
Big SQL 是 IBM 的基于 Hadoop 的平台 InfoSphere BigInsights 的 SQL 接口,旨在让 SQL 开发人员能够轻松地掌握对 Hadoop 管理的数据的查询。它使数据管理员能够为 Hive、HBase 或他们的 BigInsights 分布式文件系统中存储的数据创建新表。来自 IBM 的工程师 Cynthia 和 Uttam 对 Big SQL 做了简要的介绍。
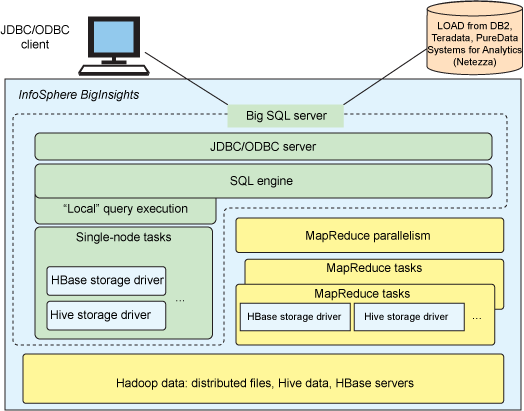
Big SQL 并没有将 Hadoop 转变为一种大型的分布式关系数据库。它是一个软件层,使 IT 专业人员可使用熟悉的 SQL 语句在 BigInsights 中创建表和查询数据。为此,程序员将会使用标准的 SQL 语法,并在某些情况下使用 IBM 创建的 SQL 扩展,使得利用某些基于 Hadoop 的技术变得非常轻松。Big SQL 的架构图如下:
Cynthia 和 Uttam 对此做了详细的介绍:
在这些和其他一些情况下,Big SQL 可能发挥着重要作用。但是,认为 Big SQL 会取代关系 DBMS 技术是不恰当的。Big SQL 旨在为基于 Hadoop 的基础架构提供补充并在 BigInsights 中利用该架构。关系 DBMS 系统的一些常见特性在 Big SQL 中并不存在,而且一些 Big SQL 特性在大多数关系 DBMS 系统中都不存在。例如,Big SQL 支持查询数据,但不支持 SQL或语句。语句仅支持用于 HBase 表。Big SQL 表可能包含具有复杂数据类型的列,比如和,而不是简单的 “扁平” 行。而且还支持一些基础存储机制,包括:
Cynthia 和 Uttam 举例说明了 Big SQL 的基本用法,比如创建一个 Big SQL 表并向其中加载来自本地文件的数据:
CREATE TABLE
语句创建一个包含两列的 Hive 表;第一列捕获一个数字代码,将它用作产品品牌的标识符,第二列捕获该品牌的一段英文描述。此语句的最后一行指定了该数据将用来存储(和想要的)输入数据的格式:以包含制表符分隔的字段的行格式。LOAD 语句,提供了本地文件系统中我们希望加载到表中的一个文件的完整路径。给定我们的表定义,此文件中的每个记录必须包含两个由(制表符)分隔的字段(一个整数和一个字符串)。子句告诉 Big SQL 将表的内容替换为文件中包含的数据。
传统事务管理不是 Hadoop 生态系统的一部分,所以 Big SQL 的运行未涉及到事务或锁管理。这表明提交和回滚操作不受支持,而且一些并发操作可能导致应用程序或查询错误。
关于性能方面的考虑因素,Cynthia 和 Uttam 也做了简要的介绍:




