摘要:经过一年多的努力,我们为 Uber 的试验和特性标记生态打下了坚实的基础,相关的一切都已经转移到了新系统上,包括 2000 多名开发人员、集成的超过 15 个合作伙伴的系统、10 多个移动应用、350 多个服务。我们弃用了 Morpheus 中超过 5 万个过时的试验。
简介
“在劣质数据上费力进行计算,也许可以将收益从 95% 提高到 100%。5% 的收益,总数也许并没有多少。但在时间和人力成本相同的情况下,对收集过程或是试验设计来一次能力范围内的彻底整改,经常可以将收益提高 10 到 12 倍。在试验结束后咨询统计学家,就好比要让他做尸检。或许他可以告诉你死因。但是,为了利用他在这方面的经验,就必须诱导他发挥想象力,让他可以提前预知其中的困难和不确定性,如若不然,他的调查也会困难重重。”(R. A. Fisher 在第一届印度统计学大会上的主席致辞)尽管 A/B 测试的统计学基础已有百年之久,但在规模很大的情况下,构建一种正确可靠的 A/B 测试平台和文化仍然是一项巨大的挑战。按照 Fisher 的上述观点,仔细构建 A/B 测试平台的构建块,确保收集到的数据都是正确的,对于保证试验结果的正确性至关重要,但这个过程很容易出错。Uber 经历过一段类似的旅程,本文就是介绍我们为什么以及如何重建 Uber 的A/B 测试平台。
Uber 有一个名为 Morpheus 的试验平台,是 7 年多以前构建的,兼具特性标记和A/B 测试功能。从那时开始,Uber 就在范围、用户、用例等方面对 Morpheus 做了大幅扩展。
2020 年初,我们在深入观察这个生态系统之后发现,有很大比例的试验存在致命的问题,经常需要重跑。要想获得高质量的结果,就需要对试验和统计学有专家级的理解,还需要完成大量艰辛的工作(自定义分析、管道化等)。这会降低决策速度,而且经常需要重新运行效果不佳的试验。
在评估了用户问题和 Morpheus 的内部结构后,我们得出结论,其核心抽象所能支持的试验设计非常有限,即使与这些设计的差异很小,也会导致对照组(control group)和试验组(treatment group)的用户无法对比,对试验结果产生不利的影响。举一个非常简单的例子,在逐步推广一个对照组用户和试验组用户三七分的试验时,由于推广和试验组分配逻辑的特殊性,推广到 10% 的用户没有问题,但推广到 5% 的用户就不行。此外,该系统无法支持 Uber 多样化的用例所需要的高级试验配置,或其他大规模试验所需要的高级功能,如监控 / 回滚对业务指标产生负面影响的试验。因此,我们决定用恰当的抽象从头开始重新构建一个平台。
我们要在系统中实现什么目标?
我们的目标是让公司可以敏捷地、高质量地运行各种试验。
高水平的质量保障
在公司中,试验系统的作用是通过提供试验结果的可信洞察来为决策赋能。为此,一个好的试验系统应该始终提供正确的结果,保证:
Morpheus 的工作方式使它只适用于简单的试验,除此之外就很难保证结果是正确的。加之 Uber 的试验要求多样而复杂,这导致很多数据有问题,造成了巨大的浪费:人工调查和分析以及重新运行试验都很常见,这会拖慢开发速度,并分散对其他优先事项的注意力。有时,试验结果有问题,却没有人意识到。
新系统应该提供有保证的正确结果:无论用户选择什么样的试验设计,任何人都可以相信试验结果,不需要自定义的验证,也不需要对统计学的深刻理解或对平台的详细了解。
除了统计学上的正确性,系统可靠性也是试验平台所必须的,因为那是公司运营中非常核心的内容。我们现有的试验系统是 7 年多以前开发的,当时是作为软件栈中的一个可选依赖。然而,多年来,特性标记已成常态,试验系统成为移动应用和后台服务的必备依赖。用户思维发生了这样的转变,但系统却没有及时跟进。当后台没有响应时,客户端就会因为故障自动关闭,导致所有移动应用和后台服务都因试验栈的故障而严重瘫痪;多年来,我们已经多次遇到过这样的故障。我们希望,新系统能提供适当的保护措施,以确保 Uber 的服务对试验系统的故障有很好的容错性。
高水平的用户生产力
最终用户主要通过移动应用来使用 Uber。但 Morpheus 的性质使我们很难在这些应用上进行试验。在 Morpheus 的编程模型中,试验组是在客户端代码中指定的(见下图)。因此,试验的修改(如新增一个试验组或修改现有的试验组)需要一个构建 - 发布周期,这会把我们的速度拖慢 2-4 周。为了解决这个问题,我们希望尽可能地将试验与代码变更解耦,以便创建 / 删除 / 修改试验时可以不用等待移动应用构建 / 发布。此外,我们希望简化客户端接口,并对客户端隐藏试验配置和服务的复杂性。
图 1:试验感知伪代码
第二个问题是,在 Uber 快速发展期间,我们的配置栈出现了碎片化。我们有一个针对试验和移动特性标记的配置系统,还有一个针对后端配置和后端特性标记的软件。移动和后端用户工作流完全隔开了,使得同时涉及移动和后端服务的试验很难做,我们需要付出双倍的努力来添加与安全 / 合规等相关的特性,而且,由于系统的细微差别所导致的问题也很难调试。此外,碎片化意味着更高的维护成本。
第三,试验分析的局限性成了数据科学家最大的辛苦之源。构建这个分析生态系统只是为了支持用户随机试验。对任何新的随机化单元做分析都需要自定义管道和设置,使得管道在不同的组织出现了多种变体,导致了不一致。分析中使用的指标也没有标准化。用户使用他们自定义的指标,不同的组织有不同的指标,无法横向比较。领导层很难推断和比较各组织的试验影响情况,甚至很难对跨组织的试验做出一致性的评价,然而,随着 Uber 成为一个业务线交叉的统一平台,这种需求却越来越常见。此外,由于该系统在生成对照组 / 试验组时经常会出现系统性的不平衡,所以进一步开发分析功能并不可行(例如,我们以前尝试开发过监控试验负面影响的功能,那从一开始就注定要失败)。
灵活支持多样化的试验设计,匹配 Uber 的各种产品开发需求
虽然有一些试验用例可以通过将分组比例固定为 50/50 来解决,但许多用例都需要更复杂的设置。新系统设计的一个关键需求是支持 Uber 遇到的各种用例,并能满足未来的潜在需求。
除了上面提到的功能,新的系统设计应该能够满足未来广泛的扩展需求,而且不需要进行大的架构调整。
架构
在这一节中,我们将介绍新平台架构的核心概念。
参数——将代码和试验解耦
图 2:配置驱动的 A/B 测试伪代码
利用参数将代码和试验解耦。客户端(移动或后端)代码不会引用试验名称或试验组,而是根据参数值生成分支。参数总是会有一个安全的默认值(通常相当于“对照”路径),以确保在没有重写值或由于网络问题而未能收到重写值时,客户端可以顺畅运行。
试验被设置为在后端重写参数的值。参数是客户端唯一可见的概念——可以在后端设置任意数量的试验,为给定的参数或参数集提供不同的值,但客户端并不知道这些试验的存在。根据调用期间传递的上下文,不同的客户端可能接收到不同的参数重写值。后端服务根据上下文向客户端传递参数值,与参数值分支相关的客户端代码就会执行。如果试验人员确定需要一个与起初完全不同的试验设计,那么他们只需禁用当前试验,并使用相同的参数设置一个新试验——不需要修改代码。同样,在旧试验结束后,可以使用相同的参数运行新试验以测试新想法。
上图展示了客户端和服务器之间的调用流,以及参数和试验之间的关系。
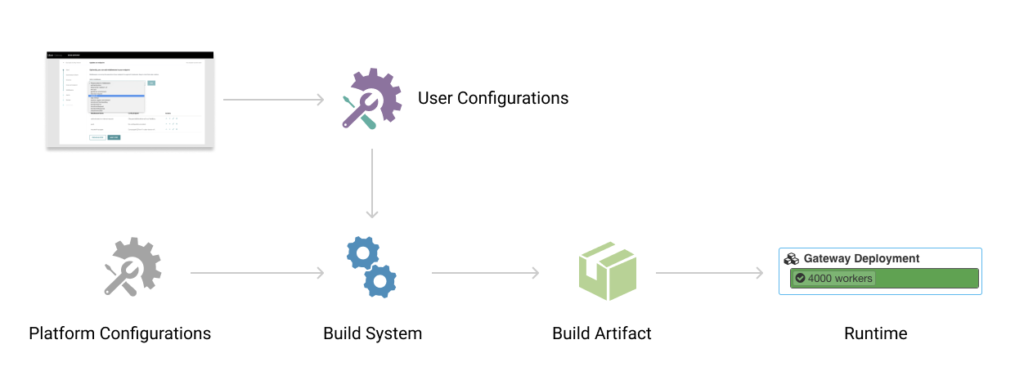
统一配置和试验栈
图 3:统一 A/B& 远程配置架构
我们选择将试验构建为 Flipr 之上的一个覆盖层。Flipr 是 Uber 的后端配置系统,其中存放了参数,如果要基于参数运行一个试验,就可以自动调用试验系统获取参数的重写值。要不然就使用默认参数值。这一决策将移动端、后端和试验配置全部统一到了一个系统中,提供了重用支持,统一了开发工作流,使得跨不同端面(surface)运行试验变得简单了。
试验
我们的试验系统只基于一个概念,即试验(experiment),完全没有其他结构:没有单独的保留结构(holdout constructs)、流量分割器、层 / 域等。更复杂的试验功能可以以试验为基础构建出来,如下所述。
试验的核心包括 3 个关键组成部分:
随机化
试验基础:我们需要一些随机的东西,和试验单元、环境或其他任何信息都没有关系;这种随机性有助于我们区分,在其他条件完全相同的环境中,针对其他条件完全相同的试验单元所采取的行动。
在特定的试验中,我们使用一个由试验键值决定的盐对单元标识符进行散列,从而随机化单元。试验键值是唯一的,这就可以保证,只要 Uber 的其他系统没有使用相同的散列逻辑,所有试验经过随机化后都是彼此独立的。
更具体地说,在我们的构建中,单元的桶(bucket )为该单元的哈希值与试验中指定的特定模数(通常为 100)的整除残差。从结构上看,单元的桶在给定的试验中永远不会变,而且很容易复制。
试验组是多套桶。在实践中,我们将所有试验组组织成一棵树,树中的每个节点(试验组)都是一组范围连续的桶。例如,在一个将单元分成 100 个桶的试验中,根节点是 all_units,桶为 [0…99],可划分为 control[0…49] 和 treatment[50…99]。试验组可以根据需要进一步拆分,例如,可以将 treatment[50…99] 分为 t1 [50…59]、t2 [60…69] 和 t3[70…99]。
图 4:试验组分配
拆分试验组的能力让我们能够设计更复杂的试验,在试验执行过程中并入更改(例如,在试验运行时将控制体验反馈给更多的用户)。
试验计划
试验计划规定了在每种上下文中对每个试验组做什么。
上下文(Context)是我们所掌握的关于一个试验单元的知识,包括地理信息,如用户所在的城市或国家,设备特征,如操作系统(iOS 或 Android),以及其他在试验评估时可能用到的信息。
在我们系统中,行动(Action)就是我们返回的参数值,即受试验影响的参数(一个试验有一个或多个受影响的参数)。
例如,我们可以考虑在旧金山运行一个和特定按钮颜色有关的试验。在这种情况下,试验将声明基于参数 button_color 进行操作,与 context.city = San Francisco 匹配的对照单元 button_color = green,同一上下文下的试验单元 button_color = black。所有不在旧金山的单元,按钮会有一个默认的颜色,可以是绿色、黑色、蓝色或其他任何颜色。
上下文的某些方面也可以随机生成:例如,为了逐步推广试验,我们使用(伪)随机生成的推广桶,其中,推广随机化与试验组分配无关。
相同参数的多个试验
作为试验计划的一部分,试验人员可以声明试验需要捕获上下文空间的哪些部分供其专用,以及哪些部分可以用于运行相同参数的其他试验。这样,就可以在不同城市、不同设备操作系统或其他需要的上下文子集上独立运行不同的试验,只要相同参数的试验不存在重叠即可。我们利用一个自定义的逻辑引擎,在配置时检测是否有两个影响相同参数的试验存在重叠,只要不重叠,就可以创建或更新试验。
日志记录
要想具备强大的试验分析功能,正确的数据不可或缺。试验日志的目标是找出该单元什么时候第一次暴露在给定是试验中——例如,单元处于这样一个情况:在不同的试验组中为单元提供了不同的参数值。实现方法是在访问被试验重写的参数时发出日志消息。在一个分布式系统中,要知道哪是第一次暴露并不容易,所以我们会在每次访问参数时发出日志消息,并稍后在数据管道中对这些日志做去重处理。
在单元所处的上下文中,如果所有试验组指定的参数值都相同(即单元体验没有差异),则不会发出日志消息。这样做的原因是,如果体验没有差异,也就不会有需要评估的影响,所以就没必要记录日志了。最后,日志发送对客户端代码来说是透明的。
虽然日志记录的理念很简单,但在工程上,要保证任何日志数据都不丢失是一项不小的挑战,尤其是在规模很大(远大于每秒 1M 条消息)的情况下。我们需要仔细优化和组织日志记录代码,尽可能避免未向用户提供体验却记录了数据的情况,反之亦然。但是,一旦记录了数据,基于日志对试验做实际的分析就完全与服务和配置层解耦了。只要配置和服务层记录并提供试验组分配外生的单元簇(cohorts),分析就可以以此为基础,专注于从有效的试验中获取最大价值。
正确性
虽然正式阐述系统特性超出了本文的范围,但值得注意的是,在这里介绍的架构中,无论用户选择什么样的试验设计(配置),所有的试验组都可以相互比较——除了实际的效果之外,它们之间不会有系统性的差异。只要在第一次接触到有差别的体验之前(这在我们的系统中就是返回有差别的参数值),描述上下文和 / 或决定分析中包含哪些单元(例如,第一条日志)的任何东西都独立于试验组分配,就可以保证这一点。
参数约束
上一小节介绍了试验是什么。我们如何在这个简单的结构与复杂的分层设计之间架起一座桥梁呢?答案就是参数约束。
试验可以把城市位置或设备操作系统作为其试验计划的约束条件(例如,试验只在美国的 iOS 系统上运行),类似地,它也可以将其他参数作为该逻辑的一部分。例如,用户可以选择只在满足约束条件 parameter_a == true 时运行试验。鉴于参数可以由试验来控制,这就为各种有细微差别的设置打提供了可能,满足了现实世界的用例——由于试验是随机化的,而且相互独立,即使试验设置很复杂也没问题。唯一的限制是,要避免循环依赖(确保依赖图是一个 DAG)。
以下是参数约束支持的部分用例:
数据管道泛化
考虑到新增随机化单元是一个常见用例,我们将管道设计成了通用的,不对随机化单元做任何假设。试验日志以及管道为所有随机化单元生成的数据都相同,包括:试验键值、unit_id、单元暴露于特定试验的时间戳、单元暴露时传递的上下文、访问的参数名,以及一些杂项元数据。所有分析库也都是对这些通用数据进行分析,而不对管道层中的单元做任何假设。只有在分析时,用户才会选择与该单元相关的指标来连接底层数据。保持管道通用的决定使得引入新的试验单元变成了简单的配置更改,并且无需任何更改就可以利用其余的基础设施和管道。
分析引擎泛化
Morpheus 提供了一个生成和查看分析结果的 UI,但后台的统计分析程序包是用 Scala 编写的,并且隐藏在服务中,这使得数据科学家很难使用这个包进行自定义分析,导致统计分析工作重复进行且不标准。
在新系统中,我们将统计分析程序包构建成了一个 Python 程序包,并构建了一个 UI 分析层来调用这个包。我们在内部与数据科学社区分享了这个 Python 包,因此,数据科学家可以用它在 Jupyter 笔记本中做探索性分析,或者用它进行在 UI 层难以实现的深层次分析。虽然 UI 层已经能够支持大多数分析用例,但通过 DS 原生工具链提供相同的分析引擎,使有能力的用户可以进行更复杂的分析,也加深了用户对系统工作机制的了解。
为了支持团队各种各样的试验分析需求,我们提供了高度灵活的按需分析,让用户可以回答有关其创新效果的细粒度问题。
每项分析都由两个关键部分组成:要分析的单元簇(cohort )和分析该单元簇时使用的指标。
单元簇是一项特定分析所聚焦的单元集合。我们为以下两种单元簇定义提供了广泛的支持:
对于 Uber 乃至整个行业运行试验来说,有日志单元簇分析可能是更标准的方法。它让用户能够准确关注受试验影响的单元,通常提供的结果比较精确。
另一方面,无日志单元簇分析为我们提供了一种分析试验的备用方法,可以在因为中断及其他问题导致部分日志丢失时使用。它还提供了一种方法,让我们可以分析不同试验中单元簇的试验结果。这样的分析可能不那么强大,但在我们的架构中,却是非常健壮。
为了支持细粒度的洞察,我们为用户提供了很大的灵活性,让他们可以划分单元簇和指标。
本质上讲,单元簇可以根据单元首次进入试验之前定义的任何数据进行划分;这让我们能够提供对比结果,诸如对 iOS 和 Android 用户的影响比较、对新用户和现有用户的影响比较,同时保证,即使进行了单元簇细分,不同试验组之间的单元簇仍然具有可比性。
对于给定的单元簇或单元簇的某一划分,也可以利用指标维度对指标进行细分,因此,我们可以评估 UberX 和 UberXL 对完成行程的影响。由于通过 uMetric 进行了指标标准化,试验中报告的对指标的影响,与世界各地的团队所依赖的报告仪表板中的指标,计算方式是一致的。
可靠性:SDK 和参数值回退
鉴于移动端和后端开发都非常依赖试验系统,我们希望这个系统在可靠性上能有大幅提升,以消除我们之前看到的一类影响非常大的中断事件。为此,我们做了很多工作。
首先,如前所述,参数总有一个安全默认值。对于移动应用,这个默认值是随移动应用本身一起提供的。对于后端服务,默认值是由 Flipr 在本地(在主机上)提供的。这样,在出现网络故障或延迟的情况下,就有一个值可以保证客户端运行在安全的代码路径上。
其次,我们为 Uber 使用的所有语言(Go/Java/Android/iOS/JS/ 等)和客户端(Web/ 移动 / 后端)构建了 SDK。移动端 SDK 会缓存从后端接收到的前一个有效负载;如果出现问题,移动应用会回退到这个缓存,如果缓存不存在且后端不可用,则它们会回退到默认值。对于后端,如果试验不可达或出现超时,客户端会回退到 Flipr 默认值(在本地提供)。这种多层回退显著提高了可靠性。
第三,SDK 会在体验分叉之前自动发出试验日志。自动记录日志消除了手工记录日志带来的麻烦和缺陷。随着时间的推移,我们已经对 SDK 做了大量的优化(缓存 / 删除 / 日志批处理等),这让所有的试验用户无需额外付出任何努力就能从中受益。
第四,SDK 支持一个名为参数预取的特性——提前获取一批参数以降低延迟,但要到稍后访问它们时才会发出日志(将获取与日志记录解耦)。这就解决了这样一种用例:正在试验的特性对参数访问延迟很敏感,但在用户流的早期对延迟不那么敏感。在需要显示特性之前支付延迟成本,在实际需要时提供对参数的即时访问——并在那个时间点自动发出日志——可以提供响应式的用户体验和准确有效的试验。
挑战及经验总结
小结
经过一年多的努力,我们为 Uber 的试验和特性标识生态打下了坚实的基础,相关的一切都已经转移到了新系统上,包括 2000 多名开发人员、集成的超过 15 个合作伙伴的系统、10 多个移动应用、350 多个服务。我们弃用了 Morpheus 中超过 5 万个过时的试验。
下一阶段,我们将致力于构建许多特性,以提高可用性、用户体验、性能、自动化监控、自动化推广,以及我们总体的试验能力,并将产品更快地提升到下一个等级。我们会在未来的博文中分享更多的细节。敬请期待!
缺少软件开发文化,大众汽车陷入困境,CEO 也被赶下了台
我庆幸果断放弃了 SwiftUI:它还不够成熟
英伟达回应“对中国断供部分高端 GPU”;月薪 3.6 万工程师日均写 7 行代码被开;12 年黑进 40 多家金融机构老板赚百万获刑 |Q 资讯
在阿里达摩院搞了四年数据库,我来聊聊实际情况 | 卓越技术团队访谈录