引言
SQL 的世界也是如此。最初 ANSI 仅仅对 SQL 提出了一种标准,于是各个数据存储厂商都自己定制了专门的 SQL 语法。也因为此,在工作中,我们常常会遇到这样的场景:
小明,刚刚参加工作,第一个任务便是查询从没接触过的 Hive 中的数据。前辈说,不要担心,你直接用查 MySQL 的 SQL 语句查询就好。小明颤颤巍巍写下了第一个 SQL 查询语句,确实能跑。但是随着业务复杂度增加,SQL 的复杂度也随之提升,他渐渐发现 Hive 和 MySQL 的 SQL 语法并不完全一样,平时查询需要区别对待,不停切换。他想知道,有没有一种 SQL 可以支持业内主流的数据存储引擎?
小红,参加工作 2 年。已经学会使用 MySQL、Hive、Oracle 等不同存储引擎的 SQL 语句查询数据。这时,上司说要引入 Elasticsearch。她发现这个数据存储引擎并不能通过 SQL 查询,而是需要编写复杂的 json 查询。渐渐地,她发现类似的存储引擎越来越多,Druid、Redis、Mongo、HBase 等,并且每一种都需要采取不同的方式查询数据,分析一个业务场景所需要切换的查询方式也越来越多。她想知道,可不可以使用 SQL 语言查询 No-SQL 乃至 New-SQL 的数据存储?
所以嘞,Quicksql(简称 QSQL)诞生啦!
Quicksql 是什么
Quicksql 是一个更简单,更安全,更快速的跨数据源统一 SQL 查询引擎。它帮助用户减少在使用不同数据引擎时需要的学习成本和切换成本,忽略不同数据引擎底层存储和数据查询方式的差异,使用户仅需要关注查询的业务逻辑和数据本身。
Quicksql 能做什么?
如何使用 Quicksql?
Quicksql 现在提供三种对外服务方式:命令行,API 和 JDBC 连接。
Quicksql 是怎么实现的?
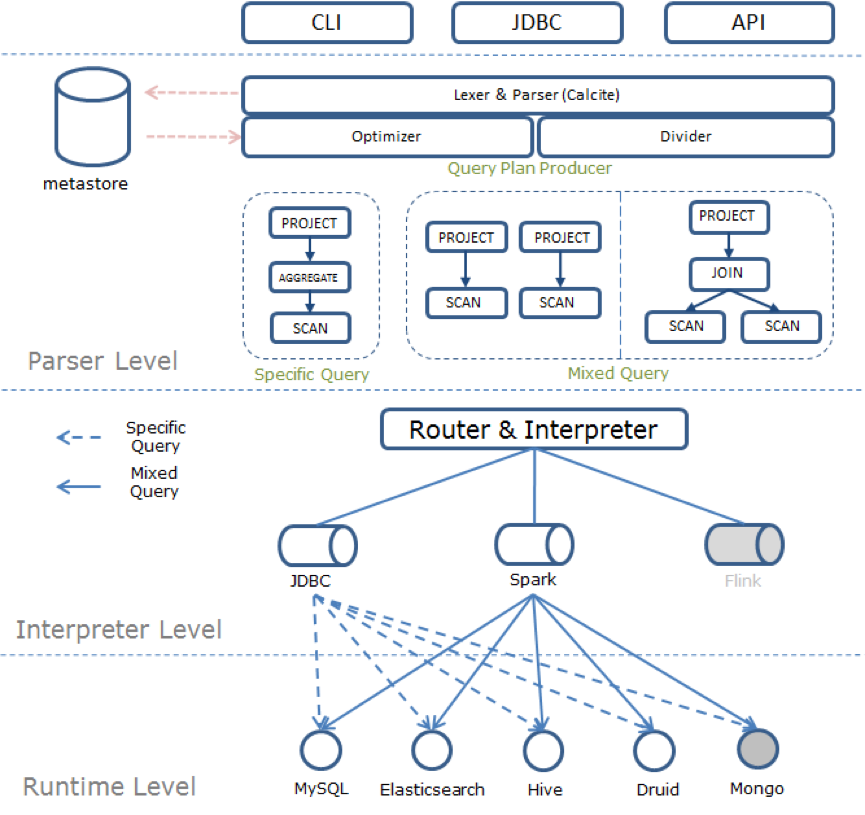
Quicksql 基于 Apache Calcite 提供的多数据引擎 SQL 语义适配功能,基于 ANSI 发布的 SQL 2003 标准和用户的使用习惯上,重新定义并扩展部分 SQL 语义,对用户提供了统一的 SQL 语言。在内部,Quicksql 会根据用户所查询的 SQL 语句,在原语义的基础上,进行解析转化等操作,最终根据数据引擎特性将用户的查询语义完整的转化为数据引擎可执行的 SQL 语句。Quicksql 还拥有智能选择功能,可以根据该 SQL 的引擎特性决定最快速最高效的数据查询方式,例如,当 Quicksql 分析得出查询语句是一个混合查询,它就会自动选择启动集群模式(默认是 Spark)进行数据处理。
想知道更多 ?这里就是开源主页啦:有问题还可加入 QQ 群和 360 的技术人员一起交流。QQ 群号:932439028