我主要和大家分享网易游戏在规模化 TiDB SaaS 服务运维以及处理高并发业务方面的实践经验。我的介绍将围绕三个核心方面展开:
数据库现状
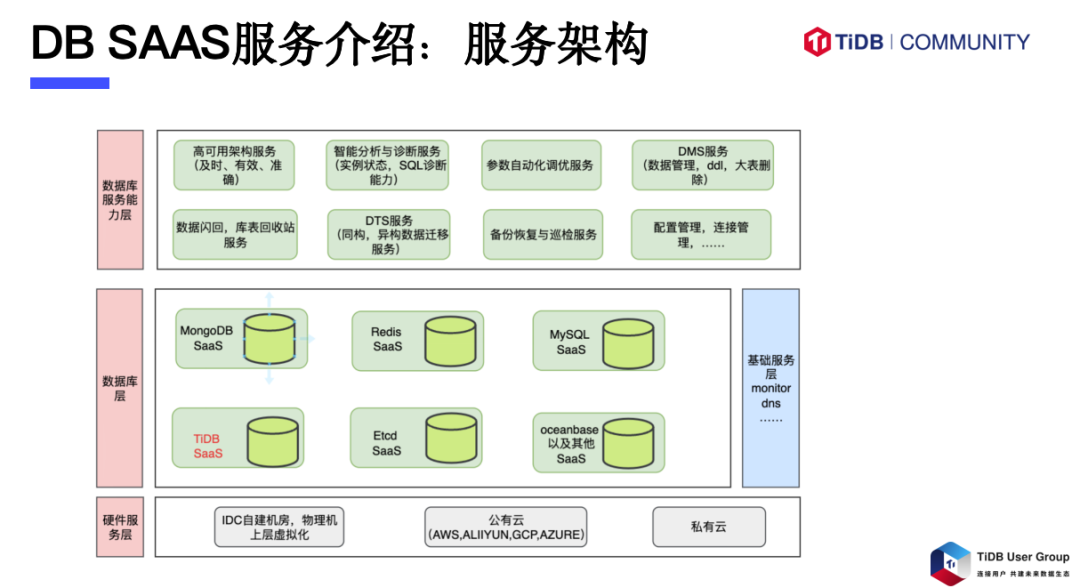
我们为网易游戏及其周边服务提供一站式数据库管控服务:
TiDB 在网易游戏的使用场景

TiDB 在网易游戏的应用场景非常广泛和复杂。包括基础架构服务、云存储、内部管理和质量治理等 OLTP 场景;以及上游是 MySQL,下游 TiDB 作为读扩展的业务场景;重 OLAP 场景下的业务,比如使用 TiSpark 直接请求 PD 进行报表统计计算;利用 TiDB 的横向扩展能力, 进行数据归档。
TiDB SaaS 平台服务介绍
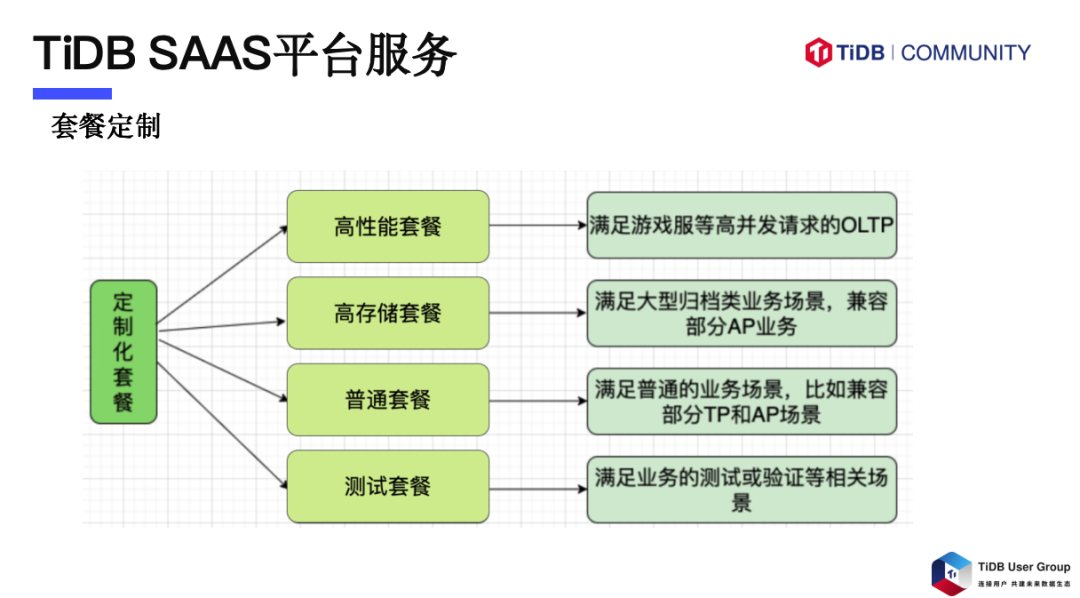
套餐定制
针对多样化的业务场景,我们提供定制化的服务套餐,以满足不同计算和存储需求。我们的 SaaS 服务根据具体的业务需求,设计了多种专属套餐。
虚拟化与资源隔离
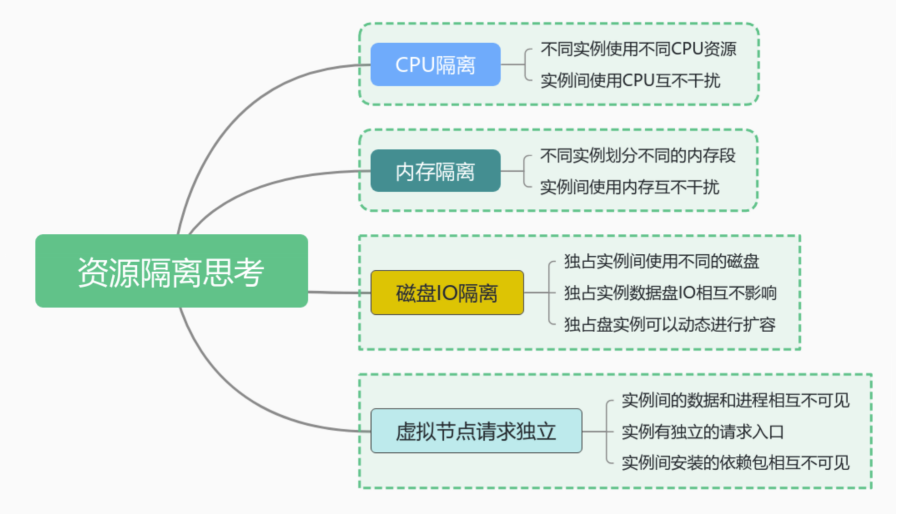
资源隔离有几个点需要考虑:
1. CPU 隔离
不同实例使用不同 cpu 资源,实例间使用 cpu 互不影响。
2. 内存隔离
不同实例使用不同的内存段,实例间使用内存互不影响。
3. 磁盘 IO 隔离
独占实例间使用不同的磁盘,独占实例间磁盘互不影响,独占实例可以动态进行扩容。
4. 虚拟节点请求独立
实例间的进程和数据互不可见,实例有独立的请求入口,实例间安装的依赖包互不依赖互不可见。
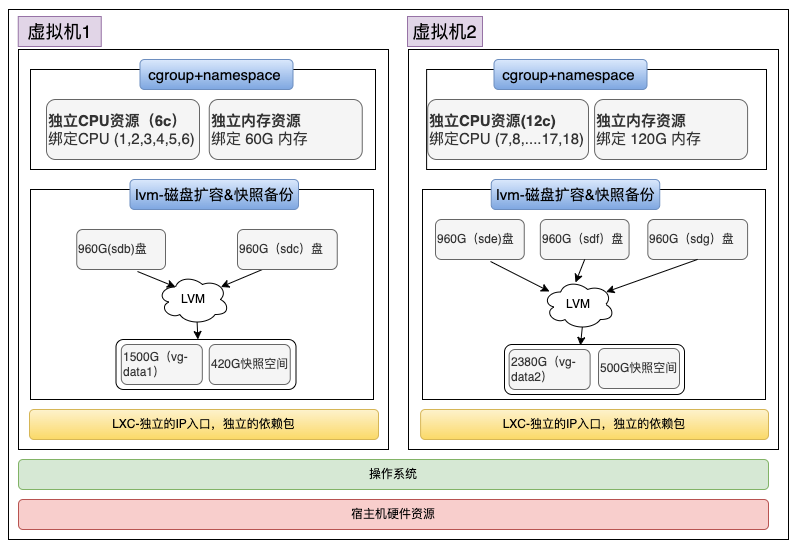
在实施套餐定制后,我们对节点进行虚拟化处理。在此过程中,资源隔离至关重要。我们采用轻量级 LXC 虚拟化技术,以实现 CPU 和内存的有效隔离。对于 IO 密集型节点,例如 TiKV 节点,我们在 SSD 盘上创建不同的 LVM,并将其挂载至不同虚拟机下,确保磁盘响应的独立性。至于网卡流量隔离,得益于多张万兆网卡的配置,通常流量不会成为限制因素。
套餐升级
平台支持套餐升级,以适应业务量的增长。如果需要从标准套餐升级至更高性能的套餐,会根据宿主机的资源情况,提供动态扩容服务。包括动态调整 CPU、内存和磁盘资源。若宿主机资源不足,后端服务将执行节点的增加和删除操作。虽然这一过程可能较长,但通过新增节点、负载均衡后再删除旧节点,确保整个升级过程的顺利进行。
备份
快照备份
在 TiDB SaaS 平台上,备份快照服务扮演着至关重要的角色。尤其在 OLTP 场景中,快速备份和恢复的能力对于数据回档等操作至关重要。用户可以通过简单的操作,在进行游戏维护或其他业务操作时,实现整个系统的完整备份,而不会对业务流程造成任何干扰。

快照服务使用 LVM 技术来创建 snapshot,用户只需一键操作,即可生成快照并继续进行其他任务,无需等待复杂的备份流程完成。根据需要,生成的快照可以被复制到备份盘,或者上传至 S3 存储,这一过程完全由用户自行选择。这样的设计使得备份过程轻量且快速,对业务的影响降到最低。
然而,快照备份作为一项可选操作而非默认备份方式,是因为它存在一些局限性。例如:
尽管如此,快照备份仍然满足了一部分业务需求。
BR 备份

我们也提供 TiDB 官方的 BR 备份作为常规备份方式。BR 备份操作简便,直接备份至远程 S3 存储。我们广泛使用公有云服务,如 AWS、GCP、阿里云和微软云等,对于支持 S3 的云服务,我们直接备份至 S3;对于不支持的,则采用快照备份方式。
BR 备份的优点包括灵活简单的备份操作,支持库表级别的备份,以及稳定的 5.0 以上版本。此外,它无需预留数据盘空间,并且恢复过程相对灵活,无需指定同等规模的 TiKV 节点。
恢复过程
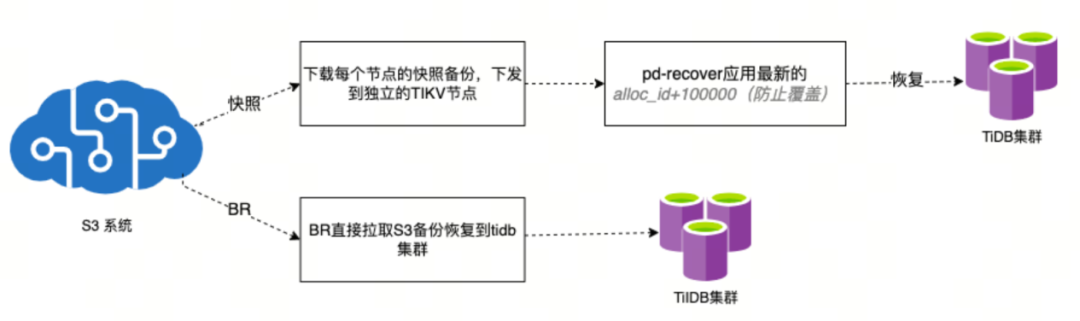
对于不同的备份方式,采取不同的恢复策略。
通过这些备份与恢复策略,确保了数据的安全性和可靠性,为用户提供了灵活的数据保护解决方案。
MySQL 与 TiDB 数据流向的闭环
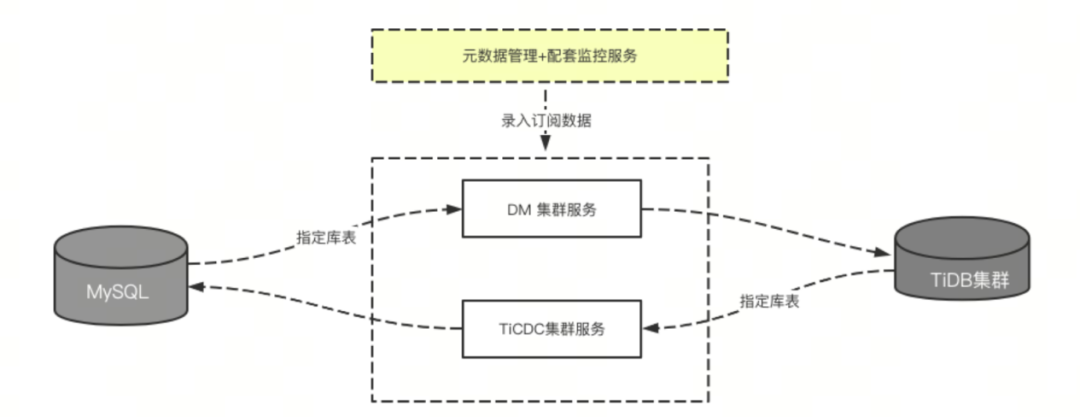
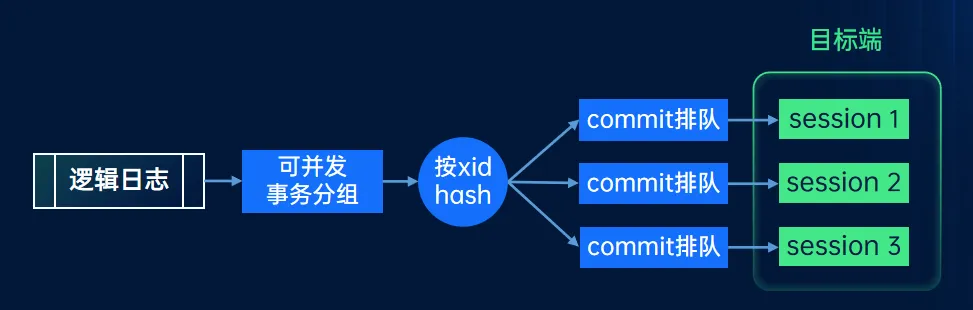
在 TiDB SaaS 平台中,我们经常需要在 TiDB 集群与 MySQL 之间进行数据同步。为此,我们提供了 DTS 服务,允许用户直接在 MySQL 中指定库表,并根据预设的规则进行同步,如同步特定表、更改库名等,通过我们封装的 DM 服务实现与 TiDB 集群的同步。若需反向同步,即从 TiDB 同步回 MySQL,用户可以通过 TiCDC 服务进行注册,实现指定表的反向同步,确保数据迁移的完整性和正确性。
异构数据的同步

此外,我们还支持异构数据的同步。通过 TiCDC,我们可以根据用户定义的规则,将增量或全量数据同步至 Kafka 集群,并进一步同步到其他非关系型数据库。提供了一个全面的异步数据同步解决方案,满足不同数据同步需求。
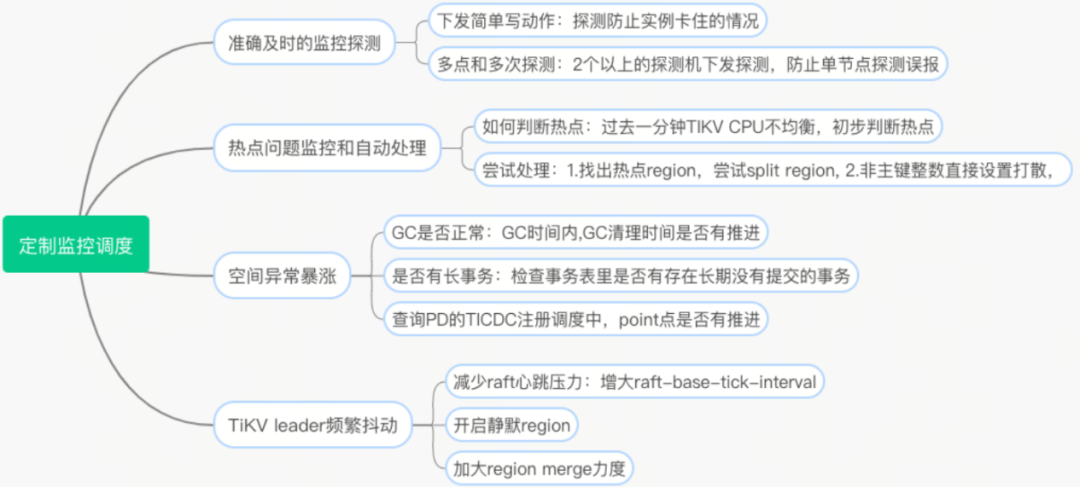
定制化监控调度服务
在我们使用的初期,在实际业务的应用中也遇到了很多问题,比如:
针对这样的情况,我们也因此打造了定制化的监控调度服务。
高并发请求运维
业务背景
接下来分享一些我们在高并发场景下的运维实践。
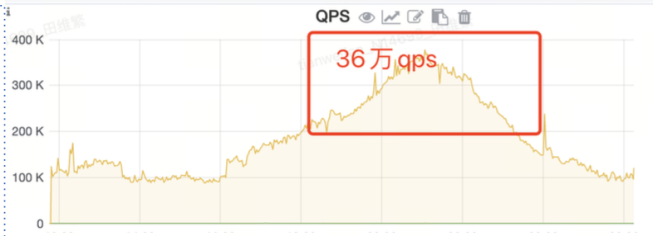
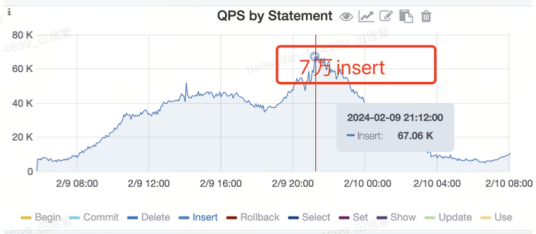
在处理高并发请求的场景中,我们积累了一系列运维实践经验。以网易内部某项目为例,在业务启动初期,我们预估并发量可能超过 10 万,而实际生产环境中,该业务已达到 36 万 QPS,高峰期甚至超过 40 万。同时,插入和更新操作的数量巨大,高峰期间的 I/O 需求极为严苛。此外,大规模数据的过期清理也对数据库性能构成了挑战。
前期优化准备
因此,在真正投入使用前的设计阶段,我们就考虑到不仅要从数据库层面,也要从业务角度尽量去优化和避免这些问题。
碰到的问题与解决方案
在业务规划初期,我们遇到了几个主要问题:
为解决这些问题,我们采取了以下措施:
1. 从 TiDB 5.1 升级至 TiDB 6.1.7 版本,优化了 GC 清理效率,减少了 1/4 的空间占用,并降低了成本。
2. 在面对庞大集群的升级任务时,我们无法通过建立新集群并进行数据同步的传统方法来实现。因此,我们采取了滚动升级的策略,确保在新版本经过充分验证后,逐步对集群进行升级。在此过程中,我们会先创建快照,以便在升级过程中出现问题时能够迅速回滚到升级前状态。针对因 Region 过大而无法进行 split 和备份的问题,通常会在业务流量较低的时段,创建一个新的表并将数据迁移过去。然后执行删除操作(drop table),以此来减少 Region 的大小,并允许正常的数据备份和升级流程进行。
3. 关于 raft 性能抖动,TiDB 6.1 版本会默认开启 raft engine,以降低 raft 平均时延,但随之而来的性能抖动是我们的业务难以接受的,所以我们选择关闭 raft engine,回归到 rocksdb 的默认写入方式,有效解决了性能抖动问题。
通过这些措施,我们确保了在高并发场景下的业务稳定性和数据库性能,为用户提供了更加可靠的服务。