灵犀科技有限公司(简称灵犀科技)是奇点控股旗下的高科技企业,专注于为企业提供 SaaS 服务、定制化决策工具、智能匹配交易平台以及开放的大数据生态系统。灵犀科技深耕于企业产业分析,积累了大量相关信息,基于这些数据构建了独特的产业链结构,向政府和企业提供精准拓客服务,助力产业升级与招商。
灵犀科技早期基于 Hadoop构建大数据平台,以 Hive、Clickhouse、Starrocks 搭建离线数仓,Flink、Redis 搭建实时数仓。2023 年随着公司的战略调整和需求扩增,数据处理效率、查询性能、资源成本问题随之出现。 为了快速应对业务的发展需要,灵犀科技引入 Apache Doris 搭建了集存储、加工、服务为一体的统一架构,有效解决上述挑战,实现存储成本下降 60%,计算效率提升超 10 倍 的显著成效。
早期架构及痛点
基于 Hadoop 体系的大数据平台架构如下图所示,分为实时及离线两条数据处理链路:
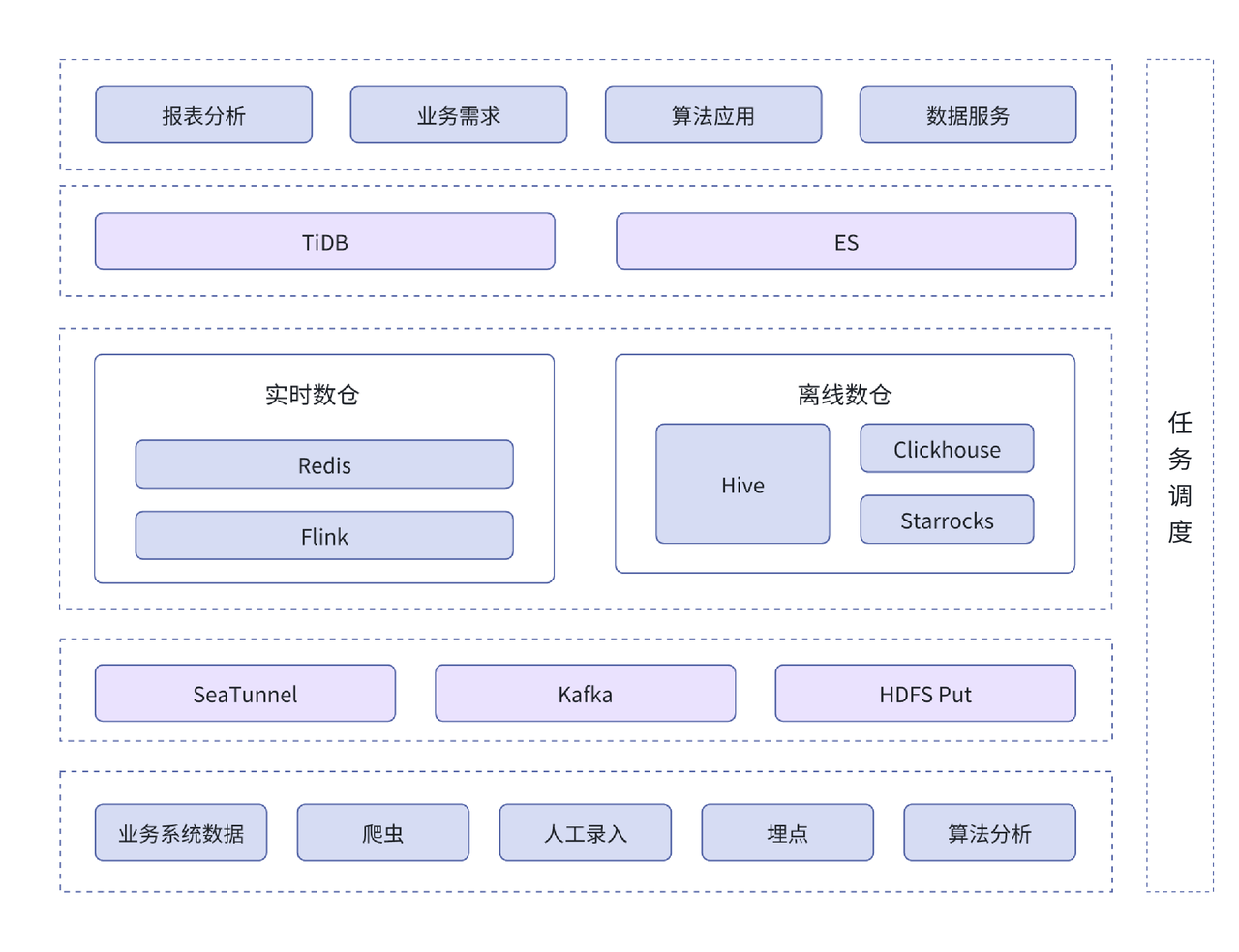
整体架构中,各组件的职能明确,并承载公司多年的数据服务工作。然而,随着 2023 年公司战略调整和需求扩大,数据处理效率、查询性能受到影响,架构疲态尽显。具体问题包括:
技术选型
为了快速应对业务发展需要,灵犀科技决定对架构进行升级。经过对多种大数据组件的对比,最终选择引入 Apache Doris 来构建公司新一代数据服务平台,Apache Doris 是一种低成本且能满足以下特性的架构:
基于 Apache Doris 的统一数据服务平台
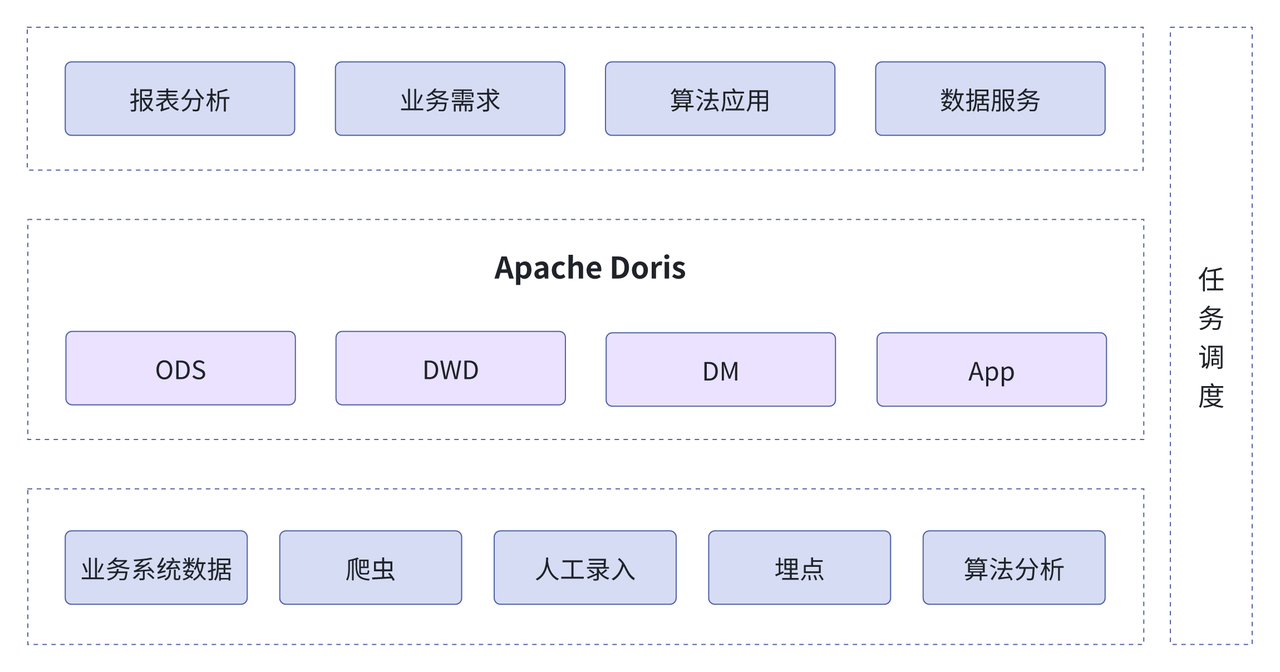
新架构中,使用 Apache Doris 替代了原先架构中数据存储与数据分析引擎,实现集存储、形成集存储、加工、服务为一体的统一架构,依赖于 Apache Doris 的湖仓一体能力, 实现数据的宽入->窄处理→宽出 ,具体来讲:
在数仓建模上遵循维度建模思路。ODS 层采用明细模型(Duplicate Key),保证了数据完整变更链路的存储,数据不做任何的加工处理;DWD、DM、APP 层选用主键模型(Unique Key),在数据的录入过程中完成的数据更新。为确保一致性的数据服务,基于 Doris 提供统一的应用服务,避免多组件间数据传输导致数据孤岛,同时避免多组件繁重的数据存储和同步成本。
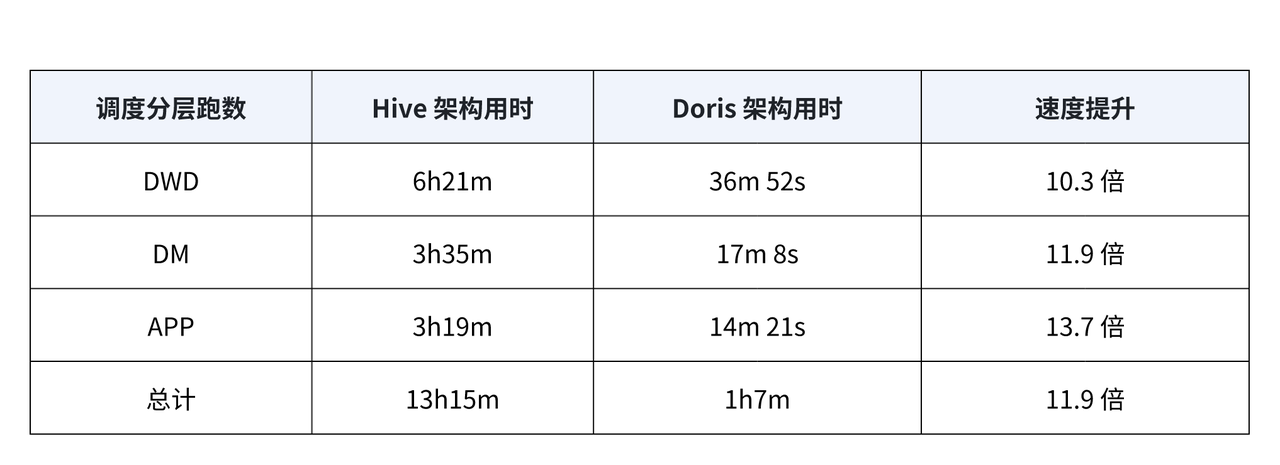
经过半年多使用,以 Apache Doris 为基石的数仓建设取得了显著成果:
基于 Apache Doris 的最佳实践
01 负载隔离实现资源高效管理
Doris 的多租户和资源隔离方案,主要目的是为了多用户在同一 Doris 集群内进行数据操作时,减少相互之间的干扰,能够将集群资源更合理的分配给各用户。
灵犀科技基于 Apache Doris 资源隔离方案对集群资源进行了租户级别的隔离。针对在线与离线任务,将节点资源划分为 Online 和 Offline 两个标签,并将 BE 节点均匀分配到这两个标签上。表数据依然以 3 副本的方式存储,其中 2 个副本存放在 Online 资源组,1 个副本存放在 Offline 资源组。Online 资源组主要用于高并发低延迟的在线数据服务,而一些大查询或离线 ETL 操作,则可以使用 Offline 资源组中的节点执行。从而实现在统一集群内同时提供在线和离线服务的能力。
同时,定义了多租户,并为每个租户分配不同的资源权限,通过租户级别的资源隔离,提高了资源使用效率,确保各业务模块按需获得计算与存储资源。在数据存储方面也进行了类似的划分,从而实现数据生产与业务应用的同时兼顾,提高了数据管理的可控性,降低了运维复杂度。
使用参考负载管理文档

为了在确保集群稳定性的同时充分利用资源,我们将用户划分为多种角色,以应对不同时间段的资源需求。举例来说:
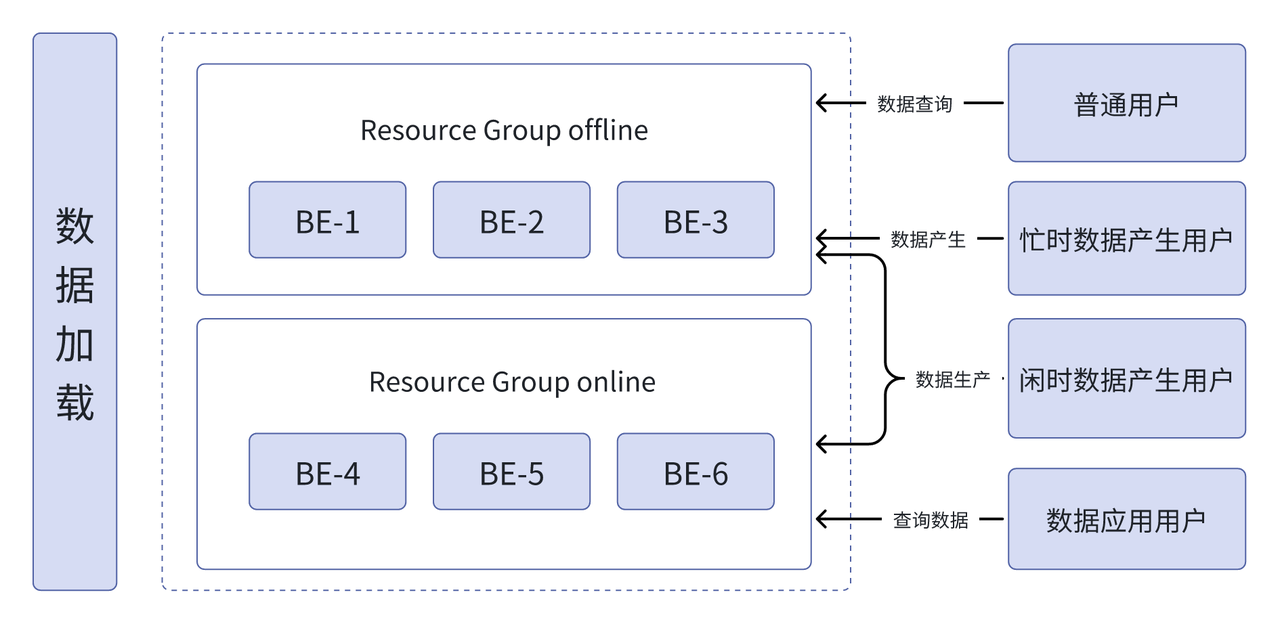
资源划分确保了应用系统在高峰时段的资源不被挤占,同时也兼顾了夜间大批量数据处理的性能需求。
02 多重机制保障集群稳定性
在一体化数仓建设中,集群需同时支持服务应用和数据生产,因此集群的稳定性显得格外重要。为此,灵犀科技采取了以下安全保障措施:
# 查询正常执行的查询select * from information_schema.active_queries# 通过查询时长设置熔断,杀掉长查询kill query {query_ID}
03 Doris 支撑企业相似度高效分析
公司依托详尽的企业信息,从多维度——包括企业类型、组织形式、经营范围以及产品服务等,构建了全面的企业产业链信息库。灵犀科技采用先进的数组结构来存储这些数据,并充分利用 Doris Array 数据结构以及强大的数据函数功能,精准分析企业间的相似度,以帮助企业更精准的招商引资。
原方案:
过往的方案中,采取每日将数据库中的新增数据同步至向量库,并转化为向量化数据进行存储。当用户发起请求时,将请求数据同样转化为向量,并查询向量库以获取相似企业的 ID 列表。随后,还需通过这些 ID 再次访问数据库,以获取并展示详细的企业信息。
这一流程存在显著弊端:数据冗余存储导致资源浪费,且数据不同步问题严重影响了结果的准确性。此外,每次页面请求都需要依次访问两个服务,不仅响应时间长,代码复杂度也较高,一旦出现问题,排查难度极大。
新方案:
为解决上述问题,引入 Doris 制定全新的方案。利用 Doris Array 的数据结构,承载企业所属产业、行业等相关信息,比如:一家企业的产业编码为 ["160", "208", "219", "399"],表示这家企业属于智能制造、汽车、新能源、物联网产业。然后运用数据相交函数
array_intersect
计算两家企业在产业、行业之间的相交度,为企业相似度分析提供数据支撑。简化模型如下:
与之前方案不同的是,引入 Doris 之后,只需一次 SQL 请求即可完成相似度计算并返回企业详细计算, 代码简单且流程缩短,接口响应时间稳定在 5 秒以内,较原方案快了 1 倍 ;同时,系统也无需进行冗余数据的存储及同步操作,避免了数据不一致的问题。
总结与规划
截至目前,灵犀科技基于 Apache Doris 建设的统一数据数据平台已上线并稳定运行,有效解决了数据孤岛问题,实现了数据整合与流通。在数据集成(ETL)、标准化、治理和可视化等方面取得显著进展,相较于原有的多组件架构, 数据生产能力提升超过 10 倍、存储成本节省超 60% 。未来,灵犀科技将进一步探索 Apache Doris 潜力,并在以下方面进行深入实践: