1.PyFlink 的发展史
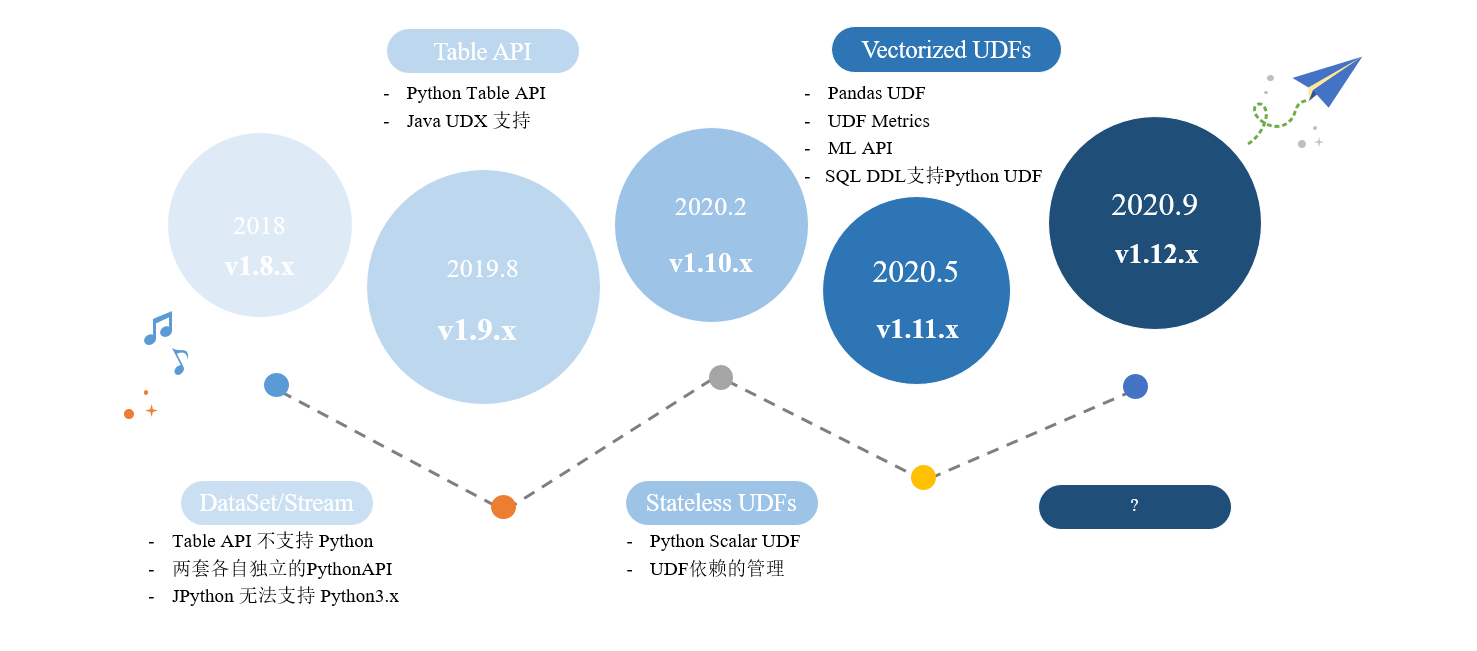
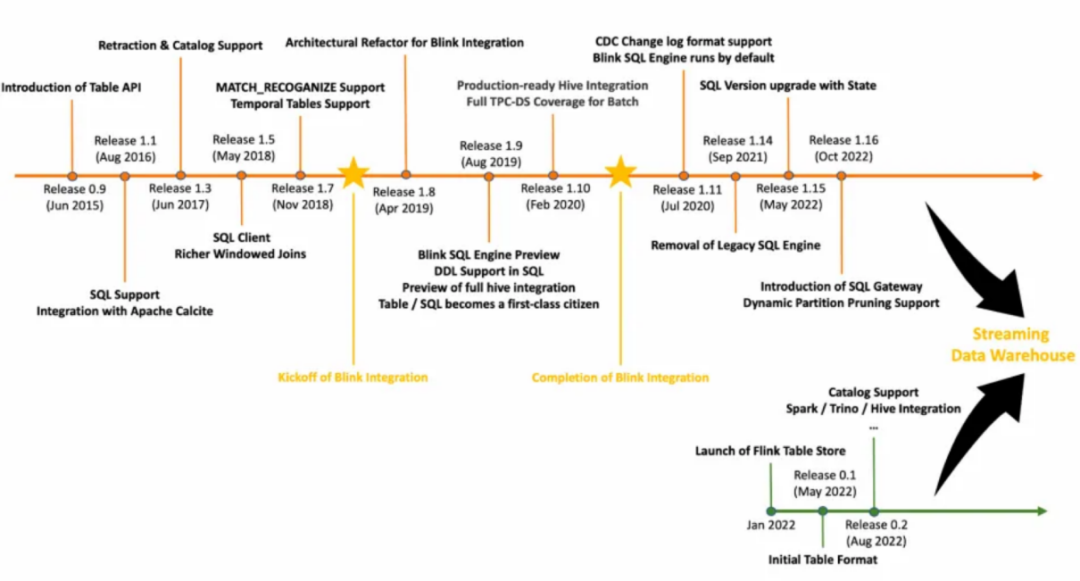
1.1、v1.8.x
1.2、v1.9.x
1.3、v1.10.x
1.4、未来发展
2.PyFlink 核心功能及原理介绍
PyFlink 核心功能将主要从每个版本的划分来跟大家进行介绍,第 1 个 PyFlink 1.9 版本里面提供 Python Table API 的支持,然后是 PyFlink 1.10 里面提供了 Python UDF 还有相关依赖管理,最后 1.11 版本里面提供了 Pandas UDF 和用户自定义的 Metrics。
2.1、Python Table API (PyFlink 1.9)
■ 1.Python Table API
什么是 Python Table API 呢?我们可以从编程的角度来介绍一下。Python Table API 大概提供了一些 Python 的 API ,比如这里主要可以看一下 Table 的接口, Table 接口上有很多 Table 相关的算子,这些算子可以分为两类:
当有一个很大的表并且想删除某一列的时候,可以用 drop_columns 来删除某一列。
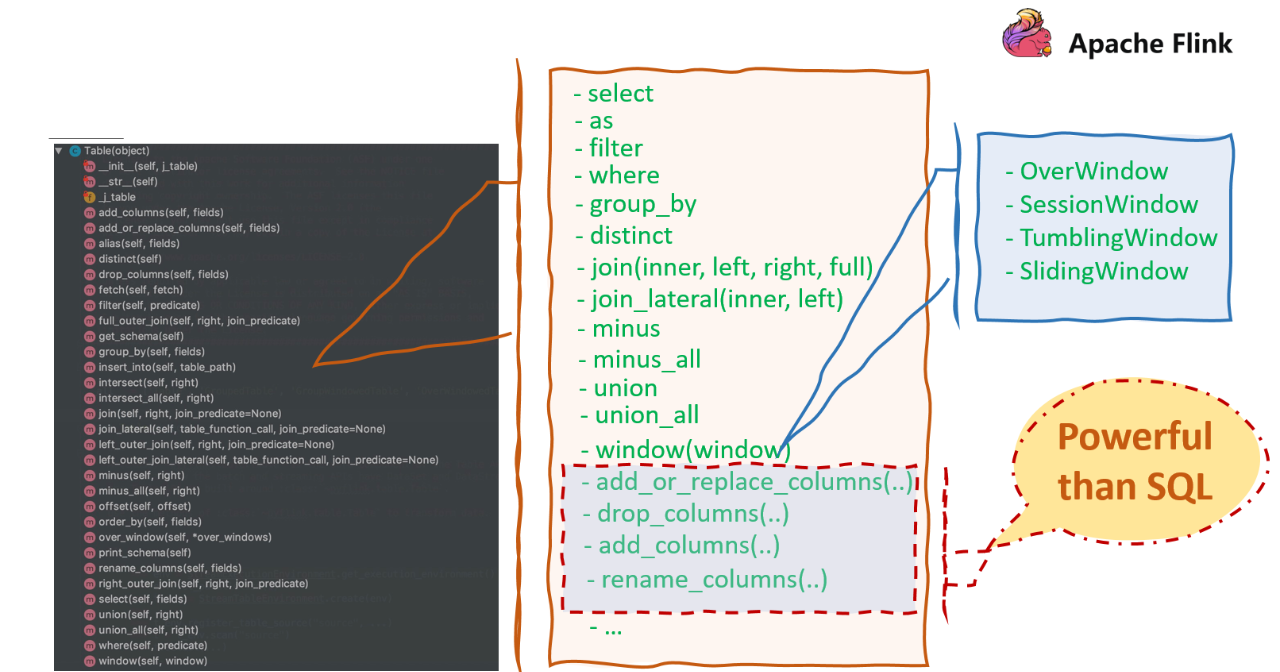
对于我们来说,可以随意组合 Table 上的方法,然后编写不同的业务逻辑。我们接下来看一下,如何用 Table API 来写一个 WordCount 的例子,可以让大家有一个比较完整的认识。
■ 2.WordCount
如下图所示,是一个完整的 Python Table API 的 WordCount 的例子。主要可以包含 4 个部分。

经过上面 4 步,我们就完整的写出了一个 Python Table API 的 WordCount。那么对于 WordCount 例子,它的底层实现逻辑是怎么样的呢?接下来看一下,Python Table API 的一个架构。
■ 3.Table API 架构
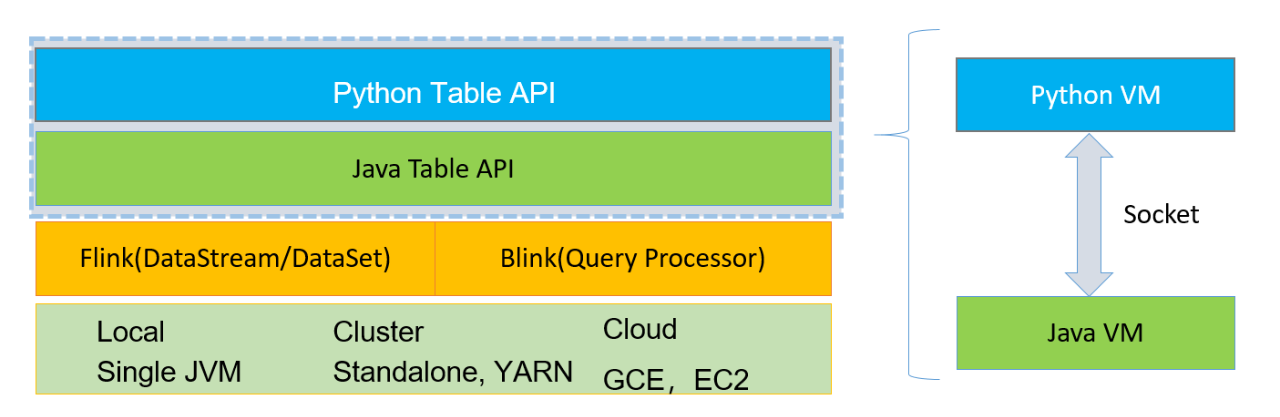
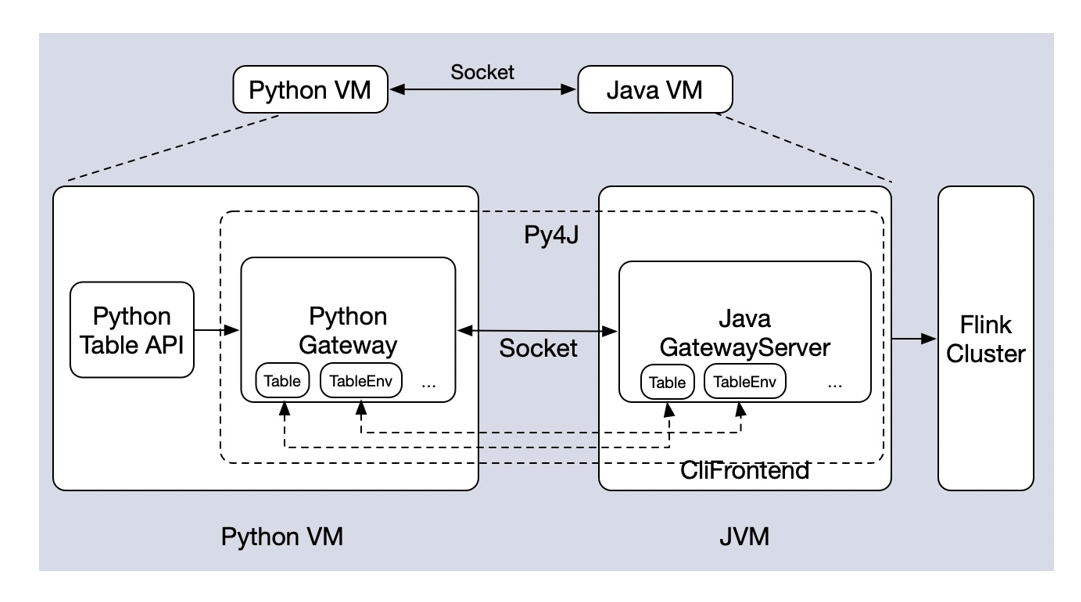
刚刚我们介绍了 PyFlink 1.9 版本里面的 Python Table API ,也提到了 table 的接口上面提供了很多不同的算子,而且可以用这些算子去组合,实现不同的业务逻辑。但是对于这些算子来说,它的功能还无法满足一些特定的情况,比如某些业务需要编写一些自定义的逻辑,此时就需要强依赖 Python UDF,所以在 PyFlink 1.10 版本里面,提供了 Python UDF 并且提供了相应的依赖管理。
2.2、Python UDF & 依赖管理 (PyFlink 1.10)
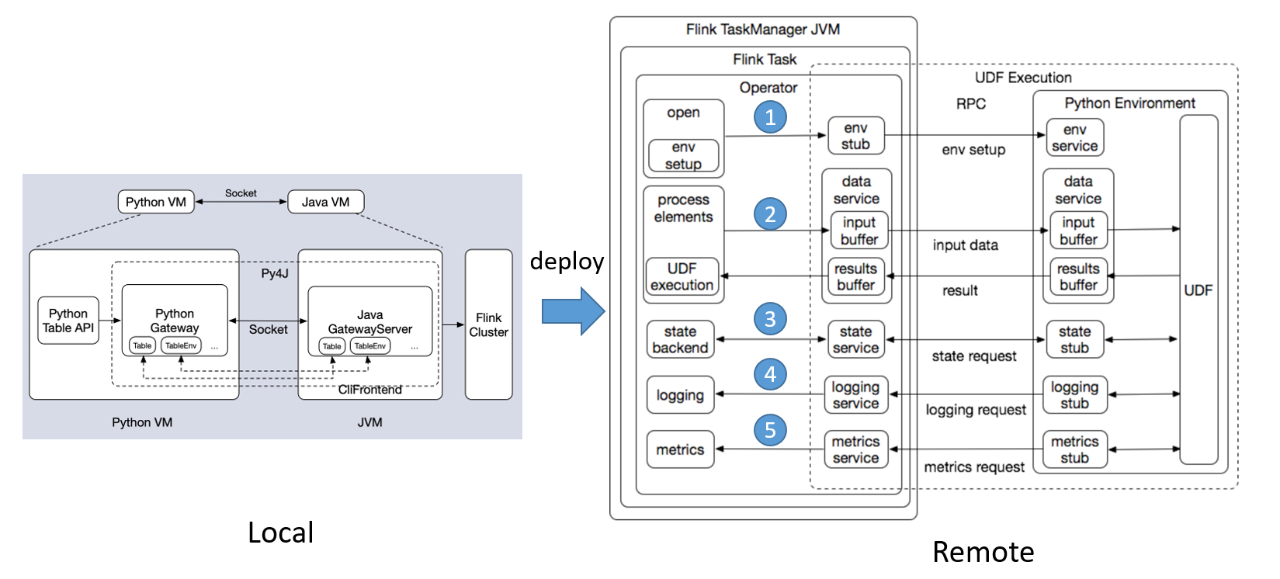
■ 1.Python UDF 架构
如果你的作业是包含一个 Python UDF 的作业,那么从提交的时候,就是左边的架构图,然后 deploy 到 Remote 端的时候,可以看到 Remote 端的架构图分为两个部分。左边部分是 Java 的 Operator,右边部分是 Python 的 Operator。
大体的流程我们可以大概看一下:
■ 2.Python UDF 的使用
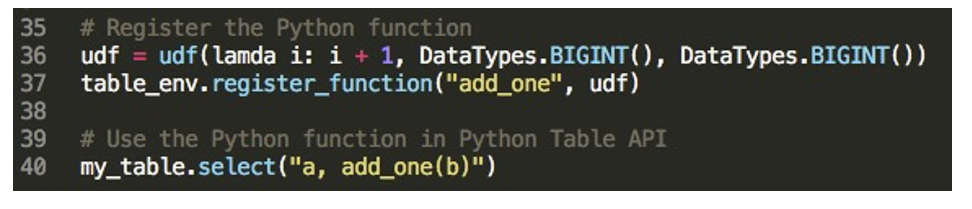
PyFlink-1.9 版本中,Python API 中支持注册使用 Java UDF,使用方法如下:可以调 TableEnvironment 上的 register_java_function 这个方法,有两个参数,一个参数是给 UDF 的命名,第 2 个是 Java 类的路径。
table_env.register_java_function(, )下面是一个例子:

可以调 TableEnvironment 上的 register_function 这个方法,有两个参数,一个参数是给 UDF 起的名字,第 2 个是 python_udf 的一个对象。
table_env.register_function(, python_udf)下面是一个例子:
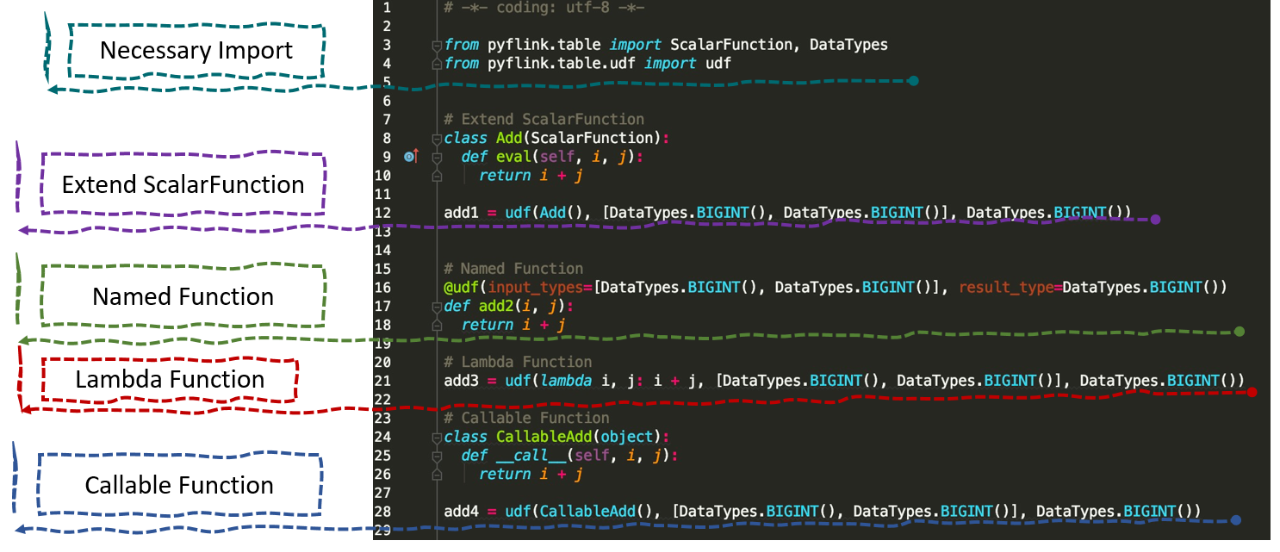
■ 3.Python UDF 的定义方式
PyFlink 里面也支持一些其他的方式去定义 UDF,我们可以看一下,总共有 4 种方式:
■ 4.依赖管理
写完 UDF 的时候,经常遇到一个问题,UDF 里面可能会有一些依赖,如何去解决这些依赖问题呢?PyFlink 提供了 4 种依赖的 API,如下所示。
如果 UDF 里面依赖一个文件的话,可以用 add_python_file 加载依赖的文件的路径,指定完之后,作业提交的时候,就会把这个文件分发到集群,那么在远程执行的时候,你的 UDF 就可以去访问这个文件。
table_env.add_python_file(file_path)可能会去依赖一个存档的文件,这个时候你可以用 add_python_archive 方法,传入两个参数。第 2 个参数是一个可选的参数。第 1 个参数表示对你存档文件的重命名。如果调用了 API,那么在 UDF 里面就可以去访问存档文件里面的所有文件。
table_env.add_python_archive(, ) 可以用 set_python_requirements 方法去指定你的第三方依赖。也是有两个参数,第 1 个参数是传一个文件,文件中写了所依赖的第三方项目,以及它对应的版本。第 2 个参数是一个可选的参数,如果集群是一个有网络的环境,那么第 2 个参数可以不填,当第 2 个参数不填的时候,作业提交开始初始化的时候, Python 就会去根据你的 requirements 文件里面配置的依赖,自动的去网络下载你的依赖,然后安装。如果集群是没有网络的,可以预先把这些依赖下载好,下载到 cached 的目录里面去。然后把目录也一起提交到集群,集群拿到这个目录会去安装这些依赖。
numpy== > requirements.txt pip download -d cached_dir -r requirements.txt --no- :all: table_env.set_python_requirements(, )假设你的 Python UDF 运行的时候,会依赖某一个版本的 Python 解释器。那么这个时候可以去指定你所希望 Python UDF 运行的一个解释器的路径。
table_env.get_config().set_python_executable()2.3、Pandas UDF & User-defined Metrics (PyFlink 1.11)
我们在 Pyflink 1.11 的版本里面提供了 Pandas UDF,还有用户自定义的 Metrics。当然 Pyflink 1.11 版本里面,不光是这两个功能,我这里主要是介绍一下这两个功能。Pyflink 1.11 版本也会即将在 2020 年的 6 月份进行发布。
接下来会从功能和性能两个角度来介绍一下 Pandas UDF。
■ 1.Pandas UDF – 功能
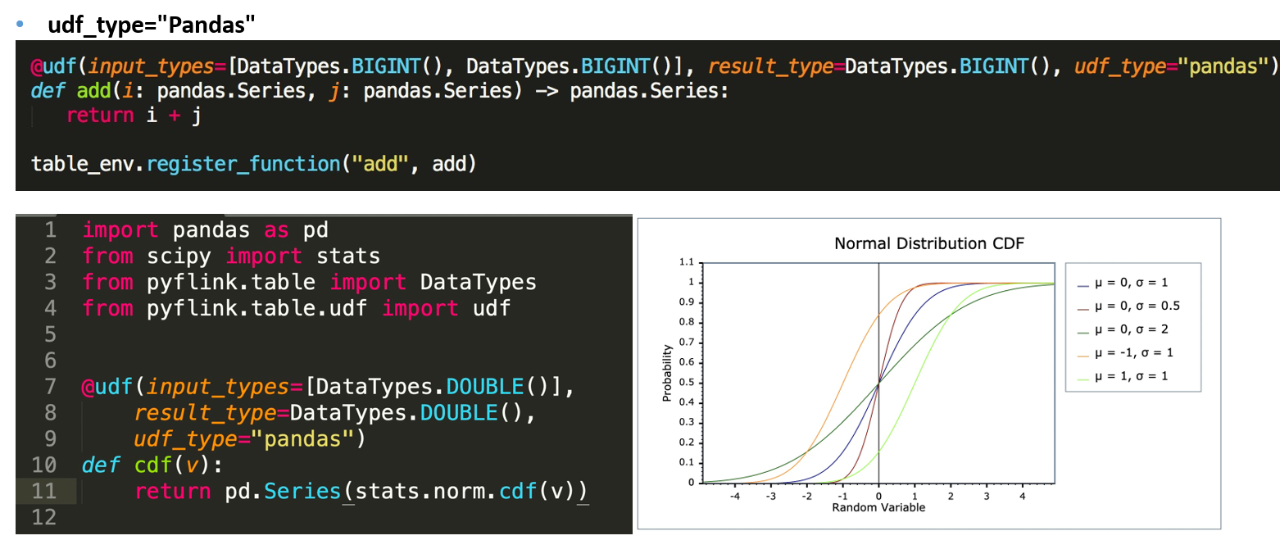
我们先来看一下功能方面,如果你要编写一个 Pandas UDF,那么跟刚才定义普通 UDF 的形式基本上是一致的。这里只需要去声明一个 udf_type,指定为 Pandas 就行了。
