在ArchSummit深圳2018大会上,王绍翾(大沙)讲师做了《Flink SQL:使用标准的 ANSI SQL 驱动大数据流计算》主题演讲,主要内容如下。
演讲简介 :
近些年随着大数据技术的不断发展和成熟,无论是传统企业还是互联网公司都已经不再仅仅满足于批处理,对流处理的场景和需求也越来越强烈。SQL 是大数据处理中使用最广泛的语言。它允许用户简明扼要地声明他们的业务逻辑。数据分析师通常没有复杂的软件编程背景,但他们可以使用 SQL 来分析数据并为业务决策提供支持。
在流计算领域,除了 Flink 之外,其他一些流处理框架(如 Kafka 和 Spark Structure Streaming)也具有类似于 SQL 的 DSL,但它们与 Flink 的语义不同。Flink 的 SQL 完全遵循 ANSI SQL 标准,而 Spark 和 Kafka 提供的 DSL 都是非 ANSI SQL 标准的。本次分享将介绍遵循 ANSI SQL 标准的好处,以及 Flink SQL 是如何实现这一目标。阿里巴巴的核心业务现在完全由数据处理引擎 Blink 驱动,它是一款阿里巴巴实时计算部基于 Apache Flink 改进的项目。阿里内部几乎所有的 Blink 作业都是由 Flink SQL 编写的。本次分享也将介绍 Flink SQL 在阿里内部的大规模应用的场景和经验。
演讲提纲
讲师介绍 :
王绍翾(大沙)
阿里巴巴 计算平台事业部高级技术专家
王绍翾,淘宝花名"大沙",加州大学圣迭戈分校计算机工程的博士,2015 年加入阿里巴巴集团,目前就职于阿里巴巴计算平台事业部。加入阿里之前,曾在 Facebook 开发分布式图关系数据库 TAO。
加入阿里之后,王绍翾一直从事阿里新一代实时计算平台 Blink 的研发工作。早期负责搜索事业部的离线大数据处理,利用半年的时间带领团队将阿里淘宝天猫的搜索离线数据处理的计算全部迁移到了 Blink 计算平台之上。之后负责 Blink 计算平台的查询和优化。用了半年多的时间,打造了一套功能完备高性能的实时计算 Flink SQL,并成功的将阿里的实时计算机器学习平台整体的迁移到这套 API 之上。阿里将 Flink SQL 的代码几乎全部推回了 Apache Flink 社区。王绍翾是 Apache flink 的 committer,除了自己,他在团队内部还培养出另外两位 apache flink committer。

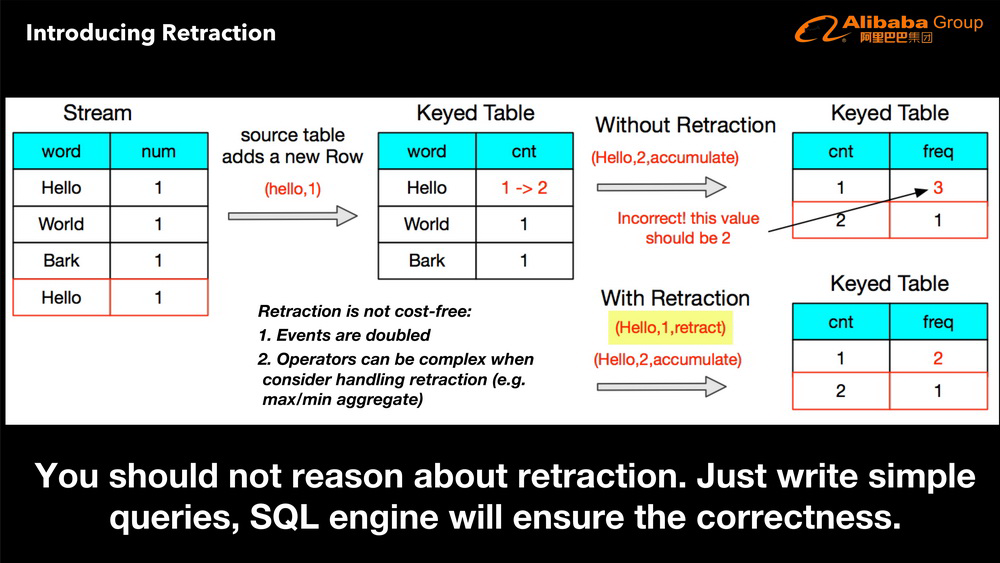

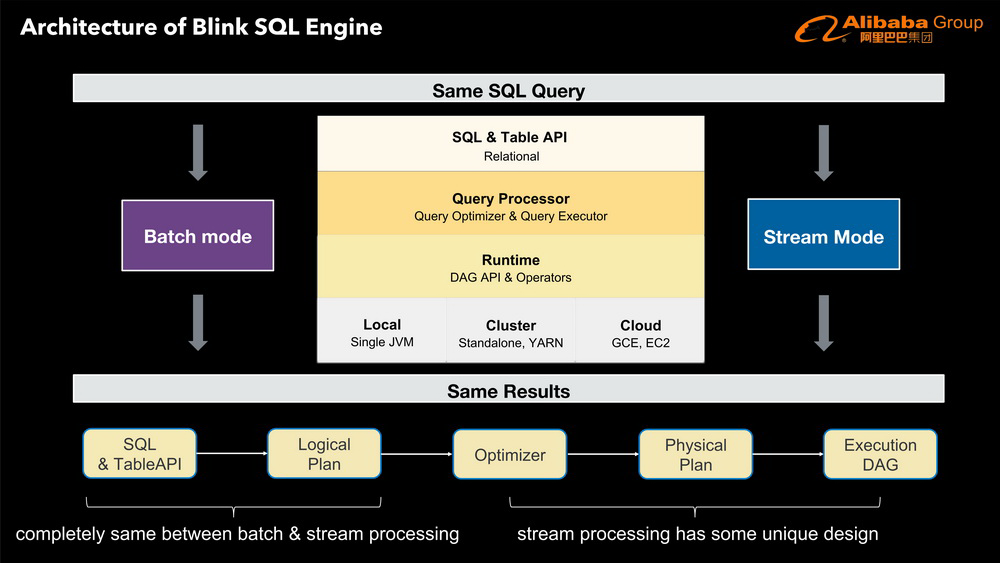
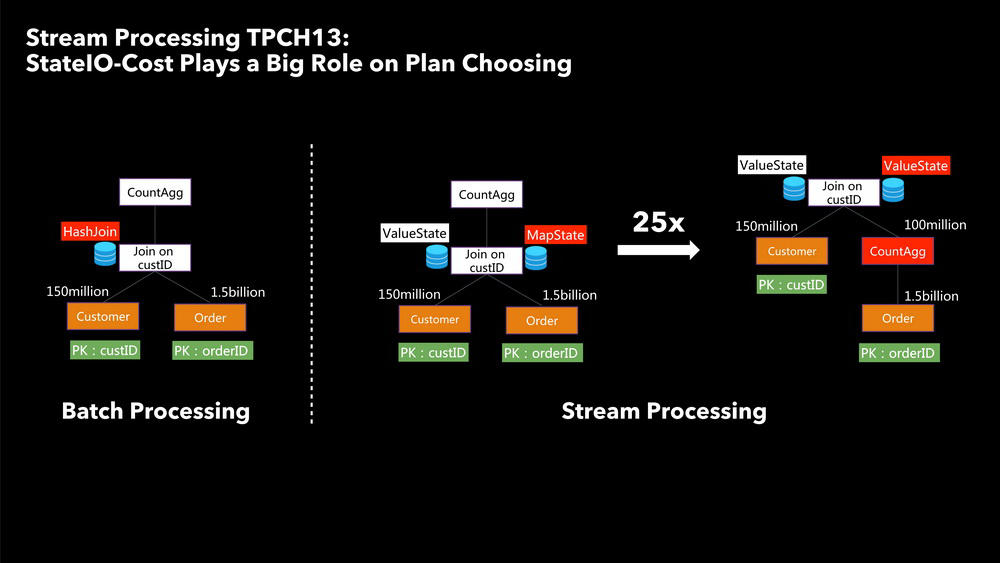
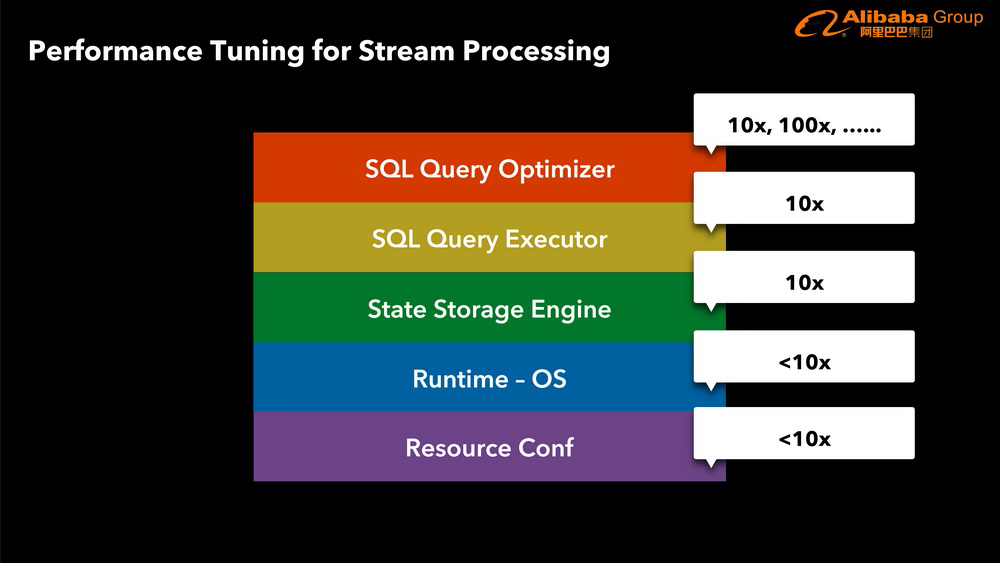
完整演讲 PPT 下载链接 :