从根本上说,就像任何其他监督式机器学习的问题一样,语言建模的目标是:在给定文档 d 的情况下,预测一些输出 y。文档 d 必须以某种方式以数字形式表示,这可以通过机器学习算法进行处理。
将文档表示为数字的最初解决方案是词袋(bag of words,BoW)模型。每个单词在向量中占据一个维度,每个值表示该单词在文档中出现的次数。但是,这种方法并没有考虑到单词的顺序,这很重要(请想想“I live to work, I work to live)。
为了解决这个问题,人们使用了 n 元语法模型(n-gram)。这些是由 n 个单词组成的序列,其中每个元素表示一个单词组合的存在。如果我们的数据集中有 10000 个单词,并且我们想存储为二元语法,则需要 10000² 个唯一的组合。对于任何相当不错的模型,我们很可能需要三元语法甚至四元语法,每个都会将词汇量提高到另一个幂。
显然,n 元语法和词袋模型甚至并不能处理稍微复杂的语言任务。它们的解决方案包括向量化过程,但这些过程过于稀疏、庞大,并且无法捕捉到语言本身的精髓。那解决方案是什么呢?是递归神经网络。
与使用高维、稀疏的向量化解决方案(试图一次性地将整个文档馈送到模型中)不同,递归神经网络是利用文本的序列特性。递归神经网络可以表示为递归函数,其中 a 是在每个时间步骤上应用的变换函数,h 是隐层状态的集合,x 表示数据的集合。
$h_t=A(h_{t-1},x_{t-1})$每个时间步骤都是利用前一个时间步骤的知识创建的,通过对前一个输出应用相同的函数创建一个新的输出。当递归神经网络“展开”时,我们可以看到在不同的时间步骤的输入是如何被馈送到模型中的,并且还知道模型之前“看到”了什么。
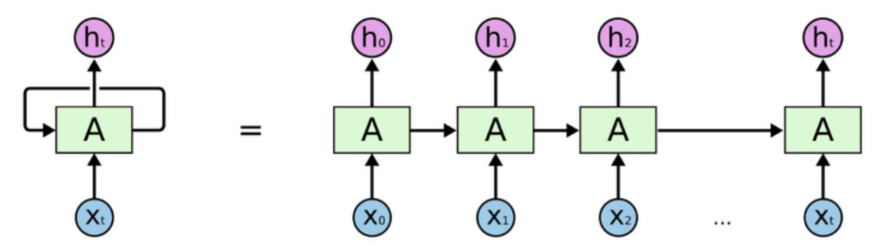
因为递归神经网络对每个输入都应用相同的函数,所以它还有一个额外的好处:能够处理可变长度的输入。使用相同函数背后的基本原理可以被认为是将“通用语言 / 序列规则”应用于每个时间步骤。
然而,递归神经网络出色的递归特性也导致了一些问题。将递归神经网络的递归定义简单地展开到第四个隐藏状态,我们可以看到,A 函数被应用了很多次。
$h_3=(A(A(A(H_0,x_0),x_1),x_2)$实际上只是乘以一个权重矩阵,然后加到一个偏差矩阵上。当然,在进行较大的简化时,经过十个时间步骤之后,初始输入 基本上是乘以 ,其中是权重矩阵。因为任何计算都会产生结果,所以将数字转换为幂会得到极端的结果:
这就引起了很多问题。权重矩阵将导致值要么向零(递减),要么向无穷大或负无穷大(爆炸)。因此,递归神经网络受到梯度递减和梯度爆炸问题的困扰。当权重更新时,这不仅会导致计算问题,还意味着它们“患有痴呆症”:它们忘记了任何超过几个时间步骤的东西,因为通过递归乘法,它们已经被模糊或放大到无法理解的程度。
因此,当使用递归神经网络生成文本时,你可能会看到无限循环:
当网络生成第二轮“walked on”时,它已经忘记了上次说过的内容。它认为,通过它天真的机制,有了前一次的输入“the street and…”,下一次的输出应该是“walked on”。这种循环会持续下去,是因为注意力框架太小。
解决方法:LSTM 网络,于 1997 年首次提出,但基本上不被重视,直到最近,计算资源使这一发现变得更加实用。
它仍然是一个递归网络,但是对输入进行了复杂的转换。每个细胞的输入通过复杂的操作进行处理,产生两个输出,可以认为是“长期记忆”(贯穿细胞的顶线)和“短期记忆”(底部输出)。
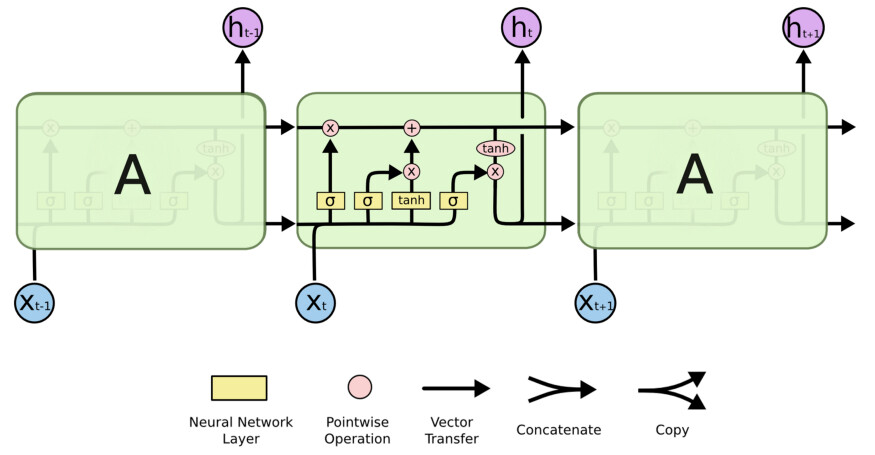
通过长期记忆通道的向量可以在没有任何干扰的情况下通过整个链。只有门(粉红点)可以阻止或添加信息,所以如果网络选择这样做,它可以保留它从任意数量的细胞之前发现有用的数据。
这种长期信息流的加入极大地扩大了网络的注意力规模。它可以访问之前的细胞状态,但也可以访问不久前的学习中获得有用的信息,使得它能够参考上下文——这是更多人类交流的关键属性。
LSTM 运作良好——有一段时间。它可以在较短的文本长度上进行相当好的字符生成,并且没有被许多早期自然语言处理发展的问题所困扰,特别是更全面的深度和对单个单词以及它们的集体含义的理解。
然而,LSTM 网络也有它的缺点。它仍然是一个递归网络,因此如果输入序列有 1000 个字符,LSTM 细胞被调用 1000 次,这是一个很长的梯度路径。虽然增加一个长期记忆通道有所帮助,但它可以容纳的容量毕竟是有限的。
另外,由于 LSTM 本质上是递归的(要查找当前状态,你需要找到以前的状态),因此并不能并行地对它们进行训练。
也许更为紧迫的是,迁移学习在 LSTM(或递归神经网络)上并不是十分有效。深度卷积神经网络之所以能够得到普及,部分原因是像 Inception 这样的预训练模型可以简单地下载和微调。从一个已经知道任务的普遍规则的模型开始训练的宝贵能力使其更易于获得和可行。
有时候,经过预训练的 LSTM 可以成功迁移,但并不是常见的做法是有原因的。这是有道理的——每篇文字都有自己独特的风格。与图像不同的是,图像几乎总是遵循某种某种带有阴影和边缘的严格的通用规则,而文本的结构则没那么明显,更为流畅。
是的,有一些基本的语法规则来支撑文本的框架,但它远没有图像那么严格。除此之外,还有不同的语法规则——不同的诗歌形式、不同的方言(如莎士比亚和古英语)、不同的用法(Twitter 上的推文语言、即兴演讲的书面版本)。比方说,从维基百科(Wikipedia)上预训练的 LSTM 开始,可能比从头开始学习数据集要容易得多。
除了经过预训练的嵌入之外,当遇到更高要求的现代问题时,如跨多种语言的机器翻译或与人工书写的文本完全无法区分的文本生成,而 LSTM 是有限的。越来越多的新架构被用来处理更具挑战性的任务:Transformer。
Transformer 最初是在论文《注意力就是你所需要的一切》(Attention Is All You Need)提出的,以解决语言翻译问题,它的架构非常复杂。不过,最重要的部分是注意力的概念。
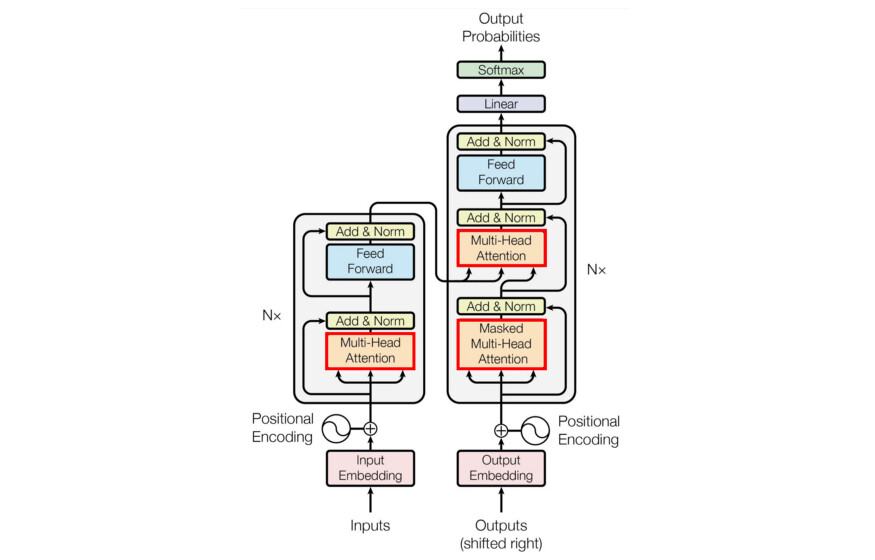
在本文的前面,我们讨论了注意力跨度,即递归神经网络过去有多少隐藏状态可以回顾。Transformer 拥有无限的注意力大小,这是它们相对于 LSTM 优势的核心。做到这一点的关键是什么?
Transformer 不使用递归。
Transformer 通过全比较来实现无限的注意力大小。它不是按顺序处理每个单词,而是一次性处理整个序列,建立一个“注意力矩阵”,其中每个输出是输入的加权和。因此,例如,我们可以将发育单词“accord”表达为 ‘The’(0)+‘agreement’(1)+…。网络会学习注意力矩阵的权重。
红色边框内的区域很有趣:尽管“European Economic Area”被翻译成“européenne économique zone”,但在法语中,其词序实际上是“zone économique européenne”。注意力矩阵能够直接捕捉到这些关系。
注意力允许输出值之间的直接访问,LSTM 必须通过记忆通道间接和顺序访问这些信息。
Transformer 的计算成本很高——构建矩阵的 O(n²) 运行时间是无法避免的。然而,由于各种原因,它并不像一些人想象的那样言中。首先,由于 Transformer 的非递归性质,可以使用并行性来训练模型,而这正是 LSTM 或递归神经网络无法做到的。
此外,GPU 和其他硬件已经发展到这样的程度:它们的扩展能力令人难以置信的强大——10 × 10 矩阵的速度基本上与 1000 × 1000 矩阵的速度一样快。
现代 Transformer 的计算时间很长,很大程度上并不是因为注意力机制。相反,在注意力机制的帮助下,递归语言建模的问题得到了解决。
Transformer 模型在使用迁移学习时也显示出了很好的效果,这对它们的普及起到了巨大的作用。
那么,LSTM 的未来是什么?
在它真正“消亡”之前,还有很长的路要走,但它肯定是在走下坡路。首先,LSTM 的变体在序列建模方面已显示出成功,例如在生成音乐或预测股票价格,在这种情况下,考虑到额外的计算负担,回溯和保持无限长注意力持续时间的能力并不那么重要。
摘要
作者介绍:
Andre Ye,Critiq 联合创始人。机器学习、计算机科学与数学爱好者。
原文链接: