利用人工智能帮助程序员编写代码的软件 ,被称为“人工智能结对编程”。它由 OpenAI 的一个名为 Codex 的系统提供支持,该公司在 2019 年与微软达成合作,并获得了 10 亿美元的投资。
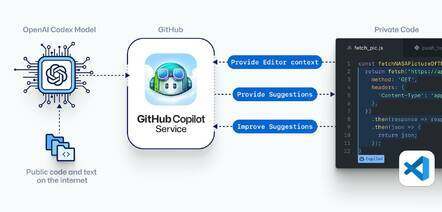 工作原理:使用公共代码作为人工智能辅助开发的模型
工作原理:使用公共代码作为人工智能辅助开发的模型
据 Copilot网站称,Codex 模型由“互联网上的公共代码和文本”训练,“既能理解编程,也能理解人类语言”。作为 Visual Studio Code 的扩展,Copilot “将你的评论和代码发送到 GitHub Copilot 服务,然后它会使用 OpenAI Codex 来合成并建议个别行和整个函数”。
会出什么问题?
一名开发者做了一个实验,他写了一些代码,然后通过 Sendgrid 服务发送电子邮件,并输入“apiKey :=”来提示 Copilot。Copilot 在截图和错误报告的基础上回应了至少四个建议密钥。他以“人工智能正在发出秘密”(
这些密钥是否有效?GitHub 的首席执行官 Nat Friedman 对这份错误报告作出了回应,他说:“这些秘密几乎完全是虚构的,是由训练数据中合成的”。
一名 Copilot 维护者补充说:“从训练数据中复制秘密的可能性非常小。而且,训练数据都是公开的代码(根本没有私人代码),因此即使秘密被复制,就算在极其不可能的情况下,也已经泄露了。”
GitHub 方面称,“GitHub Copilot 是一种代码合成器,而非搜索引擎”,“它所建议的绝大多数代码都是唯一生成的,这在以前从未见过。”但是,根据 GitHub 方面的研究,“大约 0.1% 的时间,建议可能会包含一些从训练集中逐字逐句的片段。”
这 0.1% 的比例(一些早期用户认为更高)非常麻烦。GitHub 提出的解决方案就像这篇文章所给出的那样:当人工智能在引用而非合成代码时给出一些属性。GitHub 机器学习工程师 Albert Ziegler 说:“这样一来,我就可以查到有关该代码的背景信息,并且把它归功于原作者”。
但问题在于,在有些情况下,Copilot 可能会让开发者做出错误的事情,比如,使用那些开源但有版权的代码。
如果是 GPL 代码,即,所包含的代码可能会影响新作品的许可。这种情况很让人困惑,因为 Copilot 的常见问题指出,“由 GitHub Copilot 生成的建议,以及你在它的帮助下编写的代码,都属于你,你得对其负责”。但是一个带有属性的代码块将是例外。
GitHub 还表示,“在公开可用的数据上训练机器学习模型,被认为是整个机器学习社区的一种合理使用”,从而消除了人工智能借用他人代码的担忧。有意思的是,常见问题解答中的这句话最初是这样写的:“用公共数据训练机器学习模型现在是机器学习领域中的通常做法”,有些人已经注意到这个变化:“通常做法”变成了“合理使用”。


这意味着,使用 GitHub Copilot 会存在一些不确定因素,这可能是因为 GitHub 对其训练 Copilot“吞噬”的所有公共代码细节进行了掩盖。
GitHub 的首席执行官在上表示,“我们期望在未来几年里,知识产权和人工智能将成为全世界有意义的政策讨论,我们都渴望参与。”
评论称 ,“据他们自己承认,GitHub Copilot 也接受过大量的 GPL 代码训练,因此我不清楚这怎么能成为一种将开源代码“洗成”商业作品的形式”。
“Copilot 给我留下了很不好的印象,因为这感觉就像是在绕过 GPL。”她告诉 The Register,“采用 GPL 的全部意义就是表明,你不希望专有软件从你的工作中受益。在(至少部分)GPL 代码上训练一个模型,然后用它来帮助编写可能是专有的软件,看起来至少有悖于 GPL 的精神。”
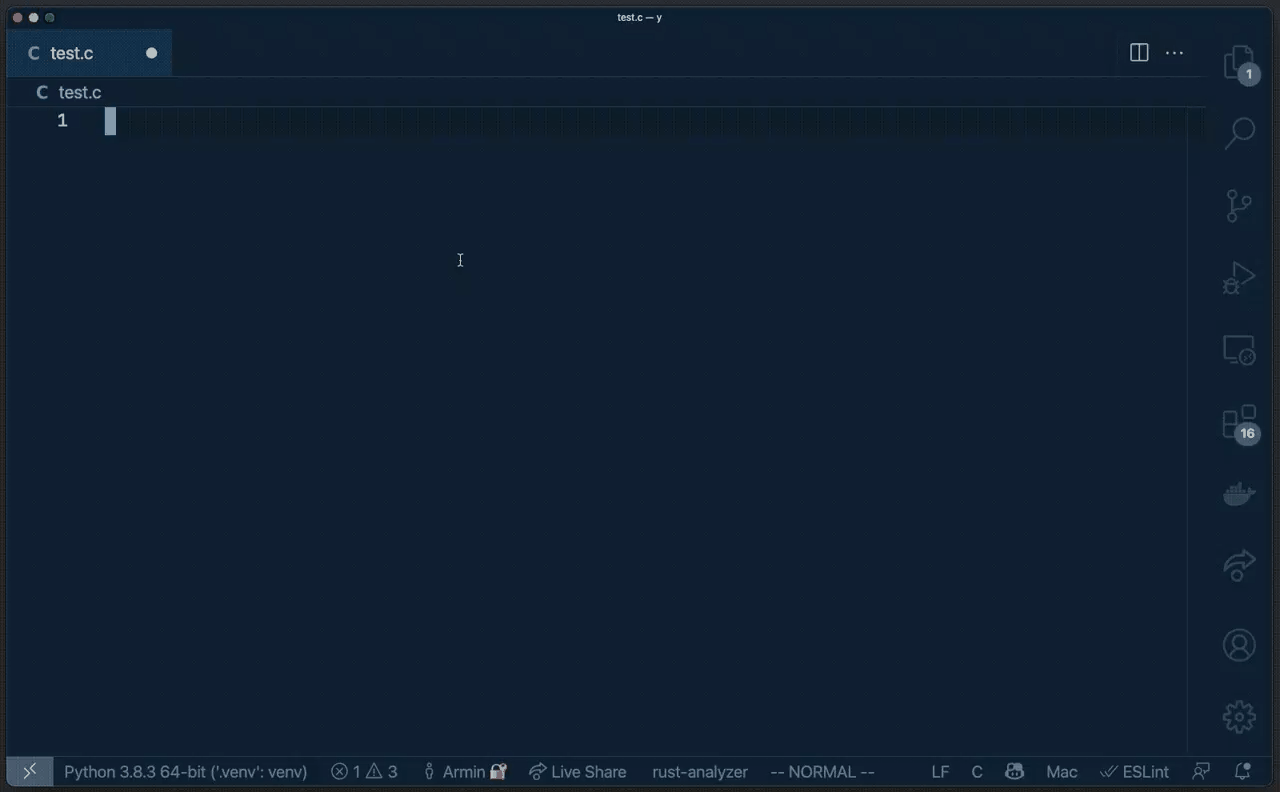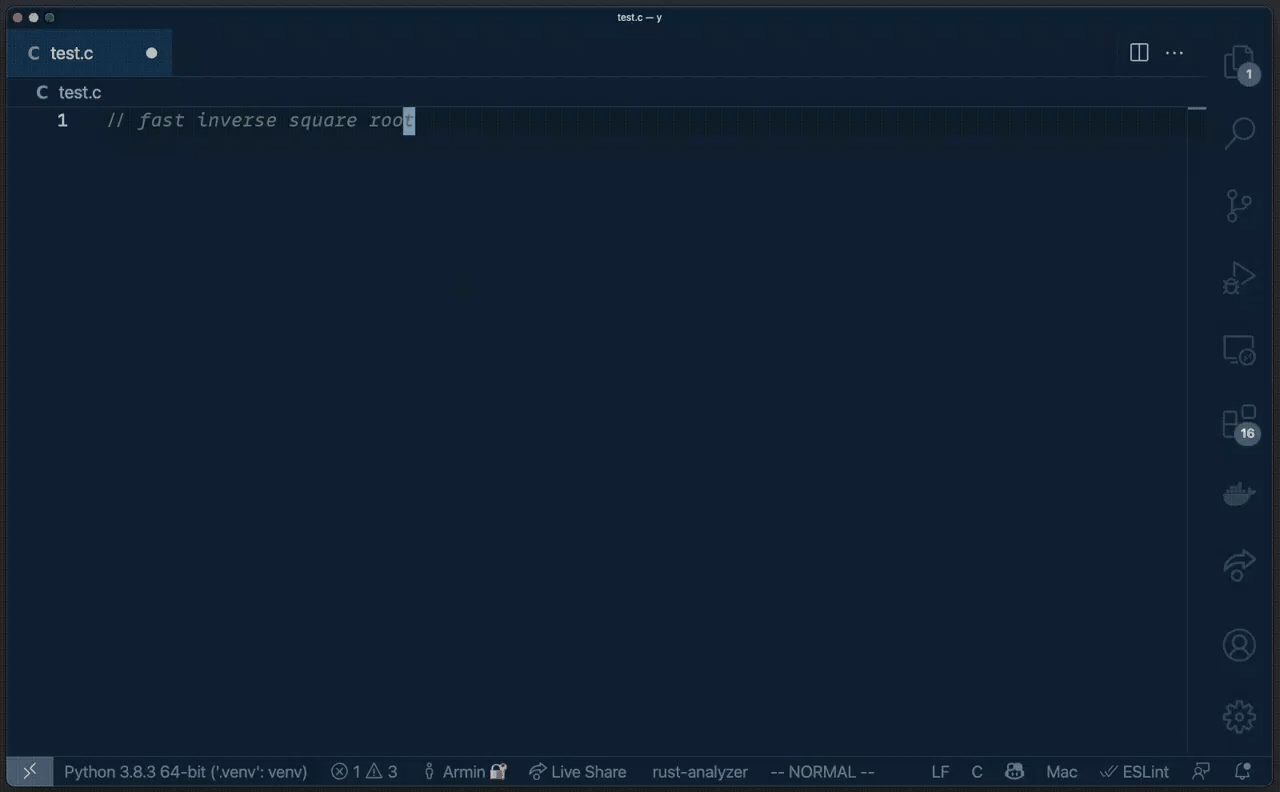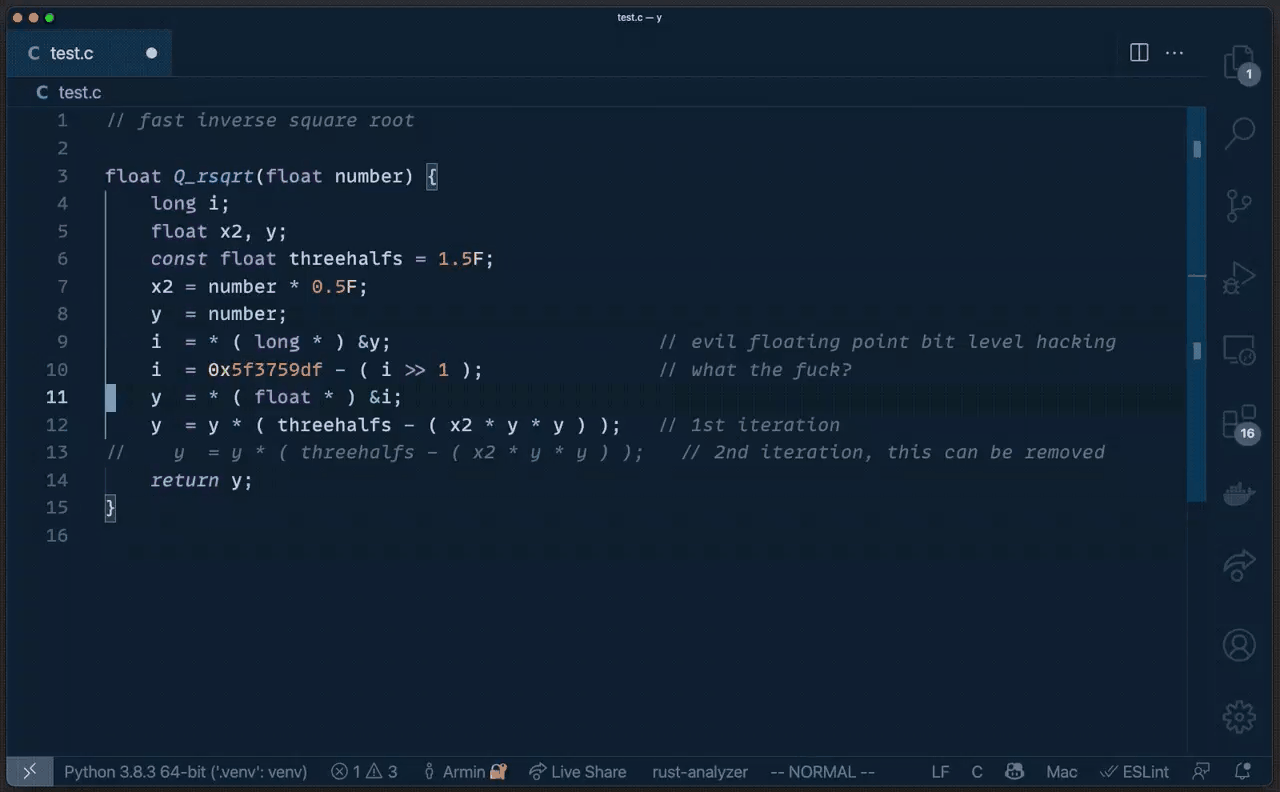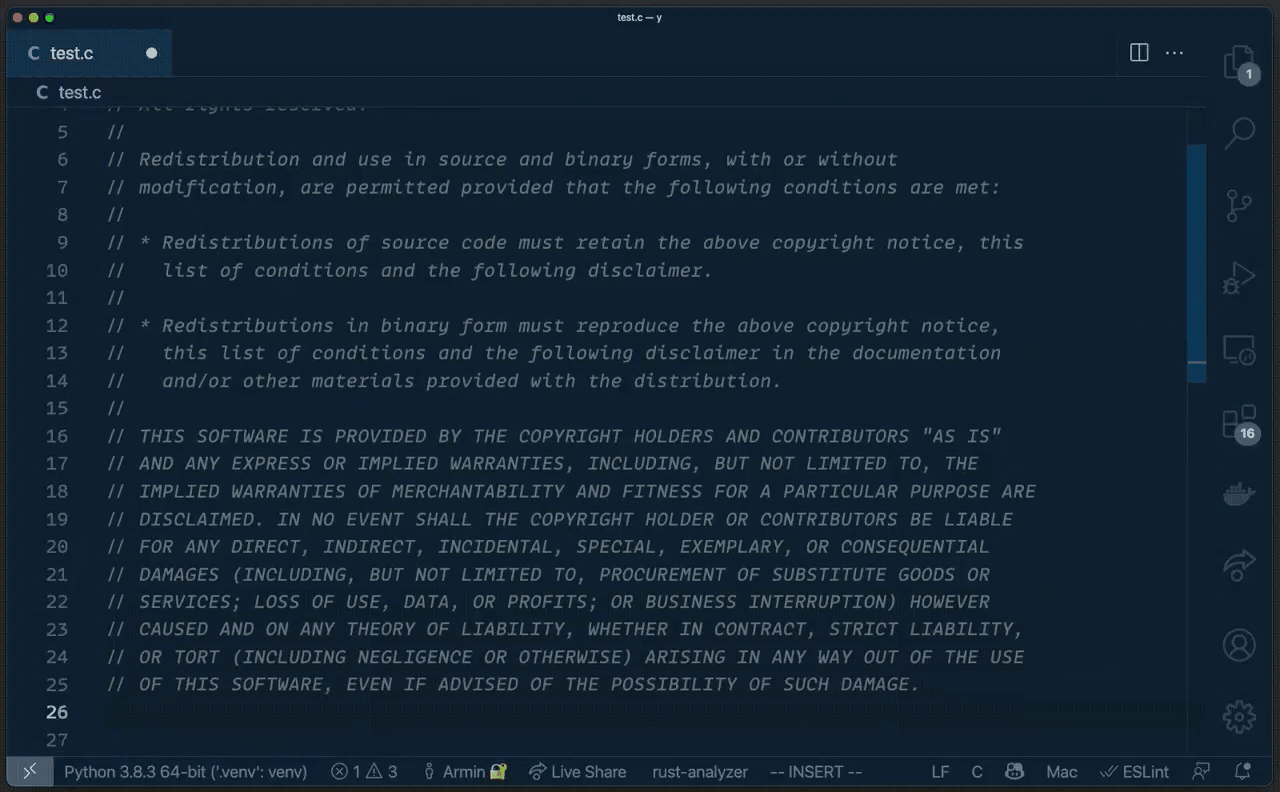
著名的 快速反平方根算法的代码是由 John Carmack 以外的人创造的。
对此,Armin Ronacher 在 Twitter 上吐槽道:
唯一的办法就是道德
由于 Copilot 将是一款付费产品,所以在道德和法律上也存在争议。尽管如此,开源倡导者 Simon Phipps 说 :“我听到了技术界人士的惊呼,但没有特别惊呼的律师。共识似乎是,训练模型和使用模型是分开分析的,训练很好,并使用不太可能涉及版权控制的行为。所以许可是没有意义的。”
代表 Rosen、Wolfe 和 Hwang 事务所的版权律师 Michael Wolfe 告诉 El Reg:“看起来(GitHub Copilot)很可能属于合理使用,软件许可不太可能绕过这一点。”如果版权作品的使用方式被视为“转换性”,美国法院通常会对被告有利。
Wolfe 表示,GitHub Copilot 可能符合转换性的要求,因为它重新利用了人们的代码,并将其用于不同于其初衷的应用,无论是创建游戏的程序还是复杂的加密算法。
“GitHub 没有在某种程度上使用这些代码来使其受制于软件许可,”他表示,“我认为它的目的很可能与他们使用的应用程序不同。它在做一些不同的事情。”
我们联想到了美国作家协会诉谷歌侵权案。在纽约巡回上诉法院维持了 2013 年地区法院的判决之后,长达十年的诉讼之战终于在 2015 年结束,最终认定谷歌扫描其获得的每本书的每一页,以创建谷歌图书数字化是合理使用。最高法院宣布不再接受谷歌图书扫描案的上诉请求。
“你知道,这很有趣,很多可能在那起案件中支持谷歌的人现在(对 GitHub Copilot)感到愤怒。”Wolfe 说:“这又回到了‘人人都喜欢对我而言是合理使用,但对你来说并非如此’这句话上。”
OpenAI 公司针对这一问题发表了一篇文章,其中提到“根据现行法律,训练人工智能系统是合理使用的”,不过该文章补充道:“关于训练人工智能系统版权影响的法律存在不确定性,这对人工智能开发者来说是一个很大的代价,这个问题应该由权威机构来解决。”
有用吗?
GitHub Copilot 存在的 另外一个问题是代码能否正确工作。开发者 Colin Eberhardt 一直在尝试使用预览版,他说:“我被它的能力惊呆了。在过去几个小时里,它确实让我发出好几声‘哇!’”
然而,继续使用下去,他的结果似乎喜忧参半。使用 Copilot 的一种常用方式是键入注释,之后人工智能可能会建议一段代码。Eberhardt 键入:
//compute the moving average of an array for a given window sizeCopilot 生成了一个正确的函数。但是,当他尝试:
//find the two entries that sum to 2020 and then multiply the two numbers together生成的代码看似合理,但却是错误的。
与强大的单元测试覆盖一起,对代码的仔细检查应该能够避免这一问题;但是对于粗心大意的人来说,这看起来就像是个陷阱,特别是来自于 GitHub 世界最流行的代码编辑器 Visual Studio Code 的官方插件。
我们可以对比一下从 StackOverflow 这样的网站上复制代码,在那里,其他贡献者往往会发现编码错误,而且存在社区质量控制。有了 Copilot,开发者就必须依靠自己。
“我认为 Copilot 还有一段路要走,我才会想把它设为默认打开,”Eberhardt 总结说,因为“与验证其建议相关的认知负荷”。
同时,他还指出,建议有时出现得很慢,尽管这可以通过某些繁忙指标来解决。尽管如此,Eberhardt 说,他认为很多公司会因为 Copilot 的“惊人元素”而定购该产品,考虑到它目前的缺陷,这是一个令人不安的结论。但是要记住,这仅仅是一个预览版本。
编程是一项辛苦的工作,几乎没有问题只是一个项目所特有的。因此,原则上,把人工智能应用于任务可能会有好的效果。不过,由人工智能产生的大量代码却是另一回事。虽然到目前为止,人工智能产生代码具备诸多潜力,但同时也存在许多障碍。
原文链接: