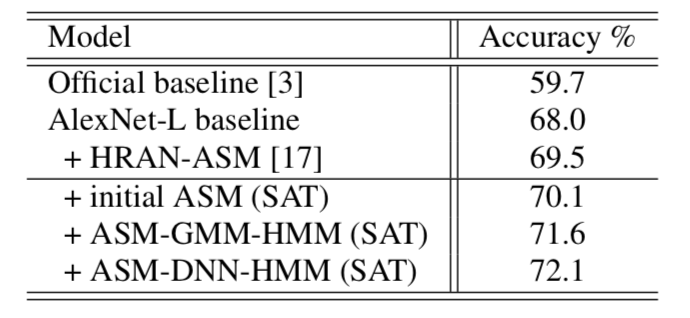
以 BERT-base 为例,它由 12 层的 transformer 组成,每一层的宽度 (即 hidden size)为 768,总的参数量为 109M。为了减少其网络规模,可以通过减少模型的层数(高度),或者通过减少模型的宽度来实现。DistillBERT 和 PKD-BERT 只减少了模型的层数,而 MobileBERT 只减少了模型的宽度,而 TinyBERT 既减少了模型的层数也减少了模型的宽度。早期的工作只关注层数的减少,这样做的好处是可以直接使用教师模型中的权重来初始化学生模型,但是减少层数对模型的压缩毕竟是有限的。而减少模型的宽度则意味着无法直接使用教师模型的参数对学生模型进行初始化。此外,MobileBERT 指出减少了宽度,attention head 数目也应该减少。