引言
近来 FreeWheel微服务业务团队的业务逐渐扩大,单体服务已经无法胜任,于是我们如火如荼地开展了向微服务迁移的工作,一时间,服务如雨后春笋般冒了出来。在享受微服务带来便利的同时,我们也面临着众多服务带来的整体稳定性的考验。尽管我们有着完善的监控和报警系统,一旦故障发生,总是能第一时间通知到工程师来排查问题,但是这些都是事后的响应和应对。如何能提前了解系统可能会出啥问题,啥时候会出问题,出了问题怎么应对变得至关重要。混沌工程是帮助解决这一问题的不二选择,本文主要聊一下 FreeWheel微服务业务团队在混沌工程道路上的实践。
混沌工程是什么
通俗地说,混沌工程就是要在你的系统上进行混沌实验,根据实验结果分析来发现你的系统有哪些缺陷,然后对系统加以改进,如果有不可解决的问题,那么可以提前知道一旦发生怎么处理是损失最小的。通过不断的迭代实验来提高系统的弹性,不仅可以很好的给客户提供服务,还能够让各位工程师高枕无忧,减少半夜被叫起来处理故障的次数,最终帮助建立起稳定可靠的系统。
混沌工程是由混沌工程师来执行的,他们通过一系列的混沌实验,来学习观察系统的表现,并能通过此种表现去指导工程师来提高系统的健壮性。这有点像科学家通过做实验去学习定律,混沌工程师就是通过实验来发现系统的知识的。它跟传统的测试有很大的区别,传统测试会提前定义好输入和输出,如果不满足这个结论,测试就出错了,具有非常明确的目的;混沌实验不是如此,实验会产生什么样的信息是不确定的。比如整个网络延迟、CPU 过载、内存过载、IO 出错等等实验,会产生什么样的结果呢?有些我们可以预料,有些则不然,只有发生了,才会看到。
混沌工程发展史
纵观国内外互联网公司,都能看到混沌工程的影子,混沌工程也经历了 10 多年时间的演进。业内比较有代表性的就是 Netflix、阿里、PingCAP 和 Gremlin(Netflix 和 AWS 的混沌工程师创立的)。纵观这 10 多年以来混沌工程的发展,Netflix 占据了极其重要的地位。
国外大厂混沌工程的发展历程,主要是以 Netflix 为代表:
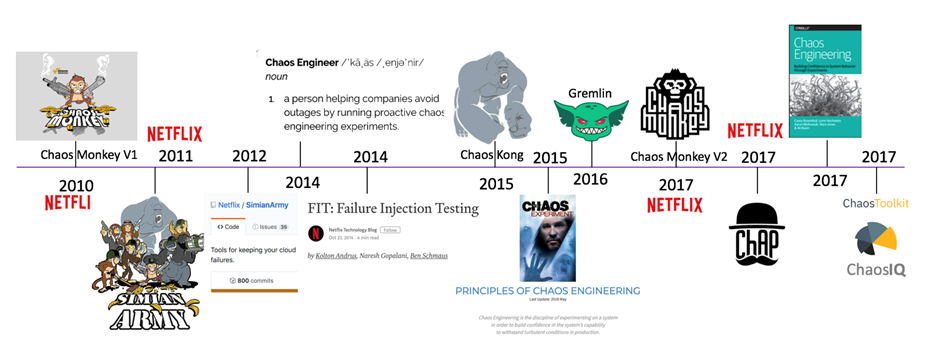
图来自 国内市场上混沌工程的发展还处于起步阶段,具有代表性的就是阿里和 PingCAP 这两家公司。相信随着云原生的发展,不断推进微服务的解耦,国内公司也会越来越重视起混沌工程。
混沌工程的原则和成熟度模型
尽管各家公司开发的混沌工程方案不同,但是都遵循了一套被大家认可的原则来指导混沌工程的发生。
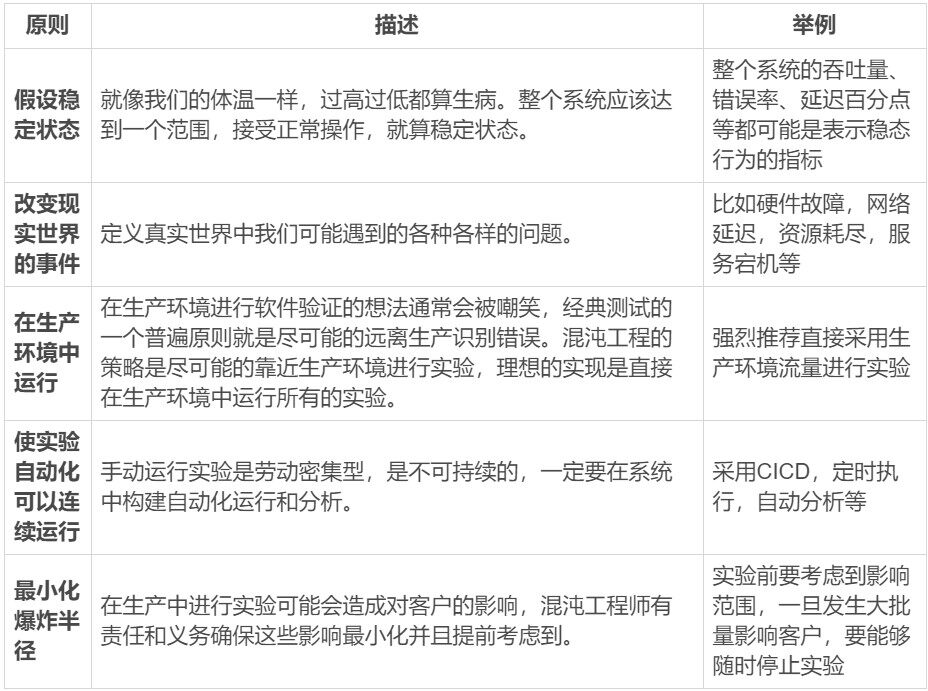
如何评判我们的实验做是好是坏,以及如何做得更好呢?混沌工程的成熟度给我们提供了一个可以参考的标准。成熟度有四个等级:初级,简单,复杂,高级。

在混沌工程工具的开发和混沌实验的进行中,要全面考虑这些原则和成熟度模型,做有用的实验,帮助工程师发现系统新的知识。
FreeWheel 微服务业务团队在混沌工程领域的实践
FreeWheel微服务业务团队在迁移微服务的过程中,微服务个数达到 30+。在这么庞大的一个服务体系,难以预料哪个服务会出问题,关注点也不再是哪个服务会出问题,而是转移到服务会在什么时候出问题、出了问题会对系统产生什么样的影响。
在寻找如何预测系统发生的问题及其影响时,我们发现混沌工程可以解决这个痛点。因此我们组建了 Chaos 小组,2020 年 4 月份立项并开始实现 Freewheel 微服务业务团队自己的 Chaos 系统,到目前为止,我们开发了 1.0 版本和正在进行的 2.0 版本。
初试牛刀
我们开发了什么
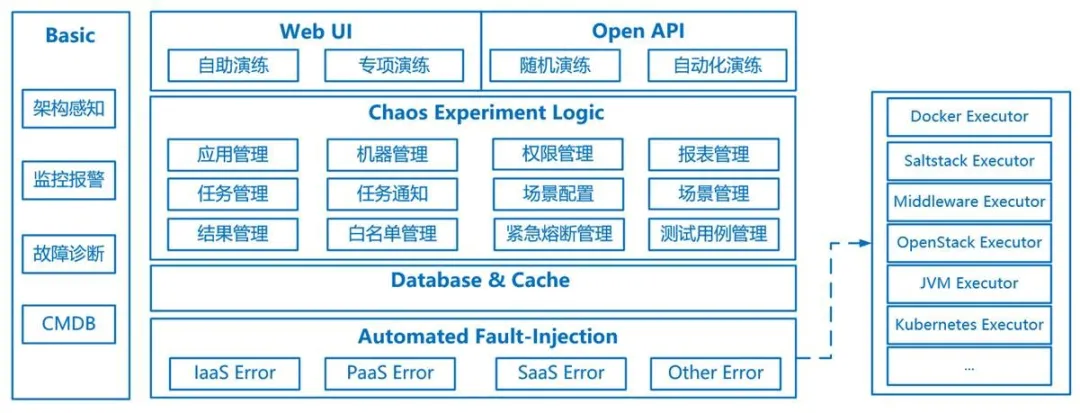
Chaos 1.0 是一个可插拔的系统,可以很方便的集成一些Monkey 到 Chaos系统,由三部分组成:Chaos Admin,Chaos Server,Chaos Monkey。Chaos Admin 主要负责跟用户的交互,混沌工程师可以通过其进行实验的开始和结束,Chaos Server 主要负责跟 K8S cluster 交互,负责搬运 Monkey 和执行 Monkey,Chaos Monkey 则是由一批可独立运行的工具组成。架构图如下:
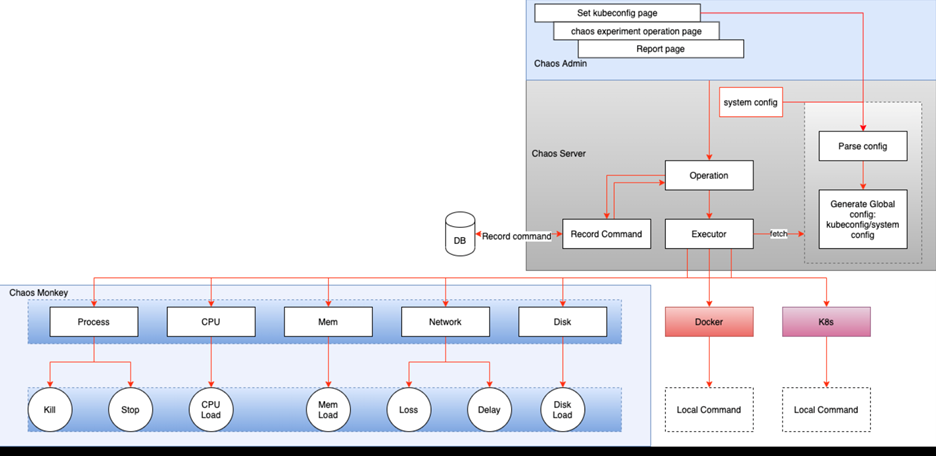
根据混沌工程的原则以及我们的业务特点,我们制定了 FreeWheel微服务业务团队使用 Chaos1.0 进行混沌实验的步骤:
Chaos1.0 的 Admin 部分交互非常简单,使用者可以选择要进行实验的微服务资源,然后进行实验。下面列举了一些我们利用现有的 Monkey 进行的实验。
我们做的实验
某一个服务在正常使用中,系统资源将近耗尽,会发生什么?
Target service 想知道当 CPU/Mem 占满时,是否还可以正常 serve 客户,于是我们对 target service 进行了 burncpu 的实验。我们发现,当 CPU 使用量上升时,target service 会自动扩容 POD,最高会扩容到 10 个来保证服务的正常运行。当 CPU 下降,Pod 会自动缩容到需要的个数。
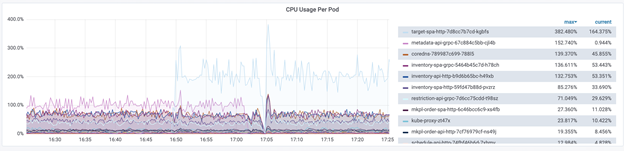
当系统资源全部占满,服务是否能正常工作?
Forecast service 想知道 CPU 占满的情况下,客户的请求是否还能在客户接受的范围,是否需要限流?
TPS=20 时,我们可以观察到,请求几乎可以在 3s 内返回:
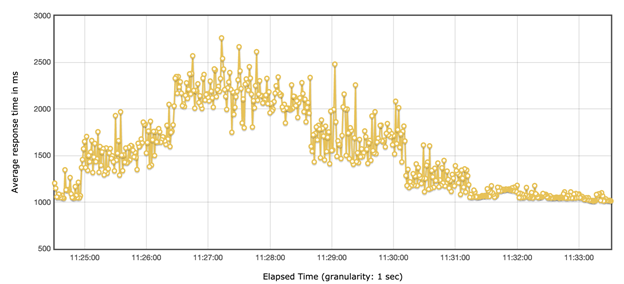
TPS=60 时,根据线上流量我们选取了这个值,我们可以观察到 90%的请求依然可以在 3s 内返回,接近 10%的请求会超过 3s。
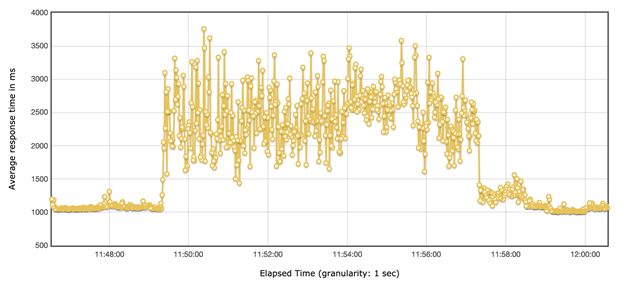
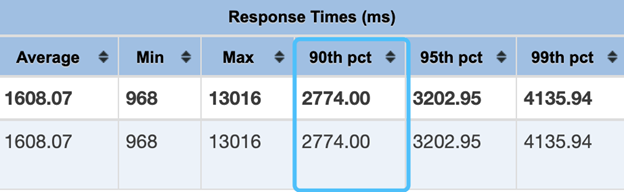
综上,我们发现 CPU load 很高时,如果要保证客户的体验,就需要对系统限流,限多少可以通过我们的实验得到一个基本值。
某一个服务在正常使用中,突然死掉,会发生什么?





系统架构演进
我们开发了什么
Chaos 1.0 中,我们的设计原则是可以很容易的接入各种 Monkey ,并且完全不需要部署到生产环境。在实验中我们发现这种方式会带来一些问题,各个 monkey 需要执行的环境和参数各不相同,导致实验的灵活度不够高,并且我们也体会到了不入虎穴、焉得虎子,不深入生产环境,有一些实验反而没那么容易做。所以在 2.0 中,我们学习了 PingCAP 公司的开源项目 Chaos-Mesh ,它的设计特别符合我们需求,基于此我们设计出了我们自己的方案。
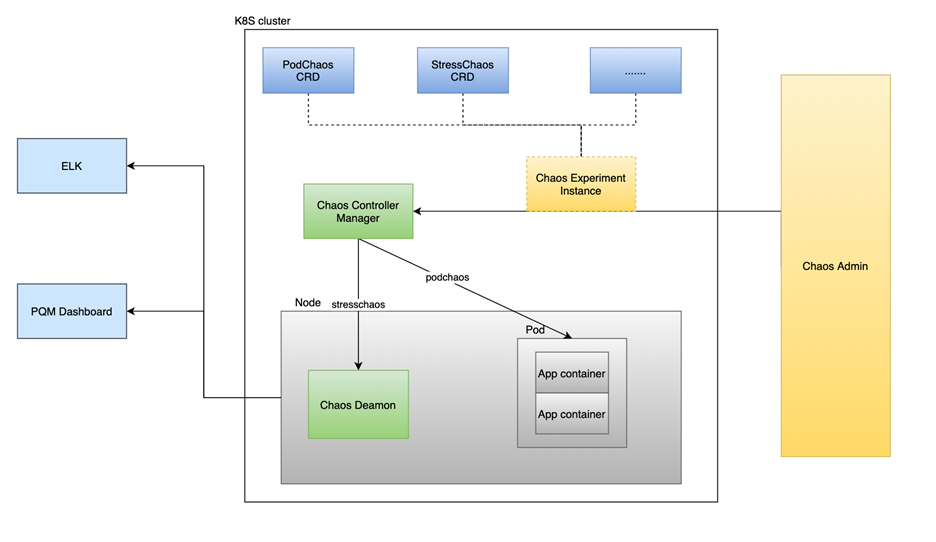
Chaos 2.0 中我们使用 CRD 来定义各个 Monkey,CRD 是 K8s 中比较成熟的解决方案,还有一些配套的工具可以很方便的帮助我们集成到 K8s 中,2.0 选择了 kubebuilder 来生成跟 K8s 融合的框架。
2.0 中我们设计了 PodChaos CRD、StressChaos CRD、NetworkChaos CRD,这三个是我们需求比较多的,尤其是 Network 方面的实验。2.0 目前的设计包含了 3 个部分:Chaos Admin、Controller Manager 和 Deamon。 Chaos Admin 跟 1.0 如出一辙,负责跟用户交互,帮助用户可以很方便的来执行混沌实验;Controller Manager 会根据 Chaos Admin 的指令来对 POD 进行直接操作或者来操纵 Deamon,主要负责跟 K8s 交互;Deamon 的功能主要是操纵 Container 以及 Container 里面的进程。
我们做的实验
Chaos2.0 目前处于开发中,我们做了一个 podkill 的实验。
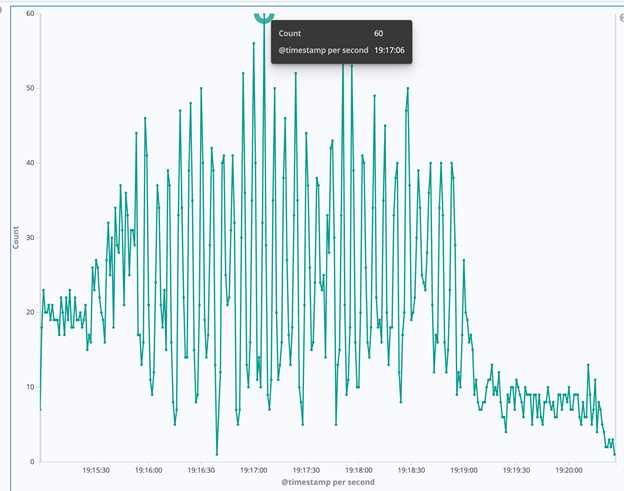
Advertising service 想知道如果随机的 kill pod,对客户的影响是怎样的?
PodNum=3,TPS=30,每 2 分钟随机 kill 掉一个 pod,pod 个数和 TPS 跟生产环境保持一致。
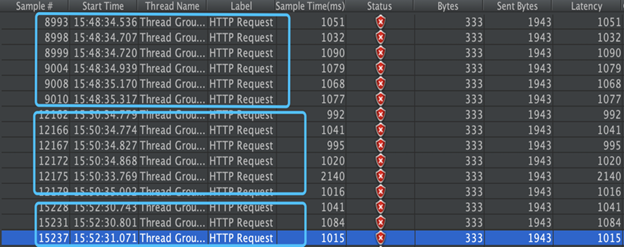
我们可以观察到,每当一个 pod 被杀掉的时候,大概会有 5-6 个 request 会失败。
目前 Chaos2.0 还在继续研发,后续还会进行各种实验来挖掘我们系统的知识。
未来之路
Chaos 系统终归是为产品质量服务的,所以无论我们处于哪个阶段,使用什么样的技术手段,我们的初心始终不变——建成一套自动化的混沌工程平台,通过混沌实验来提高系统的稳定性,可用性等,进而达到提高产品质量的目的,使得工程师和客户都可以受益。
未来我们会朝着这几个方面努力:
1.完善目前的工具和平台,通过我们的 Chaos 系统能够完成更多的实验,达到最终可以自动化分析实验结果;
2. 集成我们的系统到 CI 中,使得混沌实验不再是按需执行,而是周期性的常态化执行;
3. 持续关注业界最新的 chaos 发展,不断演进我们的平台。
作者介绍
南开大学计算机硕士,曾在国内一线互联网公司担任核心系统的开发工作,目前就职于 FreeWheel 核心业务开发团队,有丰富的开发和技术管理经验,目前研究方向是混沌工程,热衷于新技术的探索和分享。
延伸阅读:
《gRPC长连接在微服务业务系统中的实践》
《一个微服务业务系统的中台构建之路》