Fiber,让人工智能的分布式计算变得简单。
项目地址:机器学习的最新进展一直都是通过不断增加的计算量来实现的。越来越多的算法利用并行性,并依靠分布式训练来处理海量数据。无论是对更多数据的需求,还是对更多训练的需求,都对管理和利用大规模计算资源的软件提出了巨大的挑战。
在 Uber 内部,我们开发了、GO-Explore、等算法,这些算法都利用了大量的计算。为了让未来的大规模计算能够实现这样的算法,我们开发了一个名为的新系统,它可以帮助用户将原本只能在本地进行的计算轻松地扩展到数百甚至数千台机器上。
大规模分布式计算的挑战
在理想情况下,将在一台机器上运行的应用程序扩展到在一组机器上运行的应用程序,应该与更改命令行参数一样简单。然而,在现实世界中,这并不是一件容易的事。
在与许多每天运行大规模分布式计算作业的人们一起工作时,我们发现,为什么很难利用分布式计算,有几个原因可以解释:
新的 Fiber 平台明确地解决了所有这些问题,有望为更广泛的用户群开放无缝的大规模分布式计算。
Fiber 简介
是一个基于 Python 的现代计算机集群分布式计算库。现在,你可以为整个计算机集群进行编程了!而不是为你的台式机或笔记本电脑编程。最初,它是为像这样的大规模并行计算项目开发的,现在已经被用于 Uber 内部的类似项目。Fiber 的主要特点包括:
此外,在性能至关重要的领域,Fiber 可以与其他专用框架一起使用。例如分布式 SGD,许多现有框架如或touch.distributed,就已经提供了非常好的解决方案。通过使用 Fiber 的 Ring 功能,Fiber 可以与这些平台一起工作,以帮助在计算机集群上设置分布式训练作业。
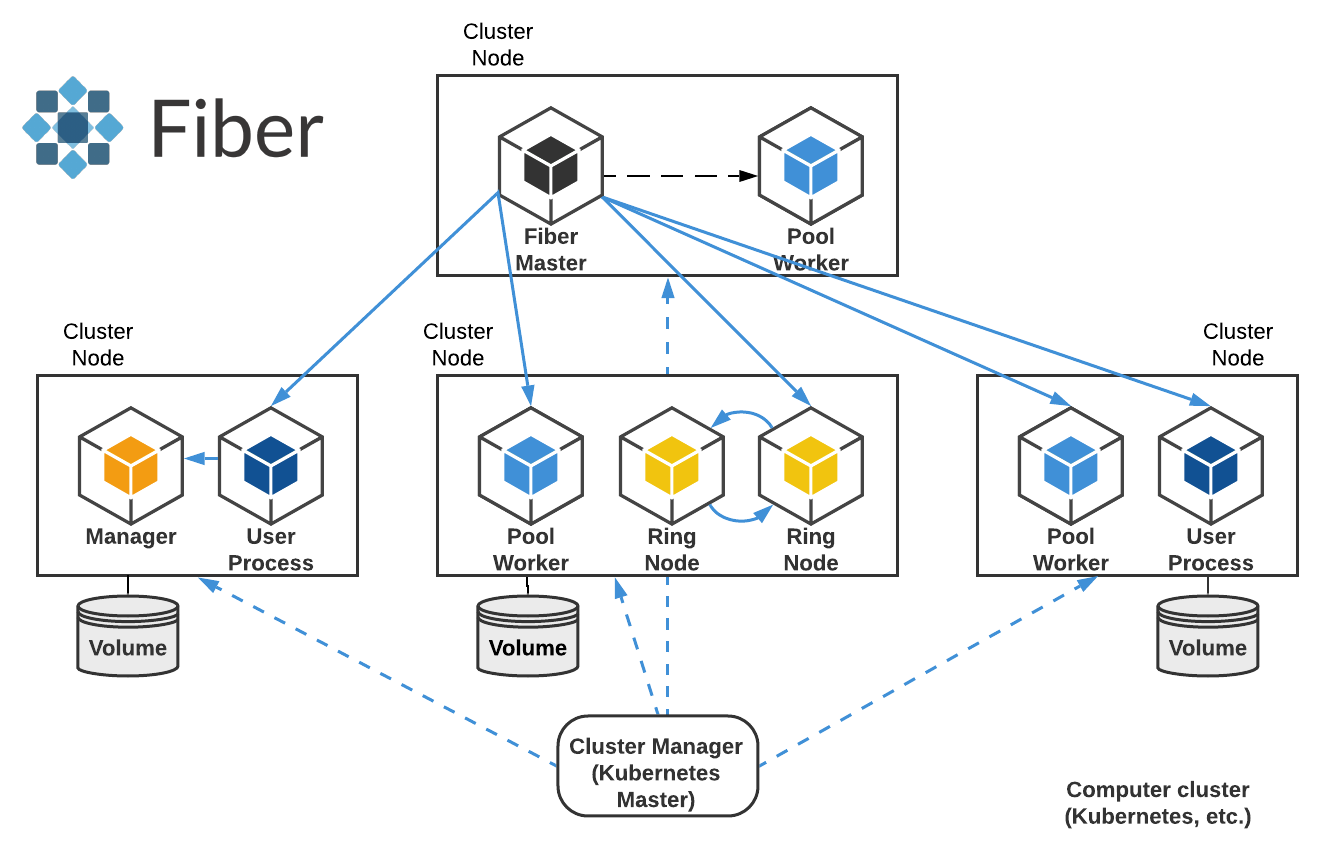
图 1:Fiber 概述。 该图显示了 Fiber 在计算机集群中的工作方式。它启动许多不同的作业支持进程,并在其中运行不同的 Fiber 组件和用户进程。Fiber Master 是管理所有其他进程的主进程。某些进程(如 Ring Node)维持每个成员之间的通信。
Fiber 可以:
(1)帮助从事大规模分布式计算的用户减少从构思到在计算集群上实际运行分布式作业的时间;
(2)保护用户不受配置和资源分配任务的细节的影响;
(3)加快调试周期;
(4)简化从本地开发到集群开发的过渡。
架构
Fiber 连接了经典的多处理 API,后端可以在不同的集群管理系统上灵活地选择。为了实现这种集成,Fiber 被分为三个不同的层: API 层 、 后端层 和 集群层 。 API 层 为 Fiber 提供基本的构建块,如进程、队列、池和管理器等。它们具有多处理相同的语义,但是可以扩展到分布式环境中工作。 后端层 处理在不同集群管理器上创建或终止作业之类的任务。当添加新的后端时,所有其他 Fiber 组件(如队列、池等)都无需更改。最后, 集群层 由不同的集群管理器组成。虽然它们不是 Fiber 本身的一部分,但它们可以帮助 Fiber 管理资源并跟踪不同的作业,从而减少了 Fiber 需要跟踪的项目数量。图 2 对这一总体架构进行了总结。
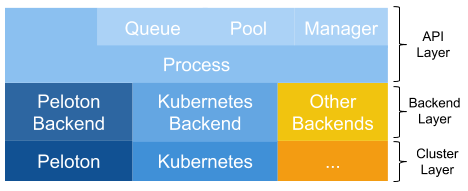
图 2:Fiber 架构。
作业支持进程
Fiber 引入了一个新概念,称为作业支持进程(也称为 Fiber 进程)。它类似于 Python 的 multiprocessing 库的进程,但更灵活:虽然多处理进程仅在本地计算机上运行,但 Fiber 进程可以在不同的计算机上远程运行,也可以在同一台计算上本地运行。启动新的 Fiber 进程时,Fiber 会在当前计算机集群上使用适当的 Fiber 后端创建一个新的作业。
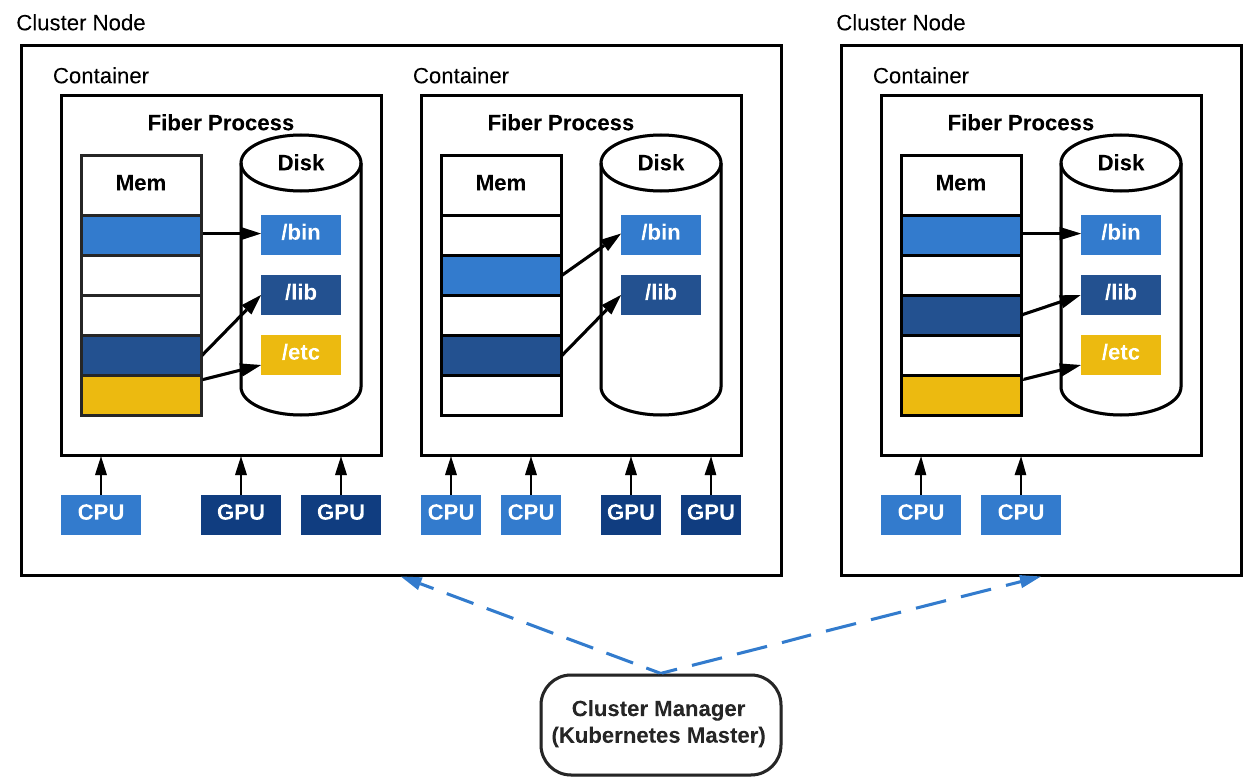
图 3:作业支持进程。 每个作业支持进程都是在计算机集群上运行的容器化作业。每个作业支持进程也将有自己的 CPU、GPU 和其他类型的资源分配。在容器内运行的代码是独立发布(self-contained)的。
Fiber 使用容器封装当前进程的运行环境,包括所有需要的文件、输入数据、其他依赖的程序包等,以确保一切都是独立发布的。所有进程都使用与父进程相同的容器映像启动,以保证一致的运行环境。因为每个进程都是一个集群作业,所以它的生命周期与集群中的任何作业相同。为了方便用户,Fiber 被设计为可直接与计算机集群管理器进行交互。因此,与 Spark 或 IPyParallel 不同,Fiber 并不需要在多台机器上进行设置,也不需要由任何其他机制引导。它只需要作为一个普通的 Python pip 包安装在一台机器上即可。
组件
Fiber 在 Fiber 进程(包括管道、队列、池和管理器等)之上实现了大多数多处理 API。
Fiber 中的队列和管道的行为与多处理中的行为相同。不同之处在于,队列和管道现在由运行在不同机器上的多个进程共享。两个进程可以对同一管道进行读写操作。此外,队列可以在不同机器上的多个进程之间共享,每个进程可以同时发送或接受来自同一队列的数据。Fiber 队列采用高性能异步消息队列系统 Nanomsg 实现。
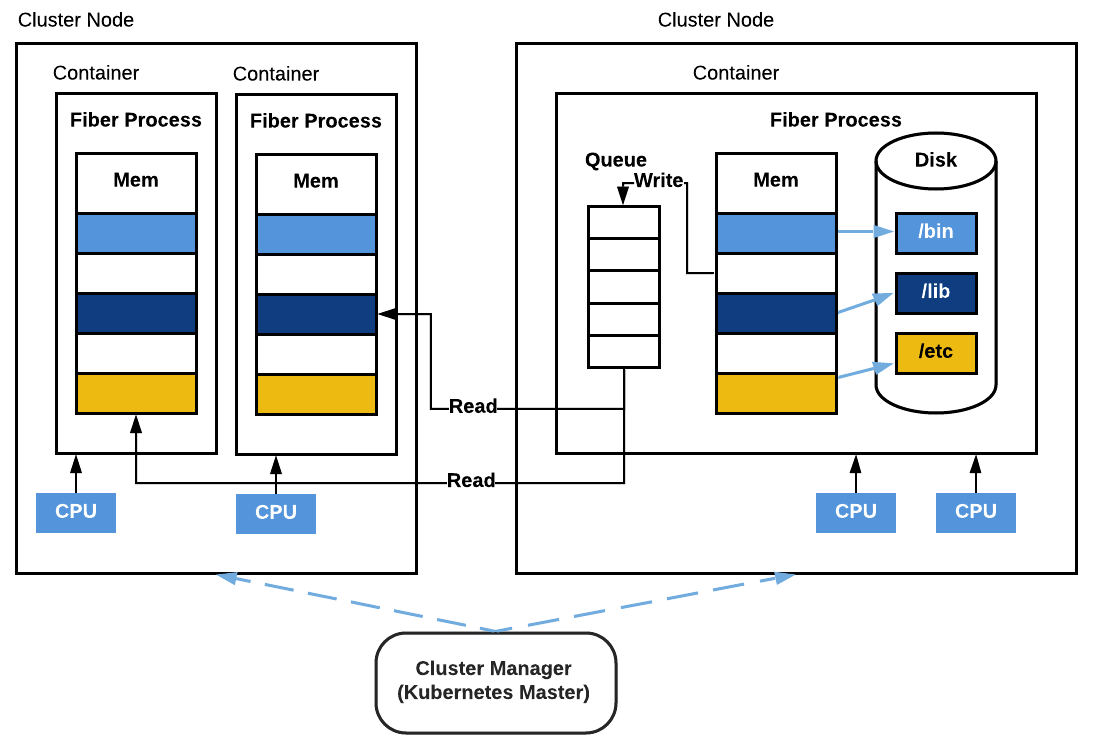
图 4:Fiber 队列。 该图显示了在三个不同 Fiber 进程之间共享的 Fiber 队列。一个 Fiber 进程与队列位于同一台计算机上,另外两个进程位于另一台机器上。其中一个进程向队列写入数据,另外两个进程从队列中读取数据。
Fiber 也支持池。它们允许用户管理工作进程池。Fiber 使用作业支持进程来对池进行扩展,因此它可以管理每个池中的数千个(远程)工作进程。用户还可以同时创建多个池。
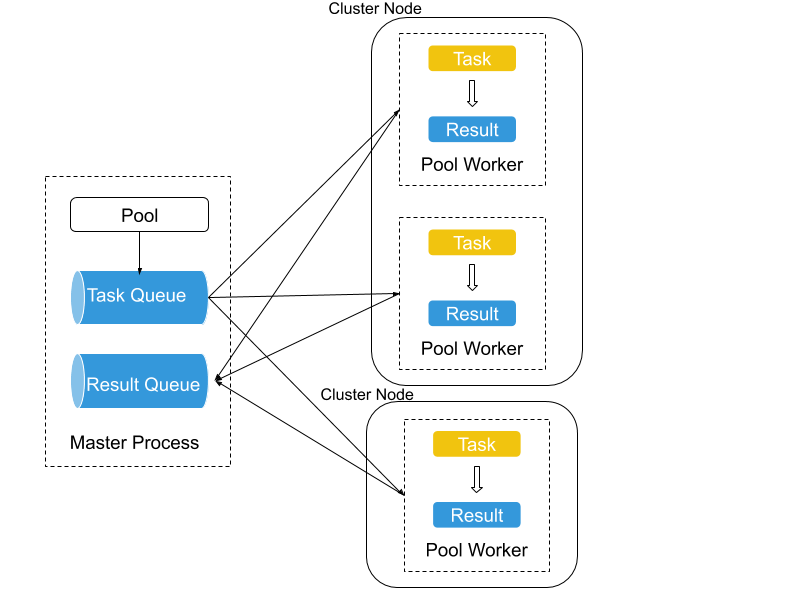
图 5:Fiber 池。 该图显示了一个包含三个工作进程的池。其中两个位于一台机器上,另一个位于另一台机器上。它们共同处理在主进程中提交给任务队列的任务,并将结果发送到结果队列。
管理器和代理对象使 Fiber 能够支持共享存储,这对分布式系统至关重要。通常,这个功能是通过外部存储器来处理的,比如 Cassandra、Redis 等等,这些存储器都是通过计算机集群来实现的。取而代之的是,Fiber 为应用程序提供了内置的内存存储。该接口与多处理的 Manager(管理器)类型相同。
Ring 是多处理 API 的扩展,可以在分布式计算设置中提供帮助。Fiber 中的 Ring 代表一组进程,它们以相对平等的方式共同工作。与不同,并没有主进程和辅助进程的概念。Ring 内的所有成员都承担着相同的责任。Fiber 的 Ring 对一种拓扑进行建模,这种拓扑在进行分布式 SGD时在机器学习中非常常见。例如torch.distributed、等。一般来说,在计算机集群上启动这类工作负载是非常具有挑战性的;Fiber 提供了 Ring 功能来帮助设置这种拓扑。
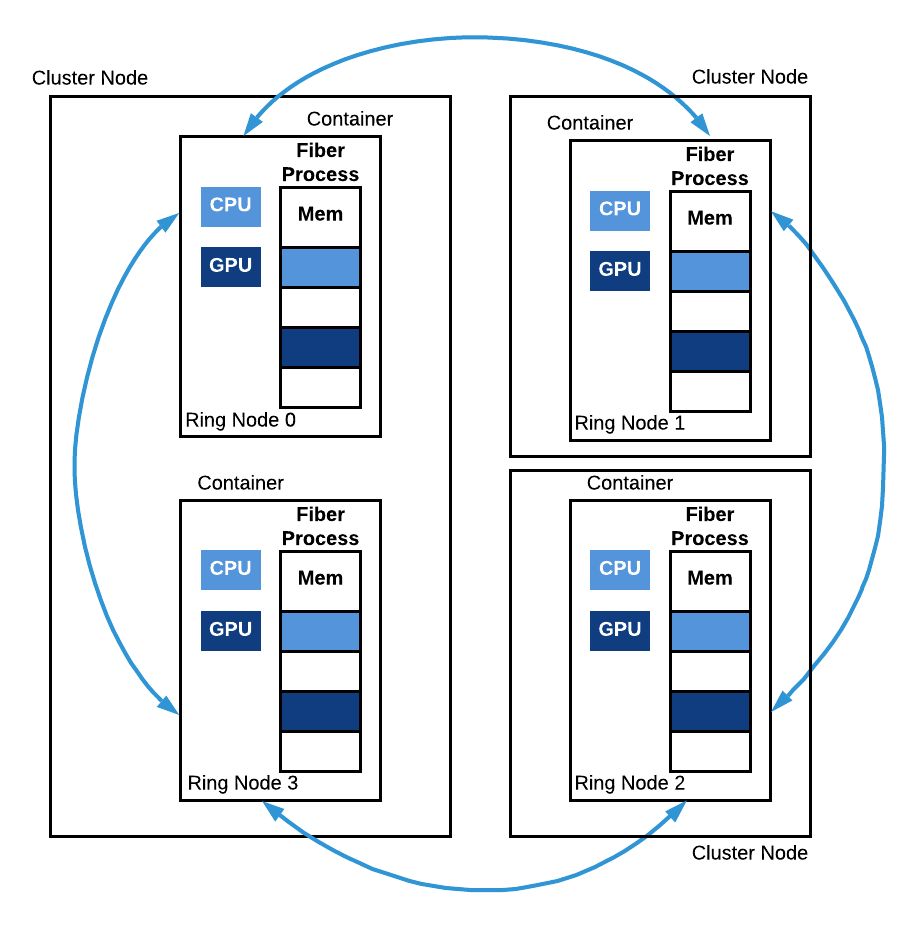
图 6:Fiber Ring。 该图展示了一个具有 4 个节点的 Fiber Ring。Ring 节点 0 和 Ring 节点 3 运行在同一台机器上,但却在两个不同的容器中。Ring 节点 1 和 Ring 节点 2 都在单独的计算机上运行。所有这些进程共同运行同一函数的副本,并在运行期间相互通信。
应用
为新应用提供支持
我们在本文阐述了如何应用 Fiber 进行大规模分布式计算的示例。该示例是一个强化学习(Reinforcement Learning,RL)算法的演示。分布式强化学习的通信模式通常涉及在机器之间发送不同类型的数据:动作、神经网络参数、梯度、每一步/每一集的观察、奖励等等。
Fiber 实现管道和池来传输这些数据。在底层,池是普通的 Unix 套接字,为使用 Fiber 的应用程序提供接近线速的通信。现代计算机网络的带宽通常高达每秒数百千兆位。通过网络传输少量的数据通常速度较快。
此外,如果有许多不同的进程向一个进程发送数据,则进程间通信延迟并不会增加太多,因为数据传输是可以并行进行的。这一事实使得 Fiber 的池适合提供许多强化学习算法的基础,因为模拟器可以在每个池工作进程中运行,且结果可以并行地传回。
# fiber.BaseManager is a manager that runs remotelyclass RemoteEnvManager(fiber.managers.AsyncManager):class Env(gym.env):RemoteEnvManager.register('Env', Env)def build_model():# create a new policy modelreturn modeldef update_model(model, observations):# update model with observed>return new_modeldef train():model = build_model()manager = RemoteEnvManager()num_envs = 10envs = [manager.Env() for i in range(num_envs)]handles = [envs[i].reset() for i in num_envs]obs = [handle.get() for handle in handles]for i in range(1000):actions = model(obs)handles = [env.step() for action in actions]obs = [handle.get() for handle in handles]model = update_model(model, obs)代码示例 1: Fiber 实现的简化强化学习代码。
启用现有多处理应用程序
由于在 Python 世界中广泛使用了多处理,因此,Fiber 为这类应用程序提供了广泛的机会,因为现在它们只需更改几行代码就可以在 Kubernetes 这样的计算机集群上以分布式设置中运行!
这里有一个例子:OpenAI Baselines是一个非常流行的强化学习库,它有许多参考算法,如、等。但它的缺点是只能在一台机器上工作。如果你想大规模训练 PPO,就必须创建自己的基于 MPI 的设置,并手动设置集群以将所有内容连接起来。
相比之下,有了 Fiber,事情就容易多了。它可以无缝地扩展像 PPO 这样的强化学习算法,以利用数百个分布式环境的工作负载。Fiber 提供了与多处理相同的 API,这是 OpenAI Baseline 用来获取本地多核 CPU 处理能力的方法。因此,要将 OpenAI Baselines 与 Fiber 一起使用,所需的更改只有一行:

然后,你就可以在 Kubernetes 上运行 OpenAI Baselines 了!我们已经提供了一份完整版指南,讲述了如何在 Kubernetes 上进行更改和运行 Baselines。
错误处理
Fiber 实现了基于池的错误处理。创建新池时,还将创建关联的任务队列、结果队列和暂挂(Pending)表。然后将新创建的任务添加到任务队列中,该任务队列在主进程和辅助进程之间共享。每个工作进程从任务队列中获取一个任务,然后在该任务中运行任务函数。每次从任务队列中删除任务时,都会在暂挂表中添加一个条目。一旦工作进程完成该任务,它就会将其结果放入结果队列中。然后从暂挂表中删除与该任务关联的条目。
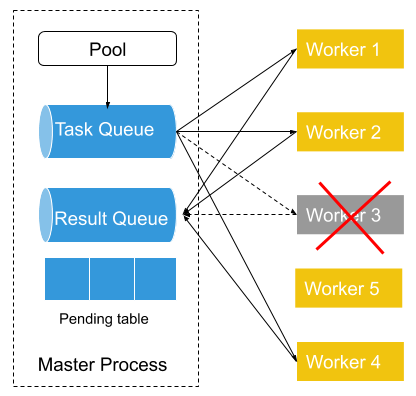
图 7:Fiber 错误处理。 左侧是一个普通的 Fiber 池,有 4 个工作进程。在右侧,工作进程 3 失败,因此启动了一个新的工作进程(工作进程 5),准备将其添加到池中。
如果池工作进程在处理过程中失败,则作为所有工作进程的进程管理器的父进程将检测到这一失败。然后,如果先前失败的进程有一个挂起的任务,则父池将暂挂表中的挂起任务放回任务队列中。接下来,它启动一个新的工作进程来替换之前失败的进程,并将新创建的辅助进程绑定到任务队列和结果队列。
性能
Fiber 最重要的应用之一是扩展像强化学习这样等算法和像 ES 这样的基于人口的方法的计算。强化学习和基于人口的方法通常应用于此类设置中,这类设置需要与模拟器频繁交互以评估策略和收集经验,如、和等。从模拟器获得结果所引入的延迟,严重影响了整体训练性能。在这些测试中,我们评估了 Fiber 的性能,并与其他框架进行了比较。我们还在框架开销测试中添加了,以提供一些初步的结果,详细的结果预计有望在以后添加。
通常有两种方法可以减少这种延迟。我们可以减少需要传输的数据量,或者使不同进程之间的通信通道变得更快。为了实现快速通信,Fiber 使用 Nanomsg 实现管道和池,为使用 Fiber 的应用程序提供快速通信的能力。此外,人们还可以使用这样的库来选择更高的性能。
框架开销
本节中的测试将探讨框架给工作负载增加了多少开销。我们比较了 Fiber、Python 多处理库、Spark 和 IPyParallel。测试的过程是创建一批总共需要固定时间才能完成的工作负载。每个任务的持续时间从 1 秒到 1 毫秒不等。我们在本地为每个框架运行 5 个工作进程,并调整批大小,以确保每个框架的总完成时间大约为 1 秒(即在 1 毫秒的持续时间内,运行 5000 个任务)。我们的假设是,Fiber 应该具有类似于多功能的性能,因它们都不响应复杂的调度机制。但是,Spark 和 IpyParallel 应该会比 Fiber 慢,因为它们依赖于中间的调度器。
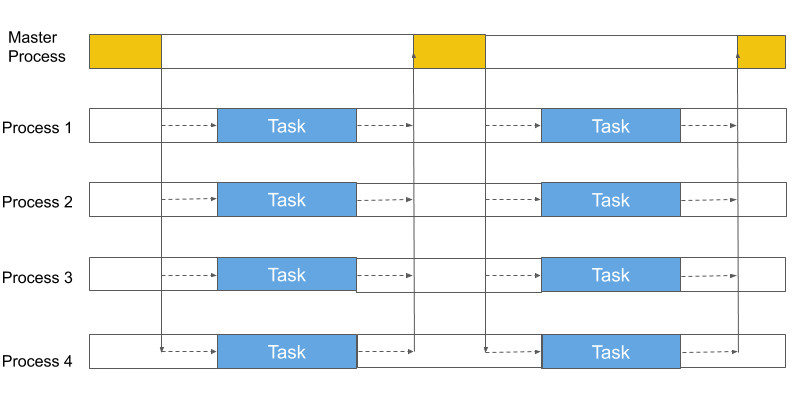
图 8:测试框架开销。
当任务持续时间为 100 毫秒或更长时,Fiber 与其他框架几乎没有什么区别,当任务持续时间下降到 10 毫秒或 1 毫秒时,Fiber 比其他框架更接近多处理。
我们使用多处理作为参考,因为它非常轻量级,除了创建新进程和并行运行任务之外,并不会实现任何其他功能。此外,它利用了仅在本地可用的通信机制(如功能内存、Unix 域套接字等),这使得它很难被其他支持跨多台机器的分布式资源管理的框架所超越,而这些框架不能利用类似的机制。因此,对于可预期的性能而言,它可以作为一个很好的参考。
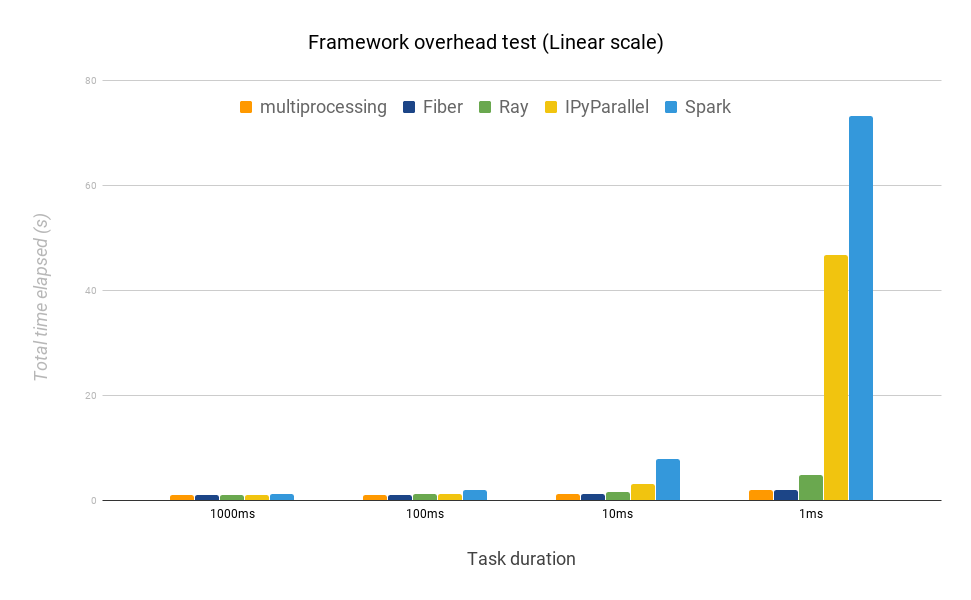
图 9:不同框架在完成一批任务的平均时间上的比较,任务持续的时间不同(线性比例)。 最佳完成时间为 1 秒。
与 Fiber 相比,IPyParallel 和 Spark 在每个任务持续时间上都落后很多。当任务持续时间为 1 毫秒时,IPyParallel 耗费的时间几乎是 Fiber 的 24 倍,Spark 耗费的时间是 Fiber 的 38 倍。这一结果突出地表明了:当任务持续时间较短时,IPyParallel 和 Spark 都会带来相当大的开销,而且对于强化学习和基于人口的方法(其中使用了模拟器,响应时间为几毫秒)来说,它们都不如 Fiber 合适。我们还发现,在运行持续时间为 1 毫秒的任务时,Ray 耗费的时间大约是 Fiber 的 2.5 倍。
分布式任务测试
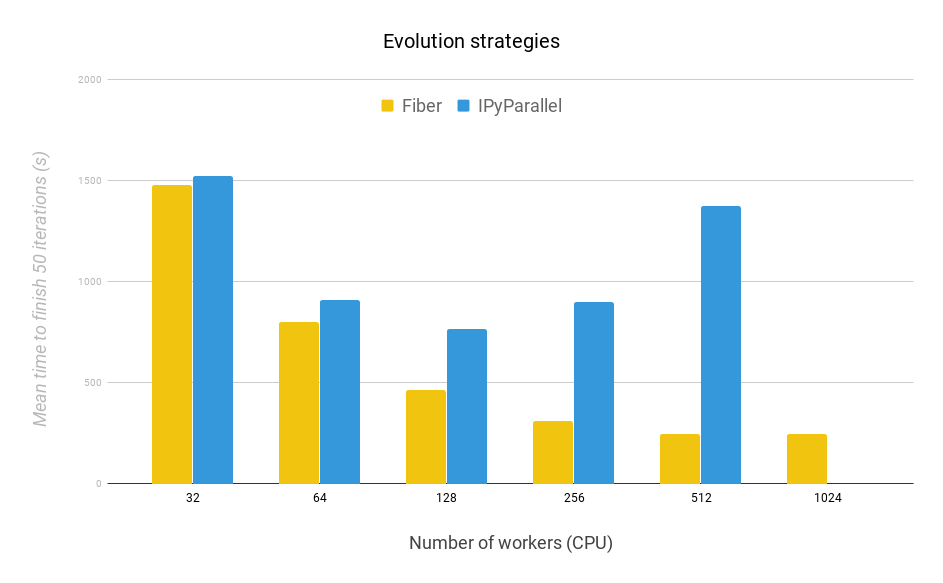
为了探讨 Fiber 的可伸缩性和效率,我们在本文中,仅将其与 IPyParallel 进行比较,因为 Spark 比 IPyParallel 慢(如上所示),而且多处理不能扩展到超过一台机器。我们通过运行 50 次 ES 算法(演化策略)迭代来测试两个框架的可伸缩性和效率,以评估这两个框架。
在工作负载相同的情况下,我们希望 Fiber 能够完成得更快,因为它的开销比 IPyParallel 要少得多,如先前的测试所示。对于 Fiber 和 IPyParallel,人口大小为 2.048,因此,无论工作进程数量多少,总计算量都是固定的。在这两种方法中也实现了相同的共享噪声表(noise table)技巧。每 8 个工作进程共享一个噪声表。这项工作的实验域是的 “Bipedal Walker Hardcore” 环境的修改版本。点此处查看关于此修改的描述。
图 10:ES 的 50 次迭代。在不同工作进程数量下运行 ES 时,Fiber 的可伸缩性优于 IPyParallel。每个工作进程都在单个 CPU 上运行。
我们得到的主要结论是,Fiber 的可伸缩性比 IPyParallel 要好得多,并且完成每个测试的速度都要快得多。随着工作进程从 32 个增加到 1024 个,Fiber 运行所需的时间逐渐减少。相比之下,相同的时间,IPyParallel 才从 256 个工作进程 增加 到 512 个工作进程。由于进程之间的通信错误,IPyParallel 并未能完成 1024 个工作进程的运行测试。这一失败摧毁了 IPyParallel 运行大规模并行计算的能力。达到 512 个工作进程后,随着工作进程数量的增加,我们发现,Fiber 的回报在递减。这是因为Amdahl 定律。在这种情况下,主进程处理数据的速度成了瓶颈。
总的来说,在所有测试的工作进程中,Fiber 的性能都超过了 IPyParallel。此外,与 IPyParallel 不同的是,Fiber 还完成了 1024 个工作进程的测试工作。这一结果突出了与 IPyParallel 相比,Fiber 具有更好的可伸缩性,同时它也非常易于使用和设置。
总结
Fiber 是一个新的 Python 分布式库,现已开源。它的设计目的是让用户在计算机集群上能够轻松地实现大规模计算。本文的实验突出地表明了,Fiber 实现了许多目标,包括有效利用大量易购计算硬件,动态缩放算法来提高资源使用效率,以及减少在计算机集群上运行复杂算法所需的工程负担。
我们希望,Fiber 能够通过使开发方法变得更容易,并在必要的规模上运行以真正看到它的闪光点,从而进一步使解决困难问题的进展成为可能。欲知更多详情,请查看我们的Fiber GitHub仓库和Fiber 论文。
作者介绍:
Jiale Zhi、Rui Wang、Jeff Clune 与Kenneth O. Stanley,皆供职于 Uber。
原文链接: