导读 :随着科学技术的飞速发展,互联网被广泛应用于各个领域,而以互联网为基础的招聘模式也越来越受到企业的青睐。互联网招聘具有不受地域限制、覆盖面广、招聘成本低、针对性强、方便快捷、时效性强等优点,现已得到广泛应用,其中,58 招聘是互联网招聘行业中规模最大的平台。今天主要跟大家分享下 58 招聘如何通过个性化推荐技术服务大规模求职者和招聘企业。分享题目是 从零到一构建 58 招聘个性化推荐 ,主要通过以下三方面进行介绍:
——招聘业务介绍——
1. 58 招聘业务简介
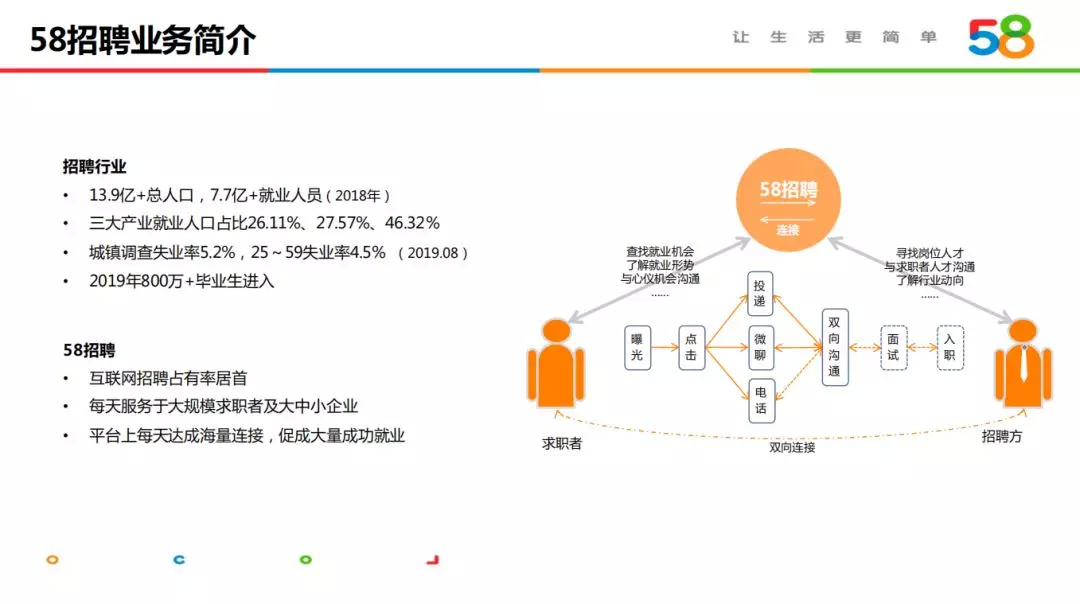
2018 年我国全国总人口 13.9 亿多,其中就业人口 7.7 亿,招聘基数庞大。三大产业就业人口占比分别 26.11%,27.57%,46.32%,其中第三大产业占比最大,部分发达国家第三大产业占比已达到 70%~80%,随着经济的发展,我国未来就业市场和就业分布将发生大的变化。2019 年 8 月城镇调查显示我国失业率为 5.2%,其中 25~59 岁失业率 4.5%,同时每年有 800 多万的应届生加入就职市场。58 招聘作为我国互联网招聘行业之首,每天服务于千万级求职者和大中小企业,平台每天生成千万级连接,促成大量求职者求职成功。
58 招聘平台主要服务于求职者和招聘方,接下来主要通过求职者的角度介绍用户在整个平台流转的大致流程,具体如下:
相比传统推荐系统,58 招聘的业务漏斗更长更深,并且有一部分转化平台无法完全捕捉,形成了 58 招聘个性化推荐开展的难点及挑战。
2. 58 招聘推荐场景类型
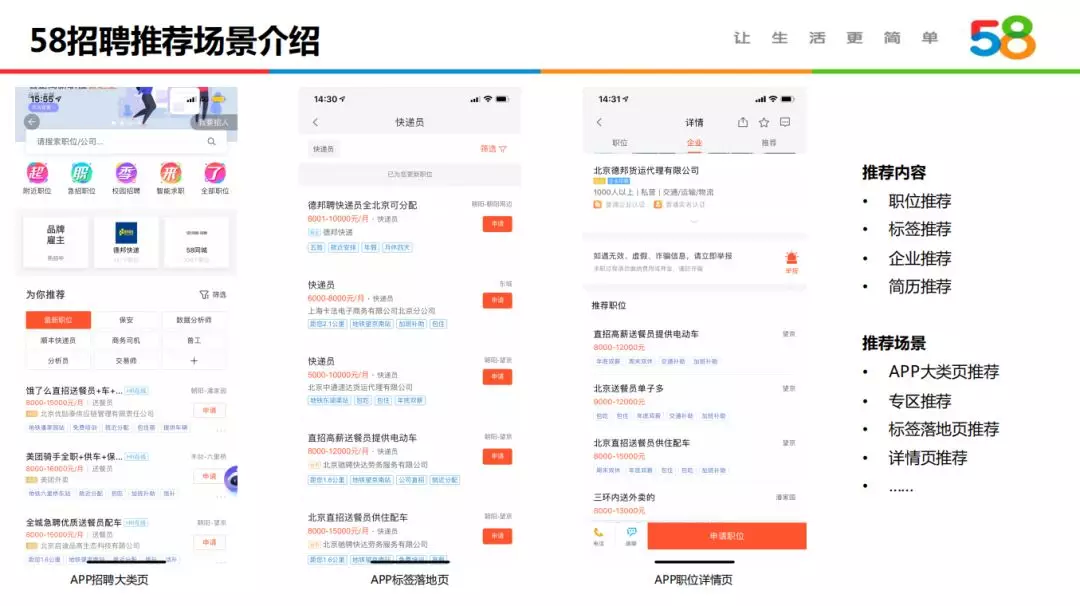
58 招聘推荐场景主要面向 C 端求职者和 B 端企业,推荐内容主要包括:职位推荐、标签推荐、企业推荐、简历推荐。
C 端求职者的典型推荐场景包括:
3. 58 招聘推荐主要问题
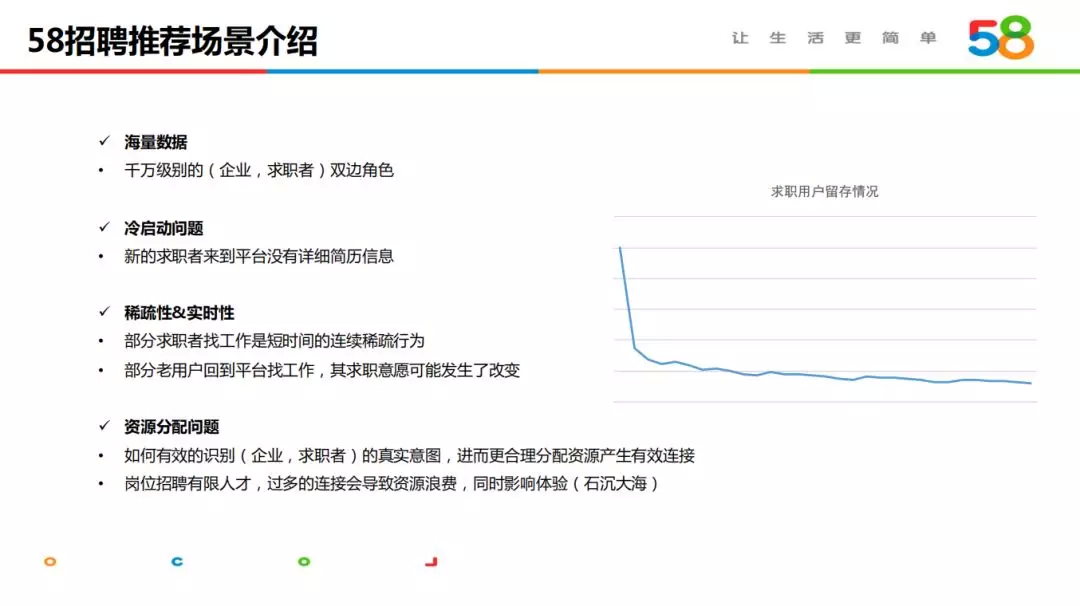
58 招聘推荐相对其它行业主要存在以下典型问题:
——招聘个性化推荐实现——
1. 58 招聘个性化推荐实现
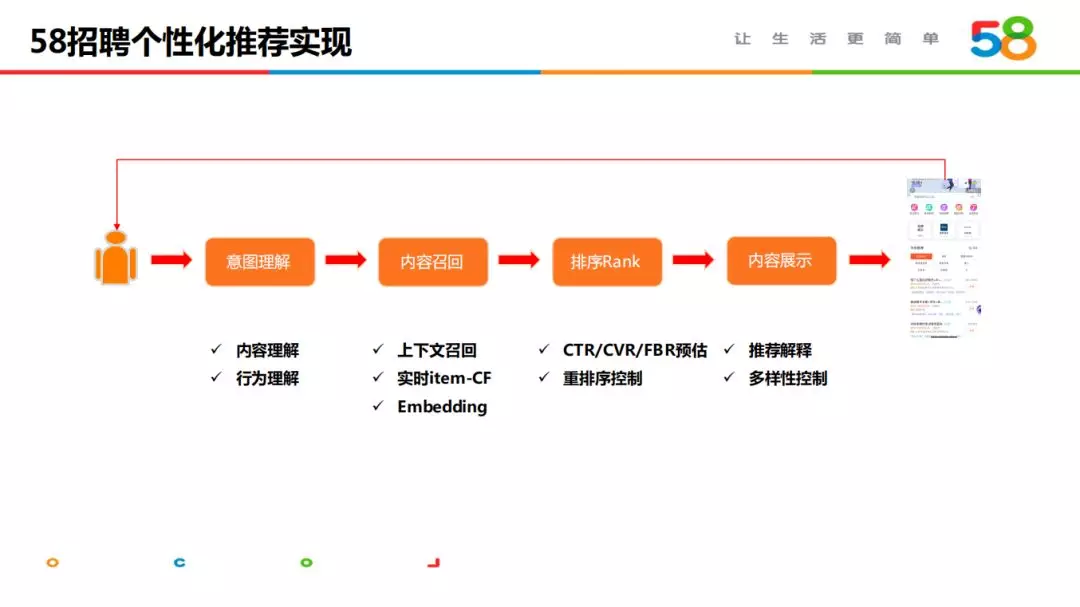
58 招聘个性化推荐的实现过程与大多数公司推荐模块基本相似,包括用户意图理解、内容召回、内容排序、内容展示四个核心模块。下面将结合业务特性,介绍每个模块实现的关键点。
2. 如何理解用户?
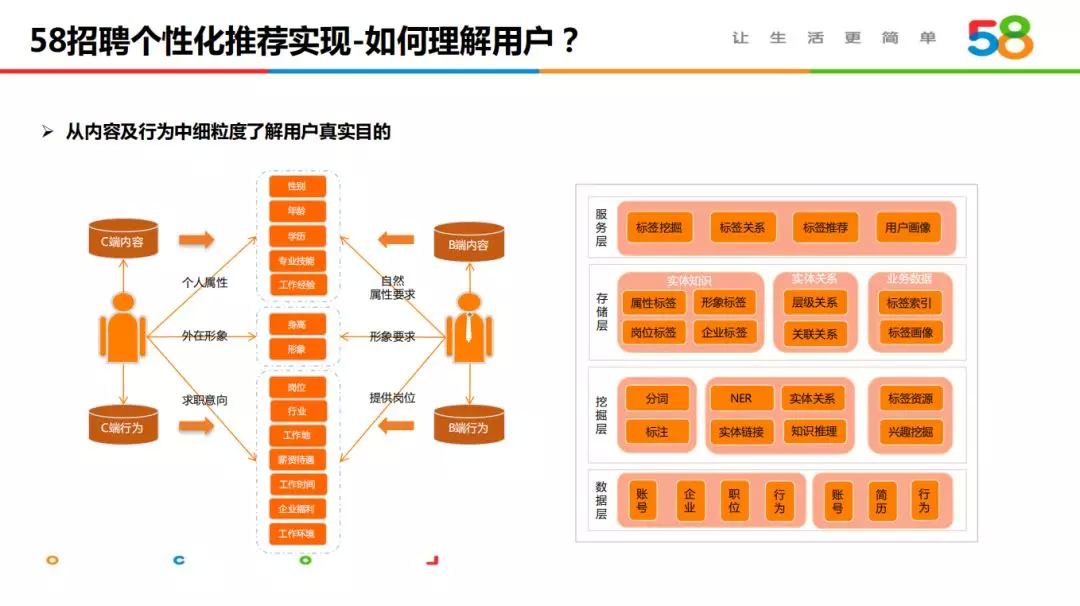
58 招聘用户理解主要通过“言”和“行”识别用户真实意图,重点关注的属性主要包括招聘领域求职意向、用户个人属性以及外在形象(如上图左边)。围绕求职者与招聘方在平台产生的内容及行为,我们构建了相应的知识图谱和用户画像。
2.1 无诚意用户识别

在理解用户之前,我们首先需要识别出无真实招聘/求职意图的用户,并进行差异对待。如频繁发布包含联系方式的导流信息、发布高薪诱惑等恶意虚假信息等,将用户引导至平台外进行转化。针对以上业务我们总结了一些特点,主要表现为:
针对以上业务特点,我们主要的识别方法包括:
在无诚意用户识别过程中,我们总结了以下心得:
2.2 知识图谱构建
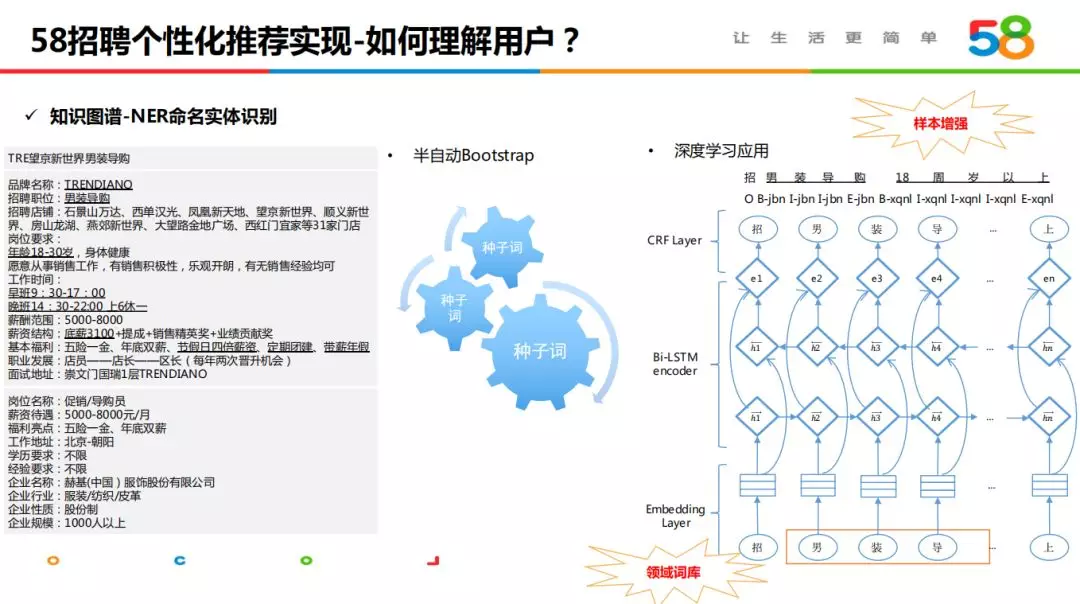
知识图谱是一个非常复杂的系统,包括多元异构数据搜集->知识获取->知识融合表示->知识推理->知识管理多个部分,主题及时间因素,我们重点介绍下在 NER 方面的探索。招聘业务场景含有大量的文本内容,通过 NER 技术能够有效提取文本中的关键信息,进一步提高系统的结构化理解能力。
NER 开展经历了两个阶段:
2.3 构建用户画像
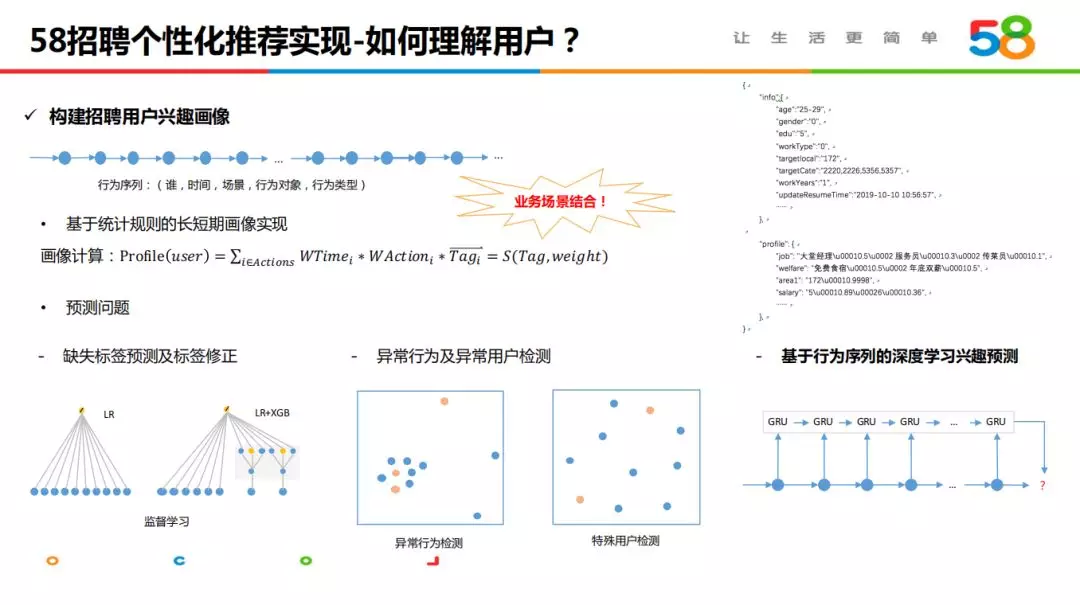
用户画像是个性化推荐系统的基础模块,决定了对用户意图理解的准确与否。基于标签传递思想,我们通过统计规则、传统分类模型和深度模型多种算法结合捕获用户行为的兴趣表达,构建长短期用户画像。
3. 召回模块
58 招聘推荐围绕个体、群体、全局三个召回不断细化演进,不同召回满足不同需要,三者结合服务于各类场景。从 2016 年到现在,我们先后主要经历了基于上下文内容、协同过滤、精细画像、深度召回几个阶段,演变成当前以上下文与用户画像结合的精准召回、协同过滤召回及深度向量化召回为核心策略的召回模块。
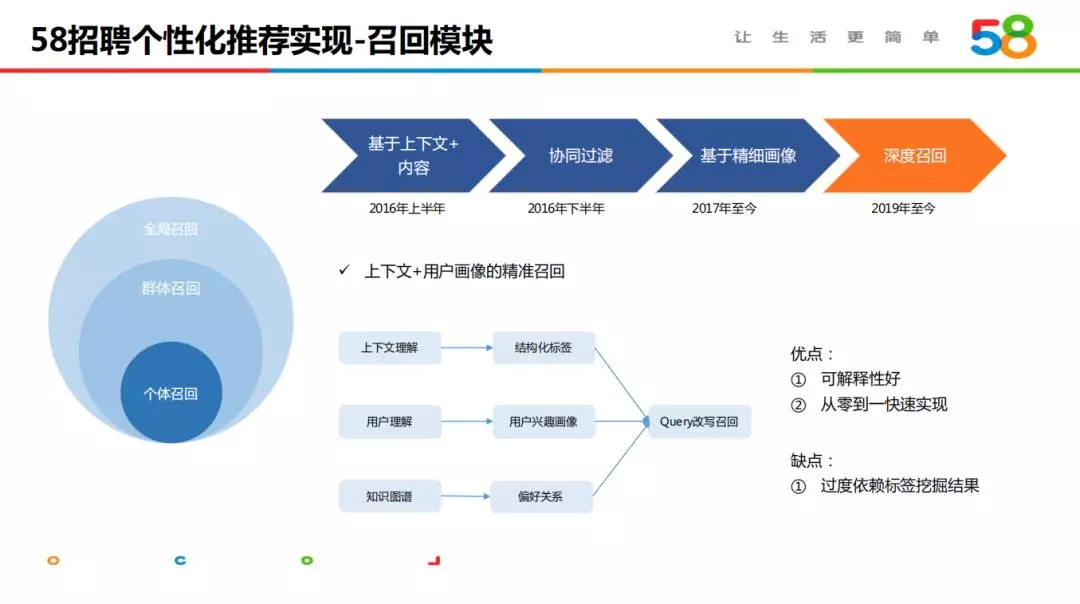
3.1 基于上下文+用户画像的精准召回
该策略是业内十分常用的召回方法之一,核心在于结合用户画像对请求进行丰富改写。绝大部分场景,用户主动搜索或点选的条件有限,借助用户画像中的历史兴趣及知识图谱组织的实体关系,我们对岗位、工作地、薪资、行业等多个维度进行条件扩充或必要改写,多路召回匹配用户的职位内容。
该策略的主要优点:可解释性好、实现时间成本低,缺点和难点是过度依赖标签挖掘的准确性。
3.2 基于业务特殊性的协同过滤算法改进
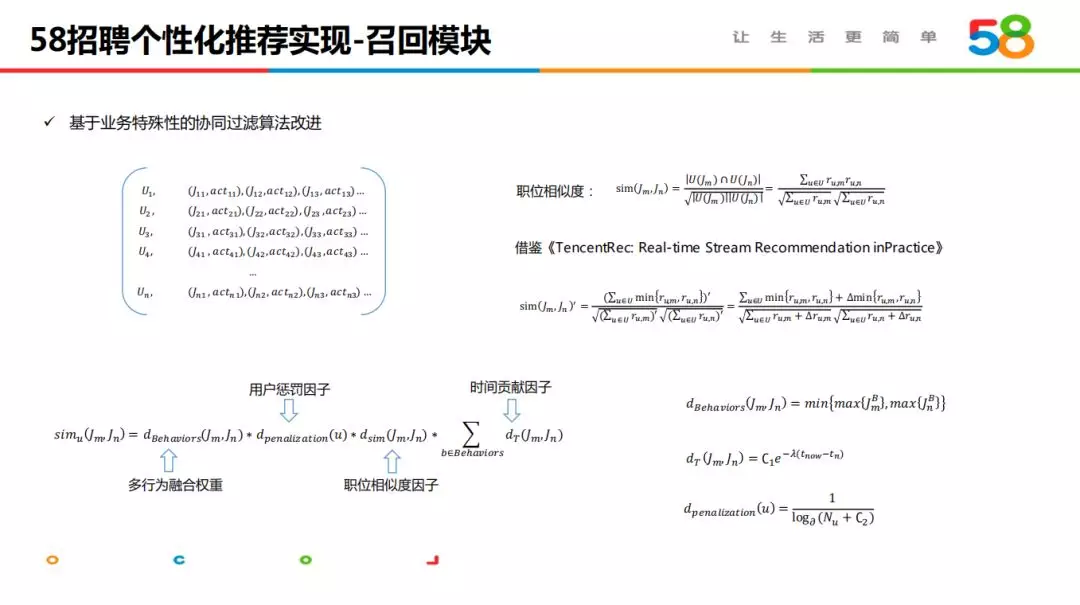
协同过滤是推荐系统经典的召回方法,通过用户与物品的行为挖掘用户与用户、物品与物品之间的关联关系。招聘业务的求职者数量巨大,且是短时间的稀疏行为场景,我们采用基于物品的协同过滤,同时希望能近实时的将实时行为信息组织进服务。
在技术实现过程中,我们参考了腾讯 2015 年发表的 Paper《TencentRec: Real-time Stream Recommendation in Practice》,赋予职位点击、投递、在线沟通等不同的行为权重进行多行为融合,基于用户行为序列的长度以及用户质量设计用户惩罚因子,同时通过时间衰减因子增强近期行为的表达,这三个因子的设计与 Paper 基本一致。另外针对业务特殊性,我们改进了职位相似度的计算,加入了职位相似度控制,避免求职目标发散的用户影响职位关系的组织。算法上线后,在点击率、投递率方面都取得了正向收益,其中详情页的相关职位推荐提升超过 25%。
3.3 Embedding 深度召回探索
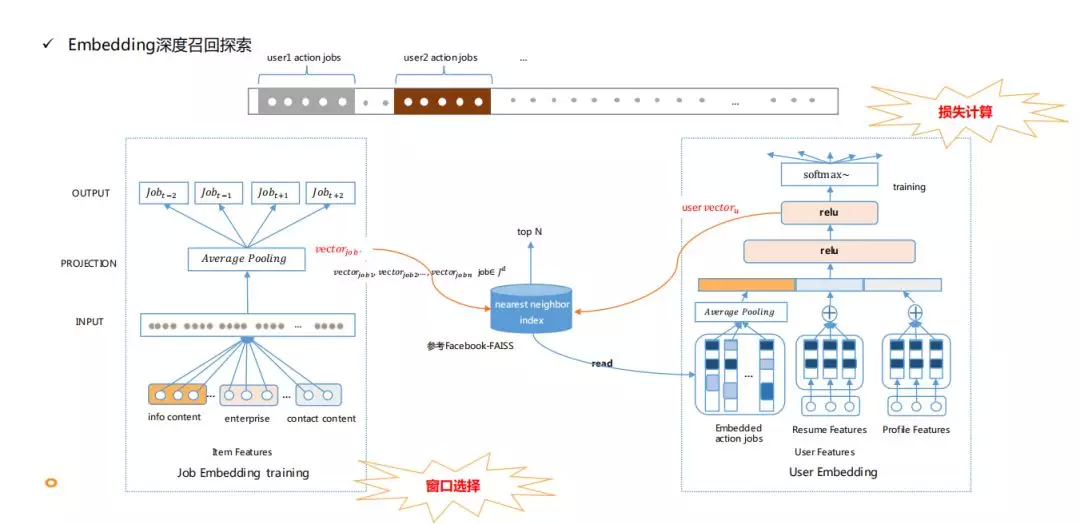
协同过滤虽然取得了不错的业务收益,但其依赖于用户与物品的行为矩阵,对于行为稀疏的场景天然表达有限。而恰好,58 招聘业务的流量构成中,有一部分是三四五线城市,城市越下沉数据稀疏的情况也越凸显。针对这类问题,我们希望进一步挖掘行为数据的信息,很自然的想到基于深度学习的向量化 Embedding 召回。我们核心参考了 Youtube 的 DNN 召回思想,基于业务现状做了调整优化。
Embedding 向量化召回,还处于初期探索,仍需要在样本、输入特征及网络参数调优开展大量工作,期待有更显著的业务收益进一步与大家分享。
4. 排序迭代历史
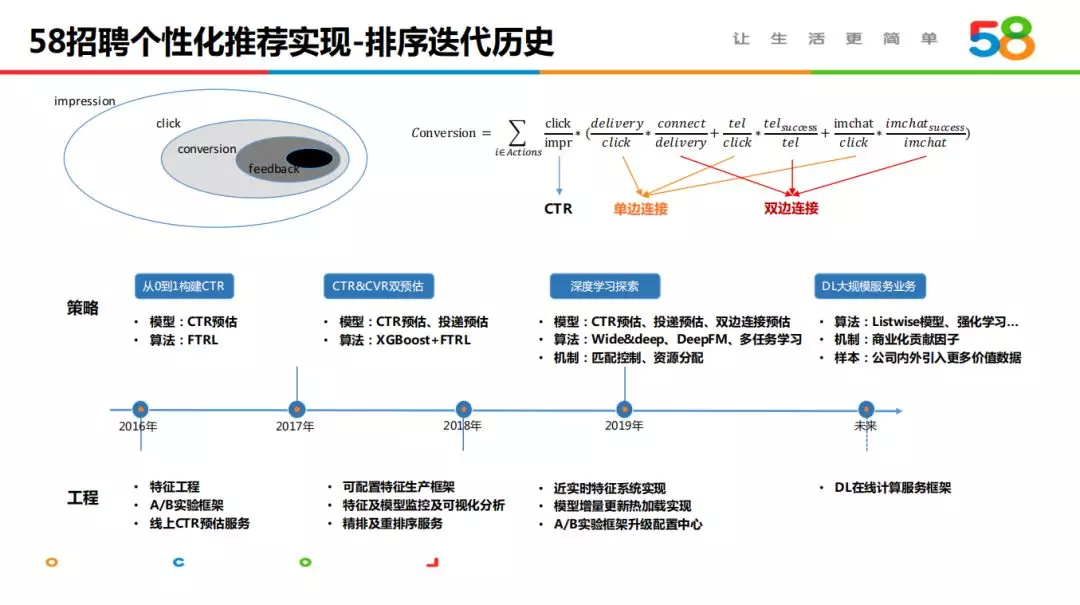
相比其他推荐场景,58 招聘的漏斗更深,并且是典型的双边业务。系统不断优化提升求职者点击、投递职位的同时,还需要关注职位背后的招聘方是否反馈形成了有效双边连接,进而达到更接近求职链条的预测目的。结合不同时期的业务目标,我们先后经历了几个主要阶段。
第一阶段:以提升点击规模为主要目标,从零到一构建点击率预估模型,开发模型建设的基本框架,包括特征工程、AB 实验框架及线上 CTR 服务。该阶段在较少人员的情况下,建立了排序模型及服务的大体框架,在点击层面支撑业务增长。
第二阶段:业务目标深入,从点击过度到单边连接直至双边连接,在 CTR 预估模型的基础上,增加了 CVR 预估及 ROR 双边连接预估。同时在工具上开展了针对性建设,包括特征生产 Pipeline、AB 实验框架升级为可配置化中心及特征模型的可视化分析监控等,解耦算法和工程依赖,支持更多算法和工程人员的并行高效迭代。
第三阶段:围绕深度学习的算法探索,wide&deep、DeepFM、多任务学习、强化学习等,不断提升算法对高维特征的表达能力,提高预估模型的刻画能力。预计在 2020 年全面落地业务,达到更为理想的迭代状态。
4.1 连接转化预估模型
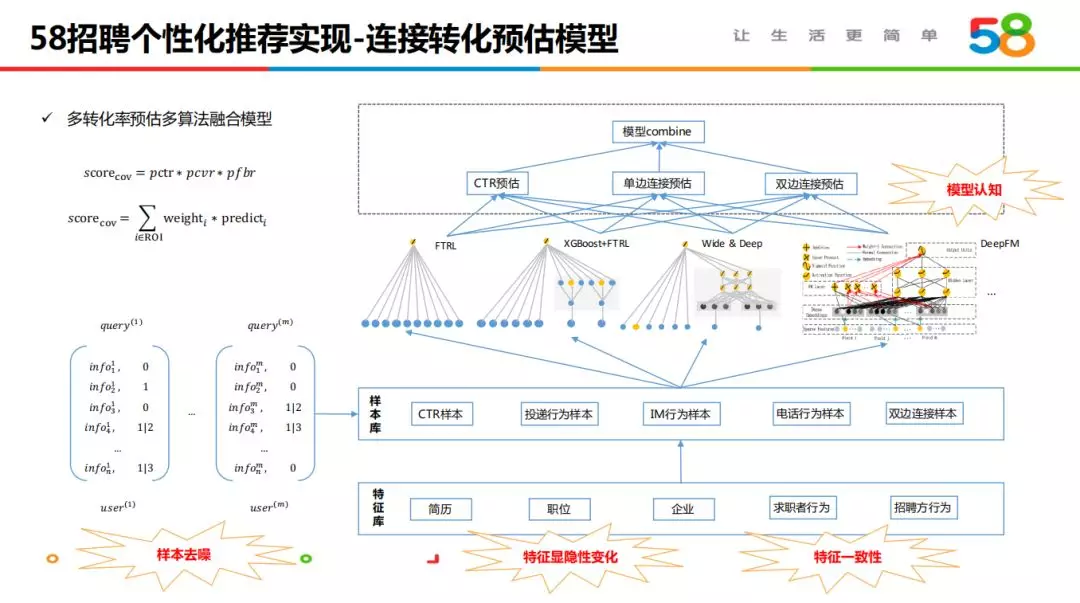
58 招聘转化预估模型是多目标学习,设计实现如上图,底层共建样本及特征,使用不同算法对 CTR 点击率预估、CVR 单边连接预估、ROR 双边连接预估进行建模,最后对多个模型进行融合支撑线上排序。
整体排序实现是业务常见的方法,总结开展过程中比较关键的点:
4.2 特征生产实现
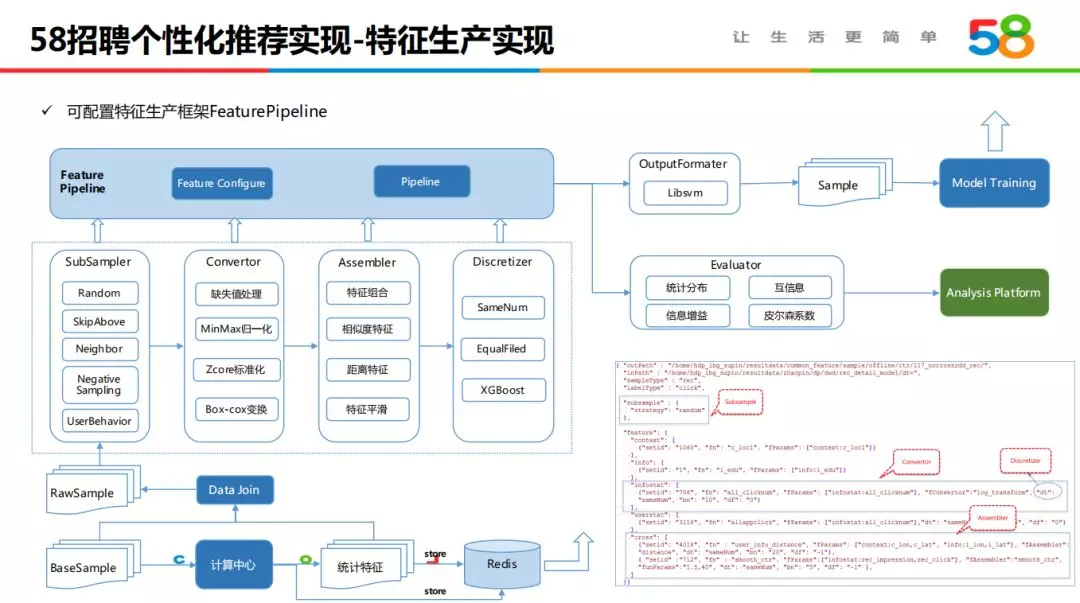
特征 Pipeline 的构建,减少了大量特征工程重复工作,显著提高模型迭代效率。其核心功能是实现配置化的方式,集成了样本采样、特征变换、特征组合、特征离散化,整合后得到训练样本,一方面输送给模型进行训练评估,另一方面也输出到分析平台支持可视化分析。
4.3 模型 serving 实现
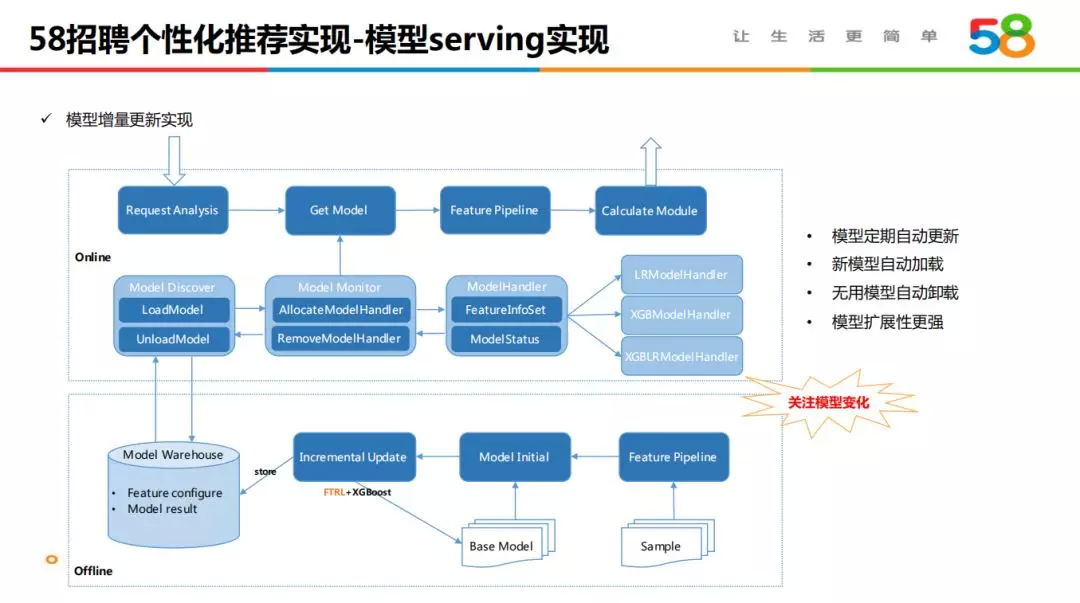
线上模型服务有定期更新及大量 AB 实验的要求,随着服务演进构建了当前的模型 Serving 框架,实现了对模型的定期自动更新以及模型的自动加卸载功能,同时也具备了更强的扩展性,可接入不同算法的模型实现。离线部分,样本经过特征 Pipeline 构建增量训练数据,模型训练模块会获取 Base 模型文件初始化并进行增量模型训练,模型评估无异常,系统会将模型存储至模型仓库及 HDFS 文件。线上部分,模型仓库增删改模型后,会发起模型热加载或卸载指令更新至线上服务内存;对于线上的排序请求,实时修改相应使用模型的存储生命周期,对于长期无用的模型,模型仓库将自动删除。
模型 Serving 能够自动化管理线上模型,但我们也不能完全托管系统,依然需要关注模型变化。一方面在离线部分的模型评估环节,除了对 AUC 等评估指标的自动监测,也将模型内存大小、模型特征表达作为监测的一部分;另一方面线上监测业务转化指标的变化,当指标发生较大波动时发出警报,人工进行模型检查。
4.4 重排序机制

由于业务的特殊性,以 CTR 预估、CVR 单边连接预估、ROR 双边连接预估支撑排序仍然存在刻画能力不足的问题,体现在以下几个方面:
针对这些需要,系统增加了重排序机制,通过分段处理手段,在粗排阶段打压甚至过滤掉低质量内容,在重排序对不活跃/不匹配内容进行降权,达到保障平台质量生态、提高有效连接规模的目的。
5. 列表展示内容控制
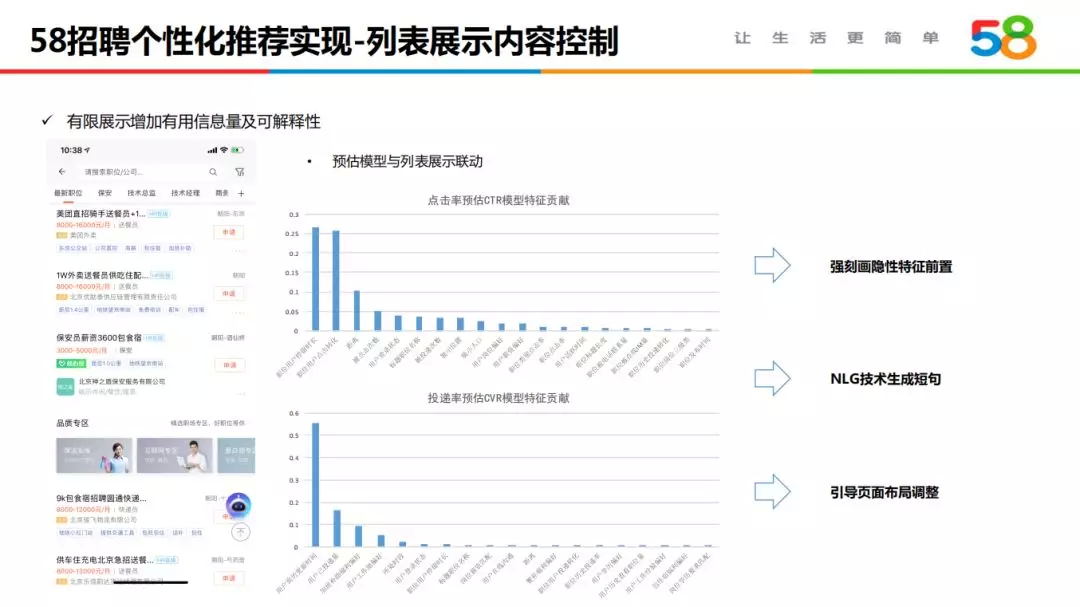
内容展示方面,我们也结合算法做了一些工作,来提高内容的可解释性、提供更多有价值的信息来辅助用户决策。结合个性化模型挖掘亮点标签,将更深预估模型的核心特征包装成标签形式展示在列表页,如距离多远、职位的福利标签、职位的热门情况等;使用 NLG 文本生成技术,自动生成简短描述进行展示,弥补标题及其简单职位的文本信息不足。
6. AB 实验配置中心
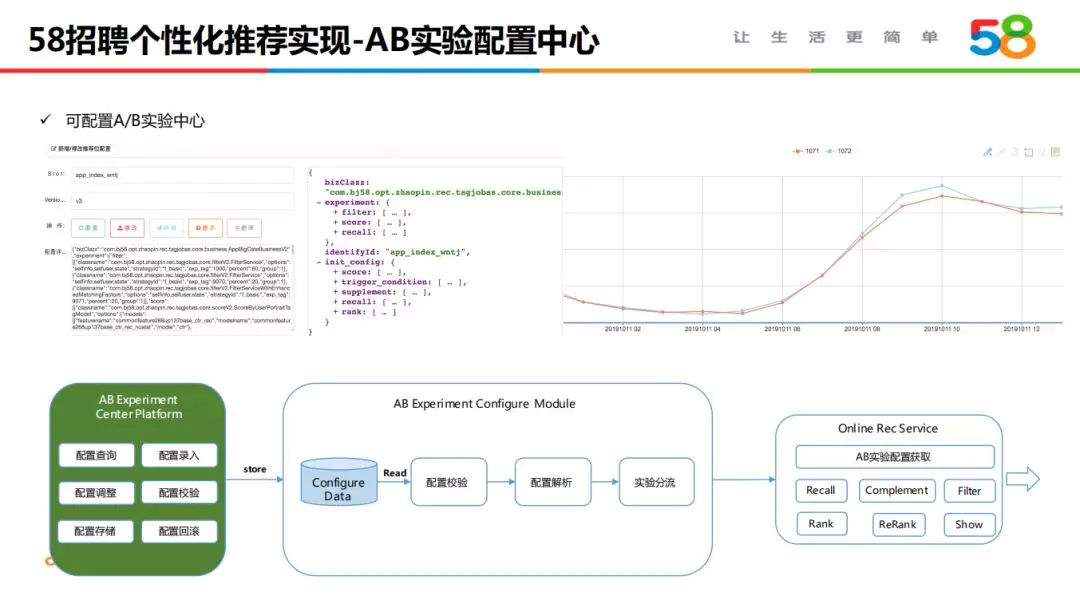
推荐系统包括召回、过滤、排序、展示几个核心模块,且每个模块都有长期进行实验迭代的诉求。我们搭建了 AB 实验配置中心,实现可视化配置,与线上服务及数据分析平台联动,更灵活高效地开展实验迭代工作。
7. 整体技术框架
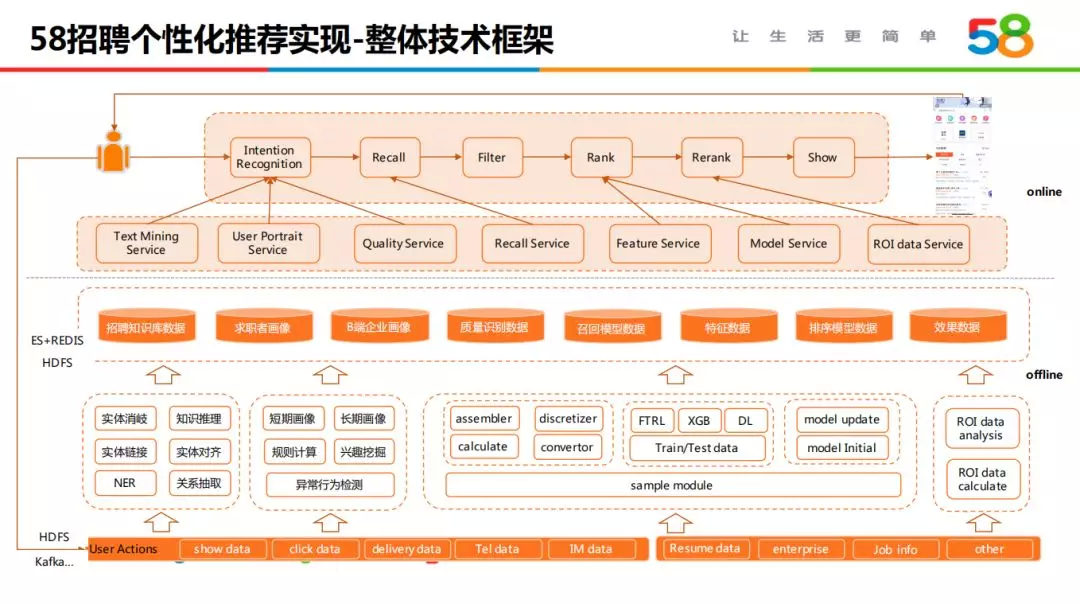
58 招聘个性化推荐经过不断演进,最终形成了如上图的技术框架。离线部分包含数据仓库层,知识图谱、用户画像、预测模型的挖掘层,知识数据存储层;线上部分包含数据服务及推荐引擎。线上产生的行为数据,实时流转至离线的计算挖掘模块,反馈到线上达到个性化体验效果。
——心得分享及规划——
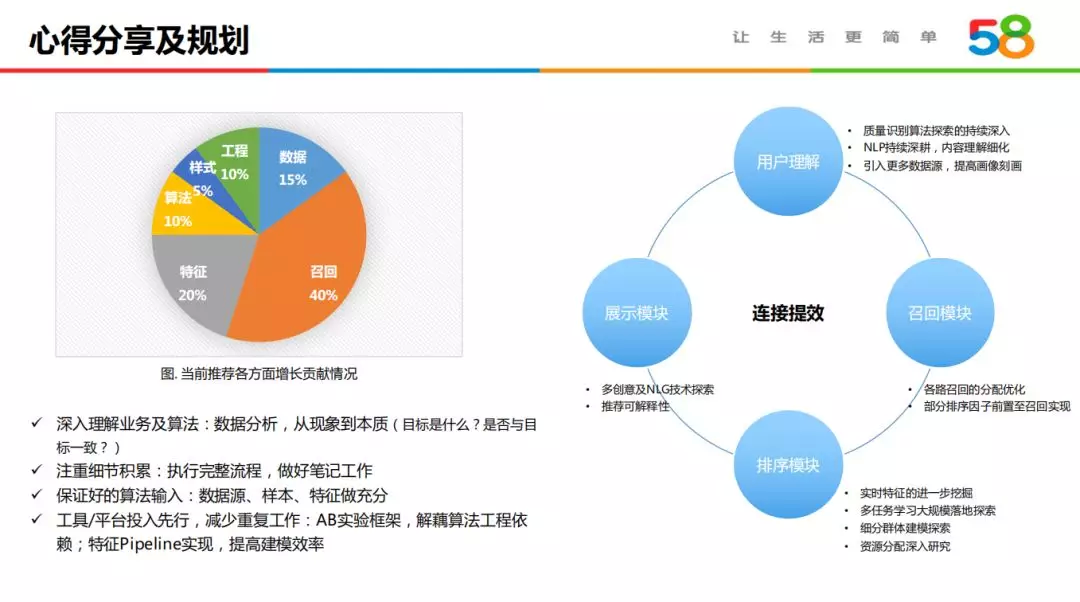
58 招聘推荐系统最近四年优化收益整理如上图,贡献大小依次是召回、特征、数据、算法、样式、工程。深入理解业务及算法、注重细节积累是做好算法工作的保证;前期在样本及特征上多下功夫,不仅能获得不错的业务增长,也是之后算法深入的基础;工具性建设尽可能先行,能够提高整体迭代效率。
未来的核心工作:
作者介绍 :
曾钦榜
58 同城 | 高级技术经理
本文来自>
原文链接 :