金融大数据风控模型的技术方法
1. 风险管理中的金融科技

风险管理中的金融科技主要包括两个方面:
一方面是传统金融的风险管理,包括:
三张评分卡,是传统金融科技中的一部分。
另一方面是信息技术,包括:
利用信息技术能力能够有效提升传统风险管理评分卡建模的效果。
2. 度小满信贷风险
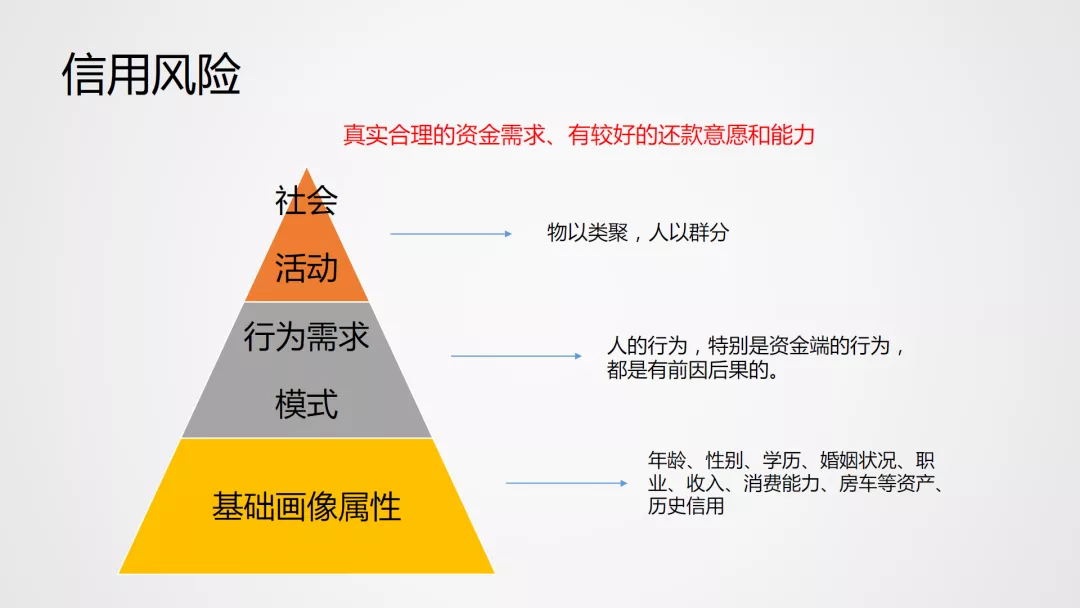
在度小满信贷业务发展过程中,积累了大量数据和模型相关的实战经验。下面主要介绍关于信贷风险模型在度小满的实战经验。如何去识别信用风险,其核心关键点在于识别借款用户真实合理的资金需求以及评估用户是否拥有较好的还款意愿和能力,主要包括三个方面:
核心而言,利用用户的基础画像、行为需求,外延到用户社会活动去挖掘用户是否有真实合理的资金需求,是否有较好的还款意愿和还款能力,从而建立区分度良好的风险模型。
3. 时间序列的处理:贷前
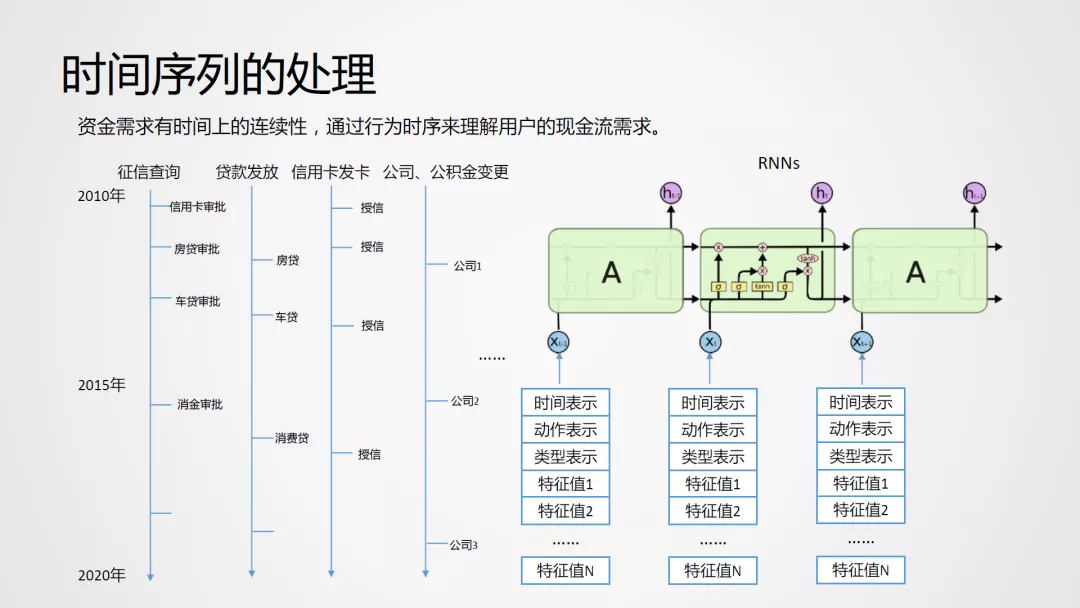
信贷业务通过用户授权获取征信报告,基于征信报告了解用户的信用历史,通过分析用户的行为时序来理解用户的真实现金流需求。
相比传统方案,基于这类机器学习的方案能够带来 KS 2 个点的提升。
4. 时间序列的处理:贷中
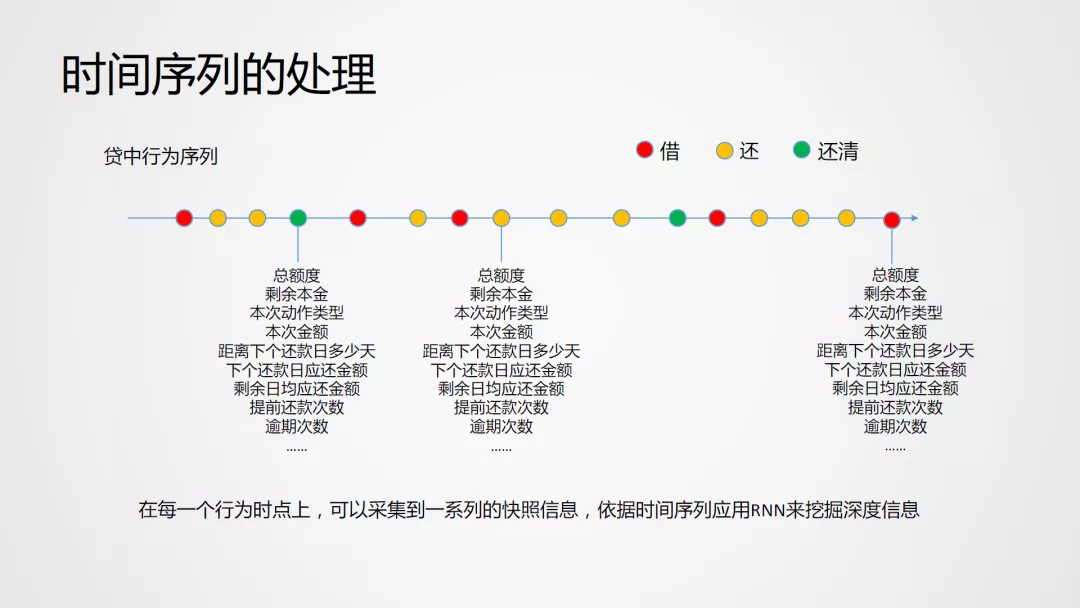
信贷贷中行为数据主要用于 B 卡的建模,在整个客户生命周期线上,用户存在不断借钱、还钱的循环往复行为。基于此,在每个动作发生的时间切片上,可以生成诸如总额度、剩余本金、本次动作类型、本次金额、距离下个还款日多少天、下个还款日应还金额、剩余日均应还金额、提前还款次数、逾期次数等特征,将这些特征组织成 item,通过各类 RNN 网络能够显著提升 B 卡的能力。
5. 文本类数据处理
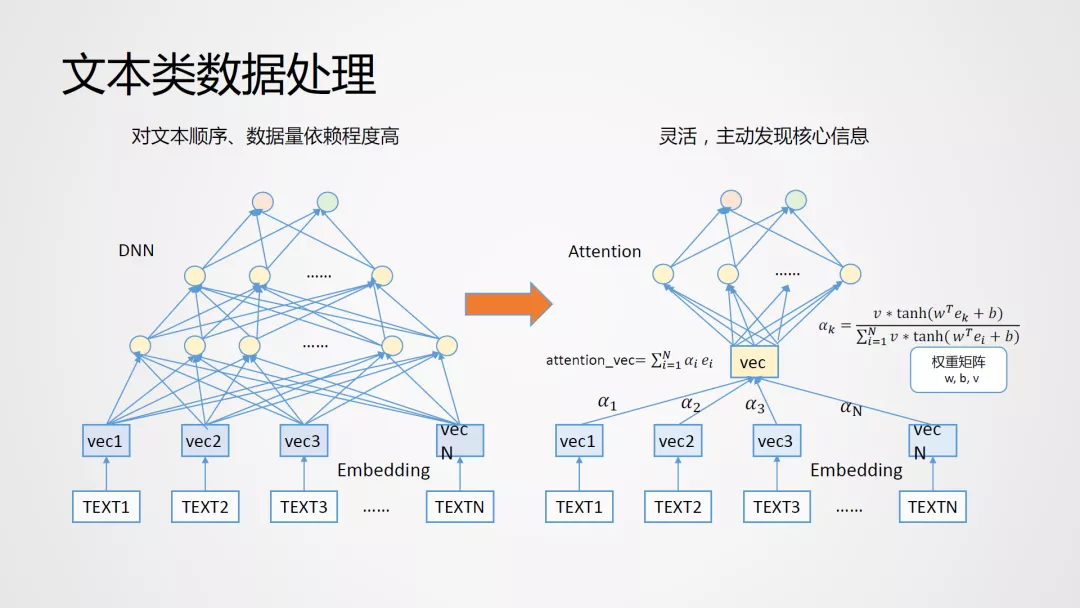
互联网行为数据除了结构化数据外,还存在许多非结构化数据,诸如文本类数据。传统金融的很多数据都是数值类的数据,类似收入水平等变量,这些数据一般具有置信度高、分辨率强的特点,而互联网数据则有数据规模大,数据杂乱,且分辨力较弱的特征。传统文本处理的方式一般对文本特征进行排序,构建全连接层深度网络 DNN,这种处理方式强依赖于文本的顺序,会存在稀疏性、泛化能力弱等缺陷。我们参照 Attention 机制的核心思想,关注每个信息单元在整体中的重要度α,由于α是基于信息单元集合实时计算得到,依赖于 Input 但与 Input 的顺序无关, 所以特别适用于那些原本就没有顺序依赖关系的文本内容集合。基于此框架,该方案无需关注文本特征的顺序,这对于整个模型的特征处理逻辑上而言是非常友好的,通过不断提供新的数据,能够让模型网络更加灵活高效。
6. 关联网络
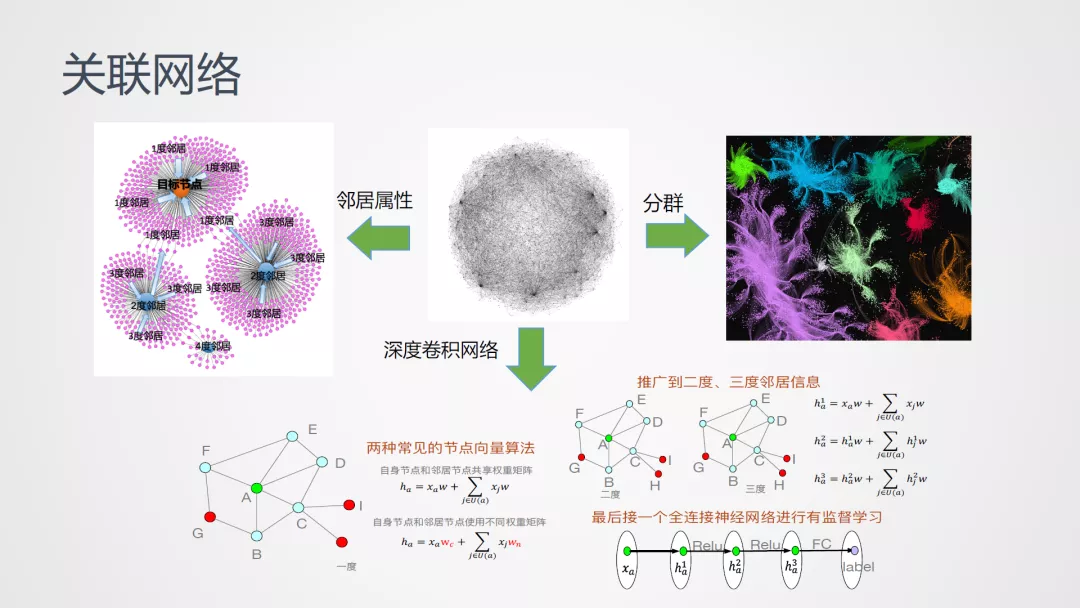
图在金融科技侧的应用十分广泛。对于图在度小满的落地应用,和传统构建图的方式相同,通过构建密集网络主要包括三个方面的输出:
单一应用方向对识别信用风险可能较弱,但通过三种方式的组合,能够显著提升模型的风险识别能力。
金融大数据风控模型应用层面的问题
1. 模型可解释性
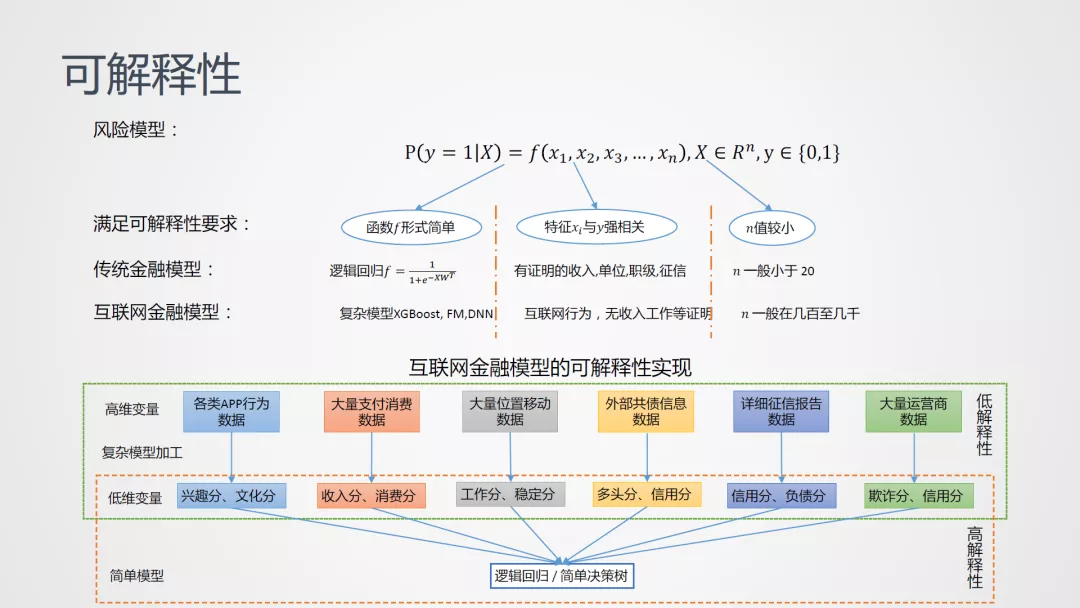
信用风险的核心即构建一个二分类的模型,而可解释性是策略同学应用模型的一个重要诉求。一个可解释的模型主要有以下三个方面的特点:
基于上述多个子模型评分,再利用逻辑回归或简单决策树构建最终的模型。由于每个低维变量评分和人的认知接近,且与风险有很好的线性相关性,整个模型就有了很好的解释性。同时,对模型质量的监控也变得更加容易了。当模型出现问题时,可以很容易定位到可能出现问题的子模型分,然后再依据子模型评分去寻找对应的底层数据的异常。
2. 概率标准化
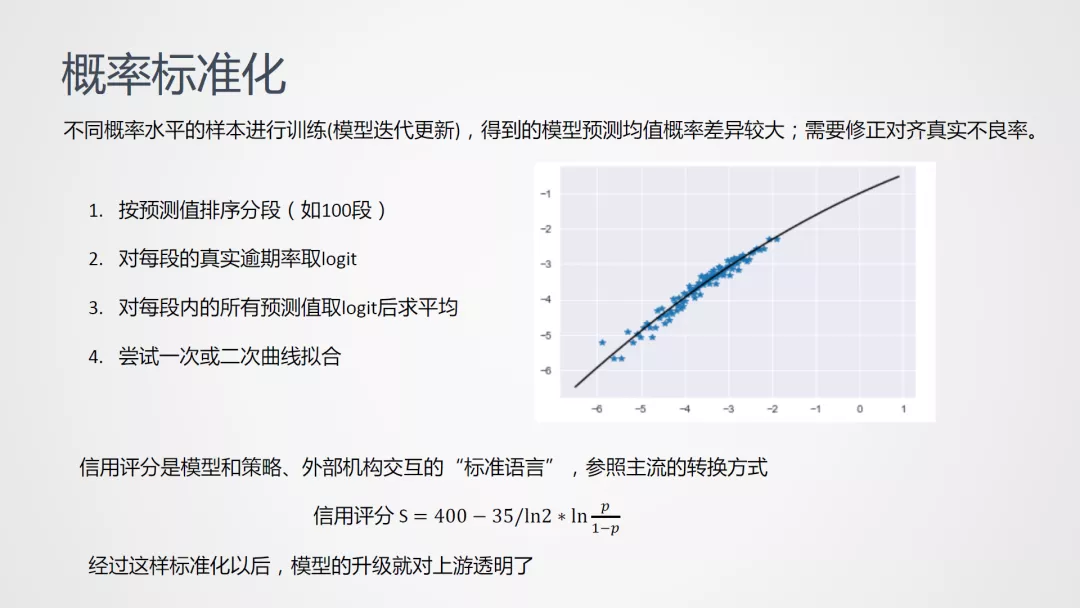
不同概率水平的样本进行训练,得到的模型预测均值差异较大,这对策略应用的同学带来很大挑战。基于此,我们需要对不同的模型修正对齐真实的不良率,具体步骤如下:
经过上述标准化后,模型与样本数据集或样本不良率无关,模型的升级就对策略、业务同事更加透明。
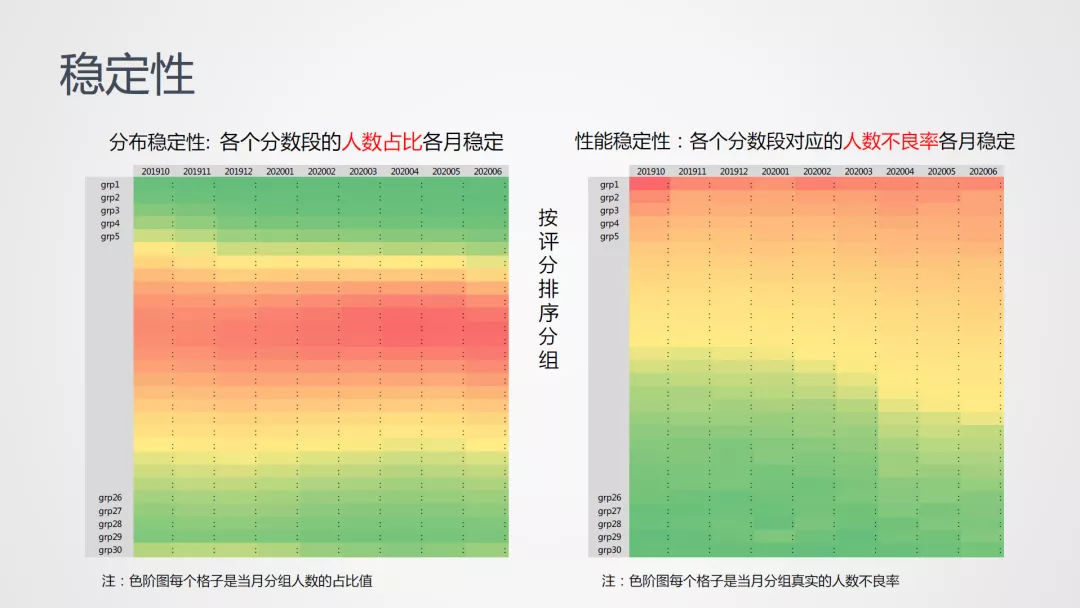
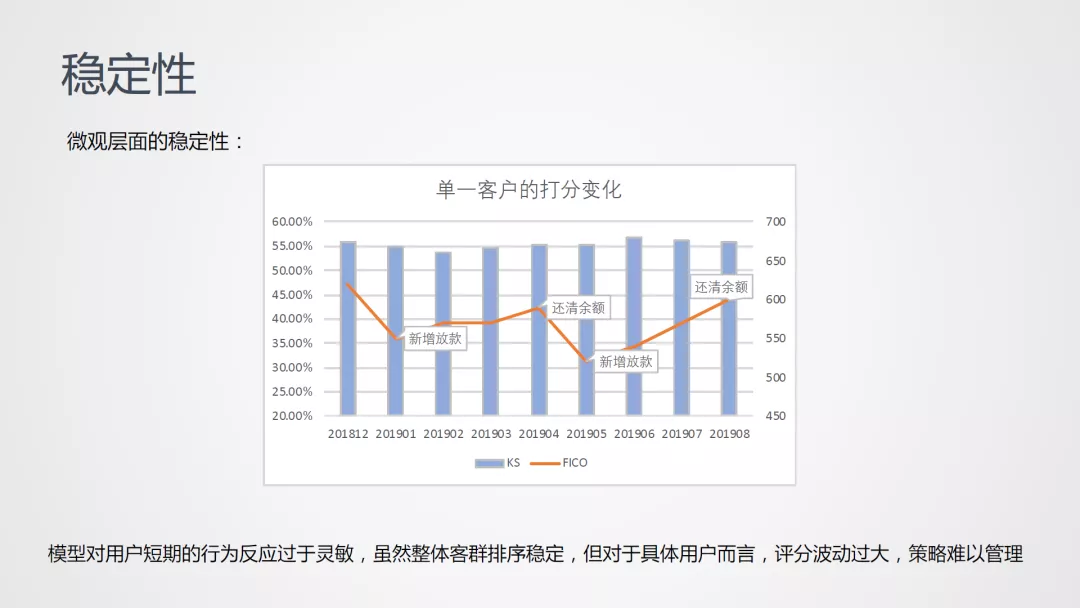
3. 评分稳定性
评分稳定性包括分布稳定性、性能稳定性以及微观层面的稳定性三方面:
新冠疫情背景下,风控模型的一些探讨
1. 疫情影响
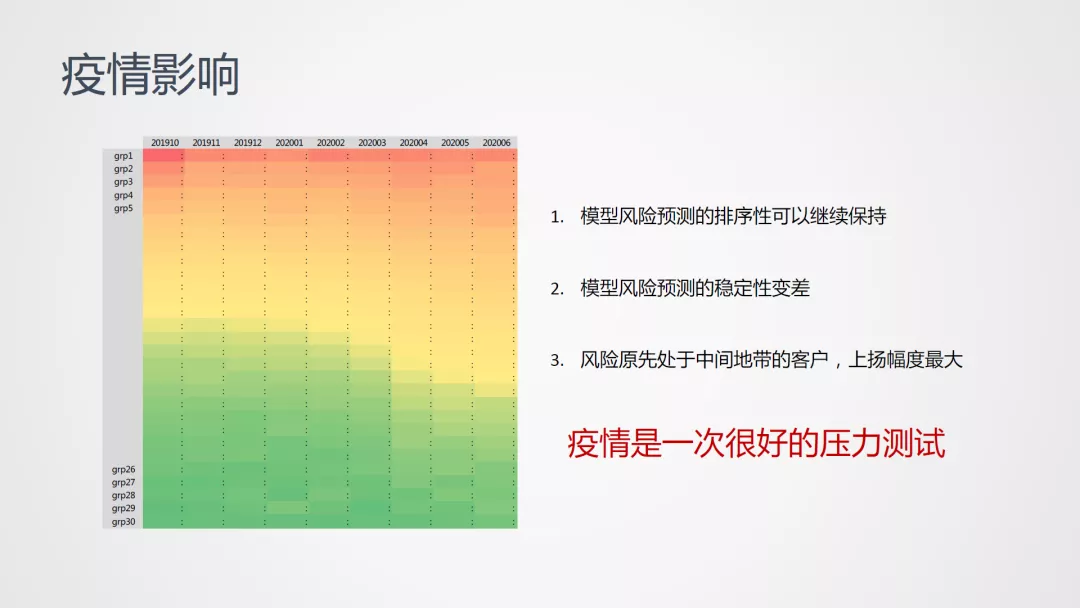
新冠疫情是对业务、策略、模型一次很好的压力测试;以前面的用于评估稳定性的图示来看,主要表现在受疫情影响的多个时间窗口下绿色、黄色下沉,该图示包含了以下三个方面的信息:
疫情归根到底其实是对客户、风险模型、策略的一场考验。
2. 疫情对模型的影响和挑战
疫情并不会改变用户的特征 X,但在疫情下同样 X 对应的 Y,即风险水平则会显著上升。在实际业务场景中,我们观察到诸如多头类变量最为明显。有一些思考和探索供参考:
问答环节
1. 什么特征可以反映疫情下的宏观经济情况?
答:这是一个极为有挑战性的问题,在我们实际业务应用发展中,复工指数对整个资产模型的贡献度较高,其实际与用户的收入存在较为强的联系。从隐私的角度很难拿到用户的收入情况,在实际应用中,我们通过位置迁移来推测用户的复工状态。
2. 对比高维变量入模效果与分开计算模型效果?
答:高维变量入模和分开入模 KS 偏差幅度在 0.5%左右,并不能说高维变量直接入模就一定好于分开入模,不同模型有±0.5 的不同表现。从整体的角度来看,我们认为结果差距并不是特别大。高维变量入模缺点在于参数较多,对数据质量监控有一定的难度,发现问题较难且可解释性较差。
原文链接:度小满金融大数据风控模型实践