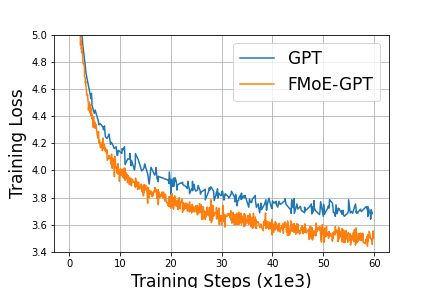
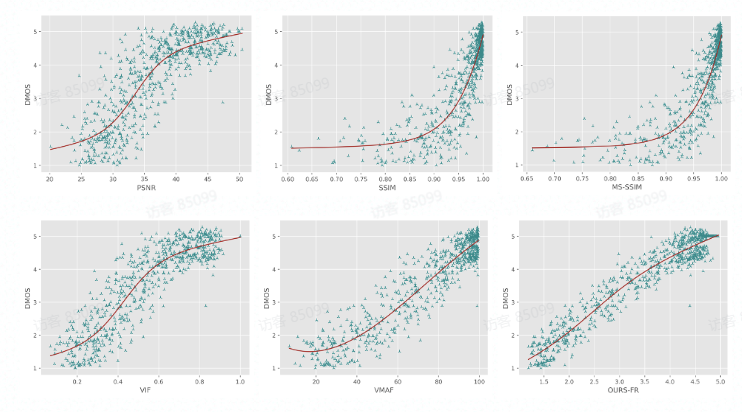
Meta开源了它的 Text-to-Music 生成式人工智能AudioCraft,供研究人员和从业者训练他们自己的模型,并帮助推动前沿技术的发展。
AudioCraft 包含三个不同的模型:能够根据文本提示生成音乐;能够产生环境声音;是一个由 AI 驱动的编码器/量化器/解码器。
据 Meta 介绍,AudioCraft 能够使用自然界面生成高质量的音频。此外,他们还说,AudioCraft 利用一种新方法简化了音频生成领域最先进的设计。
具体来说,AudioCraft 使用 EnCodec 神经音频编解码器从原始信号中学习 Audio Token。这一步从音乐样本创建出了固定“词汇表”(Audio Token),并随后将其传递给自回归语言模型。这个模型训练了一个新的音频语言模型,利用 Token 的内部结构来捕捉它们的长程依赖关系,这对音乐生成至关重要。最后,这个新模型基于文本描述生成新的 Token,并将其反馈到编解码器的解码器以合成声音和音乐。
如前所述,AudioCraft 是开源的,Meta 希望能够帮助研究社区以它为基础做进一步地构建:
虽然 AudioCraft 的大部分是开源的,但是他们为模型权重选择了CC-BY-NC许可。Hacker News 上有用户指出,该许可限制较多,并不算完全开源。
具体来说,非商业性使用条款违背了开源倡议对开源的定义中的第六点,这很可能是因为 Meta 使用了 Meta 拥有并特别授权的音乐来计算这些权重。其余组件将在MIT许可下发布。
原文链接: