中国公司赛格威制作数据集 DRIVE,助力智能货运机器人研发

中国机器人公司赛格威的研究人员正在制作一个名为“DRIVE” 的数据集和基准,旨在帮助研究人员研发更智能的货运机器人。
赛格威制作“DRIVE” 数据集的目的是鼓励相关业务领域的研究,同时也是基于宏观经济趋势的考虑:“中国的线上购物和外卖配送市场每年以 30%-50%的速度增长,引发了劳动力短缺及送货成本上升的问题,” 研究人员写道。货运机器人有可能解决这个由消费需求上涨及送货劳动力短缺造成的困境。
每个用来收集数据集的赛格威机器人都配备一个 RealSense 惯性传感器,两个车轮编码器以及一个 Hokuyuo 2D 激光雷达。
DIRVE 数据集 :该数据集包括 100 个移动镜头,收录内容涵盖五个不同的室内场地,由机器人在一年的时间内收集,它的设计相当具有挑战性,包括以下综合因素和特性:
慢还是快 :在一些数据集包含的长镜头中,机器人是静止的,这使得它难以估计深度。同时,在其它时候机器人也会快速转动,这会带来运动模糊及车轮在地面打滑的问题。
为什么这很重要 :数据集解锁 AI 发展,让多人一起协作解决挑战。另外,数据集一般会暗示着商业及研究的优先项,因此 DRIVE Benchmark 的出现暗示了智能移动机器人正逐渐成熟。
阅读更多:
top="2044.171875">印度开发野生灵长类面部识别系统
印度德里 Indraprastha 信息技术研究所和印度野生动物研究所的研究人员合作开发了一种能够识别野生猴子的系统,并将其关联到一个众包应用上,让“普通大众、专业的猴子捕捉者及野外生物学家“能够提供猴子的源图像,用来训练更大、更智能的模型。
为什么这样做? 研究人员写道,在印度的城市和半城市化地区猴子都有点令人讨厌,因此他们设计了这个系统,利用“在野外”获取的的数据,帮助人们建立系统来监视和分析生存在具有挑战性的环境中的灵长类动物。 “ 我们希望捕捉到猴子在不受控制的室外场景中的图像,这种环境下面部姿态和光线会出现明显变化”。
数据集 :
恒河猴数据集:7679 张图片/ 93 个猴子。
黑猩猩数据集:7166 张图片/ 90 个灵长类动物。在所有的图片中,来自动物园的图片质量较高,而来自国家公园的图片质量不可控。
结果 :
该系统优于各种基本标准,并在四个验证分数中表现出了最优性能,通常情况下性能表现增加至少 2 个点,有时多达 6 个及以上。经过一系列不同的损失函数训练,系统会捕捉较小的面部几何特征,从而增强模型在多个数据分布中的鲁棒性。
为什么它很重要 :这项研究显示了随着人工智能逐渐成熟,我们开始看到它被用作一种通用的实用工具,研究人员混合和匹配不同的技术和数据集,进行轻微的调整,并为社会相关的应用处理任务。有趣的是,这种方法与众包应用程序集成的方式让我们看到未来的方向,即人们能够协作测量、分析和量化周围的世界。
阅读更多:野生灵长类面部识别(Arxiv)
top="2801.171875">Recursion 发布 RxRx1 数据集,助力新药物开发
Recursion Pharmaceuticals 是一家利用 AI 进行药物开发的公司,它发布了一个名为 “RxRx1”的 296GB 的数据集,其中包含 1108 个类别的 125510 个图像。RxRx1 是一个 ImageNet 规模的数据集,它包含了人体细胞的图片,帮助科学家训练 AI 系统以观察它们的模式,进而从中获得发现促进新药物的开发工作。
生物学的挑战 :由于细胞样本之间的差异以及数据采样过程中存在的其他因素(如温度、湿度、试剂浓度等),生物数据集可能会对图像识别算法带来挑战。 RxRx1 包含来自同一实验的 51 个实例数据,有助于科学家开发对实验中的变化具有鲁棒性的算法,从而学习数据中的基础模式。
RxRx1 可以在哪些方面助力人工智能研究?Recursion 的想法如下:
为什么它很重要 :我们正进入的是一个人们将开始利用大规模机器学习来彻底改变医学的时代;跟踪 RxRx1 等数据集的使用情况以及 NeurIPS 2019 竞赛结果将有助于我们了解该领域的进展以及它对医学和药物设计的意义。
阅读更多:RxRx1 官方网站()
top="3469.171875">纽约大学推出用于 AutoML 模型构建和管理的交互式系统 Visus
纽约大学的研究人员开发了 Visus 软件,该软件使人们构建、改进模型以及管理模型训练的相关数据处理管道更加容易。作为一种工具,它体现了人工智能社区工业化愈加广泛,并预示了机器学习在社会中的更大用途。
什么是 Visus? 该软件为 AI 开发人员提供了一个软件界面,可以让他们定义问题、研究输入数据集的摘要、增加数据,然后根据它们的性能得分和预测结果来探索和比较不同的模型。该软件的用户界面设计精美,这使得它比只能通过命令行访问的工具更易于使用。
它能做什么?不能做什么? Visus 是“kitchen sink 软件“,这是因为针对探索性数据分析、问题说明、数据增强、模型生成和选择,以及验证数据分析等任务,它包含大量的功能。
用例 :研究人员举了一个例子,假设纽约市交通部用 Visus 来制定可以减少交通事故死亡率的政策。他们首先使用 Visus 来分析有关交通碰撞事故的数据集,然后在数据集中选择一个他们想要预测的变量(例如,碰撞事故的数量),然后让 Visus 进行模型搜索(要不然它就会被称为’AutoML’了),这时 Visus 就会试图找到适当的机器学习模型来实现目标。它提出模型后,用户还可以尝试扩充基础数据集,然后再次迭代模型设计和选择。
为什么它很重要 :像 Visus 这样的系统是人工智能产业化的一部分,因为他们做了一系列令人难以置信的复杂事项(如数据增强和模型设计与分析),然后将其移植到对用户友好的软件包中,从而使得能使用这样系统的人增多。这就像从手工个性化生产转向基于系统的可重复生产。Visus 之类工具的采用将使社会中更多的人使用人工智能系统,从而进一步改变社会。
阅读更多:Visus:自动机器学习模型构建和管理的交互式系统(Arxiv)
top="4136.171875">史上最强 AI 补代码工具 Deep TabNine
加拿大一名大四学生 Jacob Jackson 开发了一款名为“Deep TabNine”的自动代码补全工具,旨在帮助开发者提高编码速度。目前 Deep TabNine 可支持 Java、Python、C++及 Haskell 等多种编程语言。
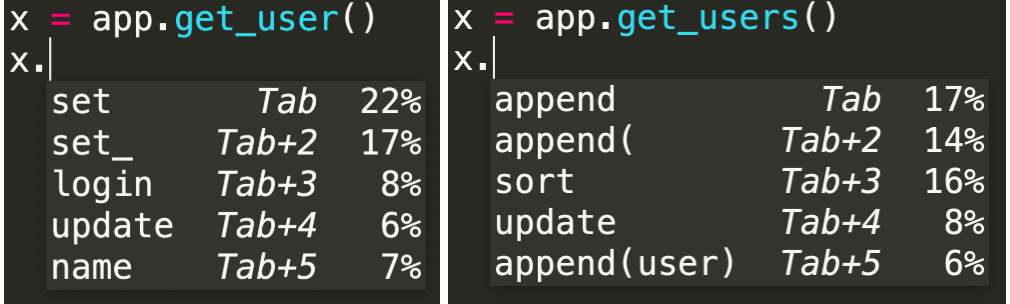
Deep TabNine 的开发者利用 GitHub 上约 200 万个文件对它进行了训练,用前面的 token 来预测下一个 token。为了实现代码补全功能,Deep TabNine 学习了动态类型语言中类型推断等复杂行为。甚至是一些细微的线索 TabNine 也可以利用起来,比如假设 app.get_user()的返回类型是一个带 setter 方法的对象,但 app.get_users()的返回类型却是一个列表:
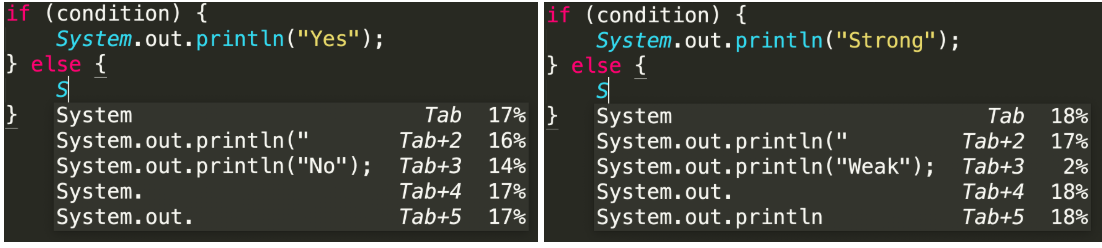
Deep TabNine 基于 GPT-2 构建,使用的是 Transformer 网络架构。这个架构最初被开发出来是为了解决自然语言处理领域存在的问题,尽管构建代码模型和构建自然语言模型看起来毫不相干,但构建代码模型是需要以一些意想不到的方式理解英语的。比如利用 if/else 语句让模型否定单词:
这个模型还能利用自然语言写的文档来推断函数名称、参数和返回类型:
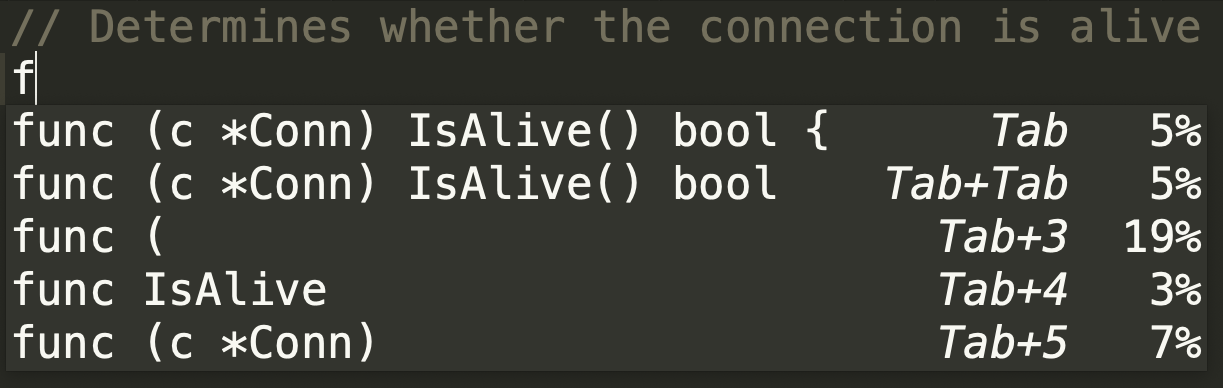
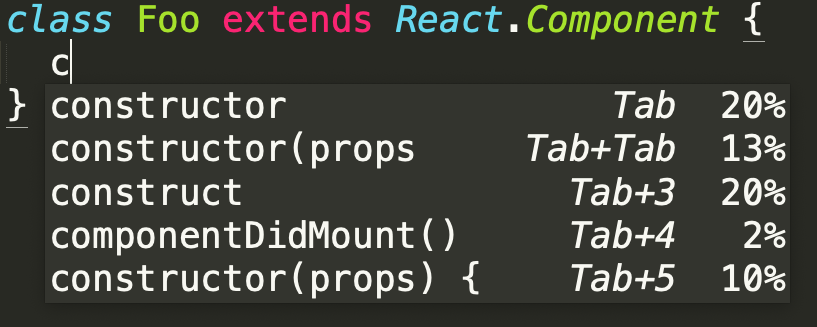
此外 TabNine 还应许多用户的要求加入了先前就存在的知识,例如当一个类扩展React.Component 时,它的构造函数通常会采用一个名为 props 的参数,且用 this.state 进行赋值。
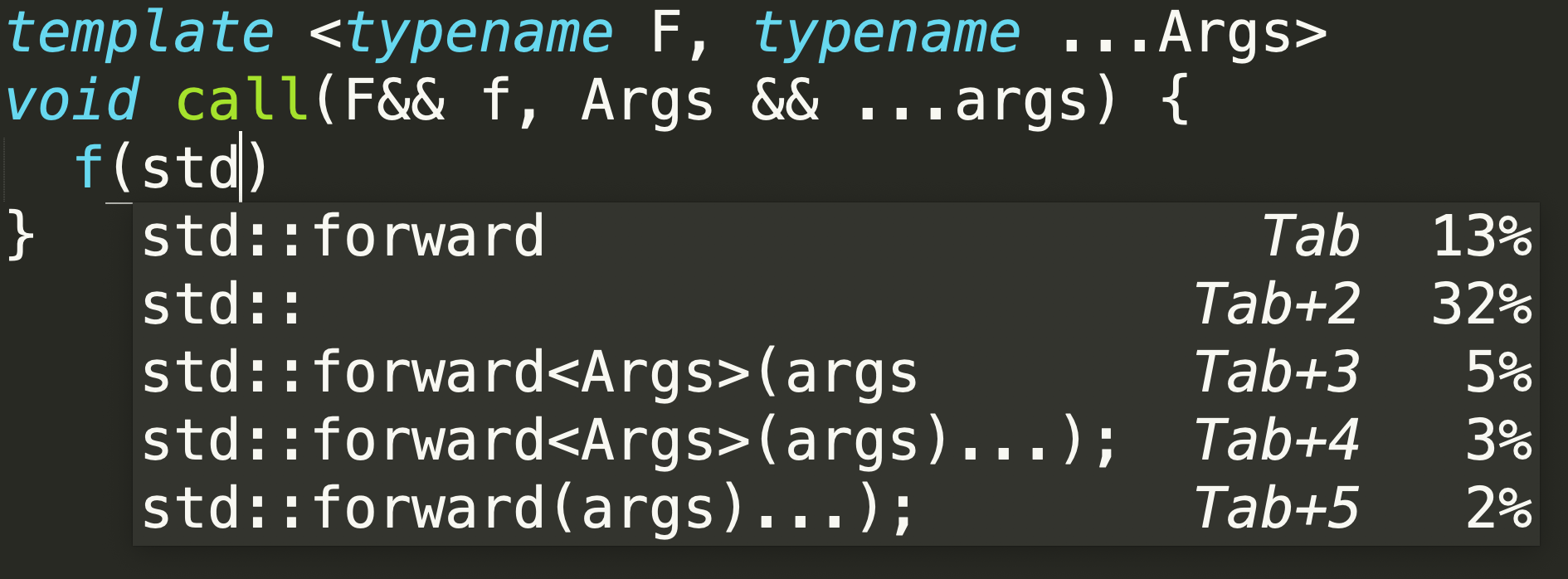
Deep TabNine 甚至可以记住 C++可变转发句法:
Deep TabNine 需要大量算力,用户在笔记本电脑上运行这个模型则无法获得低延迟体验,因此开发者推出了 TabNine Cloud 服务方便用户使用。
阅读更多:top="5198.171875">AI 攻克六人无限制德州扑克游戏
Facebook 与卡耐基梅隆大学(CMU)共同研发的 Pluribus 在六人无限制扑克游戏中打败了多名精英玩家。比赛采用两种模式:“5 个 AI+1 名人类玩家”和“1 个 AI+5 名人类玩家”。这是 AI 首次证明它有能力在多人游戏中战胜顶级专业人士。
Pluribus 是基于以及卡梅隆大学 Tuomas Sandholm 实验室的其它算法和代码改进而来,曾于 2017 年在两人无限制扑克游戏中战胜了人类专业玩家。值得一提的是,Pluribus 整合了一种新的在线搜索算法,通过提前搜索一些动作可以帮助 AI 有效评估自己的选择。它还利用了新的 self-play 算法来应对游戏中存在的隐藏信息。这些提升使得 Pluribus 的训练只消耗了很少的处理能力和内存,与之相比,一些 AI 里程碑式的项目动不动就要耗费耗费价值几百万美元的计算资源。
阅读更多:
top="5596.171875">研究人员提出多线性模型,可压缩模型参数、提升模型表现
神经模型的最新进展将编码器和解码器通过自注意力机制联系起来。Transformer 就是一种完全基于自注意力机制的架构,它的出现为自然语言处理任务的解决带来了突破性进展。然而,Transformer 的重要组成部分——多头线性注意力机制却限制了神经模型的有效部署。
为了解决这个问题,天津大学和微软亚洲研究院的研究人员根据张量分解和参数分享的理念提出了一个带 Block-Term Tensor Decomposition (BTD)的自注意力模型(也就是多线性模型)。研究人员对三个语言建模任务和一个神经机器翻译任务进行了测试,证实多线性注意力不但可以大大压缩模型参数,还能提升模型表现。
阅读更多:
top="5963.171875">英特尔发布 Pohoiki Beach 系统,搭载神经形态芯片 Loihi
在美国国防部高级研究计划局(DARPA)2019 电子复兴峰会上,英特尔实验室总监 Rich Uhlig 公布了一个名为“Pohoiki Beach”的系统,这是一个 64 芯片计算机,能够模仿 800 万个神经元。 Uhlig 称英特尔将向 60 个合作伙伴提供该系统,以促进该领域发展,并升级冗余编码和路径规划等 AI 算法。
Pohoiki Beach 搭载了 64 个 128 核、14 纳米的神经形态研究芯片 Loihi。据称 Loihi 处理信息的速度比传统处理器快 1000 倍,效率高 1000 倍。
阅读更多:top="6379.171875">CVPR 新研究:光流引导可填充视频缺失区域
CVPR 最近刊登了一项由商汤港中大联合实验室和商汤南洋理工联合实验室的研究,提出了一个名为“光流引导” (Flow-Guided) 的视频修复算法。
研究人员首先使用新设计的 Deep Flow Completion 网络在视频帧上合成了一个空间和时间上相干的光流场,然后用它来引导像素的传播,以填充视频中的缺失区域。该光流引导可以帮助精确地填充缺失的视频区域。研究人员将这种方法在 DAVIS 和 YouTube-VOS 数据集上进行了定性和定量评估,结果显示,无论是在质量还是速度上,填充性能都非常优越。
阅读更多:作者 Jack Clark 有话对 AI 前线读者说:我们对中国的无人机研究非常感兴趣,如果你想要在我们的周报里看到更多有趣的内容,请发送邮件至:jack@jack-clark.net。
参考链接: