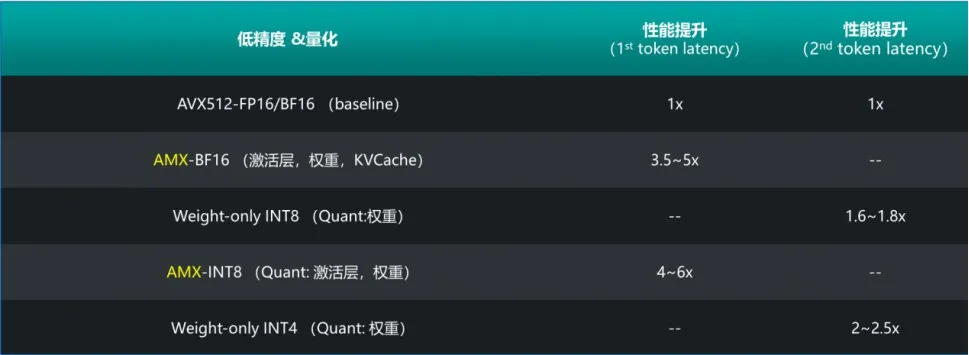
7 月 3 日,摩尔线程重磅宣布其 AI 旗舰产品夸娥(KUAE)智算集群解决方案实现重大升级,从当前的千卡级别大幅扩展至万卡规模。 摩尔线程夸娥(KUAE)万卡智算集群,以全功能 GPU 为底座,旨在打造能够承载万卡规模、具备万 P 级浮点运算能力的国产通用加速计算平台,专为万亿参数级别的复杂大模型训练而设计。

摩尔线程创始人兼 CEO 张建中表示:“当前,我们正处在生成式人工智能的黄金时代,技术交织催动智能涌现,GPU 成为加速新技术浪潮来临的创新引擎。摩尔线程矢志投身于这一历史性的创造进程,致力于向全球提供加速计算的基础设施和一站式解决方案,为融合人工智能和数字孪生的数智世界打造先进的加速计算平台。夸娥万卡智算集群作为摩尔线程全栈 AI 战略的一块重要拼图,可为各行各业数智化转型提供澎湃算力,不仅有力彰显了摩尔线程在技术创新和工程实践上的实力,更将成为推动 AI 产业发展的新起点。”
AI 主战场,万卡通用算力是标配
大模型自问世以来,关于其未来的走向和发展趋势亟待时间验证,但从当前来看,几种演进趋势值得关注,使得其对算力的核心需求也愈发明晰。
首先,Scaling Law 将持续奏效。 Scaling Law 自 2020 年提出以来,已揭示了大模型发展背后的“暴力美学”,即通过算力、算法、数据的深度融合与经验积累,实现模型性能的飞跃,这也成为业界公认的将持续影响未来大模型的发展趋势。Scaling Law 将持续奏效,需要单点规模够大并且通用的算力才能快速跟上技术演进。
其次,Transformer 架构不能实现大一统,和其他架构会持续演进并共存,形成多元化的技术生态。 生成式 AI 的进化并非仅依赖于规模的简单膨胀,技术架构的革新同样至关重要。Transformer 架构虽然是当前主流,但新兴架构如 Mamba、RWKV 和 RetNet 等不断刷新计算效率,加快创新速度。随着技术迭代与演进,Transformer 架构并不能实现大一统,从稠密到稀疏模型,再到多模态模型的融合,技术的进步都展现了对更高性能计算资源的渴望。
与此同时,AI、3D 和 HPC 跨技术与跨领域融合不断加速 ,推动着空间智能、物理 AI 和 AI 4Science、世界模型等领域的边界拓展,使得大模型的训练和应用环境更加复杂多元,市场对于能够支持 AI+3D、AI+物理仿真、AI+科学计算等多元计算融合发展的通用加速计算平台的需求日益迫切。
多元趋势下,AI 模型训练的主战场,万卡已是标配。 随着计算量不断攀升,大模型训练亟需超级工厂,即一个“大且通用”的加速计算平台,以缩短训练时间,实现模型能力的快速迭代。当前,国际科技巨头都在通过积极部署千卡乃至超万卡规模的计算集群,以确保大模型产品的竞争力。随着模型参数量从千亿迈向万亿,模型能力更加泛化,大模型对底层算力的诉求进一步升级,万卡甚至超万卡集群成为这一轮大模型竞赛的入场券。
然而,构建万卡集群并非一万张 GPU 卡的简单堆叠,而是一项高度复杂的超级系统工程。 它涉及到超大规模的组网互联、高效率的集群计算、长期稳定性和高可用性等诸多技术难题。这是难而正确的事情,摩尔线程希望能够建设一个规模超万卡、场景够通用、生态兼容好的加速计算平台,并优先解决大模型训练的难题。

夸娥:国产万卡万 P 万亿大模型训练平台
夸娥(KUAE)是摩尔线程智算中心全栈解决方案,是以全功能 GPU 为底座,软硬一体化、完整的系统级算力解决方案,包括以夸娥计算集群为核心的基础设施、夸娥集群管理平台(KUAE Platform)以及夸娥大模型服务平台(KUAE ModelStudio),旨在以一体化交付的方式解决大规模 GPU 算力的建设和运营管理问题。
基于对 AI 算力需求的深刻洞察和前瞻性布局, 摩尔线程夸娥智算集群可实现从千卡至万卡集群的无缝扩展,旨在满足大模型时代对于算力“规模够大+计算通用+生态兼容”的核心需求。
夸娥万卡智算解决方案具备多个核心特性: