

在不久前举办的 AICon 全球人工智能开发与应用大会上,月之暗面高级研发工程师、开发者关系负责人唐飞虎发表了专题演讲“长文本大模型推理实践——以 KVCache 为中心的分离式推理架构”,分享介绍 Kimi 智能助手背后的推理加速方案,以及该方案在设计时所需要考虑的指标和在真实生产环境中部署的表现。

在 10 月 18 -19 日即将召开的QCon 上海站上,我们专门策划了【大模型基础设施与算力优化】专场,并邀请到月之暗面推理系统负责人何蔚然进一步分享 Mooncake 分离式推理架构创新与实践,同时微软亚洲研究院软件开发工程师姜慧强将分享 《 长文本 LLMs 推理优化:动态稀疏性算法的应用实践 》,还有更多大模型训练推理的一手实践案例尽在本专题。欲了解更多精彩内容,可访问大会官网:
提到 Kimi,相信在座的各位都有所耳闻。Kimi 智能助手在多个平台上都有入口,包括 Apple Store、微信小程序以及 Web 端,尤其是 Web 端的排名一直居高不下。在日常使用中,尤其是在午间高峰时段,用户可能会遇到 Kimi“累了”的情况。但值得注意的是,尽管用户数量在不断增加,用户体验却得到了显著改善,现在 Kimi“累了”的情况减少了很多,这与我们推理团队的技术攻关是分不开的。
今天,我将从四个方面进行介绍。第一部分我将探讨长文本推理的瓶颈问题。随着推理集群的扩大和上下文长度的增加,无论是训练还是推理都面临着更高的要求。我们需要明确瓶颈所在,以便找到解决问题的途径。第二部分将审视目前市面上的推理优化工具和方法,看看有哪些可以为我们所用。第三部分将详细介绍我们的 Mooncake 项目。这是一个以 KVCache(键值缓存)为中心的分离式推理架构,内部代号“Mooncake”由我命名,寓意与“moon”相关,同时“Cake”与“Cache”谐音。在最近几个月,我们也看到了不少类似的方案提出,虽然与我们的设计大同小异,但我将分享一些细节,特别是在面对大量用户时可能遇到的一些独特问题。第四部分,我将讨论上下文缓存的应用。在 SaaS 服务层面,我们为开发者提供了上下文缓存功能。我将具体介绍每位开发者如何利用 Mooncake 方案来优化自己的 AI 应用。
长文本推理的瓶颈
几个月前,我在 AICon 北京站上讨论了 RAG 与长文本处理的对比。RAG 模型有其优势和劣势,但在长文本处理方面,它有两个显著的劣势:成本高和速度慢。这也是许多开源模型无法良好支持或只能有损支持长文本处理的原因之一。

成本高的问题是我们的用户群体,特别是 API 开发者在生产环境中经常遇到的一个痛点。他们需要使用我们的 API 对同一个文档,比如一份合同,进行复杂的任务处理,并可能需要反复询问 100 多次或更多。众所周知,大型模型通常采用无状态设计,这意味着每次调用都需要将整个上下文传递进去。随着对话的进行,上下文可能会不断增长,不仅包括上下文本身,还可能包括函数调用、定义以及其他文档设置。每次调用都需要处理这么多信息,因此成本自然会很高。
速度慢问题,特别是在第一次处理时,模型的响应速度会特别慢。例如,我们群里的 API 助手在用户频繁提问时,有时会卡住,20~30 秒内都无法产生回复。我们无法确定是卡住了还是其他地方出了问题,但很可能仅仅是因为处理速度慢而导致的卡顿。这是长文本处理速度慢带来的一个副作用。

贵且慢的原因
长文本推理之所以成本高昂且速度缓慢,原因在于 Transformer 模型在计算 Attention 机制时的工作方式。在没有使用缓存的情况下,每次计算 Attention 都需要进行完整的矩阵乘法,这导致每次迭代的长度以平方级别增加。每当出现一个新的 Query Token,都需要重新计算,这无疑增加了计算的复杂性和时间。
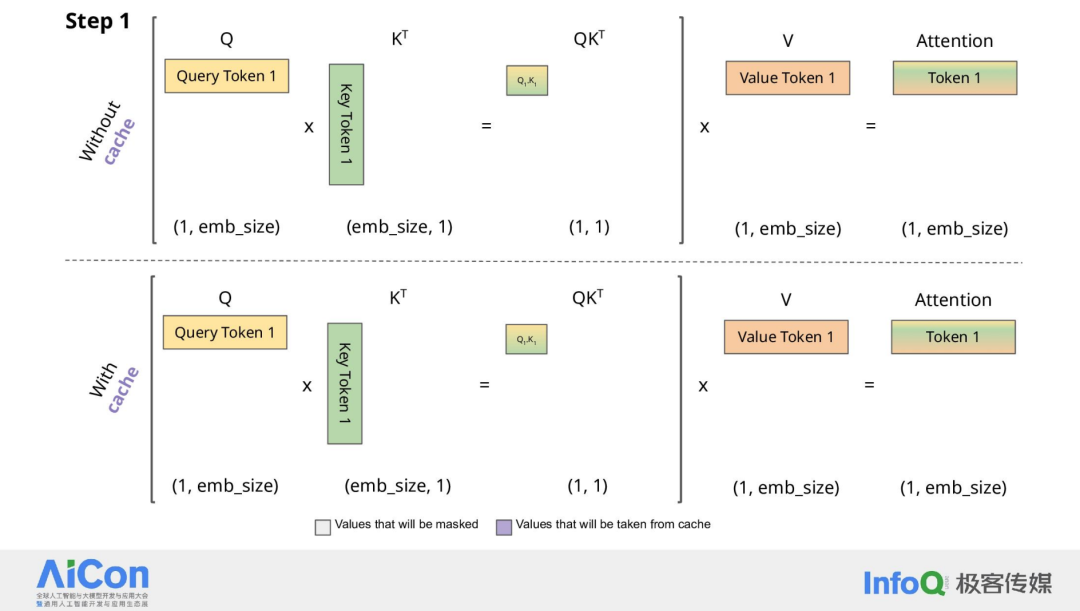
当我们引入 KVCache 机制后,情况就大为改观。使用 KVCache 后,每次计算的长度只需要线性增加,这意味着我们不再需要重新计算过往的 tokens,从而显著提升了性能。但这种优化也带来了新的问题。
为了更直观地理解这一点,我们可以看下面这张图。图表的横坐标表示上下文长度,从左到右逐渐增大;纵坐标则展示了不同的性能度量指标,包括并发数、预填充延迟、解码延迟以及上下文切换时的状态切换延迟。此外,还有 Free HBM Size,它表示可用的高带宽内存大小,随着上下文长度的增加,它可以改善并发性能。
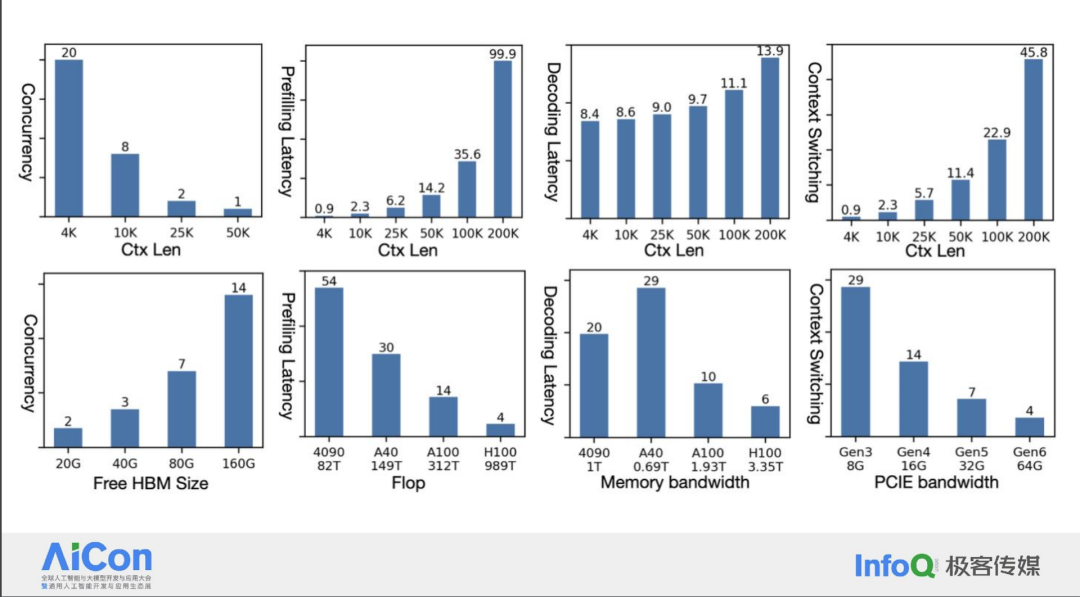
在 Mooncake 论文中,我们使用了 LLaMA2-70B 模型作为例子。从图表中可以明显看到,随着序列长度(即上下文长度)的线性增长,预填充延迟(prefill latency)呈现出超线性增长,这是一个非常显著的趋势。
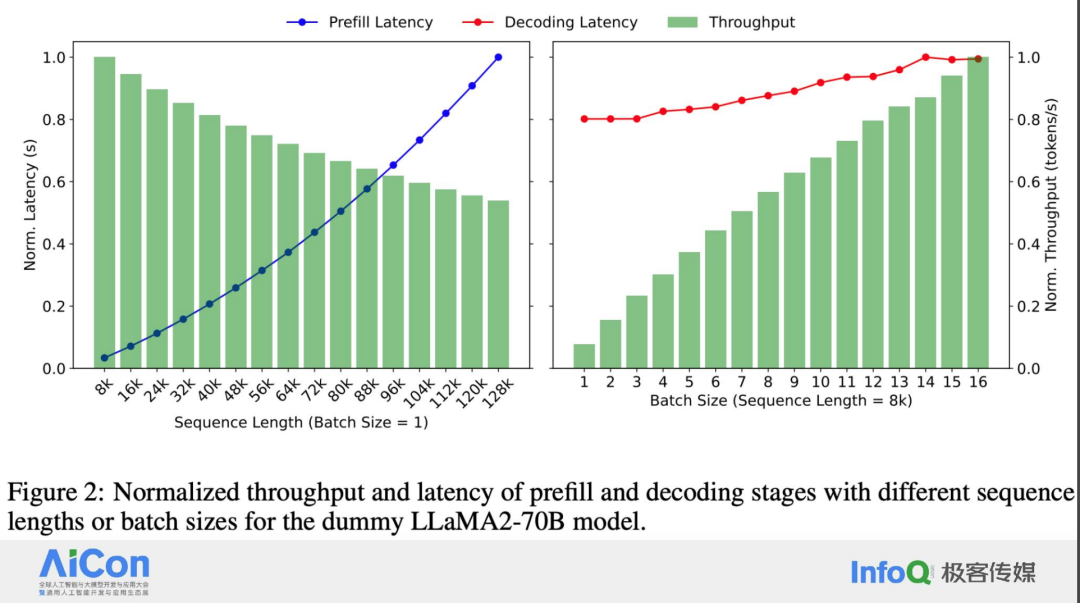
我们做个小结,长文本性能瓶颈主要包括以下几个方面:

长文本推理的优化
面对长文本推理中的成本高昂和速度缓慢的问题,我们采取了一系列优化策略。在之前的讨论中,我们已经提到了一些方法,现在我们来总结一下这些策略,并探讨它们如何帮助我们解决长文本推理的挑战。
首先,我们考虑了几种优化技术,包括 Flash Attention、vLLM(垂直扩展的大型语言模型)、MOE(Mixture of Experts,专家混合模型)以及最近非常受欢迎的 Speculative Decoding(推测性解码)。此外,还有一些有损策略,例如 Windows Attention,它通过截取部分信息来处理长文本推理,尽管这种方法在资源有限的情况下可行,但最终提供给用户的模型可能是有损的。例如,如果用户询问一个公司上市财报的问题,信息可能分散在文档的不同部分,使用 Windows Attention 策略可能会遗漏一些关键信息。这种信息的遗漏是在训练过程中就已经决定的,后续的 SFT 也无法修复这个问题。虽然这种策略可能在短期内提高模型的上下文指标,但对最终用户体验来说可能是有损害的,而且这种损害在进行大模型基准测试时可能不容易被检测出来。
此外,这些策略之间存在不兼容问题。这就需要我们深入了解每个策略的具体实现方式,这会带来一系列复杂的问题,需要从不同的层、头或隐藏层角度进行推理优化。在系统设计时,我们需要选择兼容性最好且效果最佳的策略。
我们的 Mooncake 主要是从集群调度的角度进行优化。这种优化与我们之前提到的所有策略基本上是正交的,可以与任何策略组合使用,而不会损失性能。这对于模型基础供应商来说可能是一个高优先级的策略。这也是为什么我们最近看到许多厂商推出了基于 KVCache 优化的方案。这些方案能够提高长文本推理的效率,同时保持用户体验的高质量。
Mooncake 的实践
上个月,我们在 GitHub 上发布了相关的论文,其中包含了许多细节。在详细介绍之前,让我们先澄清一些基本概念。在大模型推理中,有两个至关重要的阶段:预填充(Prefill)阶段和解码(Decode)阶段。
Mooncake 的基本思想
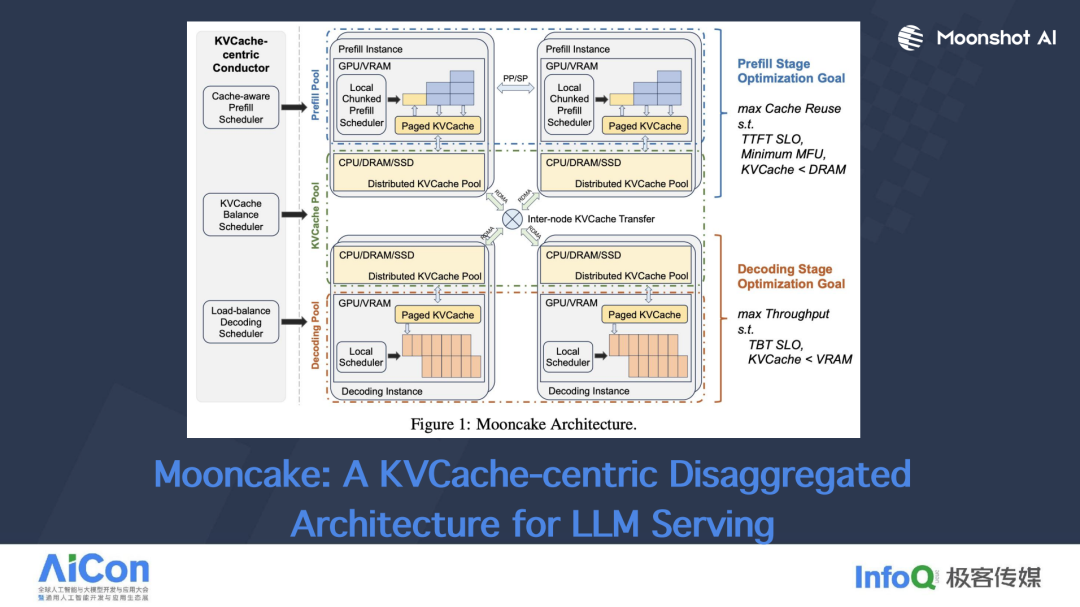
Mooncake 的核心理念是将模型推理过程中的两个截然不同的优化阶段分开处理,因为这两个阶段的优化目标和受限的瓶颈各不相同。这种分离式处理方法是一种直观且自然的思路。具体来说,Mooncake 采用了以 KVCache 为中心的分离式推理架构,主要由三个核心部分组成:
Mooncake 的开发动机
现有的大型语言模型(LLM)服务系统,例如垂直扩展的大型语言模型(vLLM),通常将预填充(Prefill)和解码(Decode)阶段放在同一个 GPU 上处理。这种设计在实际操作中会遇到一些问题:
这种分离设计的思路在计算机体系结构领域并不新鲜。例如,区块链系统 EOS 在设计时就采用了类似的分离策略,将带宽和 CPU 计算分开处理,各自形成一个资源池。受到这种设计思路的启发,Mooncake 采用了典型的分离式架构,将单个同构 GPU 集群的资源打散并重新组织成三个可以独立弹性伸缩的资源池 —— Prefill Pool、Decode Pool、KVCache Pool。
Mooncake 的分离式架构
在 Mooncake 架构中,Prefill Pool 中的一个具体实例负责处理特定的任务。下图的工作流程可以这样理解:
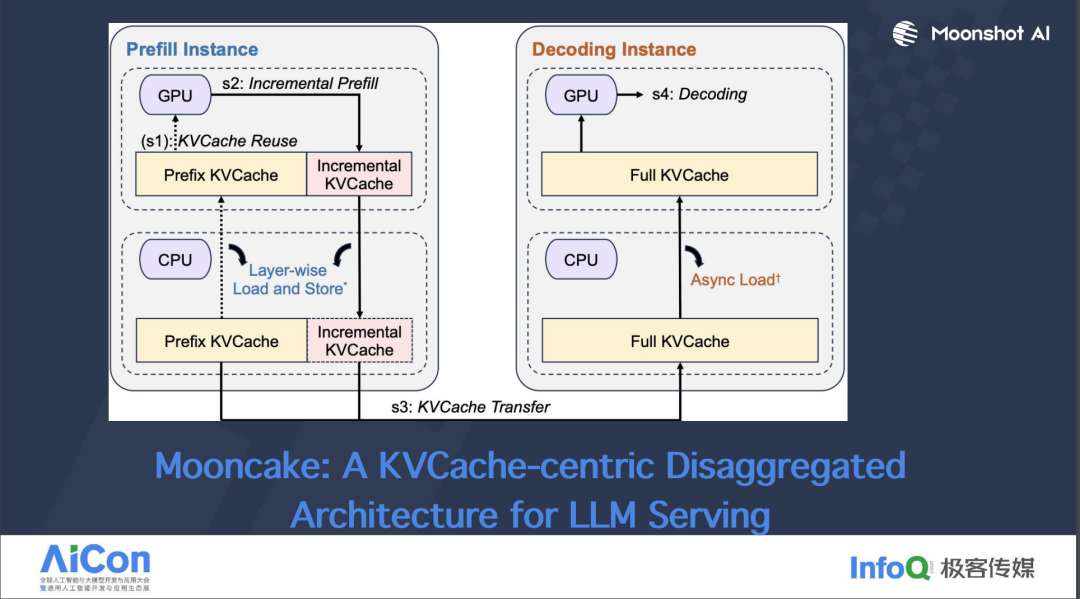
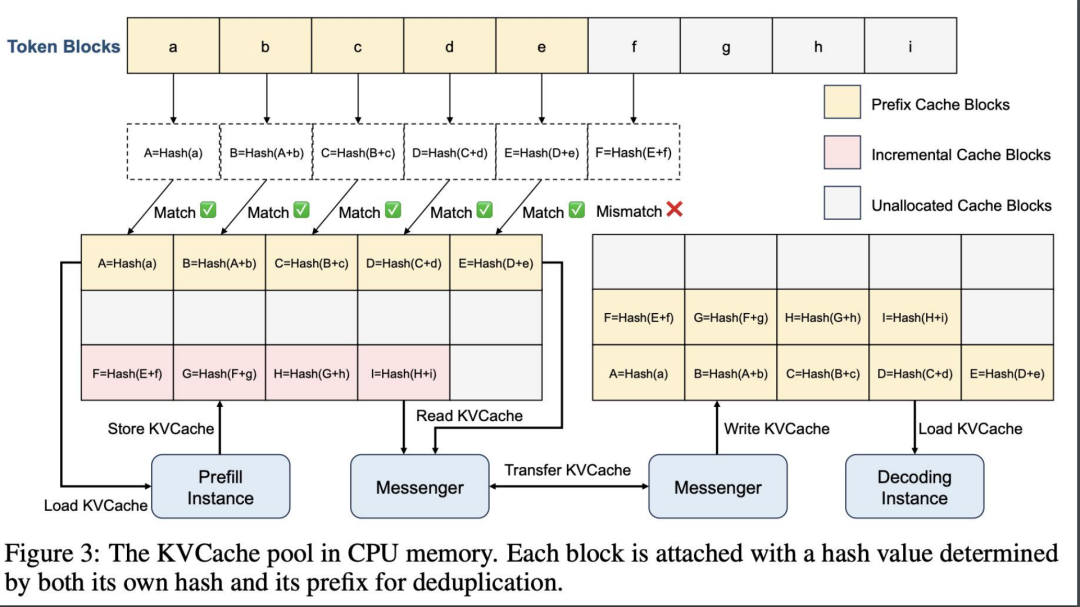
在 Mooncake 架构中,KVCache 资源池扮演着至关重要的角色,尤其是在线上服务中,每天需要应对数百万用户的查询。在一些热点事件,如奥运会期间,用户可能会频繁询问类似的问题,比如中国队当天获得的金牌数量或者乒乓球男团的晋级情况。面对这样的高频查询,我们可以利用 KVCache 资源池来优化处理。
一个自然的想法是使用哈希存储来管理这些 KVCache。不同的厂商可能会采用不同的策略,例如有些可能会选择使用 Trie 树。Trie 树在计算复杂度上与模型的词表大小有关,如果模型的词表发生变化,比如从 GPT-4 升级到 GPT-4o 时词表扩大了,Trie 树的性能可能会受到影响。
为了避免这种复杂性并提高效率,我们选择了哈希存储。哈希存储方法简单、速度快,并且不受词表大小变化的影响。这样,无论用户的查询如何变化,我们都能保证 KVCache 资源池的高效运作。
Mooncake 效果展示
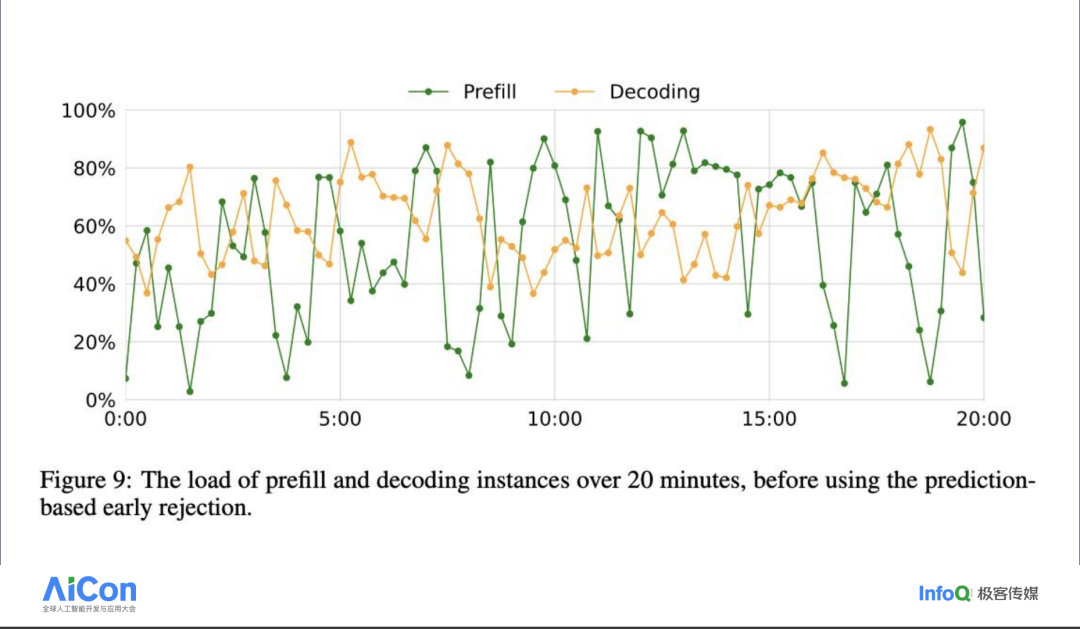
在实施了三个独立的资源池之后,我们进一步观察了线上生产环境中的实际运行情况。我们发现,Prefill 和 Decoding 阶段对资源的占用呈现出一种波浪型模式,类似于潮汐的涨落,每天都有规律地变化,尽管看起来似乎没有明显的规律。然而,当我们仔细观察并分析每天线上数百万用户的行为时,这些行为模式变得可以预测。基于这些可预测的行为模式,我们可以采取类似于 vLLM 中的策略,即在资源紧张时暂停解码阶段,让预填充阶段先行。在集群调度中,我们也可以应用类似的逻辑。我们根据线上生产环境的日常运行数据,设计了一种基于动态规划的调度策略。这种策略能够提前准备适量的预填充和解码资源,以使资源占用的波动曲线更加平缓。通过这种动态规划的调度策略,我们能够更有效地管理资源,减少资源浪费,并确保服务的稳定性和响应速度。这样的调度提升了用户体验,因为我们能够更好地应对用户需求的高峰和低谷,确保服务始终如一地流畅运行。
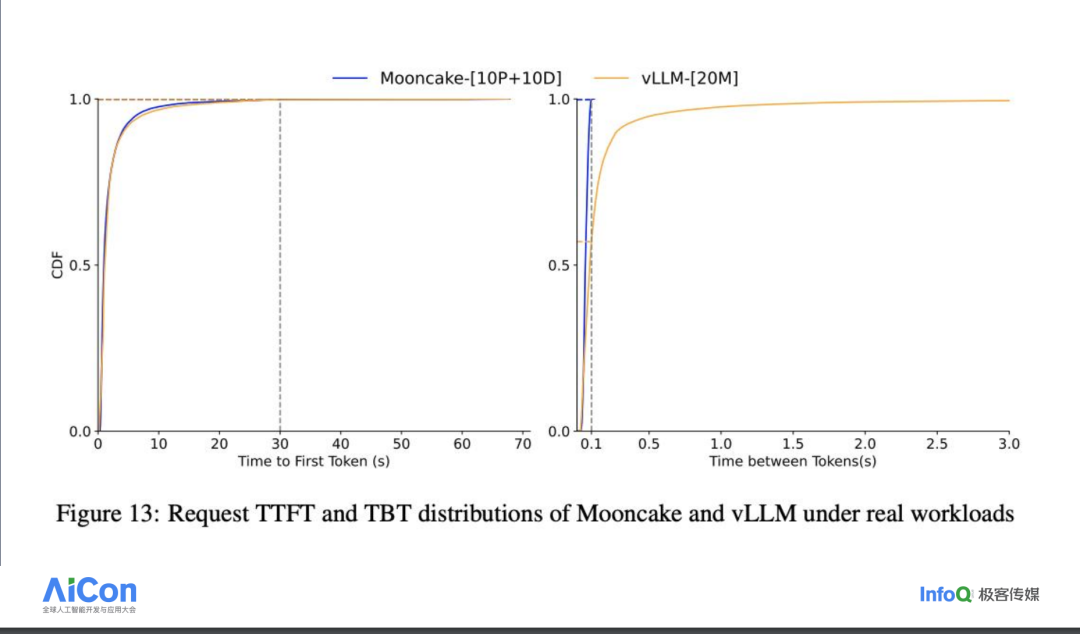
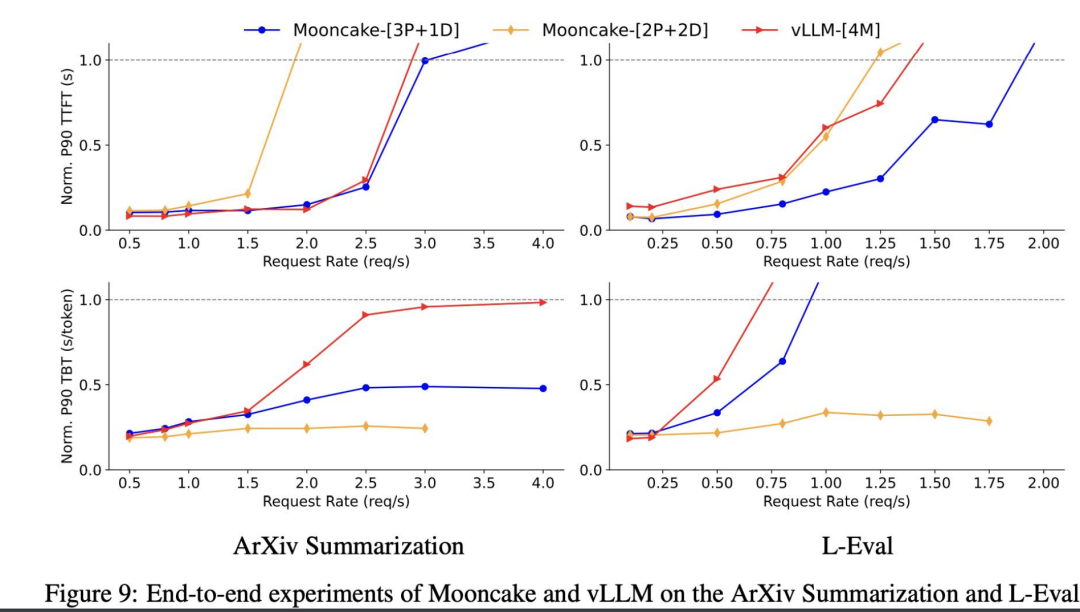
在下面展示的图表中,蓝色线条代表我们的 Mooncake 架构,而黄色线条则代表与之对比的 vLLM 架构。我们可以观察到两种架构在首次 Token 时间和 Token 间时间上的表现差异。
下图展示了一些具体的实验数据,这些数据并非来自线上环境,而是使用了开源数据集。我们特别关注了 ArXiv 上每天发布的论文摘要任务。许多用户每天都会使用 Kimi 智能助手来总结文章,包括学术论文,以及一些第三方应用基于 Kimi 大模型开发的论文摘要工具。在这些实验中,我们比较了 Mooncake 架构和单机 vLLM 架构在处理 ArXiv 数据集时的性能。实验结果显示,Mooncake 在处理这些摘要任务时相较于单机 vLLM 有明显的优势。
上下文缓存的应用
Context Caching 基本原理
在传统的 LLM 交互中,每次用户与模型的对话都需要重新计算整个上下文,这包括了所有的历史信息和对话内容。这种方法意味着每次交互都需要为整个上下文支付计算费用,无论上下文中有多少信息是重复的。
上下文缓存的核心改进在于引入了一个“公共上下文”的概念。这个公共上下文包含了对话中不变的部分,比如背景信息或常见问题。通过缓存这个公共前缀,我们只需要为其支付一次计算费用,而不必在每次交互时重复支付。这样,每次交互的成本就大大降低了,用户只需要为每次的增量输入(即新的对话内容)以及存储公共上下文的费用付费。

Context Caching 使用流程
使用 Context Caching 的流程非常简洁明了,主要分为以下几个步骤:
为了帮助开发者更容易地实现上下文缓存,我们在官方 GitHub 上提供了一些示例代码,这些代码覆盖了多种编程语言,包括 Python、Node.js 等,以便开发者能够快速上手并集成到自己的项目中。

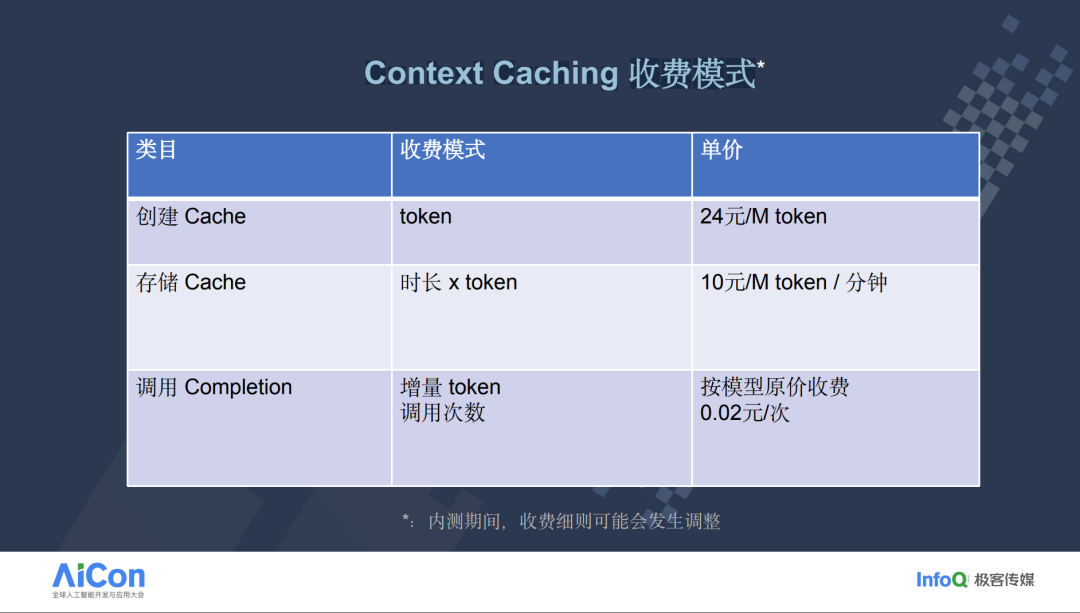
Context Caching 收费模式
我们的上下文缓存(Context Caching)技术的收费模式已经进行了优化和调整。现在,创建缓存的成本非常低,而且是一次性的费用。调用缓存的费用也几乎可以忽略不计,主要的成本瓶颈在于存储空间的费用。为了鼓励更多开发者使用这项技术,我们最近对价格进行了调整,降价幅度达到了 50%。原先的费用是 10 元,现在降低到了 5 元。我们希望通过这样的降价措施,能够激励开发者更广泛地采用上下文缓存技术。
在最近的“GOGC 黑客松”和之前的“Adventure X 黑客松”中,我们特别表彰了使用上下文缓存 API 最多的开发者,以此鼓励大家探索和利用这项技术。我们注意到,尽管上下文缓存技术能带来便利和性能优化,但仍有许多开发者没有充分利用它。例如,之前有一个非常受欢迎的应用,它在短时间内有大量的调用。如果该应用当时使用了上下文缓存技术,开发者本可以节省一大笔开支。实际上,我们与开发者进行调研后发现,由于大模型产生的费用过高,他们不得不调整其提示词,尽可能简化内容,甚至删除了一些原本设计的游戏玩法、规则和元素,这无疑是一种遗憾。如果现在有类似的爆款应用出现,它们完全可以利用上下文缓存技术来提升用户体验并有效控制成本。
Context Caching 应用技巧
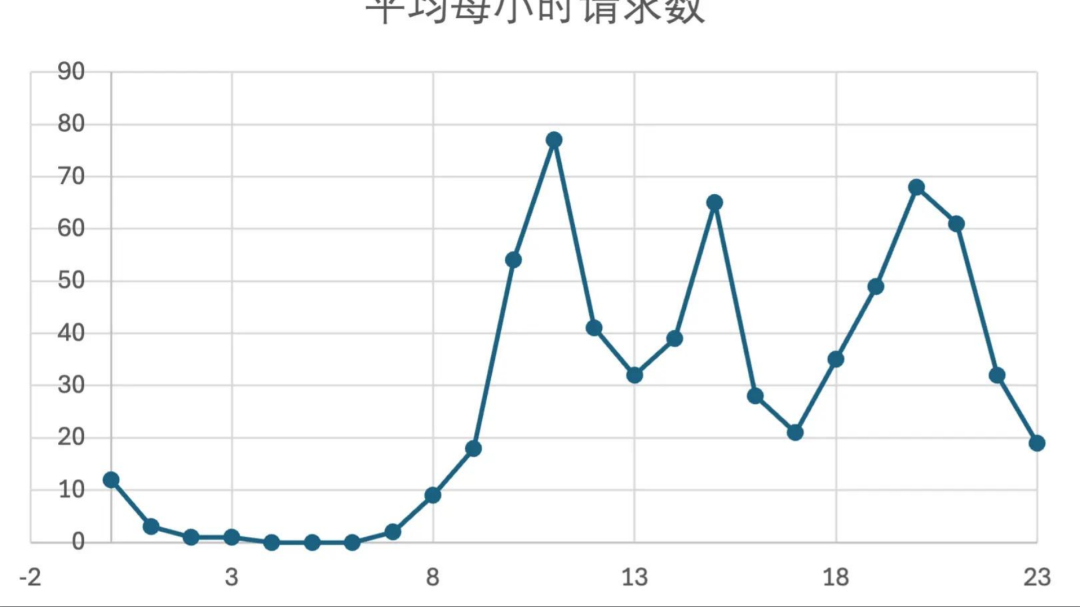
我们的官方 API 小助手的线上实际调用情况可以通过下图进行展示。目前,我们大约有 20 个开发者社群,每个社群的每小时调用情况都能清晰地反映出来。从图中可以看出,在每天凌晨 2 点到早上 8 点这段时间,社群内几乎没有活动,因为大家都在休息。一旦进入白天的工作时段,尤其是在早上、中午以及晚上下班后的时间段,社群内的活动会显著增加,这也是我们的 API 小助手最为忙碌的时段。
对于不同的开发者来说,他们的应用类型可能会影响调用频率的曲线。例如,如果应用是工具类或生产力类的,那么在工作日的白天可能会有更多的调用。相反,如果应用更偏向于娱乐或游戏,那么在晚上和周末的调用可能会更加频繁。
具体到我们小助手的情况:
以 Python 代码为例,大致的代码逻辑为:
我们具体分析了一天中的数据,发现通过在特定时间点,如上午 9 点和晚上 24 点,存储上下文缓存,可以显著降低费用消耗,大约能节省 3/4 的成本。这种策略对于那些像我们的 API 小助手这样需要频繁交互的应用场景尤其有效。如果你的应用也属于这种类型,那么上下文缓存技术将是一个非常值得尝试的优化手段。

目前,我们也观察到市场上其他一些解决方案,它们通过不同的方式处理上下文缓存的复杂性。一些系统选择将这些复杂操作隐藏起来,让用户无需手动管理缓存的存储和删除,而是将这些任务完全交给调度引擎,由它智能地进行资源分配和优化。我认为手动管理和自动调度各有优势,手动管理提供了更多的灵活性和控制权,而自动调度则简化了操作流程,降低了用户的使用门槛。未来,我们可能会看到这两种方法的融合,以满足不同用户的需求和偏好。
Context Caching 适用场景
上下文缓存技术的应用场景非常广泛,尤其适合那些频繁进行请求并且需要重复引用大量初始上下文信息的场景。在这些情况下,上下文缓存能够显著提升处理效率,主要表现在缩短首次 Token 生成的时间,同时大幅降低 Token 消耗的费用。在我们的线上生产环境中,随着 Mooncake 架构从最初的灰度测试到现在的全面部署,Kimi 智能助手能够每天处理的请求量增加了 75%。这也是为什么用户最近感觉到“Kimi 累了”的情况有所减少的原因之一。
参考资料
为了帮助大家更深入地了解上下文缓存及相关技术,我们附上了一些参考资料。特别推荐其中一篇由爱丁堡大学的傅瑶撰写的基础总结,该文详细介绍了长上下文大型模型推理优化技术,包括最新的进展和其他技术的对比分析,以及哪些技术可以组合使用等。
演讲嘉宾介绍
唐飞虎 ,月之暗面高级研发工程师、开发者关系负责人。前谷歌工程师、ACM/ICPC 亚洲赛区金牌、微软编程之美挑战赛冠军、第一届万向实验室通证经济设计大赛冠军。
会议推荐
AI 应用开发、大模型基础设施与算力优化、出海合规与大模型安全、云原生工程、演进式架构、线上可靠性、新技术浪潮下的大前端…… 不得不说,还是太全面了,报名详情请联系票务经理 17310043226 咨询。



