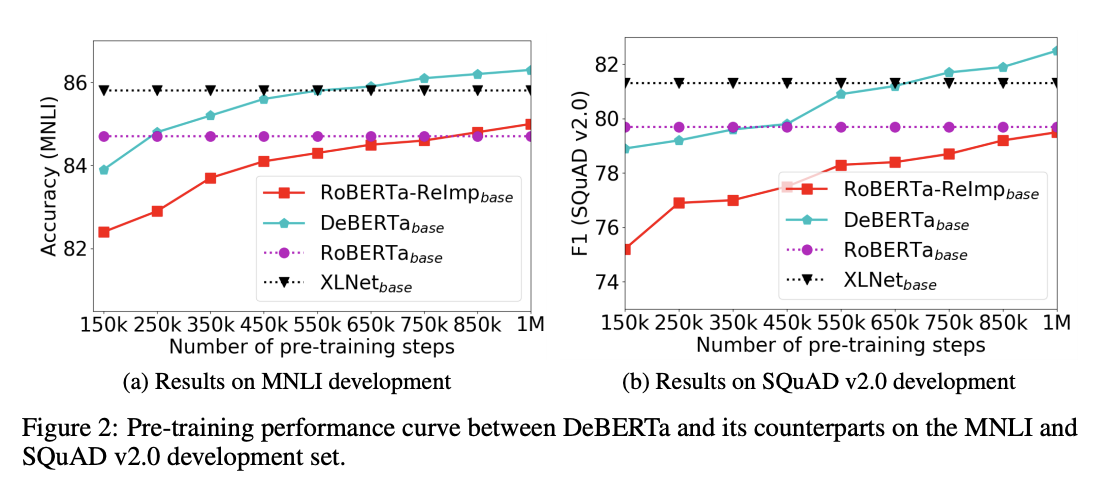
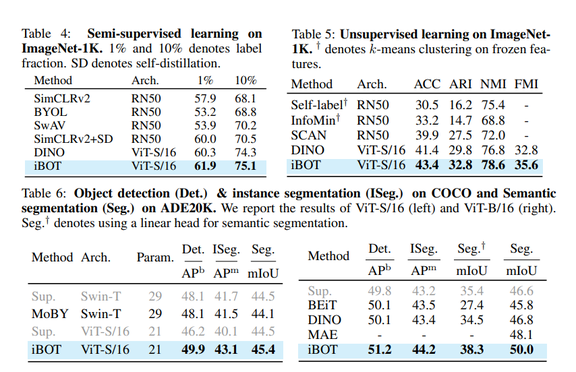
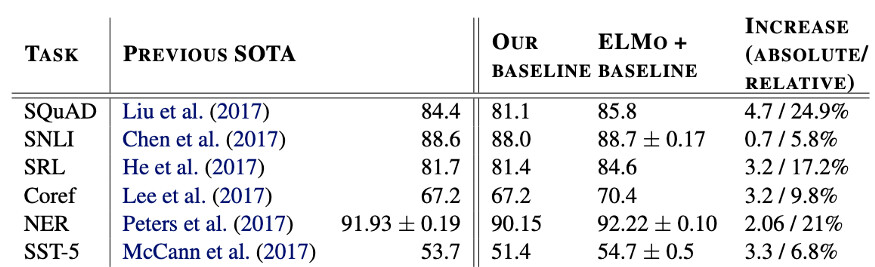
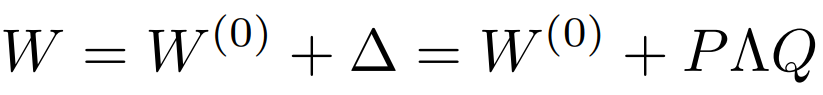近日,Facebook AI 宣布已经在 CPU 服务器是上创建和部署了一款实时神经网络文本转语音系统,音频质量能达到人类水平。以前的系统通常依赖于 GPU 或其他专用硬件来实时生成高质量的语音,但通过将模型进行广泛地优化,该系统可以将合成速度比基准速度提高 160 倍,且能够在 500 毫秒内在 CPU 上生成一秒钟的音频。据介绍,该系统已经部署在了 Facebook 的视频通话设备 Portal 上,并可以在 Facebook 多个应用程序上使用,包括支持视障人士阅读和 VR 体验。
当前的文本语音转换系统(TTS)在利用神经网络模拟人类语音方面已经做过很多尝试,为了生成类人音频,一秒钟的音频需要 TTS 系统输出 2.4 万个样本,有时甚至更多。高质量模型的体量和复杂性要求系统进行大量计算,而这些计算通常需要在 GPU 或其他专用硬件上运行。
接下来,Facebook AI 对该系统如何解决核心效率挑战来实现大规模部署的问题进行了详细介绍。
基于神经网络的 TTS 管道
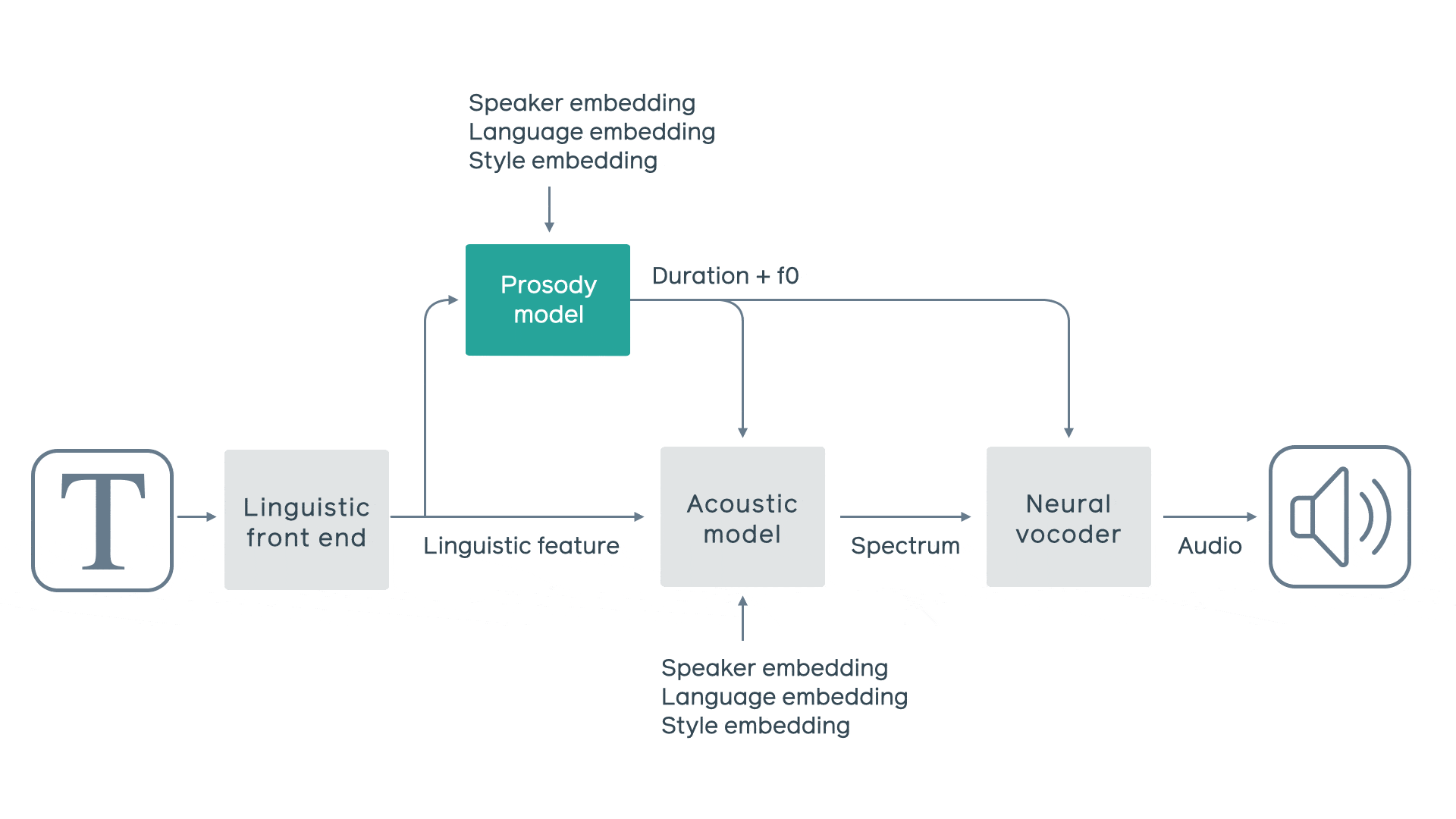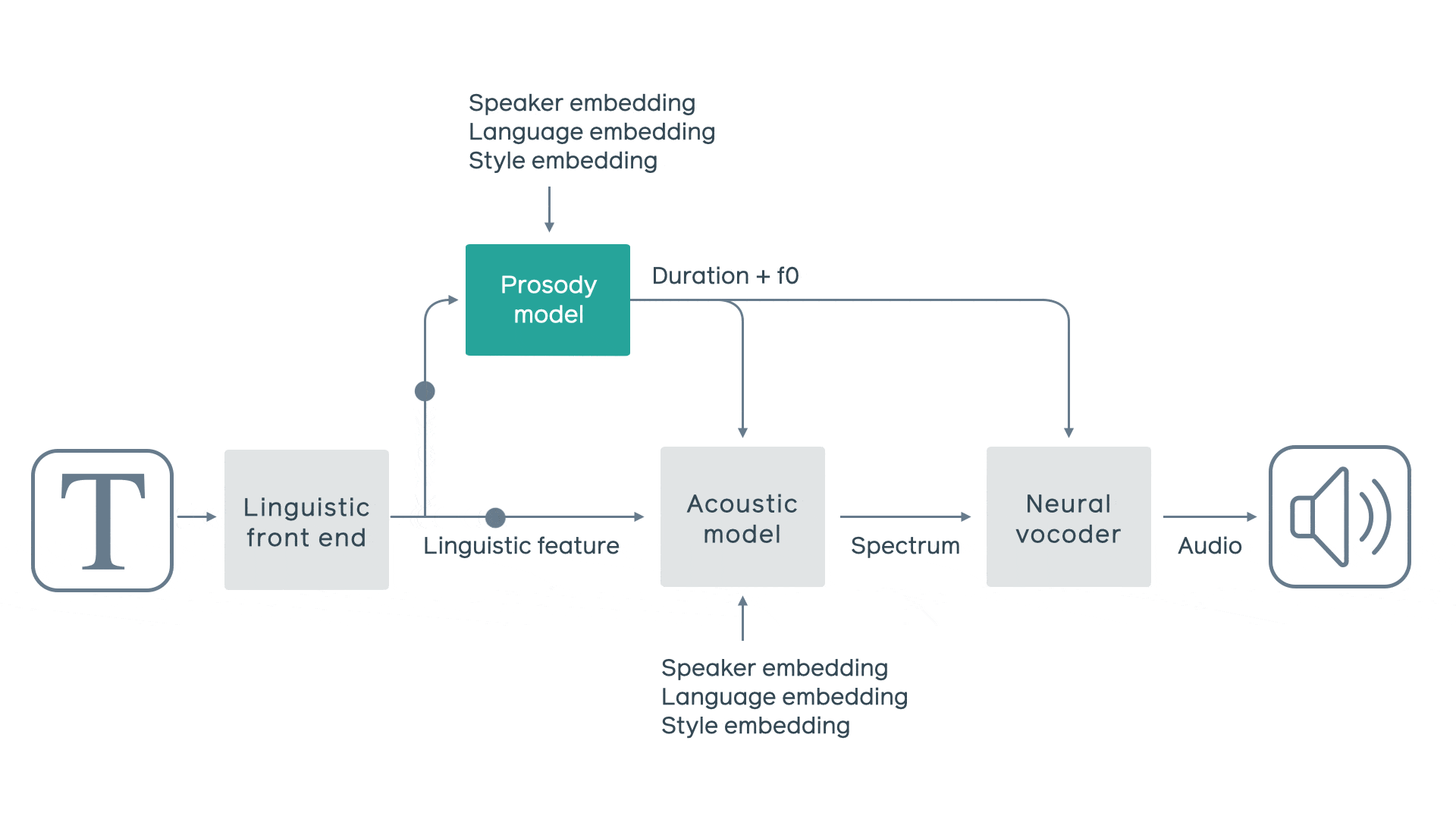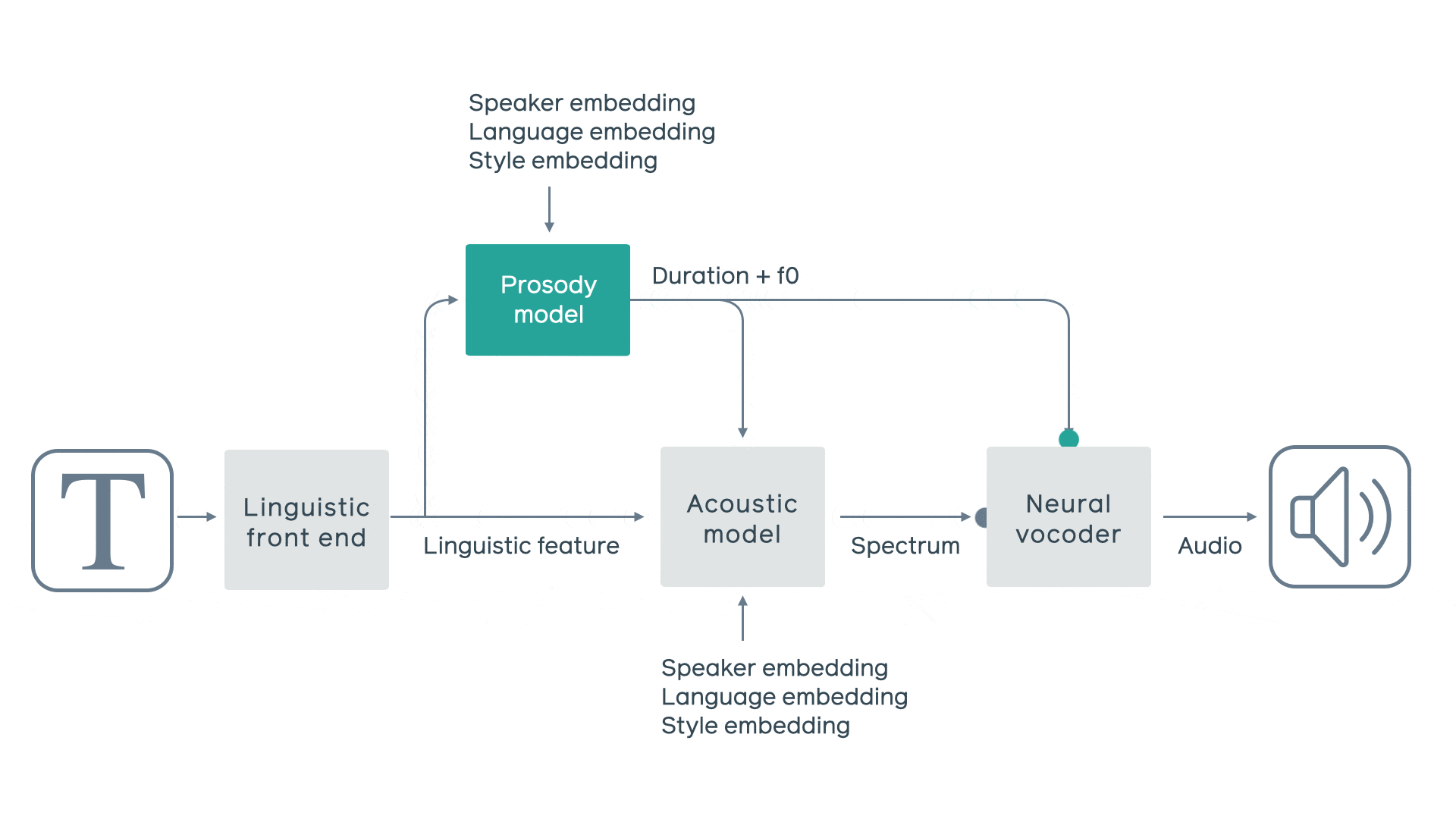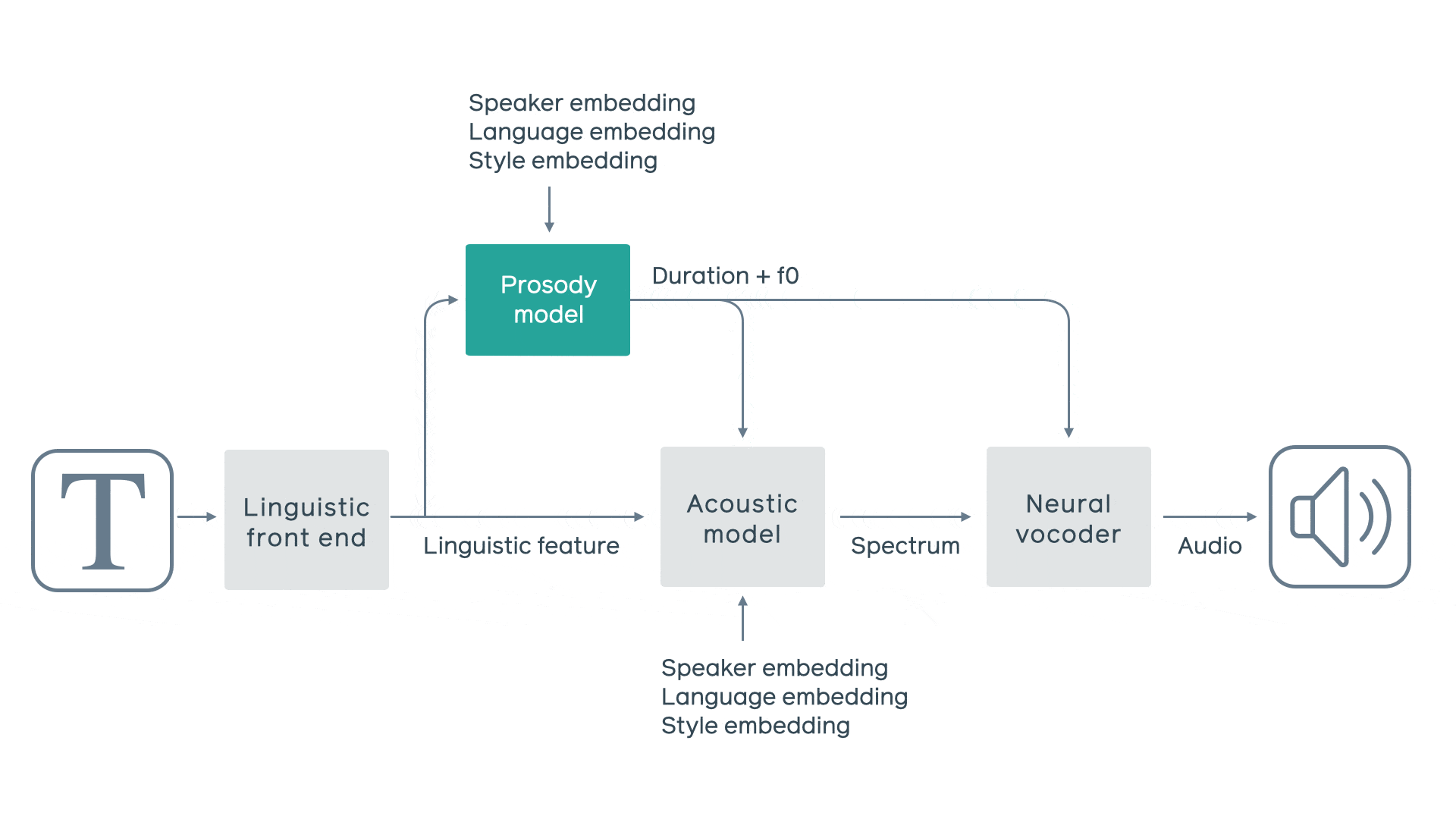
FacebookAI 设计了一个管道,该管道将四个组件(每个组件专注于语音的不同方面)有效地组合成一个强大而灵活的系统,四个组件包括:
音律模型
在管道中构建单独的音律模型尤为重要,因为它可以在语音合成时更容易地控制语音风格。音律模型根据一系列语言学特征以及语音风格、说话者和语言嵌入,来预测句子的通话级时长(即速度)和帧级基本频率(即旋律)。它的模型架构由具有基于内容的 global attention 的循环神经网络组成,其上下文向量包含整个句子的语义信息。这样可以使模型生成更真实、自然的音律。
研究人员使用了风格嵌入,可以用现有数据集中的少量额外数据来创建新的语音风格,包括助手型、柔声型、快速型、投射型和正式型。由于不需要为每个风格创建一个单独的模型,所以只需要为每个语音风格提供 30 到 60 分钟的训练数据。
声学模型
为了实现更高的计算效率和高质量的语音,研究者采用了条件神经语音编码器架构,因为它是基于频谱输入进行预测而不是直接从文本或语言特征(例如,像 WaveNet 这样的自回归模型或相当复杂的并行合成网络 Parallel WaveNet)生成音频。他们利用声学模型将语言学和音律信息转化为帧速率频谱特征,并将其作为神经声码器的输入。这种方法使神经声学编码器能够集中处理几个相邻帧中的频谱信息,让研究者能够训练出更轻量级、体量更小的神经声码器。
权衡之下,Facebook 选择了依靠声学模型来生成光谱特征。虽然通常使用的是 80D 高保真 MFCC 或 Log-Mel 特征,但实际上,要预测出逼真的高保真声学特征本身就是一个具有挑战性的任务。为了解决这个频谱特征预测问题,研究人员采用的方法是使用 13D MFCC 特征与基频和 5D 周期性特征相连接,这样能更容易地生成声学模型。
神经声码器
条件神经声码器由两部分组成:
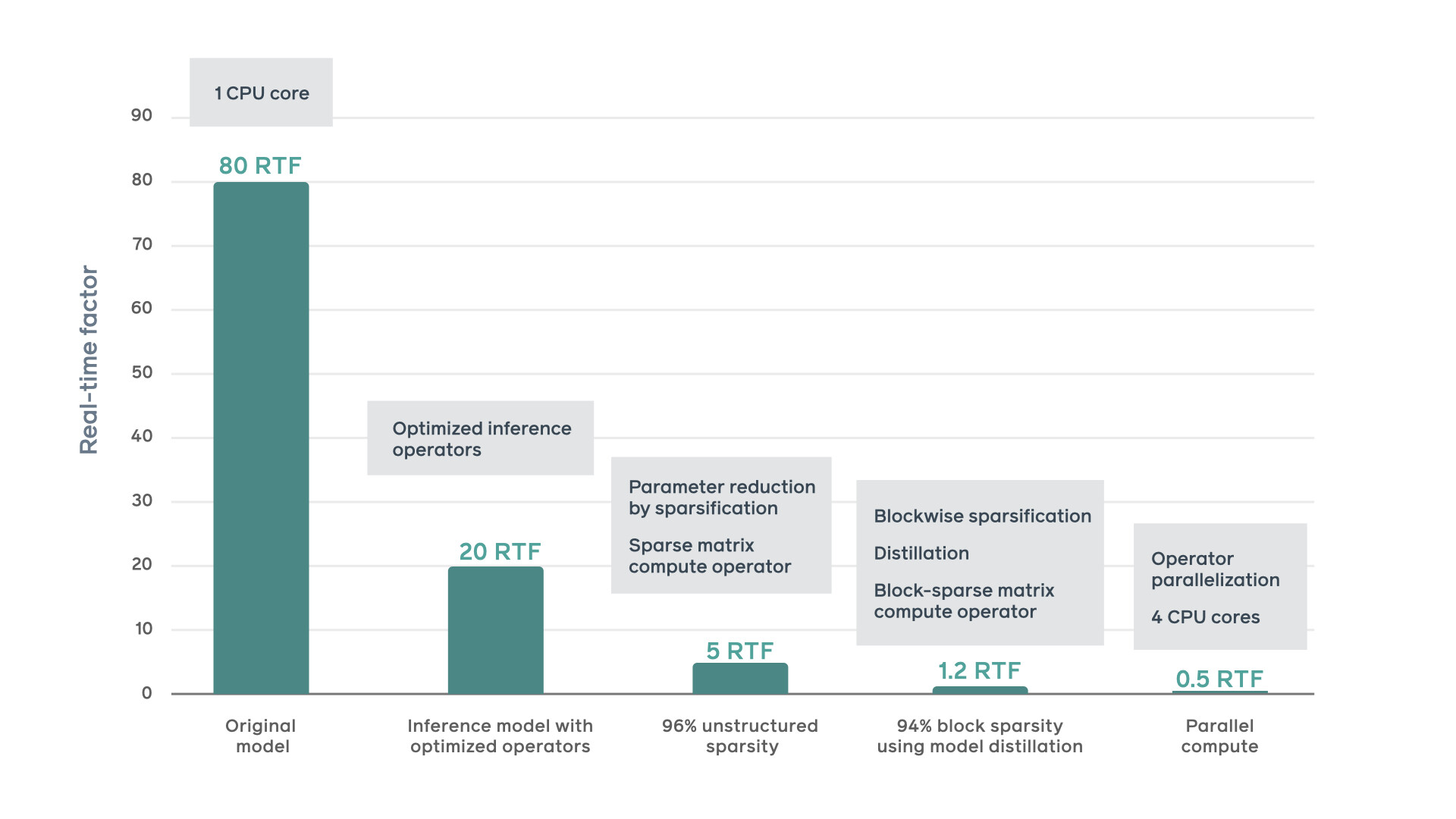
神经声码器的自回归特性要求按顺序生成样本,这对于实时合成来说是个重大挑战。当研究人员开始进行实验时,baseline 实现只能在单 CPU 内核上以约 80 个实时因子(RTF)的合成速度运行,在 80 秒内生成一秒的音频。这样的合成速度对于实时系统来说,实在是太慢了。对于像 Portal 这样的系统的实时功能,必须将其降到 1 RTF 以下。
研究人员在一个 TTS 系统中结合并实现了以下优化技术,最终使合成速度提高了 160 倍,实现了 0.5 RTF。
张量级优化和自定义运算器
在 PyTorch JIT 的帮助下,研究人员从面向训练的 PyTorch 设置迁移到推理优化的环境中。使用编译的算子和各种张量级优化获得了额外的速度提升。
非结构化模型稀疏化
研究人员通过训练,使非结构化模型稀疏化,以此来降低推理计算复杂度。在不降低音频质量的情况下,可以实现 96%的非结构化模型稀疏度——其中 4%的模型参数为非零参数。通过在推理网上使用优化的稀疏矩阵运算符,我们能够将速度提高 5 倍。
分块稀疏化
研究人员通过应用分块稀疏化技术,将非零参数限制在 16x1 的块中,并存储在连续的内存块中,从而进一步简化了参数数据布局。这使得参数数据在内存中布局紧凑,间接寻址量最小化,从而使内存带宽利用率和缓存利用率得到了显著提高。
研究人员在分块稀疏结构上操作了自定义运算符,实现了矩阵的高效存储和计算,使计算量与矩阵中的非零块数成正比。为了在不降低音频质量的前提下,对高块状稀疏度进行优化,通过模型提炼训练稀疏模型,将密集模型作为 teacher 模型。
最后,通过将重运算器分布在同一个 socket 上的多个核心上实现了进一步的加速。通过在训练过程中迫使非零参数分块均匀地分布在参数矩阵上,并在推理过程中将矩阵乘法在多个 CPU 内核之间进行分割和分配来实现。
为了改进收集训练数据的方式,Facebook 研究人员采取了这种依赖于手工生成的语料库的方法,并对该方法进行了调整以便能从大规模、非结构化数据集中选择行。通过语言模型,根据可读性标准对大数据集进行筛选。这种新颖的调整方法使我们能够最大限度地提高语料库中的语音和语序的多样性,同时仍然确保语言是自然的、可读的。这就减少了音频中的注释和录音室的编辑工作,同时提高了 TTS 的质量。通过从更多样化的语料库中自动识别脚本台词,使我们能够快速扩展到新的语言,而无需依赖手工生成的数据集。
新的数据采集方法和神经系统 TTS 系统的结合,帮助我们将语音开发周期(从脚本生成、数据采集到最终的语音交付)从一年多的时间缩短到六个月以内。最近,Facebook 成功地应用新的方法制作出了一款英伦口音的语音,这也是未来即将做出的多种尝试的第一步。
Facebook AI 表示,“很高兴能够提供更高质量的音频,提供比以前扩展性更强的数据采集方式,这样就可以更有效地为社区中的每个人带来更好的语音交互体验。
原文链接: