前言
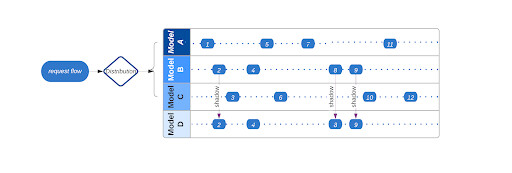
在伴鱼,我们在多个在线场景使用机器学习提升用户的使用体验。例如,在伴鱼绘本中,我们根据用户的帖子浏览记录,为用户推荐他们感兴趣的帖子。
在线预测是机器学习模型发挥作用的临门一脚,重要性不言而喻。在伴鱼,我们搭建了机器学习预测服务(以下简称预测服务),统一地处理所有的预测请求。本文主要介绍预测服务的演进过程。
预测服务 V1
目前,各个算法团队都有一套组装预测服务的方式。它们的架构十分相似,可以用下图表达:
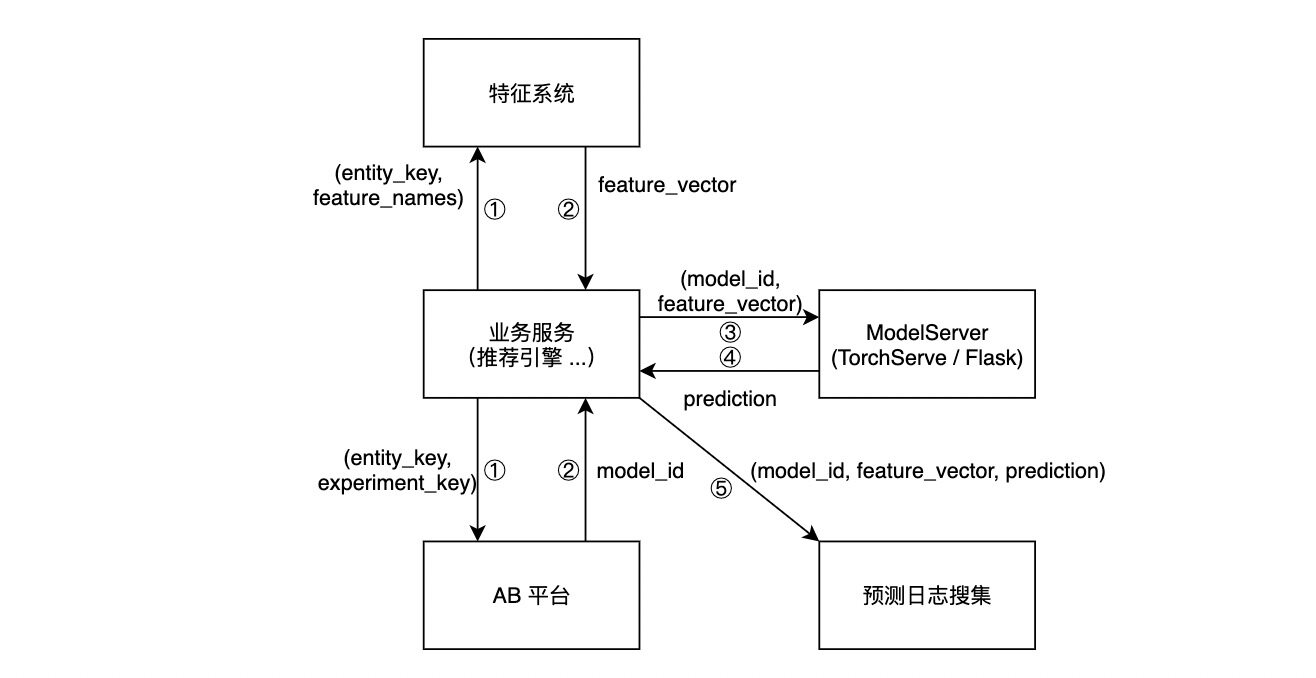
其中,ModelServer 的实现有两种主流方式。其一,使用 TorchServe 或 TensorFlow Serving 这样和训练框架高度耦合的 serving 方案。其二,使用 Flask 搭建一个简单的 HTTP 服务,将模型加载至服务的内存,在收到预测请求时调用模型的预测接口进行预测。
这种方式存在几个问题:
为了系统性地解决这几个问题,预测服务 V2 提出了几个设计目的:
预测服务 V2
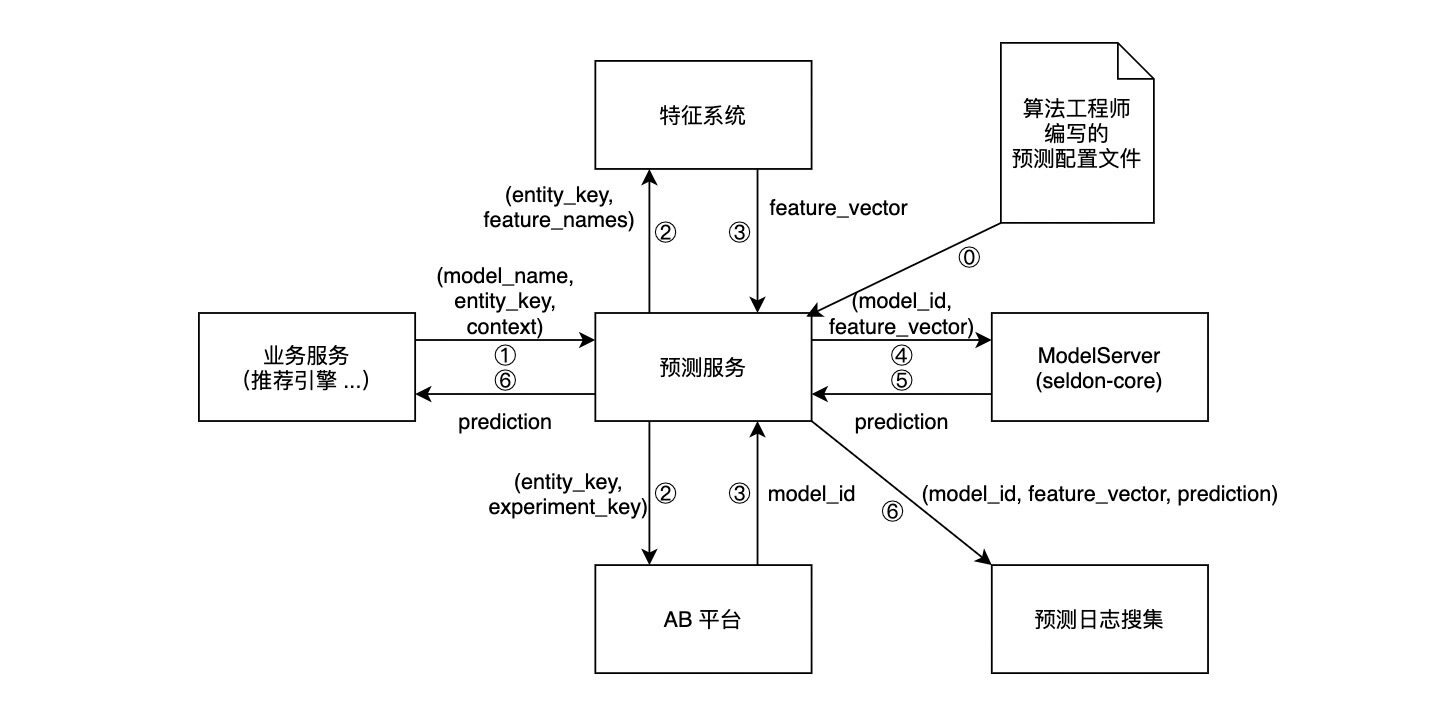
架构主要借鉴了和:预测服务接受预测请求,根据请求的内容,进行获取特征、获取 AB 实验分组等操作,然后调用 ModelServer 进行推理,返回预测结果。详情见下图。
⓪ 表示在新的模型上线之前,算法工程师上传的预测配置文件会被载入预测服务,预测服务根据配置文件的内容实例化一个工作流。
① 到 ⑥ 代表预测请求的整个生命周期:
在这个架构下,算法工程师要上线一个模型,只需:
不难看出,编写预测配置文件是算法工程师工作流的核心。预测配置文件以 YAML 格式定义了一个完整的模型推理工作流所涉及的全部信息。
举一个具体的例子。假设我们有一个视频推荐系统 Toy Recsys,它结合用户的网络情况(network),和用户的短期观看历史(last_5_views),给用户推荐视频。模型的基本逻辑是:网络情况好,就结合用户口味,放一些用户最可能感兴趣的长视频;网络情况差,就结合用户口味,放一些短视频。
我们称 network 和 last_5_views 是 Toy Recsys 模型的两个特征。其中,网络情况会附带在请求中(这类特征被称为 context 特征),而短期观看历史存储在特征系统中。要让预测服务知道如何获取这两个特征,不需要工程同学进行额外的编码工作,而只需由算法工程师提交如下配置文件:
model-name: toy_recsysfeature-system:- features:- name: networksource: contextdefault-value: 4G- name: last_5_viewssource: storedefault-value: []预测服务会根据算法工程师提交的预测配置文件,实例化一个获取特征的工作流,并开始处理该模型的请求。这个工作流会:
值得注意的是,预测配置文件极易拓展。如果预测服务要接入 AB 平台,我们只需要支持在配置文件中填写 AB 实验的信息即可。例如:
model-name: toy_recsysfeature-system: ...ab-experiment:- experiment-key: TOY_RECSYS总结
在完成预测服务的初步设计后,我们开始了预测服务的实现。我们期待在预测服务上线后,与大家分享预测服务的实现细节。
参考文献
作者:陈易生
原文:原文:伴鱼机器学习预测服务:设计篇