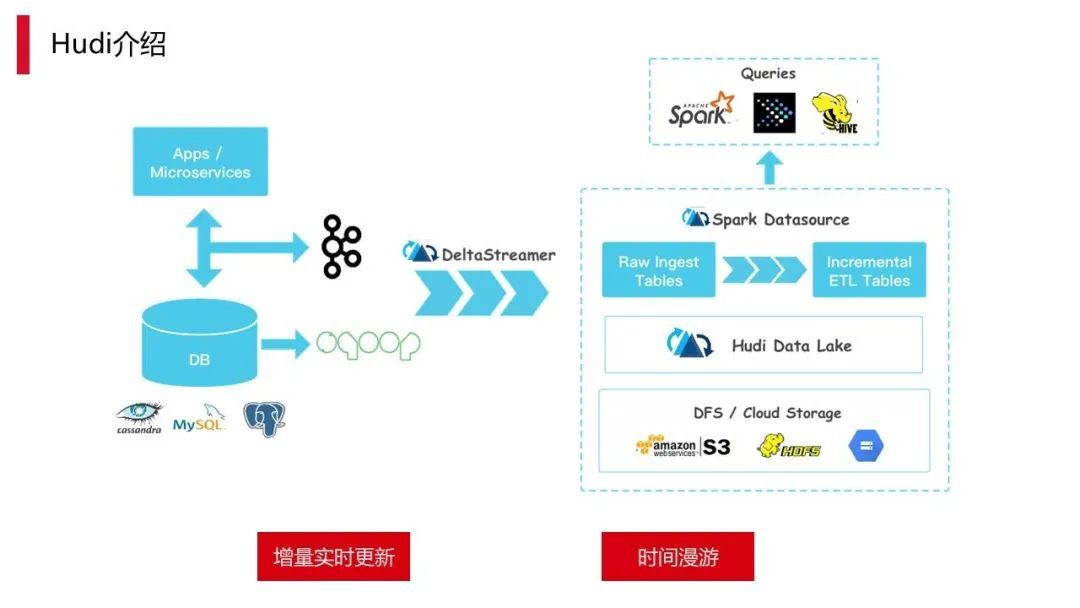
接下来我们主要介绍 Hudi on Flink 在顺丰的应用实践。Hudi 的核心优势主要分为两部分:
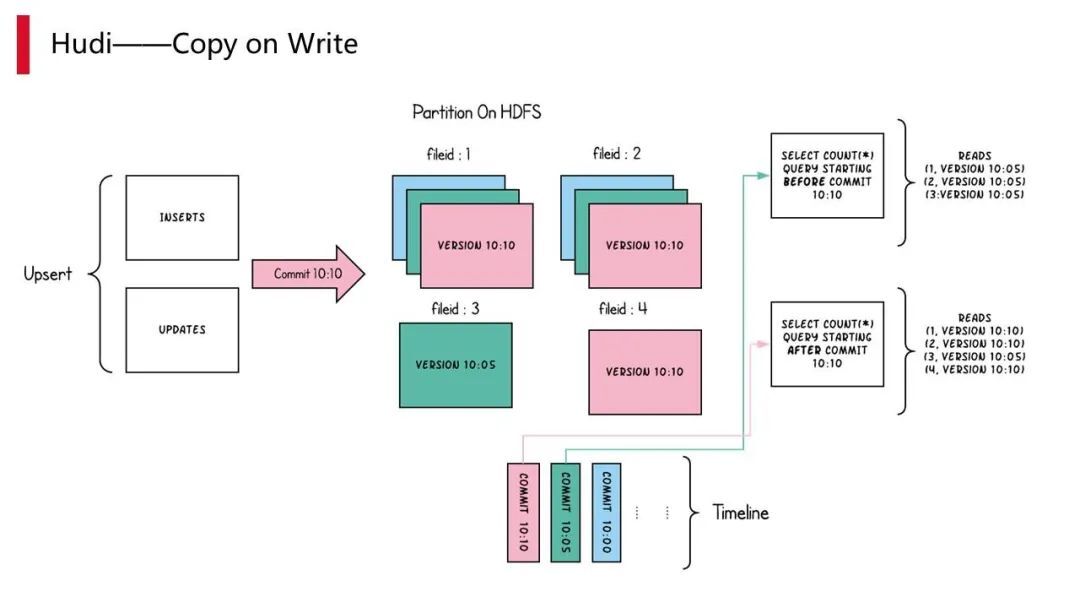
Hudi 有两种的写的方法:
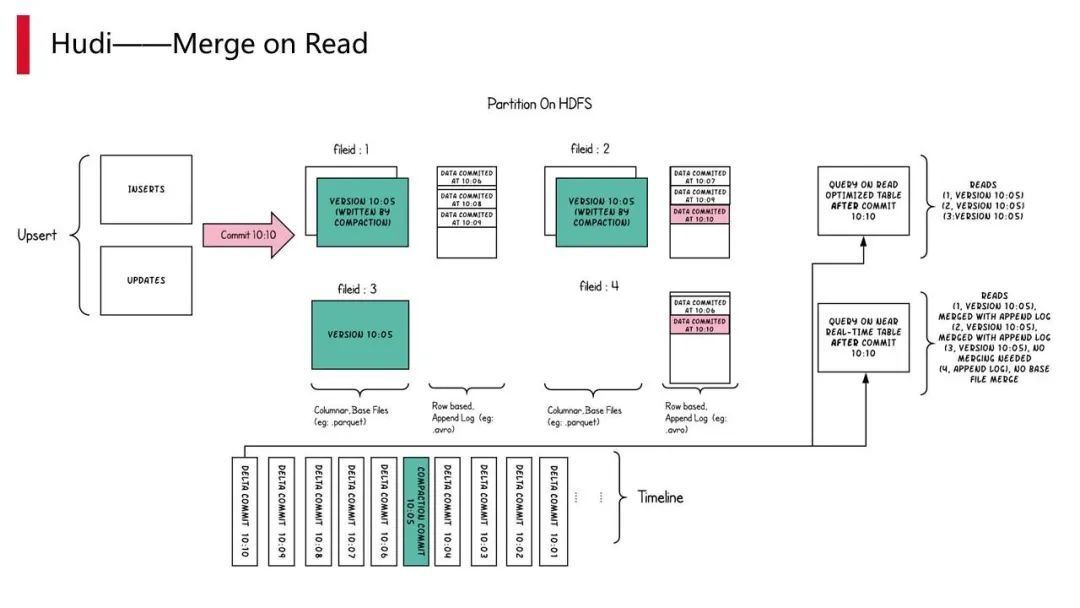
以上是 Hudi 情况的简单介绍。
2.2 Hudi on Flink 组成部分 - 数据库实时化
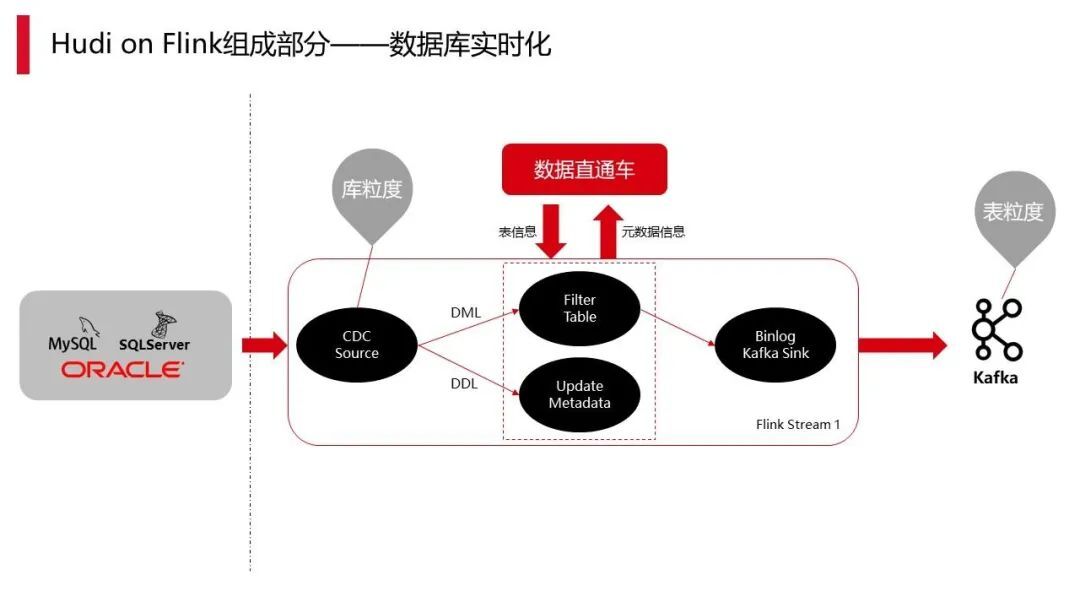
上图是我们将数据实时化 CDC 的过程。数据库的 CDC,基本上都是只能到库级别、库粒度。前面的 source 支撑肯定也还是库粒度,中间会经过两个过程:
2.3 Hudi on Flink 组成部分 - 数仓实时化
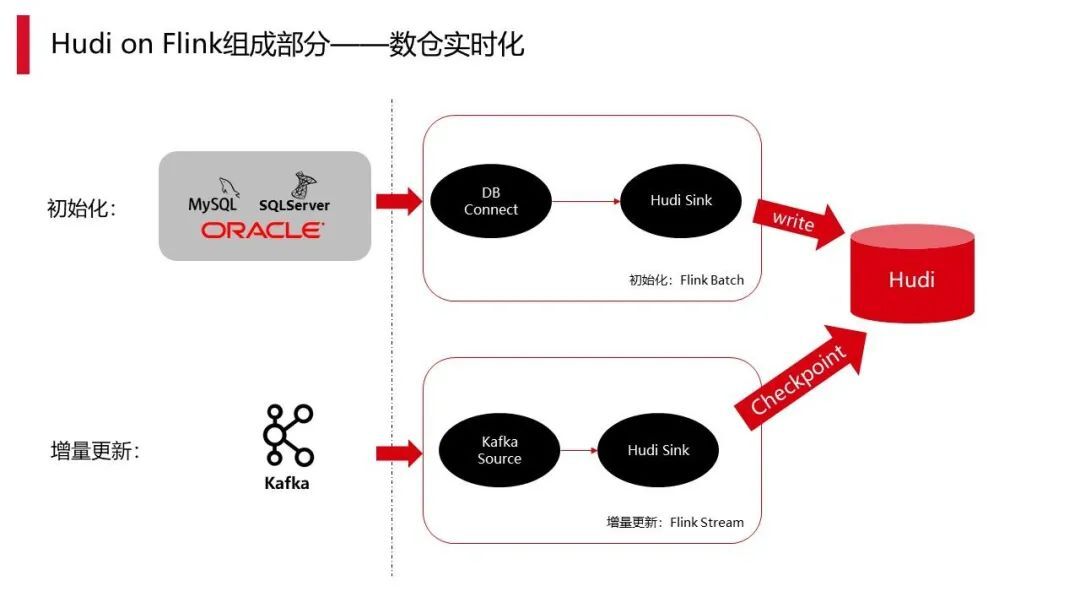
这部分主要分享我们数仓实时化的过程,我们的目标是实现 Kafka 里的数据在当前离线数仓中也能真正用起来,包括很多做准实时计算的用户也能够真正用起来。Hudi on Flink 就是我们尝试的方案。以前 Hudi 这块也做了 Hudi on Spark 方案,是官方推荐使用的方案,其实相当于多维护一个组件,但是我们大方向上还是希望所有实时的东西都能够让 Flink 去完成,另外也希望是 Flink 的应用生态能够做得更加全面,在这部分就真正去把它落地下来,并且在生产中应用起来。
其实整个过程,比如做表数据实时化的时候,它是分为两部份,一部分数据初始化,在启动的时候,会把数据重新做批量的拉取,这个是用 Flink batch 来做的,其实社区本身也有提供这种能力。另外 Hudi 本身也具备把存量的 Hive 表 Hudi 化的能力,这是 Hudi 最新才出来的功能。这部分我们会用 Flink batch 的方式重新抽一遍,当然也有存量,对于存量的一些表,可以直接用存量表来转化,然后用 Flink batch 做初始化。
另外一部分是增量更新,增量更新是指有个 DB connect 对接 Kafka,从 Kafka 的 source 拿到数据库增量 CDC 的 binlog,然后把 binlog 进行加工,同时再利用 Flink 本身的 checkpoint 机制(Flink 本身的 checkpoint 整体频率可以控制)进行 snapshot 的过程。其中所做的内容也我们自己可以控制的,所以采用 checkpoint 的形式可以把 Hudi 所需要做的 upsert 的操作全部在 checkpoint 中更新到线上,最终形成 Hudi 里面的实时数据。
2.4 Hudi 数仓宽表方案
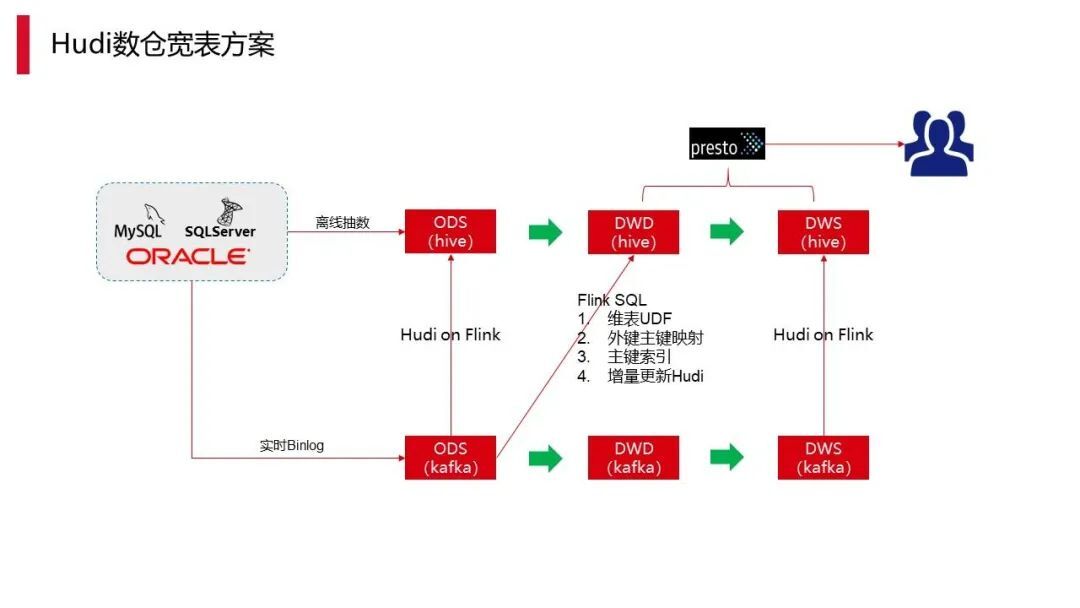
直接将 Kafka 数据扔到 Hudi 里相对容易,真正困难的点在于宽表。对于整个 Hudi 来说,宽表是涉及到很多维表,当很多维表或者事实表更新的时候,会由多个事实表做一个关联。但不是每个事实表都能抓到宽表的真正主键,因此 Hudi 没法做这种更新。所以如何把宽表做数据实时化是一个难题。
上图是顺丰的宽表方案。
当然,做维表关联,就涉及到外键主键的映射。外键主键映射是为了让我们能够在另一个事实表更新时,快速找到主键在哪,即外键主键的映射 。另外主键索引,主键索引其实也是跟外键主键的映射相关。至于外键主键的映射,相当于把它建成一个新的表主键索引获取,这样增量更新 Hudi 跟原来的 ODS 层就基本上一致了,这就是宽表实时加工的过程。下图为运单的宽表举例。

3 产品化支持
上述从技术层面分析了顺丰当下业务架构的相关情况,以下将分享我们在产品化上所做的一些支持工作。
3.1 数据直通车
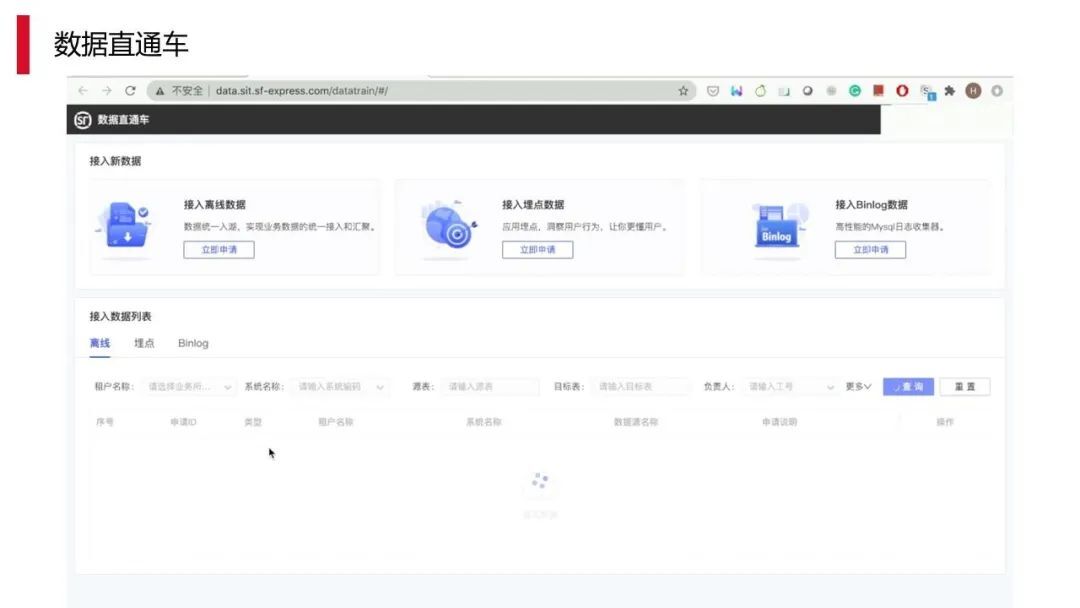
上图是我们的数据直通车,能够做到让用户自己在产品中操作,不需要写代码即可完成,可以实现低门槛的快速简便的应用。比如配置数据接入仅需 1 分钟左右,整个过程就是在产品上以配置化的手段就能够将数据最终落在数据库,我们的离线表、数仓、做数据分析都能够直接快速的运用起来。
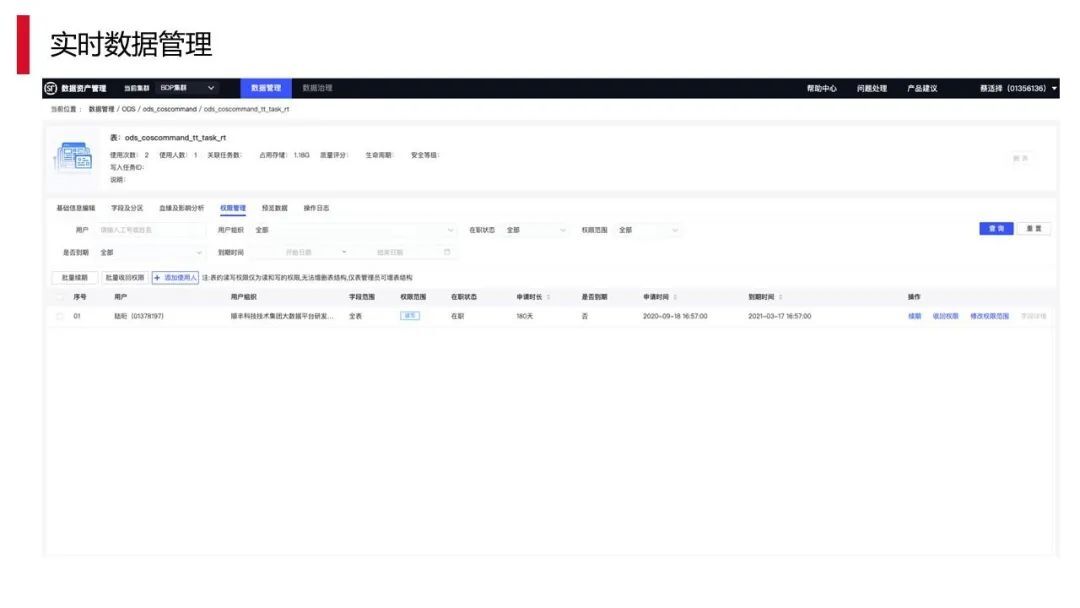
另外,数据接入进来之后,需要有数据管理的能力。上图是数据管理能力测试环境的简单情况,我们需要让用户能够管理相关的数据,首先谁用它了,其次它涉及什么字段,有哪些具体的内容,同时它里面的血缘关系又是怎么样的,这个就是我们数据资产管理所具备的功能。
3.2 实时数据使用
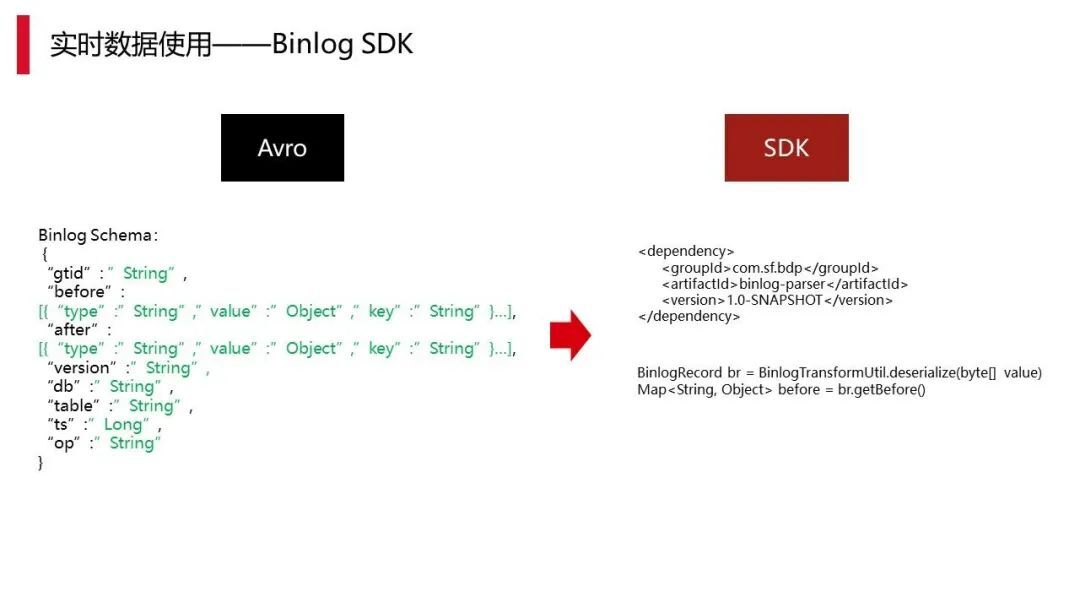
上图是我们 binlog 的 SDK,其实像 binlog 这种 avro 的格式,对用户来说使用有一定门槛。但还是有一些编码的用户,对于这些用户我们提供具体的 SDK,所以在 SDK 里真正使用时都做到简便。左边看起来是 json,实际上是 avro 格式。右边的内容就是在 Java 上的使用情况,这个是在代码层面辅助研发快速应用的工具。
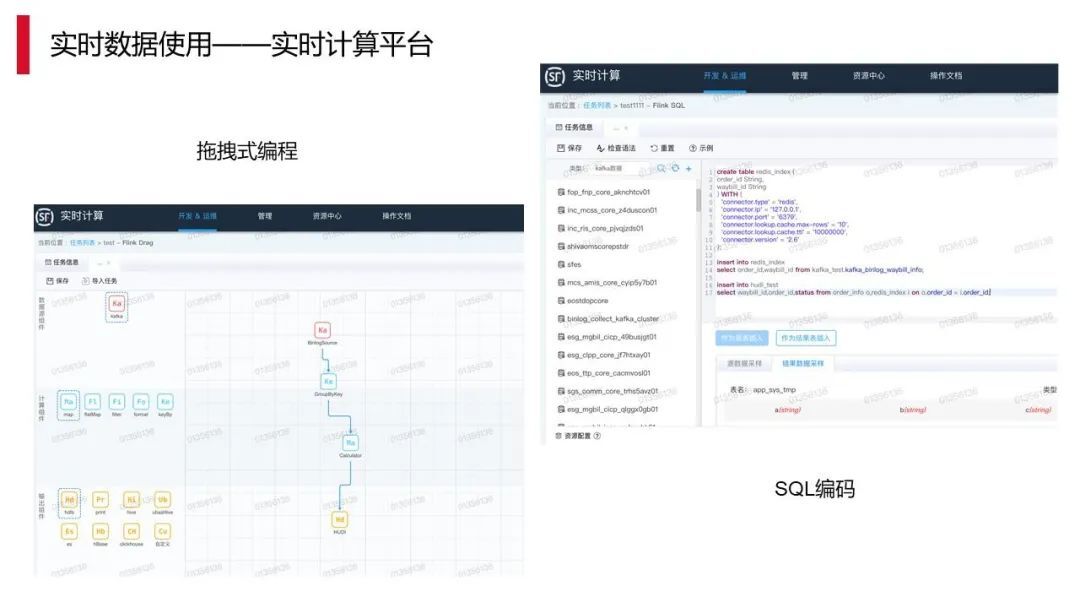
我们在平台上也做一些简化的内容,首先有一部分是关于拖拽的,拖拽是指封装一些组件,用户可以通过拖拽来快速完成其需求。这个产品上线后,很多之前没有任何实时计算的经验,甚至连离线开发的经验也没有的用户都能够做实时的数据开发。
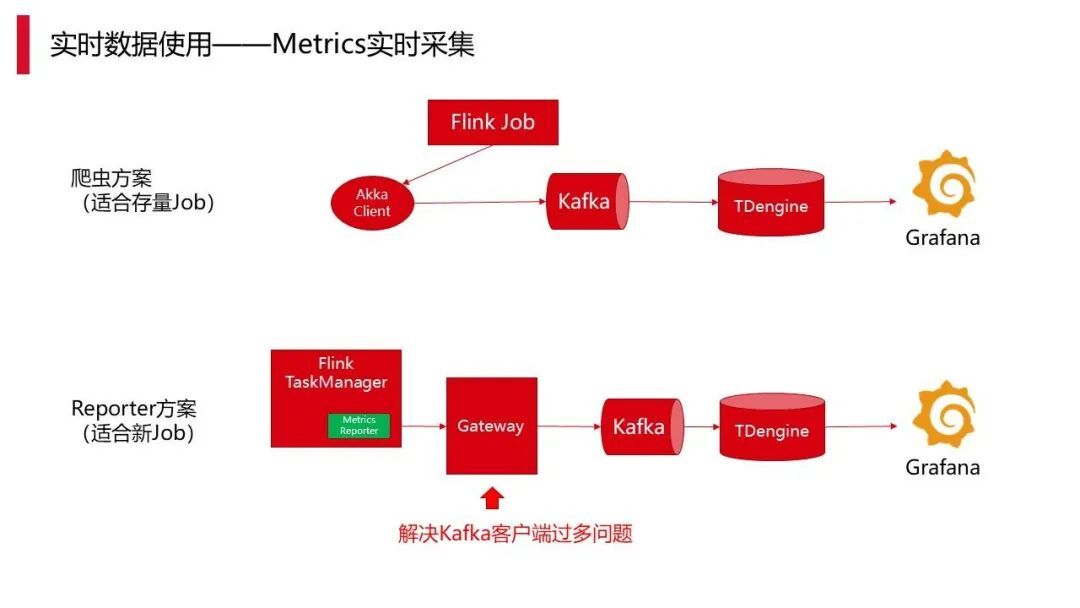
上图为实时指标采集,产品上线之后有很多监控的需求,Flink 本身提供很多 Metric,用户也有很多 Metric,我们希望为用户提供一个高效的解决方案,把 Metric 全部采集出来,让用户能够快速应用。
这里在监控里面也做了几个工作,一个是爬虫方案,实现一个 akka 的客户端,Flink 本身是 akka 的框架,每个 jobmannager 都有 akka 的服务、接口,这样只要实现一个 akka 的客户端,就能够以 akka 的 API 形式获取具体的 Metric 情况。这部分采集完之后发到 Kafka,最终存到 TDengine 再到 Grafana,提供给用户。Grafana 也会整合到我们的实时计算平台产品里面来,在面对存量的情况时,不需要重启用户的任务,就能够直接做数据采集。
但在面对增量情况时,就需要补充一些 Metric,比如 CPU 使用率、内存的使用率等。这部分我们以 Reporter 方案来满足,Reporter 方案也是社区当前主推的方案。Reporte r 方案的原理其实是在 Flink 的 Metrics Reporter 里进行插件开发,然后发到 gateway,这个 gateway 其实就是为了避免 Kafka 客户端过多的问题,所以这里中间做一个网关,后面还是和上面的一致,这个就是 Flink 的任务监控情况。
4 后续计划
上述已经分享了我们在内部已经落地、实际应用的过程,后续我们还会做什么?
4.1 弹性计算
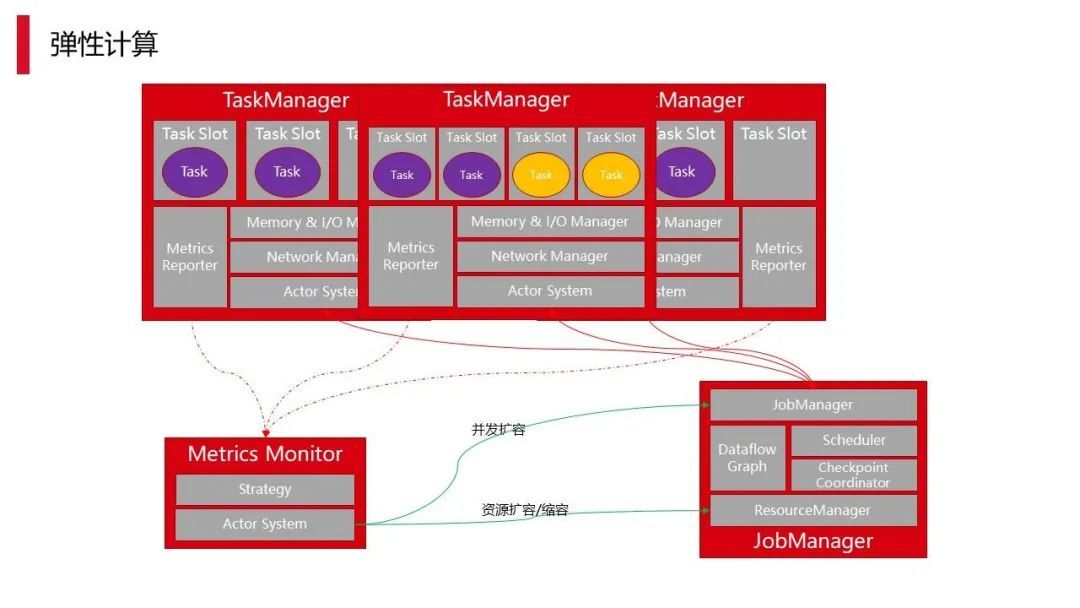
首先,弹性计算。目前像监控任务,用户申请的资源远远超过实际需要使用的资源,会造成严重的资源浪费,内存也一样。处理类似情况时,我们使用了 Flink 延伸的框架 Metrics monitor,结合采集的 Metrics,能够做到当整个使用率过低或过高的时候,及时调整达到资源扩缩容或者并发扩容。
4.2 Flink 替换 Hive 演进
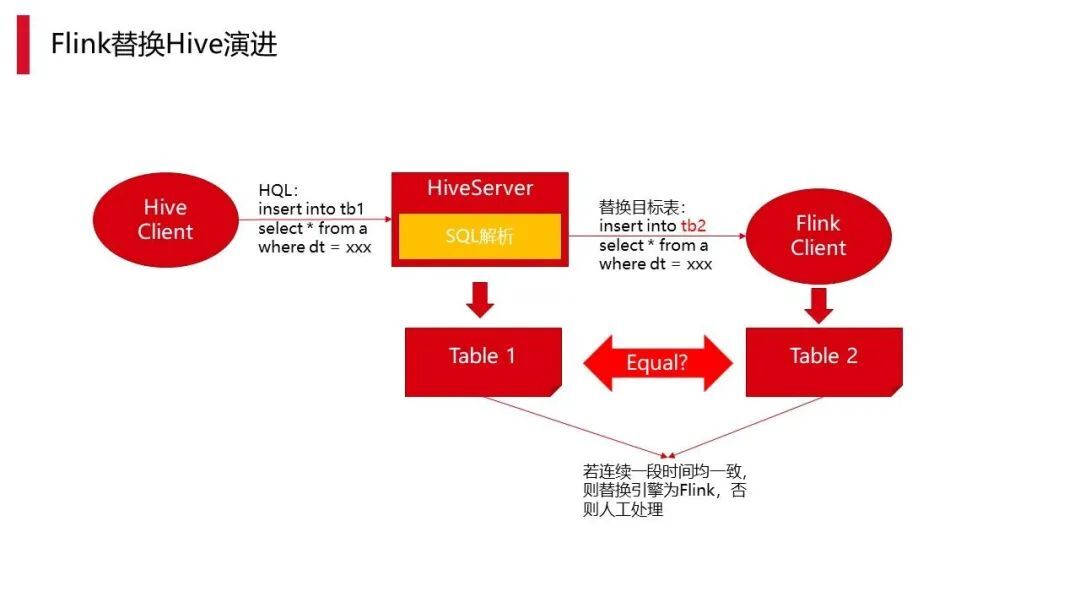
上面提到我们存量是有非常多的 Hive 任务,包括 Spark 任务需要进行替换,但怎么去做呢?
首先我们用 Flink 来替换,由于强制或平台自动推荐都有难度,所以我们做了一些折中方案。比如埋点,当需要把数据写到 Hive 的某个表,它会经过 Hiveserver,SQL 解析之后,此时将表进行替换,执行两个路线:一个是正常的 table 这样执行会写到 Hive 里面去。另外也会埋点把写的表替换成另一个表,然后同时再以 Flink 的形式去执行一遍,不过会产生额外的资源消耗,执行大概生成两个表,需要自动计算两者是否一致。如一致测试稳定后就能以计算框架来去替换它。
大部分任务是兼容的可替换的,但也有小部分不兼容的情况,这部分可以采取人工处理,以尽量实现整个技术上的统一,这部分是后续需要完成的。
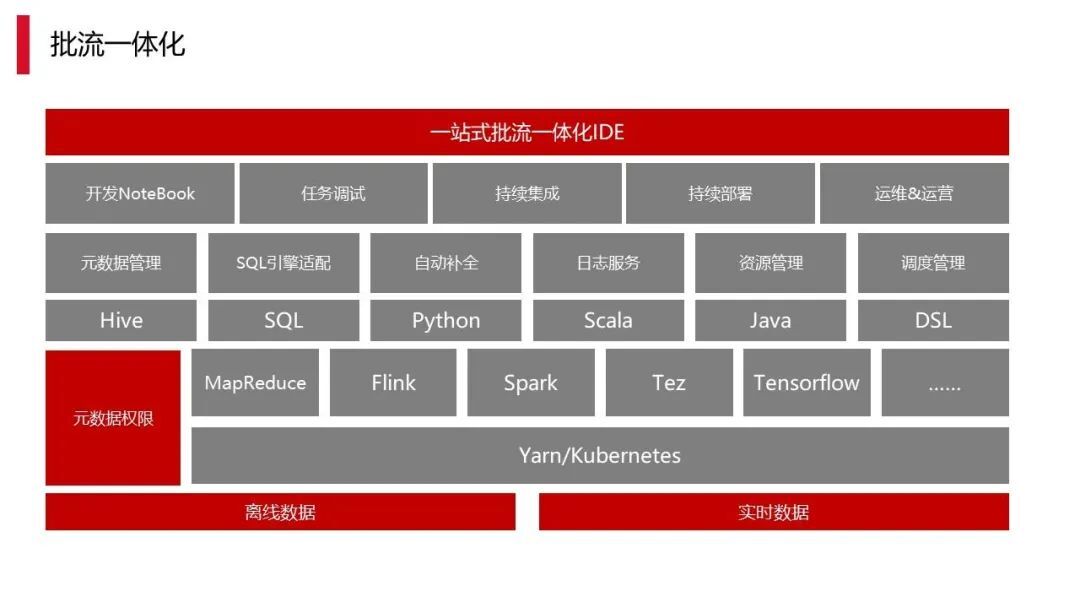
4.3 批流一体化
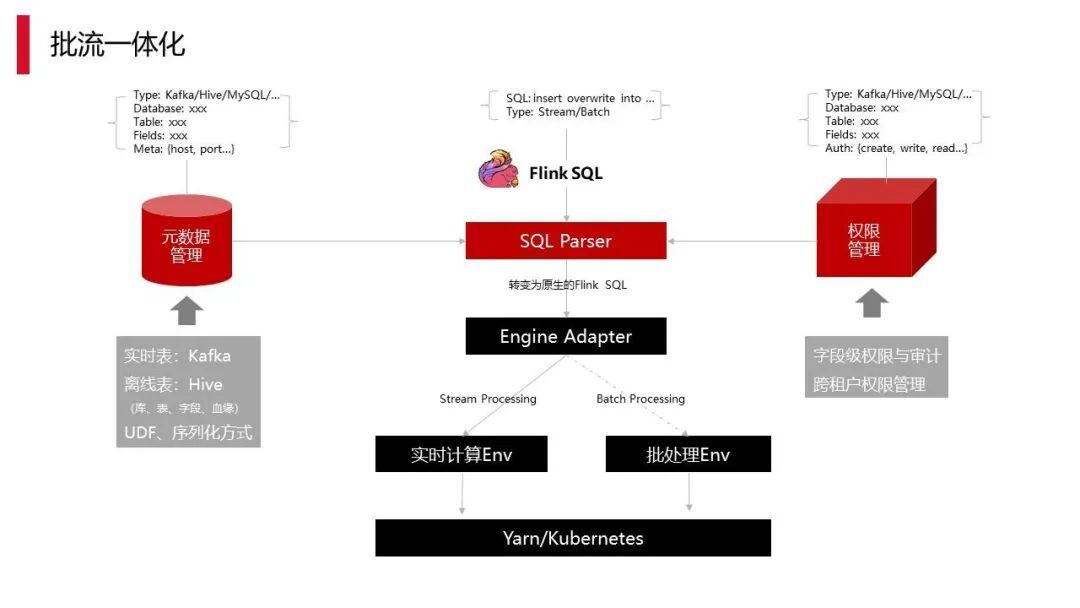
上图是我们做批流一体化的过程,批流一体化在元数据管理与权限管理部分都已经有一些落地。
除此之外我们结合刚刚所说替换的过程,上图就是 SQL 的兼容测试。因为这几者都做完之后,其实批流一体化可以同步去做,相当于同一个接口,加一个参数,即可实现流批处理底层引擎的快速切换,有助于整个数据开发能够保持一致,所以批流一体化也是后面需要尝试的。
上图实际上是我们一体化整个框架的最终形式。首先上面有一层 IDE 能够让所有的用户使用。然后下面各种基础功能支持,包括自动补全的 SQL 语法解析功能的支持,再往下就是一些资源管理、调度管理和知识管理,这些也是为了辅助开发而用的。再下面一层是计算引擎,要把这些计算引擎跟用户做一个大的隔离,让用户不用再关注底层技术的实现和使用,这是我们后面的要持续去做的事情。