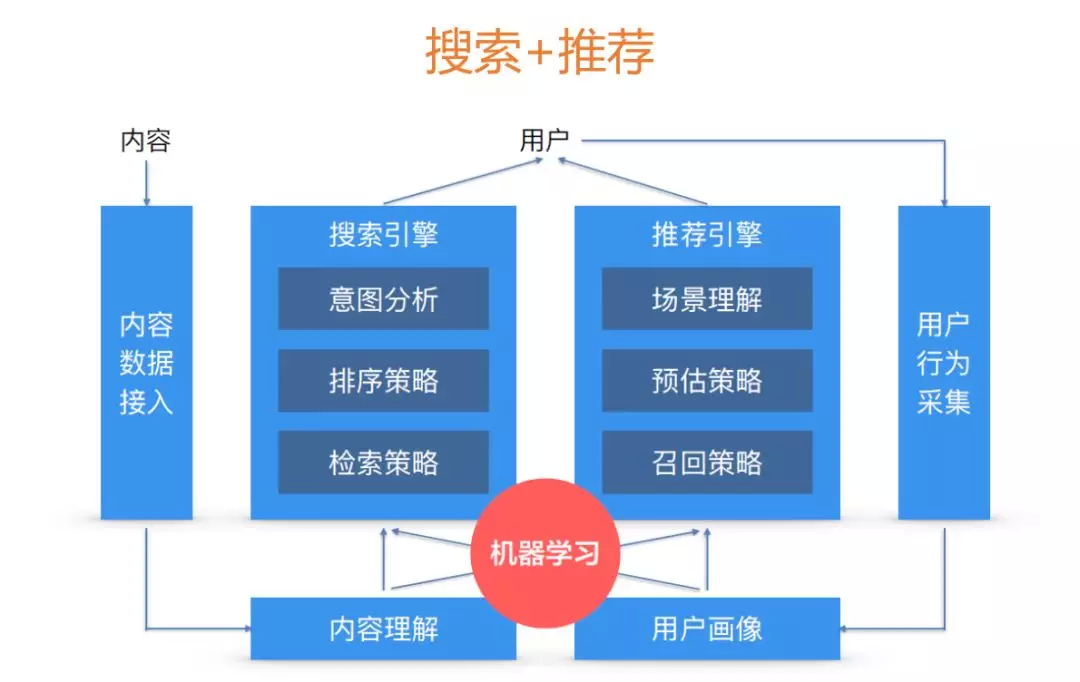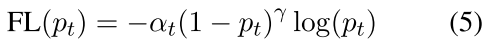
自然语言处理的国际顶级会议 ACL2019 刚在文艺复兴的发源地-意大利的佛罗伦萨落下帷幕,最佳论文等各奖项也都名花有主。本文概述了 ACL 对话与交互系统中的报告论文,16 篇优秀论文看这篇文章就行。
我们对对话系统比较关注,因而梳理了会议中 Dialog and Interactive Systems(对话和交互系统)下的文章,该主题共接收长文 38 篇,有 16 篇在会议中做了报告。下面介绍报告中的相关论文。
本次会议中,Dialog and Interactive Systems 分了三个 section,分别是 Neural Conversation Models, Task-Oriented Dialog, 和 New Task。
神经网络对话模型(Neural Conversation Models)
这个 section 的工作,是在给定对话历史的情况下,如何通过模型来选择对话中最优的回答:
文章针对对话系统中容易出现的通用和一般性回答,做了些优化来提升生成对话文本的相关性和多样性。其工作,是基于 RAML(Reward-augmented Maximum likelihood learning, Norouzi 2016)模型:该模型的目标是最大化预测的分布 y*在模型中条件概率分布 p(y|x),并在模型迭代中采用连乘的 boosting,使每一轮迭代能更好的模拟分布。
本文的优化,是在模型迭代中假设训练数据的分布服从均匀分布,来简化 boosting 的过程,并把这个假设扩展到 RAML 模型的指数回报分布(exponential payoff distribution)中:
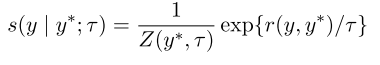
在实验中,作者发现通用的回答也不一定总是有低混淆度 Perplexities(Li 2017b),而高混淆度会在迭代中增强对应的回答的权重,导致通用回答在后面的迭代中出现的频率越来越高。普通的区分模型,是通过学习人产生的回答与生成式回答的差异,但在这,生成式回答数量太少,模型能轻易记住所有人类的回答,导致模型不好泛化。
作者采用了一个基于规则的区分模型:在每次迭代中,保留一个最常出现的生成式回复的列表,并用一个简单的二分函数来判断两个回复是否相似,用这个相似得分去更新数据的权重。最后在 Persona>
Bengio 大神署名的文章,主要是研究现有的神经网络模型是否有效利用了对话历史,其方法,是在对话历史中加入一点扰动,比如,改变对话数据的先后顺序,或者改变词的顺序,然后看模型计算的条件概率是否有变化。需要注意的是,扰动只是发生在预测阶段,而训练阶段,是没有对数据做修改的。
文章在 4 个数据集上(bAbI dialog,Persona Chat,Dailydialog,MutualFriends),加入了 10 种不同的扰动(随机打乱句子序列,去掉某个整句,句子截断,去掉句子中的名词或动词等),发现 seq2seq 的 model(Bahdanau 2015),以及 transformer 的 model(Vaswani 2017)等对这些扰动都不敏感。
本文通过加入时序和空间上的 feature,来解决对话系统中的回复句子的选择问题。方法分两步,第一步是通过软对齐来获取上下文和回复之间的关联信息;第二步是在时间维度聚合注意力的映像,并用 3D 卷积和池化来抽取匹配信息。模型分表达模块(Representation module)和匹配模块(Matching block)两部分,如图 1,表达模块用的是 Bi-GRU,匹配模块用的是深度 3D 卷积网络(Ji 2013)。
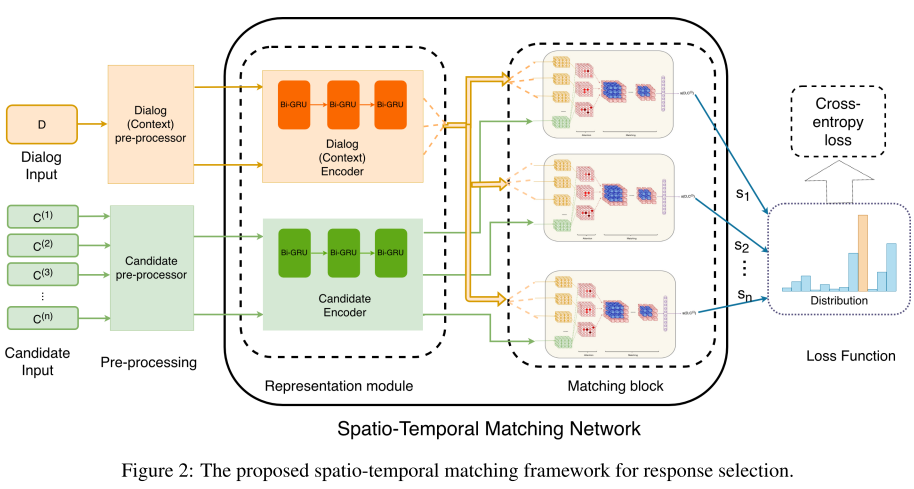
图 1
时序和空间上的匹配体现在如下过程中:句子空间上的关联,通过 attention 机制来构建;时间上的关联,则是把不同时间维度上的 3D 特征扩展成 4D「方块」(cube),之后采用类似 2D 卷积核对 3D 数据的处理流程,这里用 3D 卷积核来处理 4D 数据,并在 3D 上进行池化操作。最后再加上一个 softmax 进行分类。
方法在两个数据集上,和 Dual LSTM Encoder(lowe 2015b),Dual Multi-turn Encoder,Sequential Matching Network(Wu 2017),Deep Attention Matching Network(Zhou 2018) 比较了 R@1 和 MRR,得到了较好的比较效果。
这是一篇来自腾讯和阿里的文章。本文的想法,是通过语句改写,来解决多轮对话中信息省略和引用的问题。通常,在多轮对话中,后续的问句会和前面的问句存在部分指代关系,因而后续问法会省略到部分信息。
如图 2 所示的,第一句「梅西有多高」,第二句「他和 C 罗谁是最好的球员?」,这里的「他」指代的就是前面的「梅西」。这种指代或者信息省略的情况,使得机器很难去理解对话的真实意图。因而,本文的工作,是构建一个模型来生成补全信息后的句子。
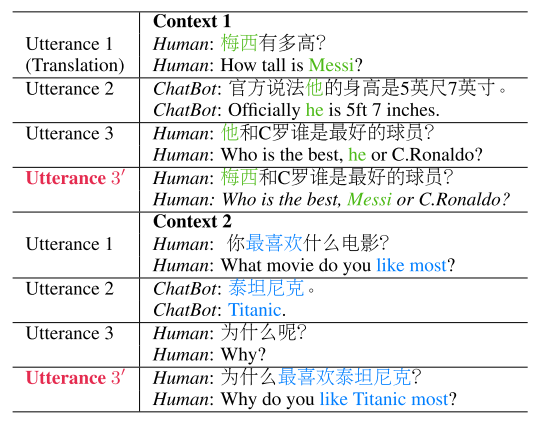
图 2
为了让模型学习到自动补全的能力,本文作者花时 4 个月,建立了一个补全的对话数据集。原始数据由 20 万中国主流社交网站上的多轮对话组成,标注人员在标注时,进行判定:对话是否有指代,或者有信息省略,或者两者都没有。
统计表明,只有 30% 左右的对话是没有指代和省略的。然后标注人员需要提供改写后的信息补全的句子。最终,数据集包含了 4 万高质量的多轮对话样例,正负样本(有改写的为正样本,无改写的为负样本)各占 50%。
在模型上,还是采用了 Transformer(Vaswani 2017)架构来做 Encoder-Decoder。其中,Encoder 里除了 word embedding,position embedding 之外,还加入了对话的轮次 embedding 信息;在 Decoder 中,加入了一个阀门参数λ,来控制是否要进行语句的改写。
图 3 展示了完成的编解码过程。最终的实验结果,表明在语句改写之后的准确率,召回率,以及 F1 值上,都比不加改写过程的模型要提升 3% 到 5%。
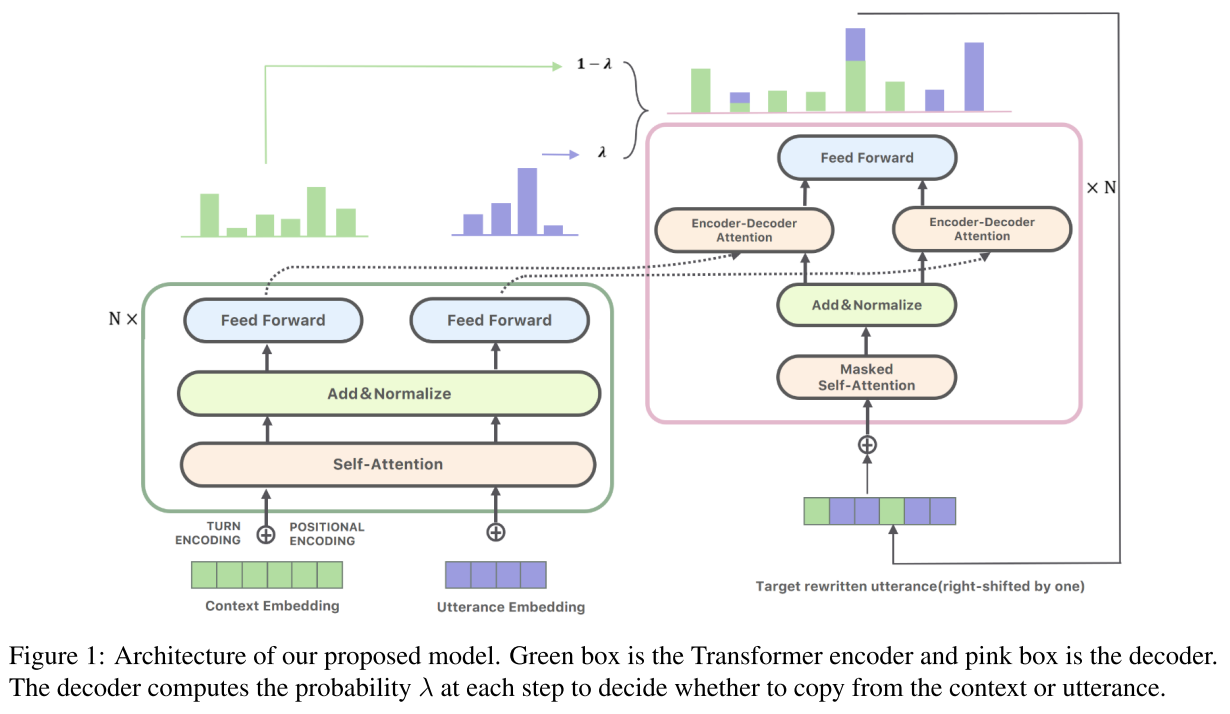
图 3
本文提出了在有文档背景信息的多轮对话中,一种基于 Transformer 的对话生成模型。任务描述如下:当多轮对话的内容,和一个文档集合相关时,模型的目标,是输出一个整合了文档知识在内的对话回复。因而,模型的输入,除了已有的多轮对话历史,还有一个文档的集合。任务需要解决的问题有两个,一是需要挖掘文档中和对话相关的部分;二是将多轮对话的语句,和文档中的相关部分进行统一的表示。
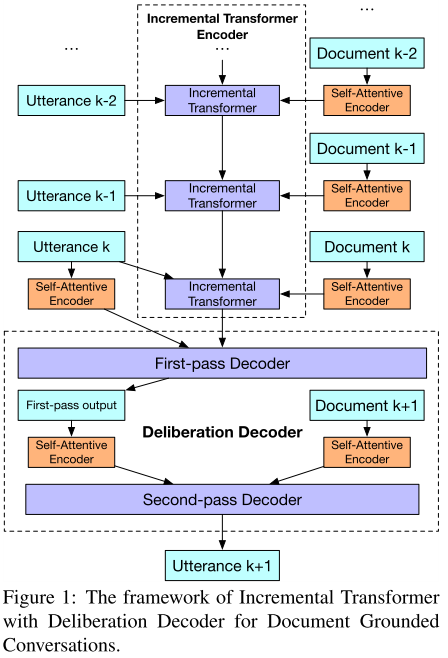
图 4
本文提出的模型,有两个创新,一是提出了一个增量式的 transformer 结构,可以将对话的句子,以及相关联的文档,增量的添加到模型中;二是提出了一个两阶段的解码思想,第一阶段关注对话的上下文连贯性,第二阶段引入相关的文档内容,来对第一阶段的结果进行修正润色。具体架构见图 4。这个模型分几个部分:
图 4 的上部分是 Encoder 部分,其中:
这里面的 Self-Attentive Encoder,和 ITE 都是多层结构,即上面描述的单元可以继续累加,组成深层网络。
图 4 的下部分是解码部分,包括两阶段解码。这两阶段的模型结构一样,只是输入不同,都包括 4 个子层(图 5(c)所示)。完整的解码由 Ny 个两阶段解码器累加的深层网络组成。
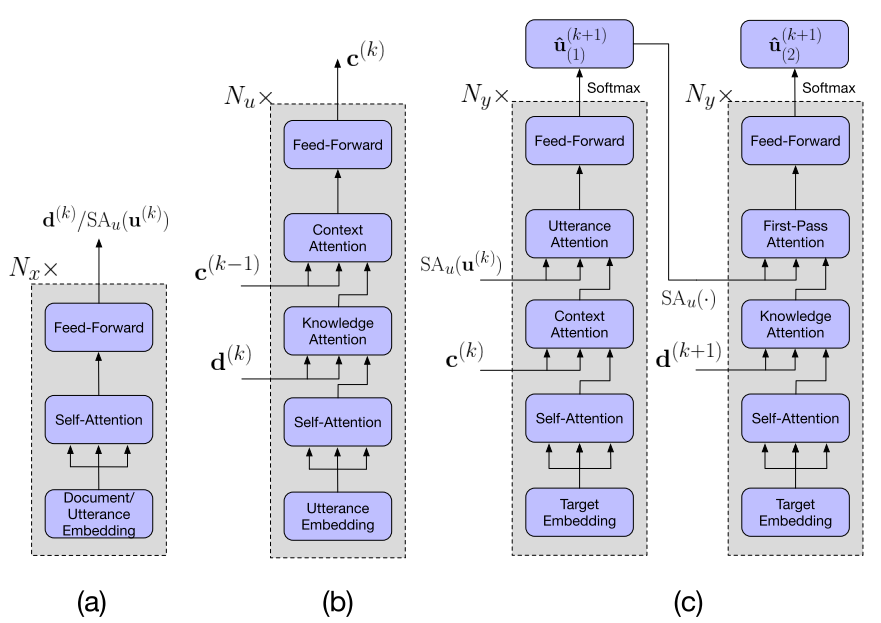
图 5
实验采用的数据集(Zhou 2018),用 73k 的语句训练,3.6k 语句验证,11.5k 的语句做测试。评测指标包括 PPL(perplexity),BLEU,Fluency,Knowledge Relevance 和 Context Relevance。其中后面的三个指标由标注人员在随机采样的数据上标注完成。
对比的模型,包括最基础的 Seq2Seq,Transformer,Hred(Serban 2016)等,和本文的模型的一些扩展变化模型。需要说明的是,本文模型在 PPL 上有个显著提升(15.11,越小表明更好的性能),原因是解码器的第二阶段极大的提升了结果(图 6)。
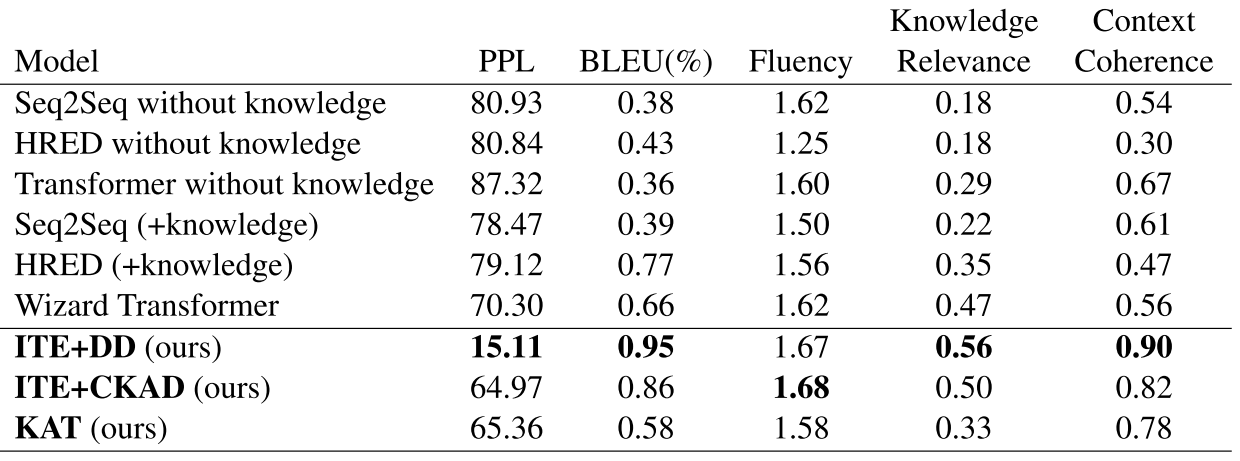
图 6
本文提出了一个基于检索的深度交互对话模型,来解决现有模型中,对对话交互信息利用较浅的问题。问题的定义如下:对话数据由 D={(yi,ci,ri)} 三元组组成。其中 ci 是对话的问句,ri 是回复,yi 是标记,表明 ri 是否是 ci 的回复。模型需要计算 ci 和 ri 之间的匹配得分,来表明两者是否是关联的。
本文的核心,是定义了一个 Interaction-over-Interaction(IoI)网络。这个网络由 Interaction Block 构成。每一个 block 包含一个自注意力模块,来抽取问句或回复之间的依赖;一个交互模块,来对问句和回复之间的交互进行建模;一个压缩模块,来将前两个模块的结果合并成一个。
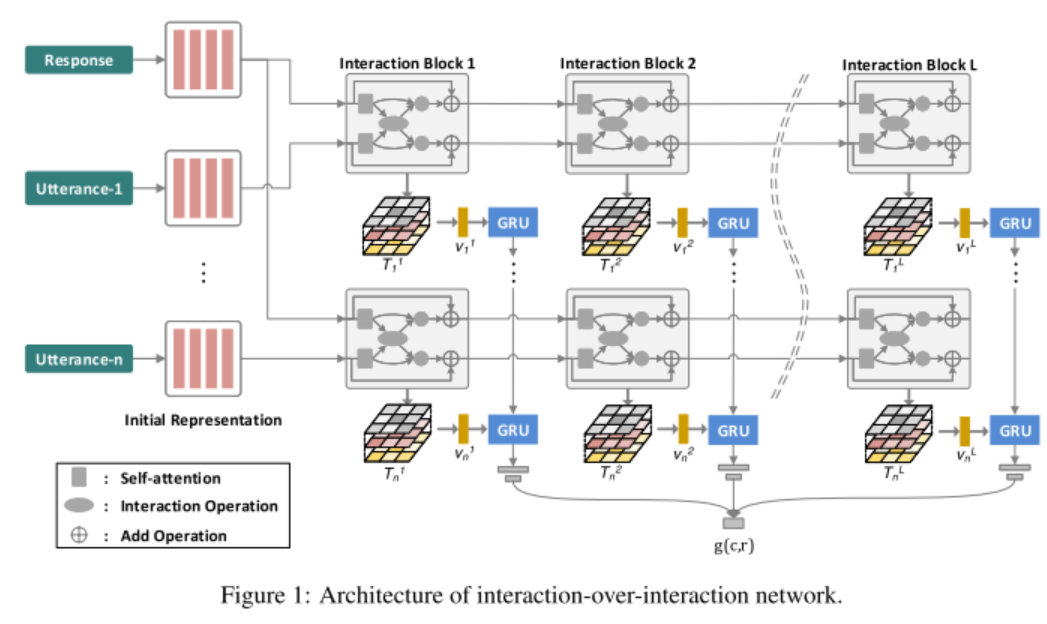
图 7
一个 IoI 模块的细节如下:给定两个输入 Q 和 K,从 Q 到 K 的注意力机制为:
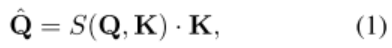
其中 S 为函数:
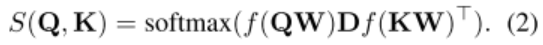
f 为 ReLU 激活函数,D 为对角阵,和 W 一样都是模型的参数。然后将公式(1)的结果输入一个残差网络和正则化层,再输入一个 FFN 层:
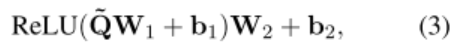
至此,这一整个流程被定义为 fatt(Q,K)函数:
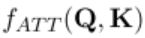
定义完 fatt 函数后,再回到 IoI block 的三个模块:
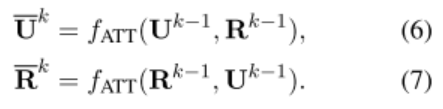
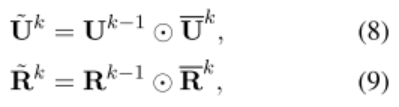
经过 IoI 网络后,在计算匹配得分时,用到了问句 u 和回复 r 在 IoI 网络中几个模块的结果:
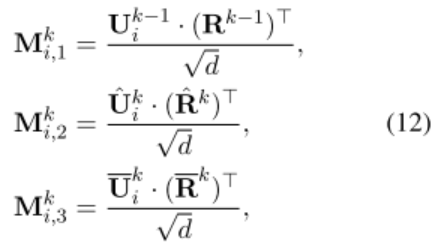
再把这三个 M 向量连接后,输入一个卷积网络(Krizhevsky 2012)来抽取匹配特征,然后拉平后做一个线性变换,将输出维度恢复成 embedding 的维度,再连接一个 GRU 来获取时序的关系,最后经过一个隐藏层,输出到 sigmoid 函数,得到最终的匹配的分。
模型在三个数据集上做了验证,评测指标包括 R@N,MAP 和 MRR。整体来看,方法对比现有的模型,效果约有 2% 左右的提升。(做出提升不容易呀)
任务导向的对话(Task-Oriented Dialog)
这个 section 关注的,是如何优化涉及到任务的对话。通常,任务式对话里面包含有领域和意图的分类,槽位的挖掘和填充等。
本文提出了一种新的树形结构,来更好的表示 Mean Represention(MR)。MR 是一个 key-value 的列表,其中 key 是槽名(slot),value 是槽对应的值。传统的 MR 表示,是扁平的,因而会丢失槽之间的评论关系。
图 8 展示了一个原始的句子(Reference 1),改写成 Flat MR 的例子(E2E MR),以及本文改写后的树形 MR 结构(第四行)。相比 Flat MR,树形 MR 保留了 Slot 之间的关系,比如转折(Contrast),联合(Joint)等等。
除此之外,树形 MR 还有助于加强槽之间的可控性(controllability),而这点在某些特定的对话中尤其重要,比如当用户指定了某些喜好时。

图 8
本文构建了一个树形 MR 的数据集。一个树形 MR 包括三个要素:
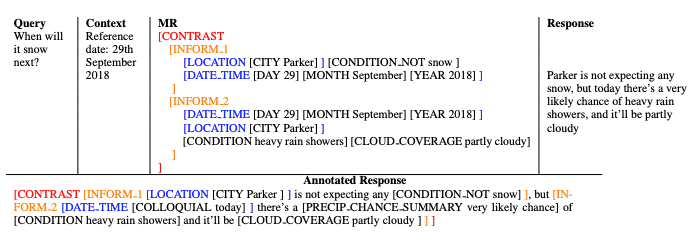
图 9
最终获得了包含 33k+个样例的数据集。在这个数据集的基础上,用 seq2seq 的模型来学习,编解码主体是带 attention 的 lstm,输入是树形 MR 的结构(图 9 的第 3 列),输出是带回复的树形 MR 结果(图 9 中的 Annotated Response)。
其中,在 decoder 中,用了剪枝的算法,剪枝算法包括两方面,一是对树种的节点进行聚类;二是输出中的格式验证,如中括号的配对等。实验和基础的 seq2seq 模型进行了对比,评测方式包括自动评测和人工评测。
基于神经网络的端到端(end-to-end)对话系统在任务式对话中表现良好,但在面对新的用户行为时,受限于训练数据的缺失,无法得到预期的结果。这里的新的用户行为,不是指历史数据中完全没有的,而是在训练数据中部分出现的,比如在对话记录或者用户行为模拟中,删除掉部分对话语句或者行为。
本文提出了一个端到端的训练方法,来识别新的用户行为,以便转交给人工处理,在转交的过程中,要考虑移交的成功率和人工的工作量之间的平衡;同时也能从人工的反馈中学习如何处理这种新的用户行为,更新模型,用于将来的处理。图 10 描述了系统的整体架构。
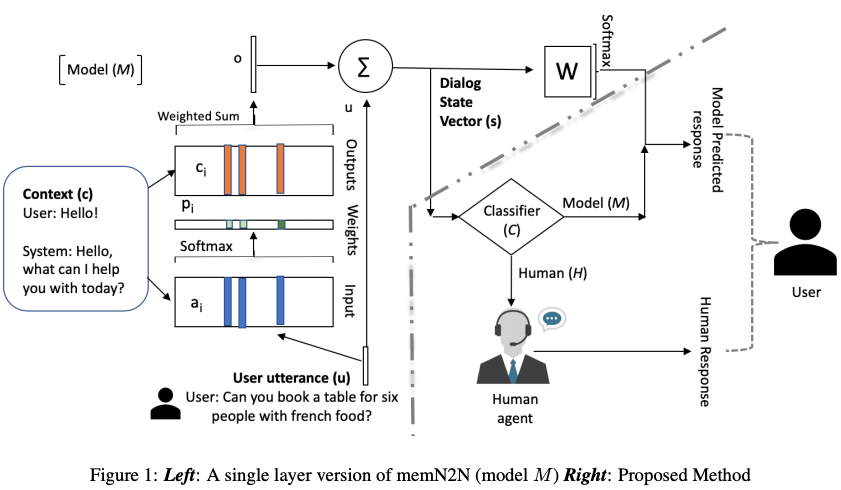
图 10
问题的定义如下:用户问句 utterance 进入系统后,经过模型 M,变成对话的状态表示 s;然后由分类器 C 来决定是由人工 H,还是由模型 M 来回复。分类器 C 是需要在尝试分配和错误中不断修正,因而是采用 Reinforce Learning 来训练的:
这里的正确与否,则是通过用户的反馈来判断的。这个奖励函数有助于最大化回复的成功率,并且最小化人的工作量。同时,分类器的梯度更新也会回传到模型 M,让 M 能将对话的基本信息和对回复的信任度整合起来。
当分类器选择人工 H 的时候,H 的回复会被在线的加入到训练数据中,通过监督学习,来帮助模型学习新的用户行为。本文的对话模型 M 用的是端到端的记忆网络(memory network)(Sukhbaatar 2015),分类器 C 用的是多层感知机。
为了训练模型,需要对现有的对话任务数据进行变化,来模拟新的用户行为。本文基于 bAbI 对话任务(Bordes 2016),构建了一个 Modified bAbI 对话任务。bAbI 是基于饭店预订的场景的预订座位任务。
里面有 5 类 tasks:分别是提交 API 查询,更新 API 查询参数,展示选项,提供额外信息,以及这四类的合并。而 Modified bAbI 通过删除或者替换某些用户行为来生成对话任务数据。比如,删除用户预订中的提供的价格区间,城市或者电话信息。实验对比了这种(模型 M+分类器 C)的联合模型和基础的端到端记忆网络模型的结果,在准确率上提升很明显。
多任务学习(Caruana 1993)相比单任务学习,能更好的利用任务间的共性和数据共享,避免个别单任务的训练数据不足的问题。本文提出了并行网络和串行网络两种多任务学习的结构,并应用在虚拟助手(virtual assistants)的多领域自然语言理解中。通常,虚拟助手,例如 Alexa,微软的 cortana,google assistant 等,会涉及到很多领域范围(domain),比如音乐,交通,日程安排等。在每个 domain 中,又会定义很多意图(intent),在意图下,会包含槽位(slot)信息。对话模型对领域和意图进行分类,抽取并填充槽位信息。
本文通过对任务组合的力度,来抽取单个任务,任务组(task group),以及全体任务(task universe)三类特征。任务组指的是同领域下的类似的对话任务。具体的模型结构如下:
每个任务都会被输入到 Task Encoder 中,生成 Task features;iv) 每个 Task features 会和 Universe features,Group features 连接,作为 Task Decoder 的输入,得到最后的结果。在这个模型中,三类 feature 是并行生成的。
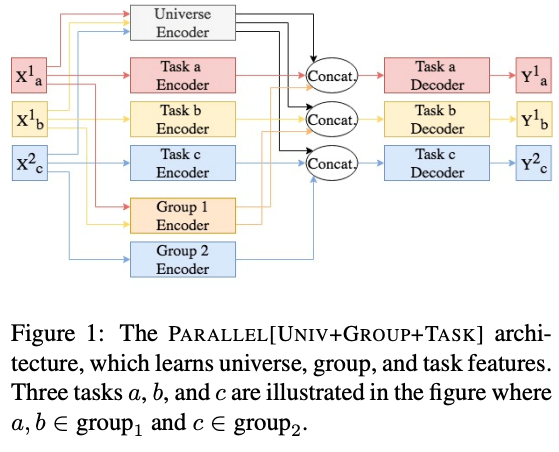
图 11
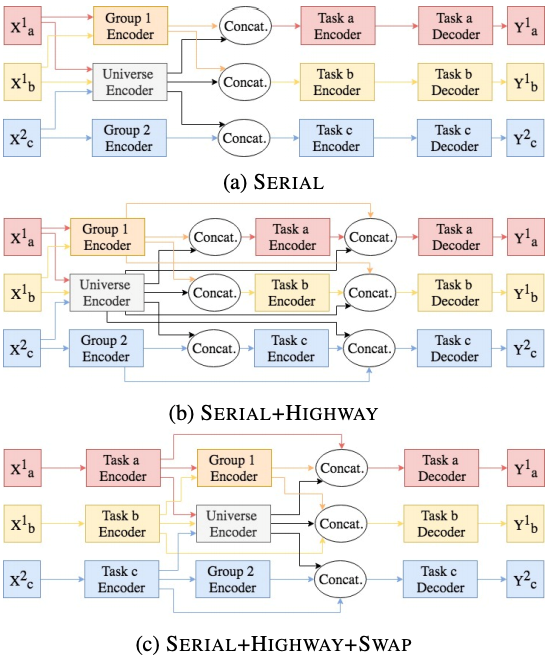
图 12
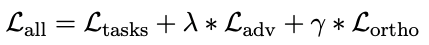
在模型的验证中,选取了意图分类(Intent classification)和填槽(slot filling) 这两个任务进行多任务训练。编解码框架用的是 Bilstm+CRF(如图 13 所示)。整体的损失函数定义为单个任务的损失函数的加权平均。实验用的数据集是 Alexa>
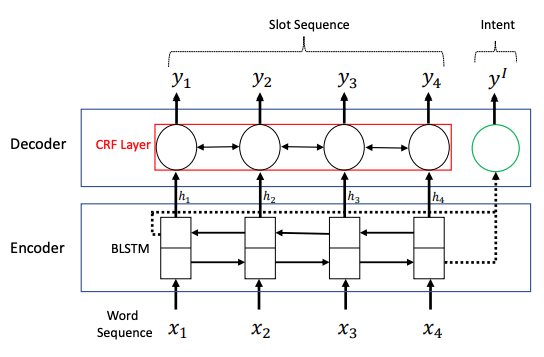
图 13
本文将对话系统和知识图谱(knowledge graph)结合起来了。在对话中,语句有时候会涉及到知识图谱中的实体,对话的交互还会涉及到知识点在图谱上的关系转移。如图 14 所示,对话双方在谈论书籍,对话内容涉及到从一本书的实体,跳转到文学流派,作者等等。本文的工作,集中在三个方面:
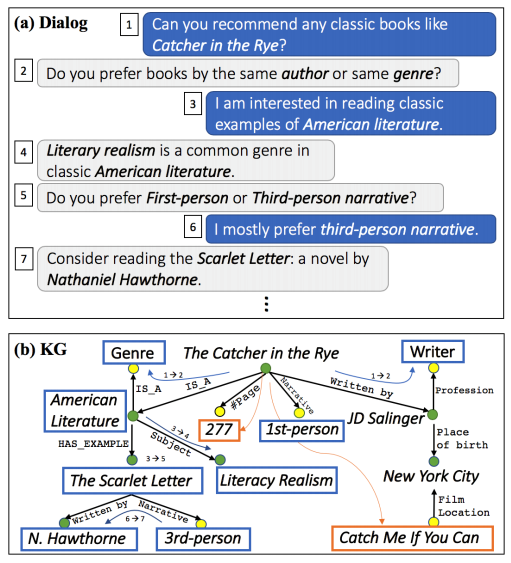
图 14
整体模型还是采用 Encoder-Decoder 的架构。其中,每一轮 Encoder 的输入,由当前轮次的语句中包含的实体,完整的对话语句,和之前轮次的所有语句组成:
最终这三类编码用 modality attention(Moon 2018a,b)合并到一起,modality attention 能依据候选者对任务的重要程度,选择性的缩小或者放大候选者的权重。整体的 Encoding 过程如图 15 的左边。解码部分的目标,是输出对应的知识图谱中的实体,由两部分损失函数,即下一轮生成正确实体的损失,和知识图谱上对应的推理路径的损失相加组成。
第一部分损失通过计算图谱中的 zeroshot 相关性来得到(Moon 2017),并用于最终实体的重排序。第二部分损失中面临的问题,是图谱中的推理路径数量巨大。本文用基于注意力机制的模型来对不会出现的路径进行剪枝。具体的剪枝过程,见图 16 的公式(6),其中 zt 就是注意力机制输出的上下文向量。路径损失也被拆分为所有实体的损失之和,加上关系的损失。
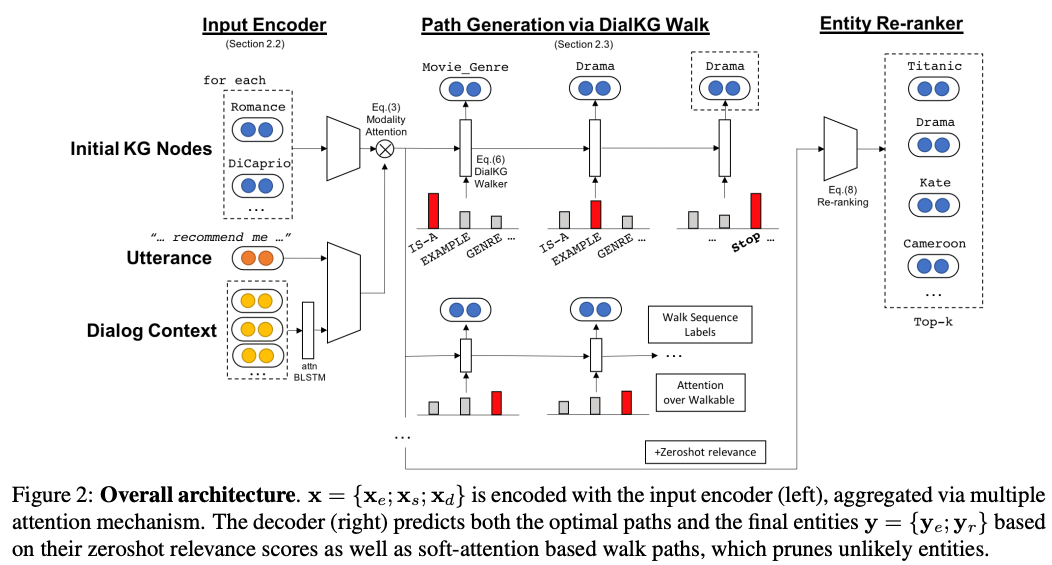
图 15
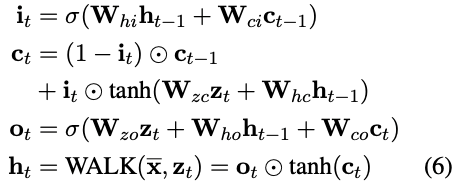
图 16
为了训练模型,本文还构建了一个 OpenDialKG 数据集。OpenDialKG 是在给定 topic 后,由对话中的两个人来完成,包括了 91K 的对话轮次。每个对话都会和它对应的知识图谱路径(这个路径包含实体,和对话中提及的实体间的关系)相关联。
数据集的生成过程主要依赖标注人员完成。实验对比了另外三种算法 seq2seq(Sutskever 2014),Tri-Lstm(Young 2018)和 Extended Enc-Dec(Parthasarathi 2018),在 R@N 上的提升都很明显。
对话状态跟踪 DST(Dialogue state tracking)是对话系统的核心部分,来抽取对话中的领域,意图和槽位信息。现有的 DST 面临的挑战,有如下几点:
本文针对 multi-domain 的 DST,提出了一个可迁移的对话状态生成器 Trade(transferable dialogue state generator)。如图 17 所示,模型由三部分组成:
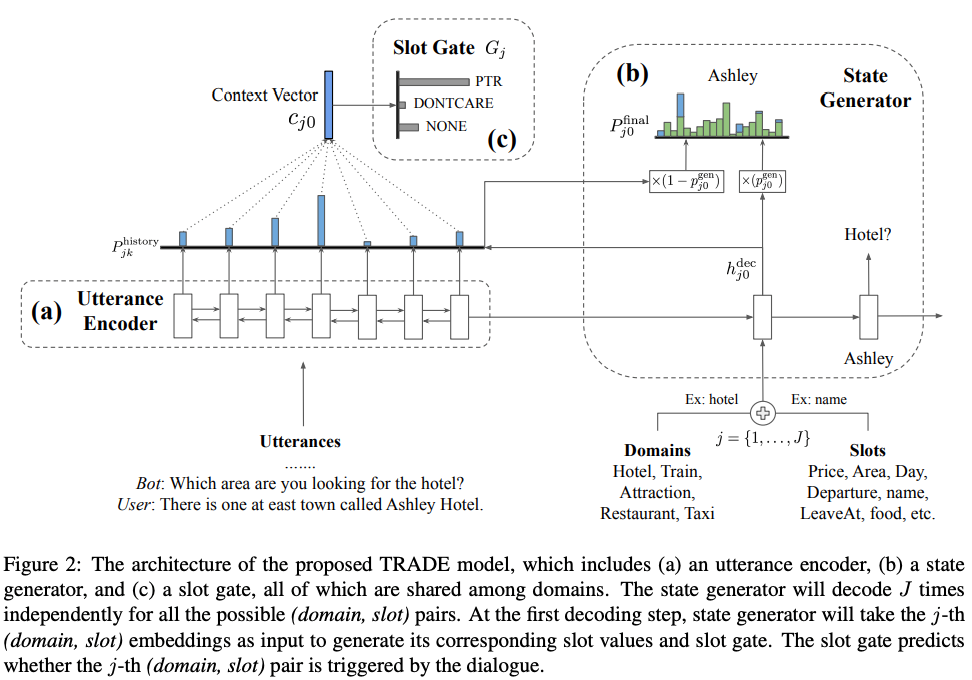
图 17
初始轮,输入的是 domain 和 slot 的 embedding 的加和;然后每一轮都会添加词,并生成中间隐藏状态 h,这个隐藏状态用来计算词典空间中的词的概率分布 P_vocab,以及对话历史中的 attention 值 P_history:
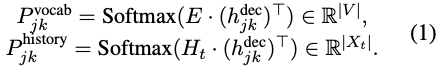
最终状态生成器输出是这两个 P 值的加权和。
最后的训练过程,优化的是对 State Generator 的输出,和 Slot Gate 输出的交叉熵损失。因为在训练过程中,Domain 和 Slot 的组合由训练数据决定,会有某个组合完全没出现的情况。
Trade 结构的架构,能同时去优化(domain,slot)所有组合的出现以及值的选择,因而会利用不同 domain 之间的共享信息,比如领域 train 和 taxi 都会有槽位 departure。这让 Trade 有一定的 zeroshot 或 few-shot 能力。
在实验中,对比了 MDBT(Ramadan 2018),GLAD(Zhong 2018),GCE(Nouri 2018),SpanPtr(Xu,2018),数据集用的是 Multi-domain Wizard-of-Oz(Budzianowski 2018)。Trade 的性能提升效果很显著,在多领域上提升达到了 20%,单领域的也有 8%。
新任务
这个 section 关注的,是对话系统的一些新的形式,比如引入对话外的额外信息,或者在某些特定领域,比如慈善或医疗领域的新模型和新应用。
本文解决的问题,和前面的差别很大:在生成对话回复中,除了考虑文本信息,还要考虑相关联的视频信息,称为 Video-Grounded Dialog System(VGDS)。VGDS 需要在给定的视频(包含图像和语音)的基础上,根据视频内容,视频标题,和已有的对话语句,来生成最合适的回复。图 18 是一个 VGDS 的例子。

图 18
这里的挑战,一是视频信息包含了多帧图像,因而语义信息不易抽取;二是对话引擎需要整合不同形式的信息特征。因而 RNN 在这个场景下不够有效。本文提出了 MTN(Multimodal Transformer Networks),来对视频编码,并整合不同形式的信息。MTN 包含三个部分:编码层,解码层,和一个自动编码层(Auto-Encoder Layer)。
视频编码在一个 n-video-frame 的滑动窗口内抽取视频特征,这个特征包括了图像和音频两部分。然后用一个 ReLU 激活层将特征的维度变为和文本的一样。编码层的结构如图 19 所示:
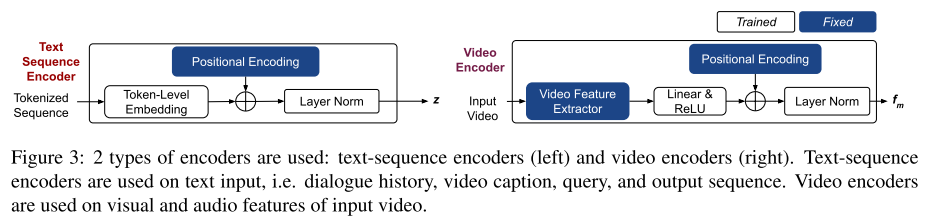
图 19
前向传输层由 ReLu 连接的两个线性变换组成。在每个 attention block 之间,还加入了残差连接(He 2016)和正则层(Ba 2016)。见图 20 中的 Decoder(D);
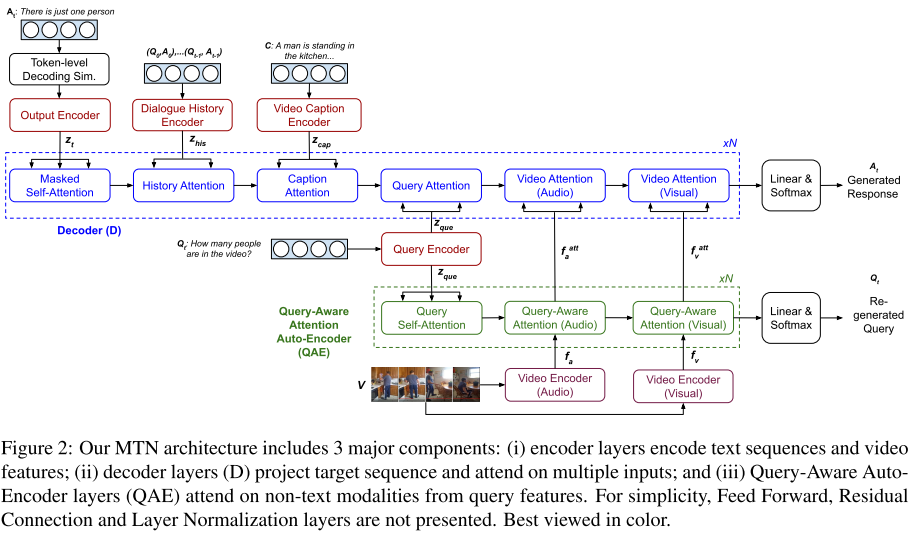
图 20
自动编码层也是由多层网络组成,每一次包含的 1+M 个子层,也就是上述的 query self-attention(1 个),加上和视频相关的 query-aware(M 个,这里 M=2)。
在训练过程中,损失函数定义为目标序列 T 的损失,和 QAE(自动编码层)的输出的损失之和。实验用的数据集合是 DSTC7(Yoshino 2018),包含了基于 Charades 视频(Sigurdsson 2016)的对话信息,并设置不同参数,训俩了 Base 和 Large 两个模型。在和相关模型的对比上(CorefNMN(Kottur 2018),MN(Das 2017a),HRE(Das 2017a),LF(Das 2017a),模型有了一定的提升。
本文讨论的,是如何在一个开放的对话聊天中,将对话引向一个特定的目标。如图 21 所示的例子:对话从闲聊的「Hi there, how are you doing」开始,对话引擎的目标是将对话引向「e-book」。
这个问题要明确的两点,一是如何对目标进行有效的定义,二是如何将引导的策略进行编码。本文通过定义粗粒度的词(比如:麦当劳,书籍,等)来对目标建模,并控制输出内容,然后通过设定规则,来接近最终的对话目标。
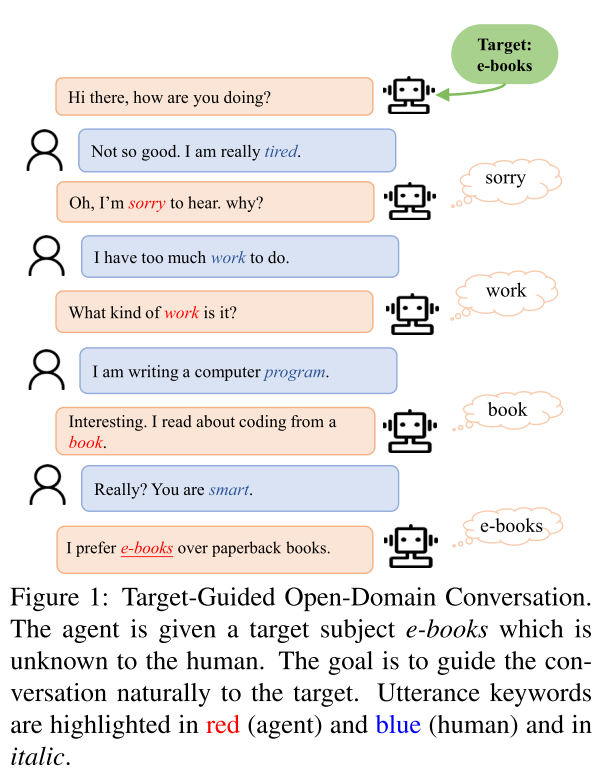
图 21
在对话的进行中,为了向目标进行引导,有两个要求:一是对话的状态迁移要平稳,这样的对话流程才会更自然,更可接受;二是目标的最终达成,这是为了避免追求对话的流畅迁移,而一直进行无意义的闲谈。这两个要求是相冲突的,更流畅的迁移可能会导致始终无法接近目标。本文提出了一个分治算法,来解决这两个问题。
系统包括三个核心模块:一个对话轮次级别(turn-level)的迁移预测器,来解决平稳迁移的问题;一个论述级别(discourse-level)的目标导向策略,来接近对话的目标;一个回复检索器,来生成合适的对话回复。架构如图 22 所示。
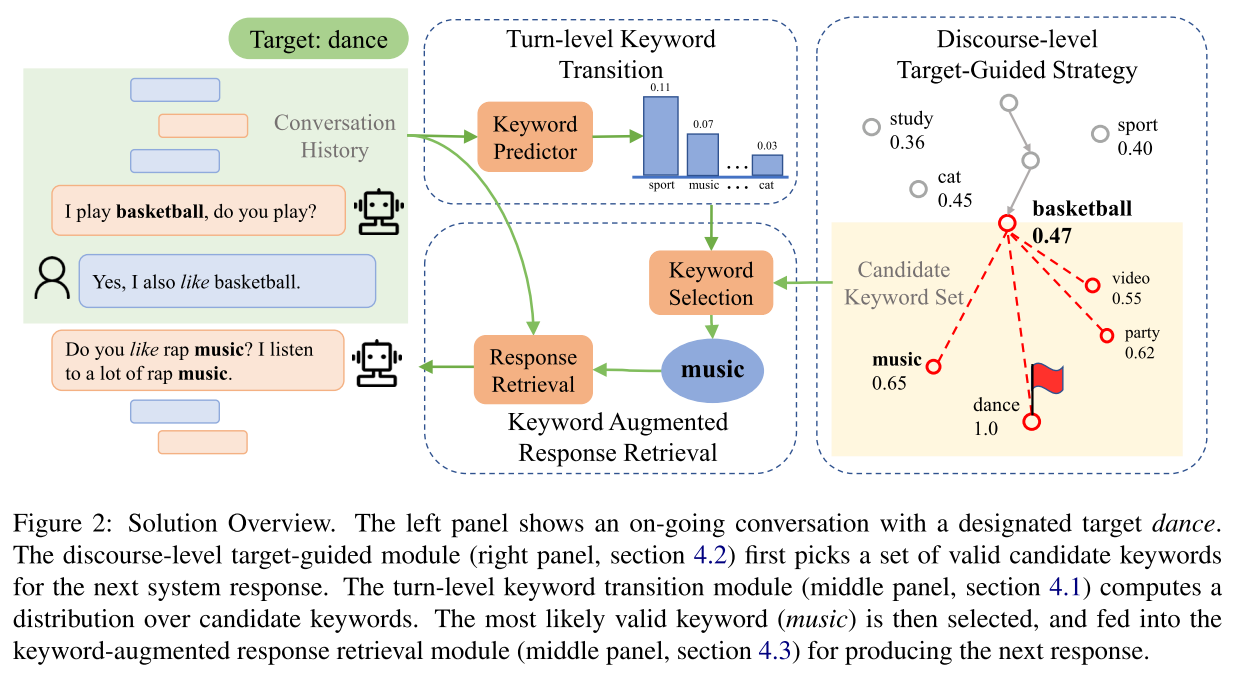
图 22
本文的实验是基于 PersonaChat 的数据集(Zhang 2018),并对数据先做了关键词的标注抽取。评测指标用了 R@N 和 MRR,本文对比了迁移预测中不同的预测方法对结果的影响,在绝大部分结果上,混合核方法效果最好。
本文的侧重点,其实不在模型方面,而是在数据集的收集整理方法上。解决的问题,是如何在对话中采用不同的劝说策略,来劝说人们对慈善机构进行捐助。采用的方法,是设计了一个数据采集的策略,并对数据中涉及到的劝说策略进行分析和分类。然后基于分类的结果,来训练一个分类器。数据收集的方法是本文的重点。作者先在 Amazon Mechanical Turk 平台上,设计了一个在线的任务。任务包括四个部分:
这个数据收集过程持续了 2 个月,获得了 1017 个对话,参与者有 1285 个人,其中 42% 的劝说者自己也进行了捐助,54% 的被劝者进行了捐助。
在获取了数据集后,还设计了一种标注方案(Krippendorff 2004)来对对话中的劝说者的语句进行劝说策略的标注,虽然被劝者的语句也进行了标注,但只是用于记录而已。标注方案先由 4 个研究助理在小数据集上验证其有效性,然后应用在全数据上。最终,标记出来的策略分为劝说呼吁(Persuasive appeal)和劝说询问(Persuasive inquiry)两大类:
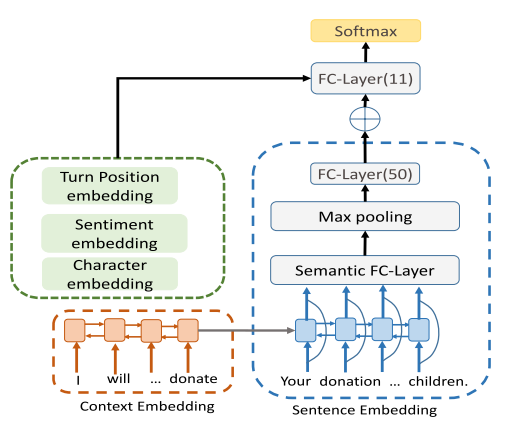
图 23
在对数据分完类后,用混合 Recurrent-CNN 来对对话进行分类,用到的 embedding 包括对话语句的 embedding,对话上下文的 embedding,轮次位置的 embedding,情感,和字符的 embedding。模型结构如图 23。在实验中,主要比较的是引入不同特征组合时,分类的准确率和 F1 值。
本文关注的,是通过数据集的优化,来提升开放式对话模型的效果。基于神经网络的对话模型,在开放式对话中,容易产生通用的回复,缺乏多样性。因而,本文通过剔除掉具有高熵值的对话语句,来修正数据集,进而提升对话系统的性能。
一个高熵值的例子,如「what did you do today」,这个问句的答案会有很多种回复;而「what is the color of sky」的熵值就比较低,因为回复很明确。其中,计算熵值的时候,对对话中的 source 和 target 做了区分(source 表示对话的发起方,target 为应答方)。在给定数据集 D 时,Target 和 source 的熵值的定义如下:
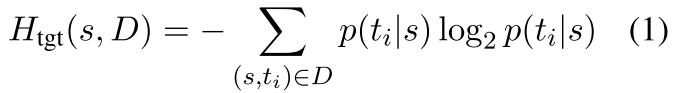
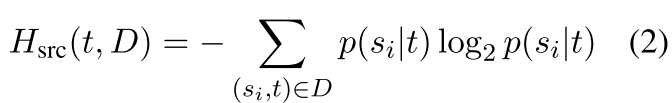
另外,先对语句聚类,也会对实验效果有影响。聚类能反映出问句的回答是否是语义上的多样。比如「how old are you」,虽然答案也会有很多种,但语义上都是接近的。一个句子可能有低熵值,但是如果组成的 cluster 有高熵值,这个 cluster 也会从数据集中删除掉。一个 source cluster 的目标熵值定义如下:
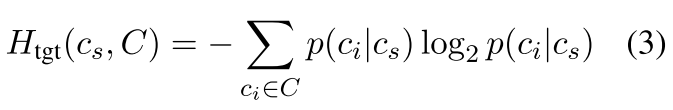
其中 C 是所有的 cluster。在删除 cluster 时,高熵的 source cluster 和 target cluster 都会被删掉。
聚类的方法,可以用 Mean shift algorithm(Fukunaga 1975),或者 sent2vec(),即句向量的方法。
在实验中,对话模型用了 Transformer 的 encoder-decoder 架构,测试了在数据集 DailyDialog,Cornell,Twitter 上的熵值分布情况,并测试了不同的聚类算法对结果的影响。
本文主要是针对心理治疗领域,提出了两个分类模型,在治疗师和患者的对话中帮助治疗师。本文的模型,没有去生成对话的回复,而是对已有的当前轮次的语句,和接下来可能出现的语句的标签进行分类和预测。研究是基于 Motivational Interviewing(MI,Miller 2012)进行,对话的语句由 Motivational Interviewing Skill Codes(MISC,Miller 2003)来标注。一个标注的例子如图 24 所示。
任务的定义如下:输入包括 MI 上的对话的语句 u,对话历史 H,每个语句对应的人 s,以及语句对应的 MISC 标签 l。模型需要提供两个实时的输出,包括:
分类:对对话中的最后一个语句 u_n 进行分类;
预测:给定了 n 轮的对话,和第 n+1 轮的人,来预测还没发生的第 n+1 轮的语句的分类标签。
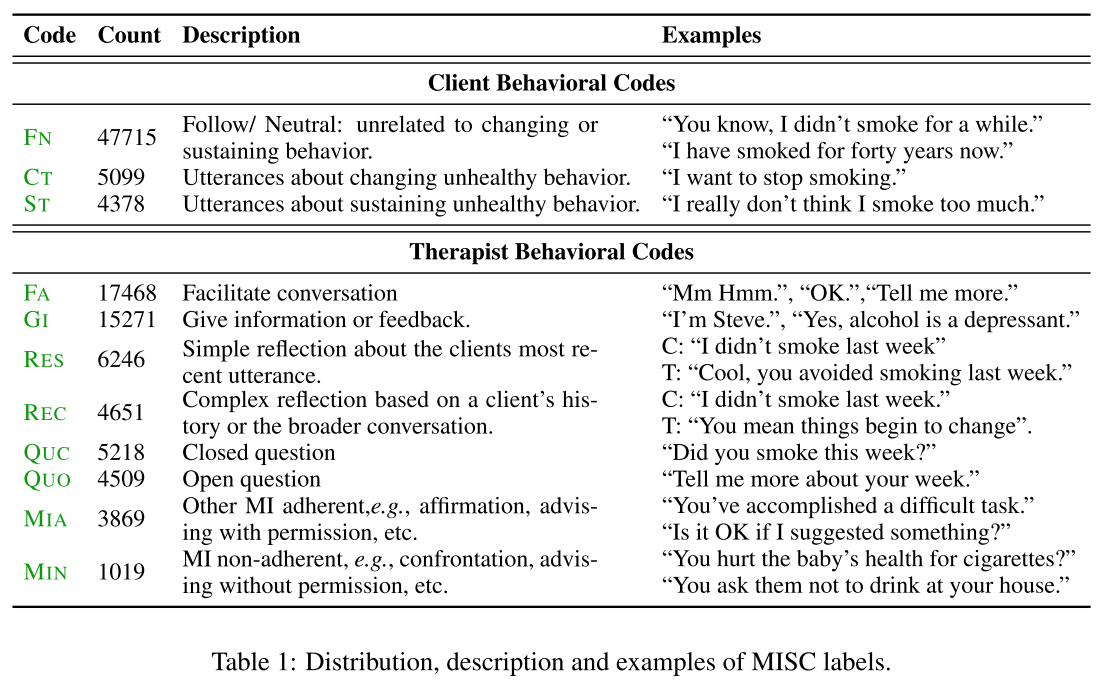
图 24
在构建的模型中,用层次 GRU 来对对话级别进行编码,用词级别的 attention 来抽取语句中比较关键的词信息,用 multi-head attention 来抽取语句级别的对分类结果比较重要的语句。另外,在数据中存在标签不平衡的问题,本文还设定了一个平衡权重α,和 focal loss(Lin 2017)函数来解决数据不平衡问题,如下面的公式表示:
实验中,先用 MISC 对所有的数据进行标注,并对比了不同的模型配置在分类和预测这两个任务上的效果,在分类任务上能提升约 6%,在预测任务上提升约 4% 左右。
参考文献:
作者简介
Will Li,中国科学院计算所博士,前微软资深工程师,目前在 Udesk AI Lab 任算法专家,负责智能客服系统相关技术的研究和开发。