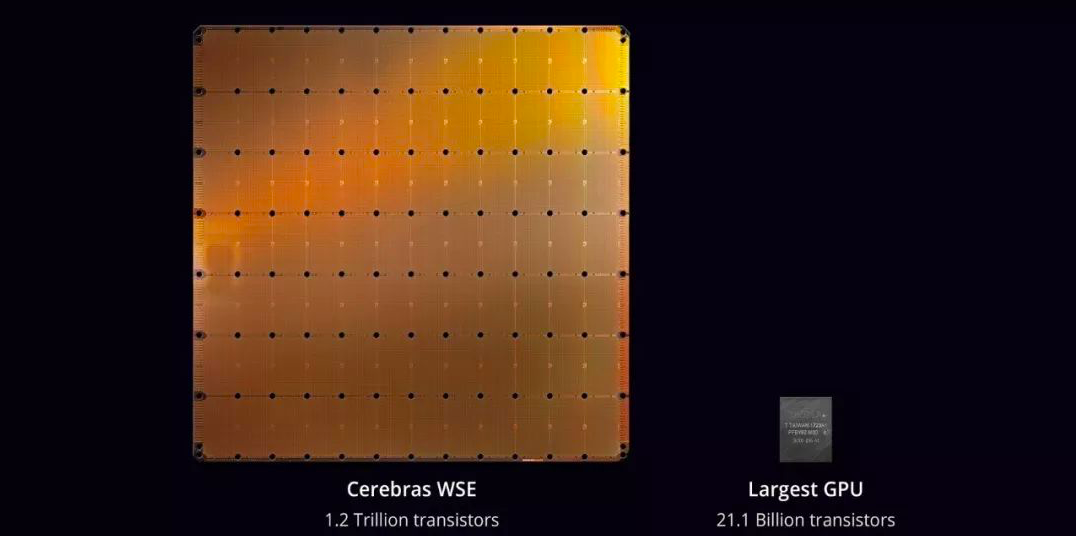

Cerebras Systems 的首席执行官 Andrew Feldman 表示,在人工智能研究中,更大的芯片能够更快的处理信息,并缩短神经网络的训练时间。
Cerebras WSE 的每一面都是 8.5 英寸,是世界上有史以来最大的计算机芯片。通过更大的面积获取更快的速度,Cerebras WSE 凭借自己独一无二的 422.25 平方厘米,集成了 1.2 万亿个晶体管,与目前最大的 Nvidia GPU 相比,可谓是“巨无霸”的存在。
人工智能的飞速发展要求 AI 芯片具备更快的速度,无论是“训练”一个神经网络,还是处理这些并行操作所产生的巨大数据,都需要 AI 芯片具有更加优秀的性能。据了解,每当计算工作量发生变化时,基础机器就会进行一次改变,或许芯片“巨大化”便提供了这样一个“改变”的契机。
为了做出“大而好”的芯片,Cerebras 需要解决很多的问题。
首先,Cerebras 打破了一些规则。
芯片设计人员使用 Cadence Design 和 Synopsis 等公司的软件程序来制定“平面图” ,包括晶体管的排列、芯片上的各个逻辑单元等;但由于传统芯片通常只会集成数十亿个晶体管,Cerebras 却需要将 1.2 万亿个晶体管集成在同一个晶圆上,制定这样的“平面图”对于平常芯片设计工具来说具有很大的难度;所以,Cerebras 建立了自己的设计软件工具。
其次,Cerebras 解决了晶圆制造过程中所产生的杂质问题。
Nvidia、英特尔和其他普通小型芯片的制造商可以通过选取晶圆中的“优质芯片”来解决杂质带来的问题,毕竟一个晶圆上不止一个芯片。但是 Cerebras 的芯片却占据了整个晶圆,这便意味着芯片良品率会大打折扣。而 Cerebras 则通过建立冗余电路,绕过杂质所产生的缺陷,以便保证 40 万个工作核心的正常工作。
Cerebras WSE 并不会单独销售,而是将被打包到 Cerebras 设计的计算机设备中。这个设备需要一个复杂的水冷系统,以抵消 15 千瓦功率运行芯片所产生的极端热量。Feldman 表示,搭载 Cerebras WSE 的服务器将是搭载多个 Nvidia 芯片服务器速度的 150 倍,他还预测,在云计算设备中人工智能训练任务的成本可能会因为 Cerebras WSE 的存在而降低一个数量级。
然而还有待观察的是,这 40 万个可对神经网络进行优化的内核是否真的可以统一协同工作,以达到预想中的性能。因为在看到基准测试之前,仅凭借晶体管的集成程度,很难评估一项 AI 芯片的设计是否具有优势。Feldman 称,有些人已经收到搭载 Cerebras WSE 的原型机,并且使用结果显示其具有竞争力。
在“大数据”时代,要处理的数据量大大增加,但在性能改进方面,Nvidia 和英特尔的进展大幅放缓。如果 Cerebras WSE 真如 Feldman 所说,可以将神经学习网络的训练时间缩短至几分钟,那么会不会有更多的企业转向“巨大化”芯片呢?