1 背景
当前 Hadoop 集群版本是 2.7.3,社区最新 Hadoop 生产版本是 Hadoop3.2.0(rbf1.0),随着集群规模及数据量的增加,单 NameNode 产生了性能及稳定性瓶颈:
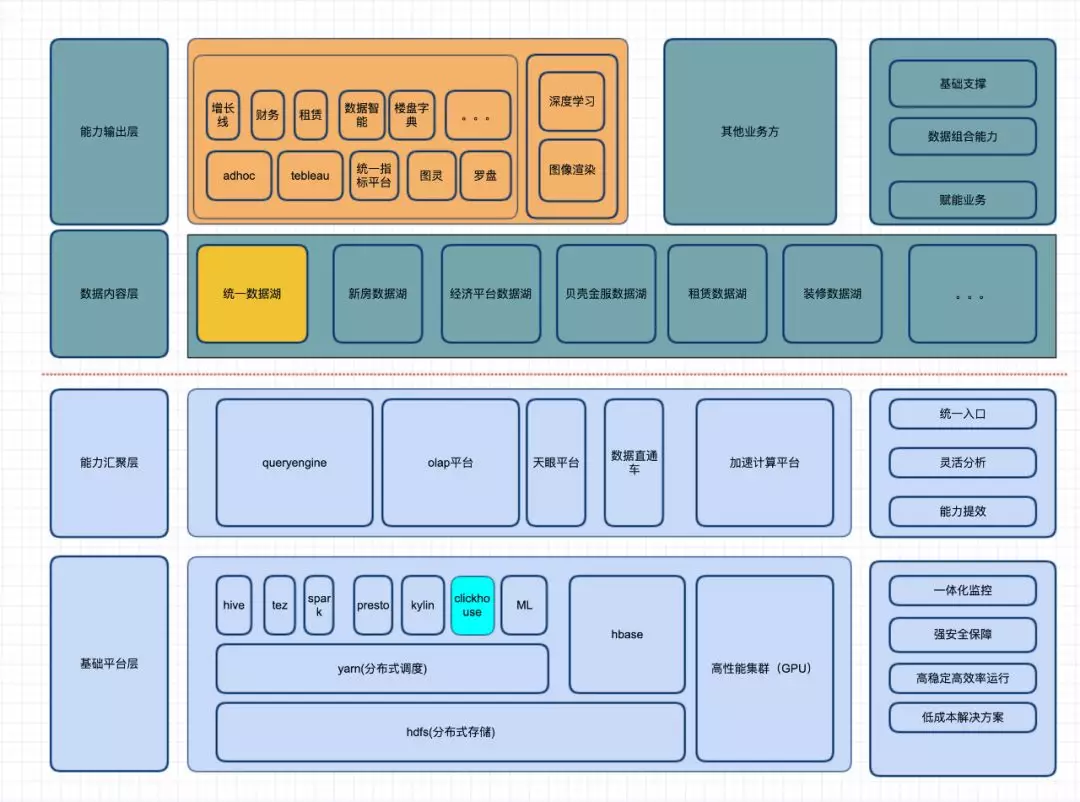
2 大数据架构
3 基本概念
Federation
为了 namespace 横向扩展,federation 使用多个各自独立的 Namenodes/namespaces.。这些 Namenodes 组成联邦组织,每个 namenode 之间不需要交流.。所有的 namenode 共享所有的>
多 namenode 拥有一个集群的编号 clusterid,如果某个 namenode 格式化时,不是使用相同的 clusterid 说明处于不同的集群。Block pool(块池)就是属于单个命名空间的一组 block(块)。Datanode 是一个物理概念,而 block pool 是一个重新将 block 划分的逻辑概念,同一个>
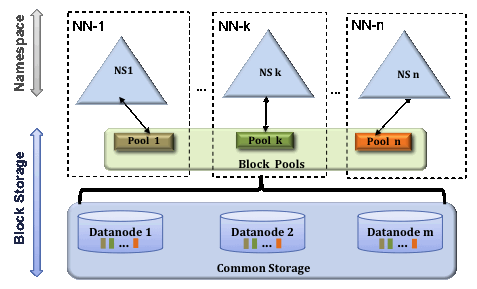
视图文件系统(View File System ,ViewFs)提供了管理多个 Hadoop 文件系统命名空间的方式,该系统在 HDFS federation 的集群中有多个 NameNode(因此有多个命名空间)是特别有用。
mounttable
目录挂载配置表,我们做到 hdfs 目录和 viewfs 目录一致。
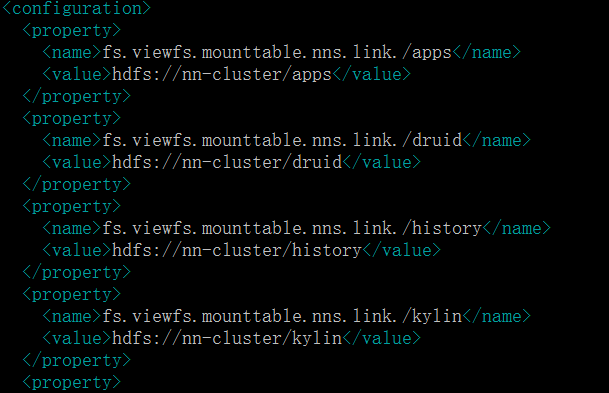
原理:
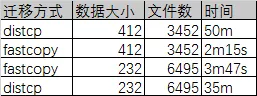
二次开发:由于HDFS-2139是单客户端执行方式,相比distcp有数十倍的性能提升,但对于拷贝上亿文件快,几P的数据速度仍然无法满足需求,将fastcp改为分布式模式执行。hadoop distfastcp-strategy dynamic-prbugpcaxt -update -skipcrccheck -i -deletehdfs://ip:9000/$1hdfs://ip:9000/$1我们将distcp数据拷贝逻辑改造为fastcp逻辑,将distcp中的CopyMapper中的copyFileWithRetry改为调用fastcopyFastCopy.CopyResult c = fcp.copy(sourceFileStatus.toString(), target.toString(), (DistributedFileSystem) srcFileSys,(DistributedFileSystem) targetFS);解决map数据倾斜(利用dynamic strategy,同时将UniformSizeInputFormat的getSplits按照文件个数划分)解决文件更新覆盖删除等问题扩展acl属性及存储策略的拷贝BlockStoragePolicy[] policies =((DistributedFileSystem)fileSystem).getStoragePolicies();HdfsFileStatus status = ((DistributedFileSystem)fileSystem).getClient().getFileInfo(fileStatus.getPath().makeQualified(fileSystem.getUri(), fileSystem.getWorkingDirectory()).toUri().getPath());byte storagePolicyId = status.getStoragePolicy();for (BlockStoragePolicy p : policies) {if (p.getId() == storagePolicyId) {copyListingFileStatus.setStoragePolicy(p.getName());if(srcFileStatus.getStoragePolicy()!=null) {((DistributedFileSystem) targetFS).setStoragePolicy(path, srcFileStatus.getStoragePolicy());多线程列表生成器,如果分区文件较大,单线程列表生成器成为瓶颈导致任务启动慢if (explore) {CountDownLatch countDownLatch = new CountDownLatch(sourceFiles.length);ExecutorService listFileExecutor= Executors.newFixedThreadPool(100);for (FileStatus sourceStatus : sourceFiles) {listFileExecutor.execute(new ListFile(countDownLatch,sourceFS,sourceStatus,sourcePathRoot,options,preserveAcls,preserveXAttrs,preserveRawXAttrs));countDownLatch.await();listFileExecutor.shutdown();以下为 fastcp 和 distcp 的效率对比:
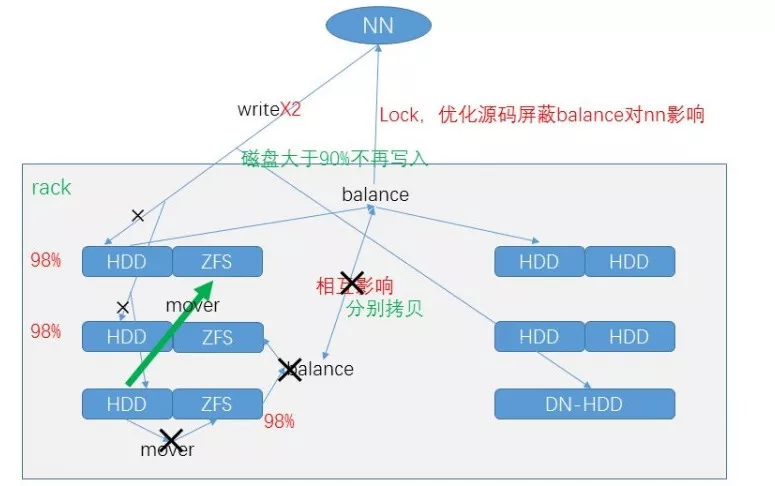
4Balance&Mover
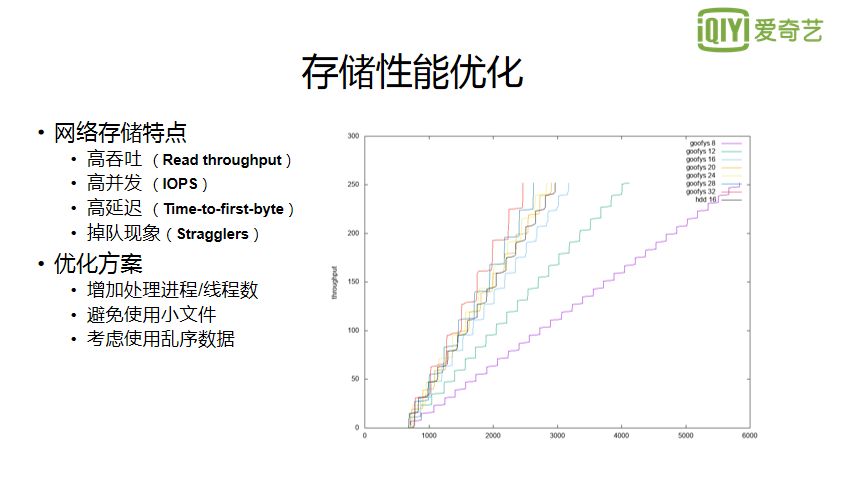
balancer 是当 hdfs 集群中一些>
MOVER 定期扫描 HDFS 文件,检查文件的存放是否符合它自身的存储策略。如果数据块不符合自己的策略,它会把数据移动到该去的地方。fastcp 是通过硬链接的方式来加速数据的拷贝,但同时会占用磁盘的大小,fastcp 前需要保证>
由于我们使用了基于 ZFS 的透明压缩方案,即>
针对不同存储策略的 balance:
for (DatanodeStorageReport r : reports) {final DDatanode dn = dispatcher.newDatanode(r.getDatanodeInfo());LOG.info("DFSConfigKeys.DFS_BALANCE_ONLY_DISK :"+ typeStore );if (this.typeStore) {for (StorageType t : StorageType.getMovableTypes()) {if ("DISK".equals(t.name())) {dispatcher.getStorageGroupMap().put(g);for (StorageType t : StorageType.getMovableTypes()) {mover限定磁盘占用率高server:static HashSet<String> getNameNodePathsToMove(Configuration conf,String... args) throws Exception {final Options opts = buildCliOptions();CommandLineParser parser = new GnuParser();CommandLine commandLine = parser.parse(opts, args, true);return getNameNodePaths(commandLine, conf);private static HashSet<String> getNameNodePaths(CommandLine line,Configuration conf) throws Exception {HashSet hashSet = new HashSet();BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(line.getOptionValue("d")), "UTF-8"));String line;while ((line = reader.readLine()) != null) {if (!line.trim().isEmpty()) {hashSet.add(line1);IOUtils.cleanup(LOG, reader);return hashSet;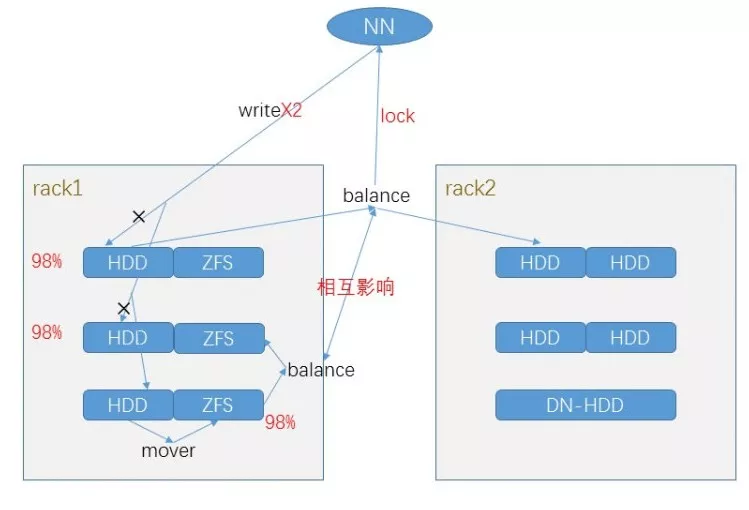
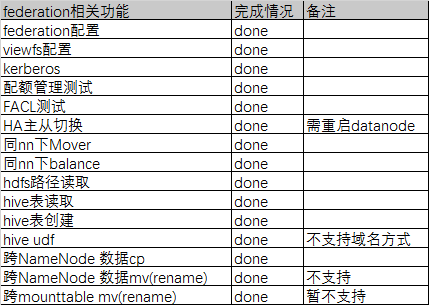
5 测试
**功能**
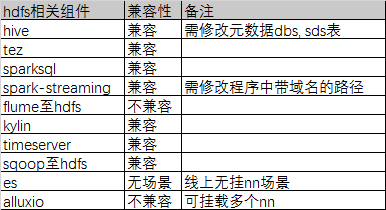
**兼容性**
6 相关 Patch
配置, hive.exec.stagingdir)
表空目录读取,新分区写入,spark 依赖此包)
jar failing with url schemes)
,需更新>
7 数据划分方式
做好合理的数据划分方式是解决问题的关键,主要由两种方式:
根据 hdfs 目录划分,可以对 namenode 流量进行分流,做到业务数据分割,但需要对客户端有极强的掌控能力,拷贝数据时需要较长的时间,集群停服务时间达数小时以上。根据表的分区划分,可以将历史冷数据拷贝至单独的 namenode,但会导致 mounttabl 异常复杂,历史数据一旦变更会有较大的风险。
结合数据特点和业务需求及 namenode 的瓶颈,我们决定将 stg 层数据迁移至新的 namenode,目前 stg 层数据主要有三种接入方式,flume,sqoop,databus(贝壳找房自研数据流转工具),我们对这三个工具有较强的掌控力。迁移时再根据分区进行分批迁移,来解决集群长时间停服务对实时任务及 etl 任务的影响,做到平稳迁移。同时我们也把 yarn.log-aggregation 目录迁移至新的 namenode。
8 域名格式兼容性
通过运营手段解决 viewfs 兼容性问题:
9Viewfs 上线步骤
10 总结 &展望
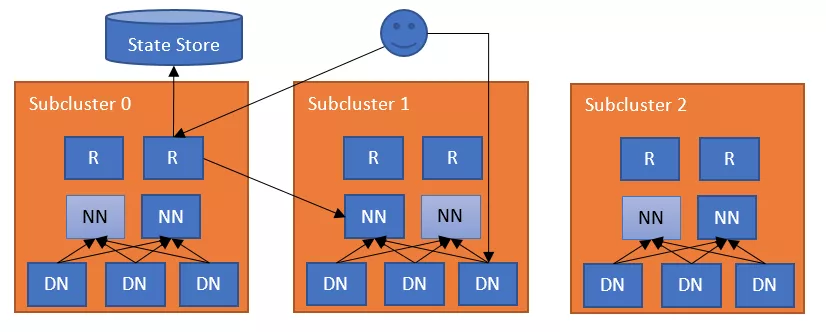
federation 一期我们主要迁移 stg 层数据,可降低 namenode 内存 30%,后续随着数据的增加我们再进行不同业务间的数据迁移 viewfs 需要对 hadoop 客户端有一定的掌控能力,我们也会对 RBF 进行调研引入,屏蔽 mounttable 的修改对客户端的影响,RouterFederation 每个 NameNode 作为一个子集群挂载到 RF 层,挂载信息保存在 Zookeeper 中。
RF 可以具有多个 DfsRouter 进程,负责接收用户的请求,并从 Zookeeper 中获取 Mount 信息。同时,每个 NameNode 会定时向 RF 发送心跳信息,RF 会感知 NameNode 的存活以及在 HA 状态下的 Active 状态。
作者介绍:
数大大(企业代号名),贝壳找房大数据工程师,大数据架构团队成员,目前主要负责 hadoop,hive 集群。
原文链接: