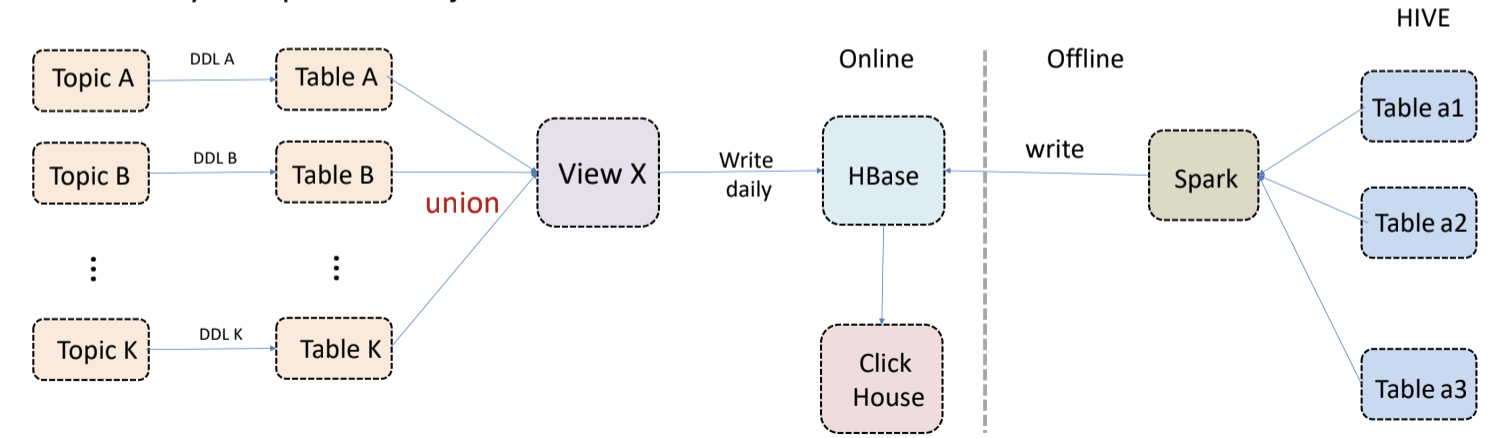
在数据驱动时代,高效的数据处理和分析能力已经成为企业竞争力的关键。在实际业务中,用户会基于不同的产品分别构建实时数仓和离线数仓。其中,实时数仓强调数据能够快速入库,且在入库的第一时间就可以进行分析,低时延的返回分析结果。而离线数仓强调复杂任务能够稳定的执行完,需要更好的内存管理。
ByConity 是字节跳动开源的云原生数据仓库,可以满足用户的多种数据分析场景。2024 年 8 月,ByConity 增加了 bsp 模式:可以进行 task 级别的容错;更细粒度的调度;基于资源感知的调度。希望通过 bsp 能力,把数据加工(T)的过程转移到 ByConity 内部,能够一站式完成数据接入、加工和分析。
为了让更多的开发者深入了解并体验 ByConity bsp 模式的能力,InfoQ 和 ByConity 社区联合举办“ByConity 有奖众测活动”,邀请广大开发者参与 ByConity bsp 模式在离线数仓场景的实际测试,通过亲身实践来感受其带来的高效与便捷。
ByConity 有奖众测参与指南
活动时间
2024 年 12 月 2 日 - 2024 年 12 月 20 日
众测要求
本次众测活动共提供两种测试类型,以满足不同用户的需求。
标准测试
进阶测试
参与方式
点击链接或者扫码海报报名二维码参与,参与标准测试开发者需完成测试并产出测试文章并发布,参与进阶测试开发者需在自有场景成功完成测试,能够胜任离线数仓的负载,并有对应测试文档产出并发布。

参与者可添加小助手进答疑群
参与奖品
标准测试 :
进阶测试 :社区周边 + 进阶测试激励。
ELT 任务对系统的要求
ByConity 对 ELT 能力的优化
提升任务并行度,保障业务平稳运行
传统架构中,之所以要分别建设离线数仓和实时数仓,是因为常见的 OLAP 产品不擅长处理大量的复杂查询,很容易把内容打满任务中断,甚至造成宕机。
ByteHouse 具备 BSP 模式,支持将查询切分为不同的 stage,每个 stage 独立运行。在此基础上,stage 内的数据也可以进行切分,并行化不再受节点数量限制,理论上可以无限扩展,从而大幅度降低峰值内存。
任务级重试,减少重试成本
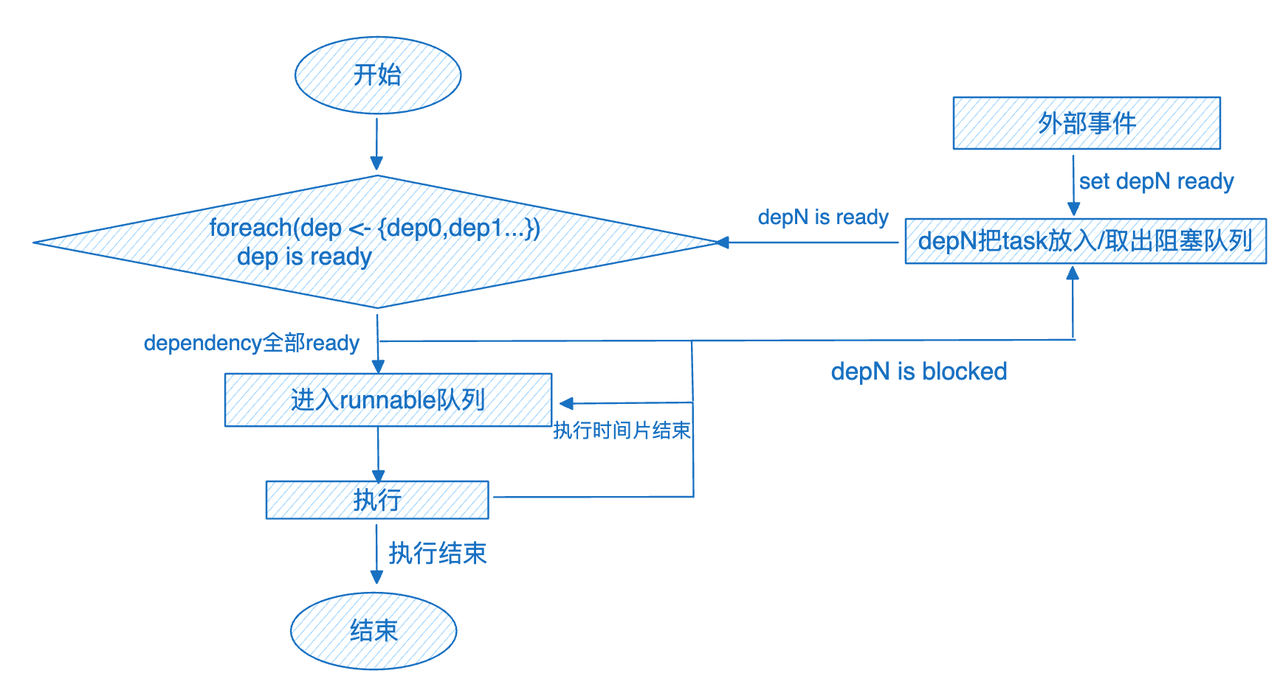
离线加工任务的另外一个特点就是链路比较长,并且任务间有依赖关系。如下图所示,
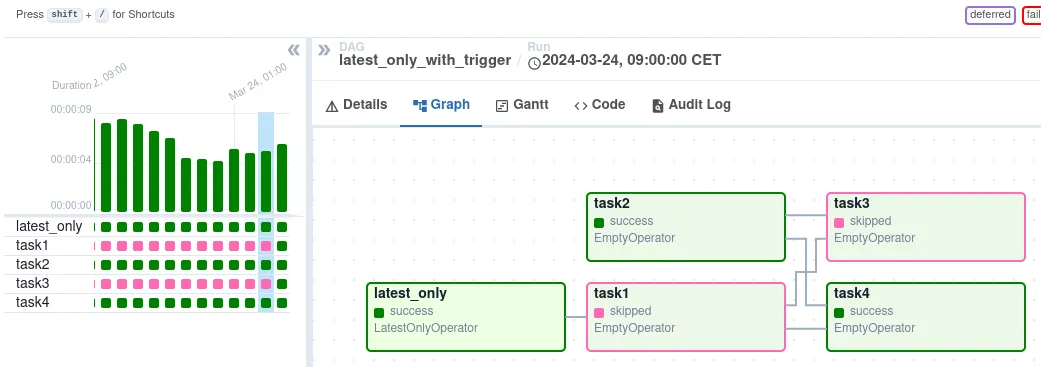
如上图所示,task4 依赖 task1、task2 的完成。如果 task1 失败发起重试,会显示为整个链路执行失败。ByteHouse 增加了任务级重试能力,在 ByteHouse 中只有运行失败的 task 需要重试。
大批量并行写入,稳且快
实时数仓存在频繁更新的特点,使用重叠窗口进行批量 ETL 操作时,会带来大量的数据更新。在这种场景下,ByteHouse 做了大量的优化。
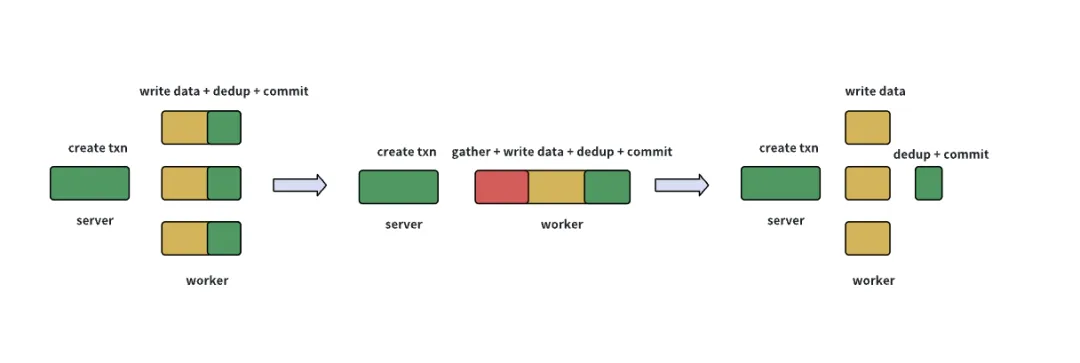
写入优化示意图
经过持续优化,将最耗时的数据写入部分单独并行化,并且在写入 part 文件时标记是否需要进行后续的 dedup 作业。在所有数据写入完毕后,由 server 指定一个 worker 进行 dedup 和最后的事务提交(如上图最右)。
简化数据链路,提高健壮性
ByteHouse 在传统的 MPP 链路基础上增加了对复杂查询的支持,这使得 join 等操作可以有效地得到执行。在数据交换方面,要求所有 stage 之间的依赖必须在查询执行之前以网络连接的形式体现。离线加工场景下,这种方式有着天然的劣势:
BSP 模式使用 barrier 将各个 stage 进行隔离,每个 stage 独立运行,stage 之内的 task 也相互独立。即便机器环境发生变化,对查询的影响被限定在 task 级别。且每个 task 运行完毕后会及时释放计算资源,对资源的使用更加充分。
在这个基础上,BSP 的这种设计更利于重试的设计。任务失败后,只需要重新拉起时读取它所依赖的任务的 shuffle 数据即可,而无需考虑任务状态。
期待开发者持续关注 ByConity,同 ByConity 一起开启开启数据仓库的新篇章。