指定之后, UDF 运行起来的时候系统传的 i 跟 j 就变成一个 pandas.Series 的数据结构。这个时候可以直接用 series 来进行操作。与此同时会有一个好处,就是我们拿到的是一个 pandas 的数据结构,可以调用 pandas 相关的一些库函数,并且可以调用一些数值计算相关的库函数,这样可以极大的扩展功能。不需要再去实现一套逻辑。
■ 2.Pandas UDF - 性能
那么性能上 Pandas UDF 的好处,主要有两点。
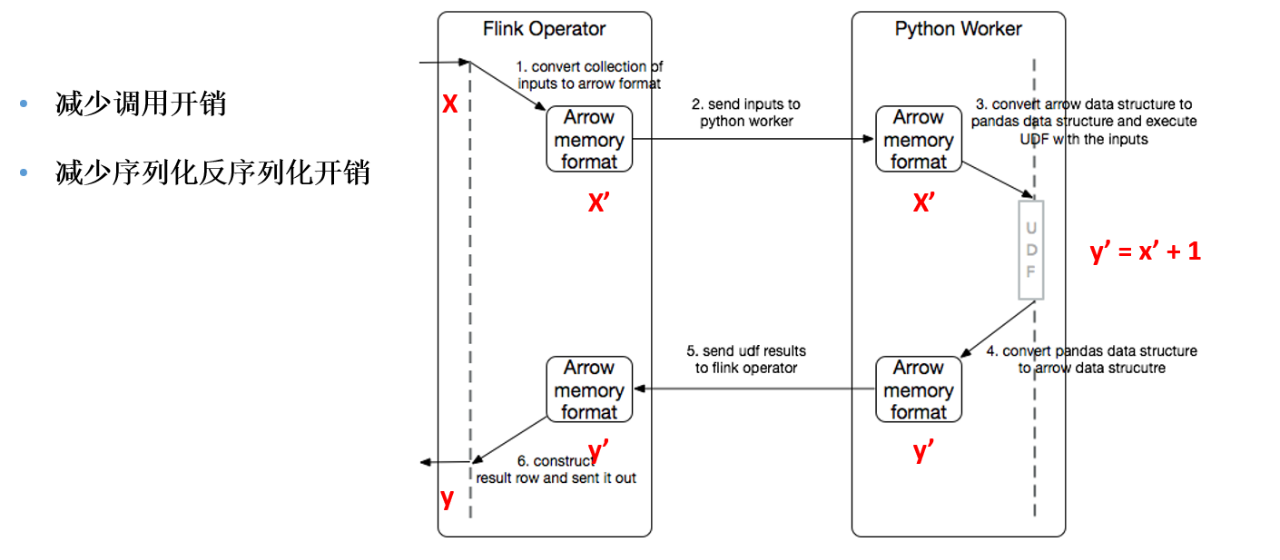
我们可以看一下右边这个图,左边是 Java Operator,右边是 Python Operator。假设 Operator 收到了一个 X,然后 X 在这里会进行一个序列化,变成 arrow 的内存数据格式,这个时候用 X’ 来表示。那么这个时候 Java 这边会把 X’ 传给 Python,Python 就可以直接来访问 arrow 数据结构,因为 pandas 底层的数据结构就是用 arrow 来表示的,所以这个时候不需要在 Python 进行反序列化,可以直接来操作 X’。然后在 X’ 加一之后,得到 Y’, Y’ 也是直接生成的 arrow 内存数据格式,这里也不需要反序列化。那么把 Y’ 传到 Java 时,就需要进行一个反序列化。
我们可以发现,只需要在 Java 进行一个序列化和反序列化。Python 这边可以省去了序列化和反序列化开销。
而且这里需要提出的一点是,如果你的输入 X 也是一个 arrow 的内存数据格式,那么 Java 这边的序列化跟反序列化也是可以避免的。比如你的 source 是一个 Parquet Source,那么它输出的数据格式也是 arrow 数据格式,这个时候就可以避免掉 Java 的序列化和反序列化。所以,Pandas UDF 也是可以减少序列化反序列化的开销。
■ 3.User-defined Metrics
我们再来看一下用户自定义 Metrics。
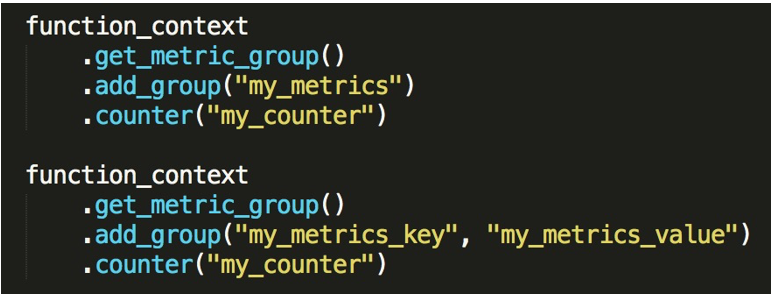
先来看一下 Metric 的注册,Metric 注册可以是在 metric_group 上调用对应的 Metric 方法来注册。

metric_group 还可以调用他的 add_group 方法去定义你的 Metric 的一个域,可以对 Metric 进行分类。
目前 PyFlink 里面提供的 Metric 类型有以下 4 种:
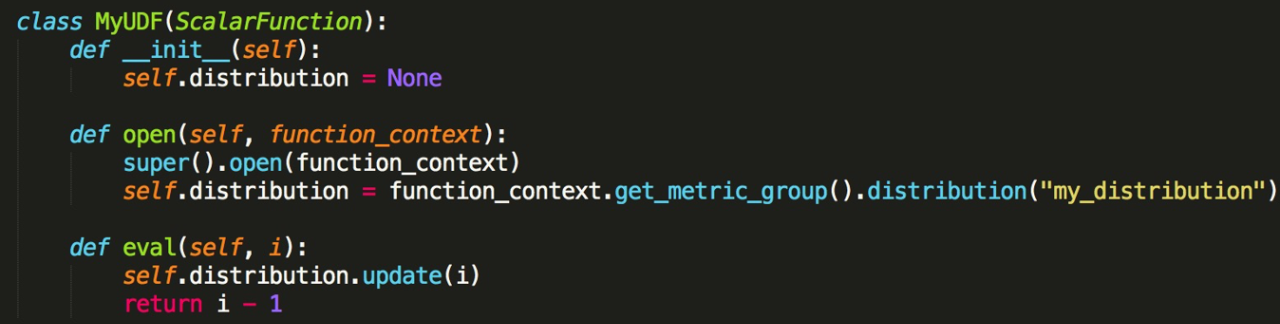
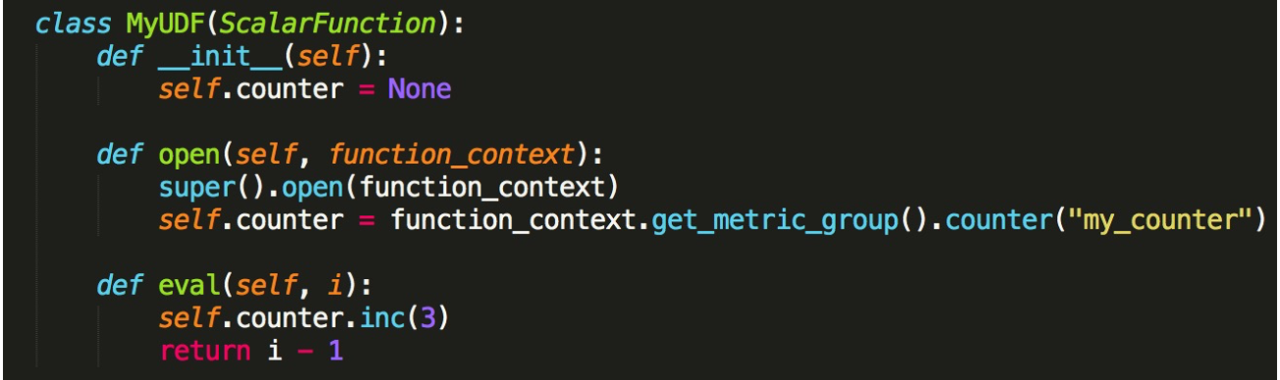
类似累加器。一开始需要在 open 方法里面进行 Counter 的注册,然后调用 match_group 上 Counter 方法,这里我们给了一个 Metric 的名字叫 my_counter。定义完之后,就可以在 Eval 方法里面进行使用。然后 Counter 可以提供 Inc 方法,你可以调用 Inc 进行相应的增加。
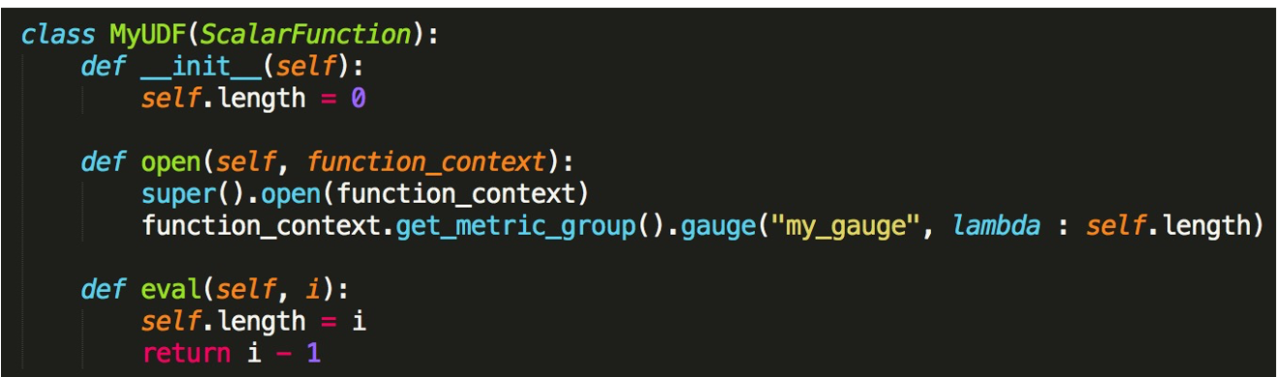
它是用来反映一个瞬时值。假设我们需要在 Metric 上显示 length 值的变化情况。那么我们需要用 Gauge 方法来注册,名字是 my_gauge。第 2 个参数这里需要注意它是一个 UDF ,我们需要返回要监控数值的值是什么,返回这个值。然后在 Eval 方法里或者其他 UDF 的调用里可以改变这个值。框架底层就会不断去汇报这个值当前值是多少。
Meter 这种 Metric 是表示当前这一秒往前一个时间区间内所有数值相加的一个均值。我们看可以调用 Meter 方法来注册。第 2 个参数是一个默认的参数,默认是 60 秒,表示 60 秒内所有值的一个均值。这里需要注意的是,Meter 每一秒都会去汇报当前这一秒往前 60 秒时间区间内,所有值的均值。可以用 Meter 的 mark_event 方法来汇报。
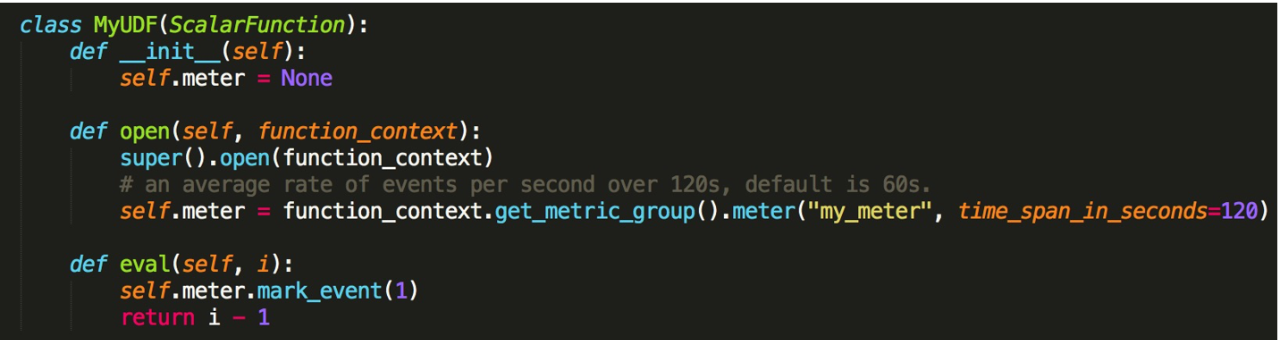
最后一种是 Distribution 的一个 Metric 类型,它对你的值能提供一些 sum/count/min/max/mean 等统计信息。可以调用 metric_group 上的 Distribution 这个方法。更新上可以调用 distribution.update。
3. PyFlink 的 Demo 演示
接下来对这些核心功能做一些 Demo 的演示跟讲解。此处我们提供了一个 playgrounds 的 git。主要是希望帮助大家更快速地熟悉 PyFlink 所有的功能及使用,并附上了相关代码示例。具体参考信息请见下方链接:
推荐阅读: